Consensus
How to set up consensus for quality analysis and view/comprehend results.
The consensus tool allows you to automatically compare the annotations on a given asset to all other annotations on that asset. Consensus works in real-time, so you can take immediate and corrective actions toward improving your training data and model performance.
Consensus scores are calculated for assets with more than one label. When an annotation is created, updated, or deleted, the consensus score is recalculated for data rows with to or more labels. Consensus scores can take up to five minutes to calculate.
The following table shows which data types and annotations support consensus agreement scores.
| Annotation type | Image | Video | Text | Chat | Audio | Geospatial |
|---|---|---|---|---|---|---|
| Bounding box | ✓ | X | N/A | N/A | N/A | ✓ |
| Polygon | ✓ | X | N/A | N/A | N/A | ✓ |
| Polyline | ✓ | X | N/A | N/A | N/A | ✓ |
| Point | ✓ | X | N/A | N/A | N/A | ✓ |
| Segmentation mask | ✓ | X | N/A | N/A | N/A | N/A |
| Entity | N/A | N/A | ✓ | ✓ | N/A | ✓ |
| Relationship | N/A | N/A | X | X | N/A | N/A |
| Radio | ✓ | X | ✓ | ✓ | ✓ | ✓ |
| Checklist | ✓ | X | ✓ | ✓ | ✓ | ✓ |
| Free-form text | X | X | X | X | X | X |
Queued consensus submissions
You can queue consensus submissions for all supported data types, which means you can "collect votes" to build consensus throughout your team.
Configure consensus settings
When you create a new project, you’ll be prompted to select a quality setting (benchmark or consensus), by default benchmark will be selected.
Quality settings are defined when a project is created; they cannot be changed after the fact.
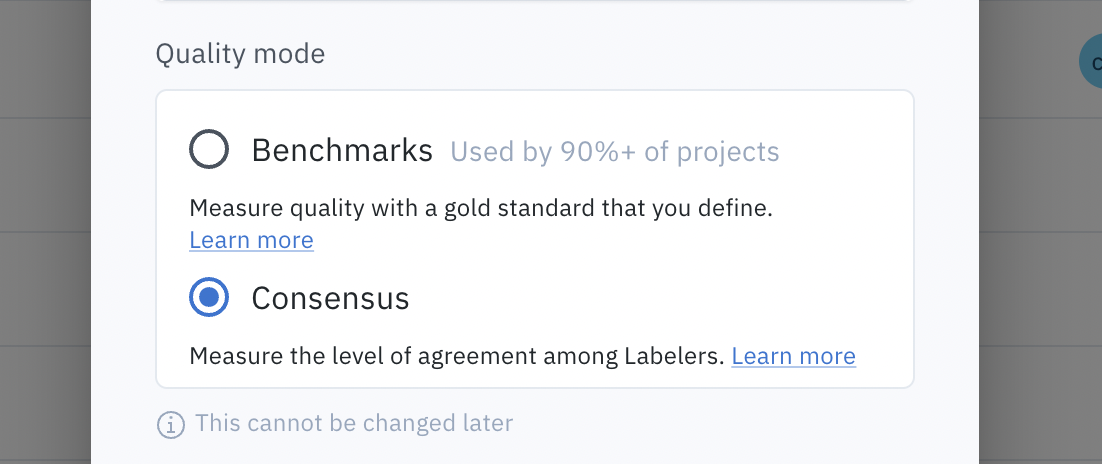
Batch settings
Consensus projects let you configure additional settings for each batch added to the project, including priority, coverage, and number of labels.
The priority, coverage, and number of label settings are defined only when the batch is created. They cannot be changed later.

| Consensus setting | Description |
|---|---|
| Data row priority | This value indicates where in the labeling queue these data rows will be slotted based on priority. |
| % coverage | This value indicates what percentage of the data rows in the batch will enter the labeling queue as consensus data rows, by default the value is 10%. |
| # labels | This value indicates how many times each consensus data row will be labeled, by default the value is 2 labels. |
Select a set of annotations as the “winner”
By default, consensus projects allow multi-labeling for the data rows queued to that project. This means that data rows included in the percent coverage can be labeled by more than one labeler.
After a data row is labeled, it can be reviewed. By default, the first annotations entered for a data row are considered to represent consensus. During the review process, a reviewer can reassign consensus to another set of annotations one the data row has more than one label.
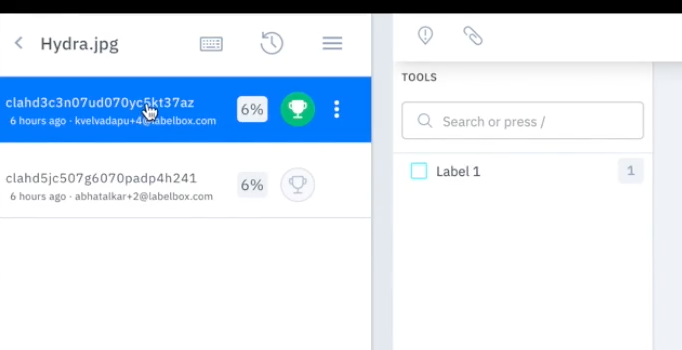
If your data row has been labeled more than once, you'll view all of the label entries on that data row in the data row browser. The following example shows a data row with two sets of labels. The green trophy icon indicates that the first set of annotations is considered "consensus."
To change consensus, select the trophy icon next to the preferred annotations.
The following video shows how to approve and reject rows in a consensus project.
View consensus results
Within a project, navigate to Performance > Quality and you will see two charts. The histogram on the left displays the average consensus score for labels created in certain date ranges. The histogram on the right shows the number of labels created that have a consensus score within the specified range.
The consensus column in the data row activity table contains the agreement score for each labeled data row and how many labels are associated with that score. When you click on the consensus icon, the activity table will automatically apply the correct filter to view the labels associated with that consensus score.
When you click on an individual labeler in the performance tab, the consensus column reflects the average consensus score for that labeler.
Consensus scores in export
When you export consensus scores, a consensus_score field is added to the performance_details section of exported labels in the resulting JSON file.
The consensus-score value is a floating point value between 0 and 1; it represents the associated consensus score for the label. This field can be found in the performance_details.
Consensus scares are provided only for data rows with more than one set of labels.
FAQ
How are object-type calculations factored into the Consensus calculation?
Consensus agreement for bounding box, polygon, and segmentation mask annotations is calculated using Intersection over Union (IoU). The agreement between point annotations and polyline annotations is calculated based on proximity.
-
First, Labelbox compares each annotation to its corresponding annotation to generate IoU scores for each annotation. The algorithm first finds the pairs of annotations to maximize the total IoU score, then it assigns the IoU value of 0 to any unmatched annotations.
-
Labelbox then averages the IoU scores for each annotation belonging to the same annotation class to create an overall score for that annotation class.
"Tree" annotation class agreement = 0.99 + 0.99 + 0.97 + 0 + 0 / 5 = 0.59
How are text (NER) annotations factored into the consensus calculation?
The consensus score for two text entity annotations is calculated at the character level. If two entity annotations do not overlap, the consensus score will be 0. Overlapping text entity annotations will have a non-zero score. When there is overlap, Labelbox computes the weighted sum of the overlap length ratios, discounting for already counted overlaps. Whitespace is included in the calculation.
- Since the consensus agreement for NER is calculated at the character level, spans of text are partly inclusive. For example, If two labelers make an overlapping text entity annotation on the word "house" and the first labeler submits an annotation with
houseand the second labeler submits an annotation on the same word in the text file withhous, the agreement score between these two annotations would be 0.80. - Labelbox then averages the agreements for each annotation created using that annotation class to create an overall score for that annotation class.
How is consensus calculated for classifications?
The calculation method for each classification type is different. One commonality, however, is that if two classifications of the same type are compared, and there are no corresponding selections between the two classifications at all, the agreement will be 0%.
-
A radio classification can only have one selected answer. Therefore, the agreement between the two radio classifications will either be 0% or 100%. 0% means no agreement, and 100% means agreement.
-
A checklist classification can have more than one selected answer, which makes the agreement calculation a little more complex. The agreement between two checklist classifications is generated by dividing the number of overlapping answers by the number of selected answers.
For child classifications, if two annotations containing child classifications have 0 agreement (false positive), the child classifications will automatically be assigned a score of 0 as well.
Labelbox then creates a score for each annotation class by averaging all of the annotation scores.
For example, when Image X loads in the editor, the labelers have 3 classification questions to choose from (Q1, Q2, Q3) each with two answers.

Each of the dotted boxes represents a unique answer choice/answer schema.
Say, for example, these 2 labelers have the same answer for Q1 but different answers for Q2 and Q3.

Labeler 1

Labeler 2
For classifications, the consensus agreement is calculated based on how many unique answer schemas are selected by all labelers.
-
Q1-A: 1 (both labelers picked this answer)
-
Q1-B: N/A (neither labeler picked this answer) <-- not included in the final calculation.
-
Q2-A: 0 (Labeler 1 selected, Labeler 2 did not)
-
Q2-B: 0 (Labeler 2 selected, Labeler 1 did not)
-
Q3-A: 0 (Labeler 1 selected, Labeler 2 did not)
-
Q3-B: 0 (Labeler 2 selected, Labeler 1 did not)
So the final consensus calculation for the classifications on Image X is:
(1 + 0 + 0 + 0 + 0) / 5 = .20
How is the consensus score calculated for objects + classifications?
Labelbox averages the scores for each annotation class (object-type & classification-type) to create an overall score for the asset. Each annotation class is weighted equally. Below is a simplified example.
Consensus score = (annotation class agreement + radio class agreement) / total annotation classes
0.795 = (0.59 + 1.00) / 2
You can use the metric as an initial indicator of label quality, the clarity of your ontology, and/or your labeling instructions.
Updated 14 days ago