
 All blog posts
All blog postsLabelbox•August 22, 2025
Announcing R-ConstraintBench: A novel way to stress-test LLM reasoning abilities under interacting constraints
Research overview
We introduce R-ConstraintBench (short for Resource-ConstraintBench), a framework for testing large language models on real operational challenges such as large-scale project management, construction, staff scheduling, equipment allocation, and deadline management. These are real-world, high-stakes planning problems that organizations face every day.
What makes R-ConstraintBench different is that it provides a new way to test LLM reasoning at scale: as complexity rises, can models generate schedules that satisfy every constraint while remaining internally consistent? Think of it as a stress test for LLM reasoning, applicable across countless domains where planning, allocation, and logical consistency matter. In practice, this becomes a lever for improving overall reasoning: the same signals that expose breakdowns can guide training focus and track real progress.
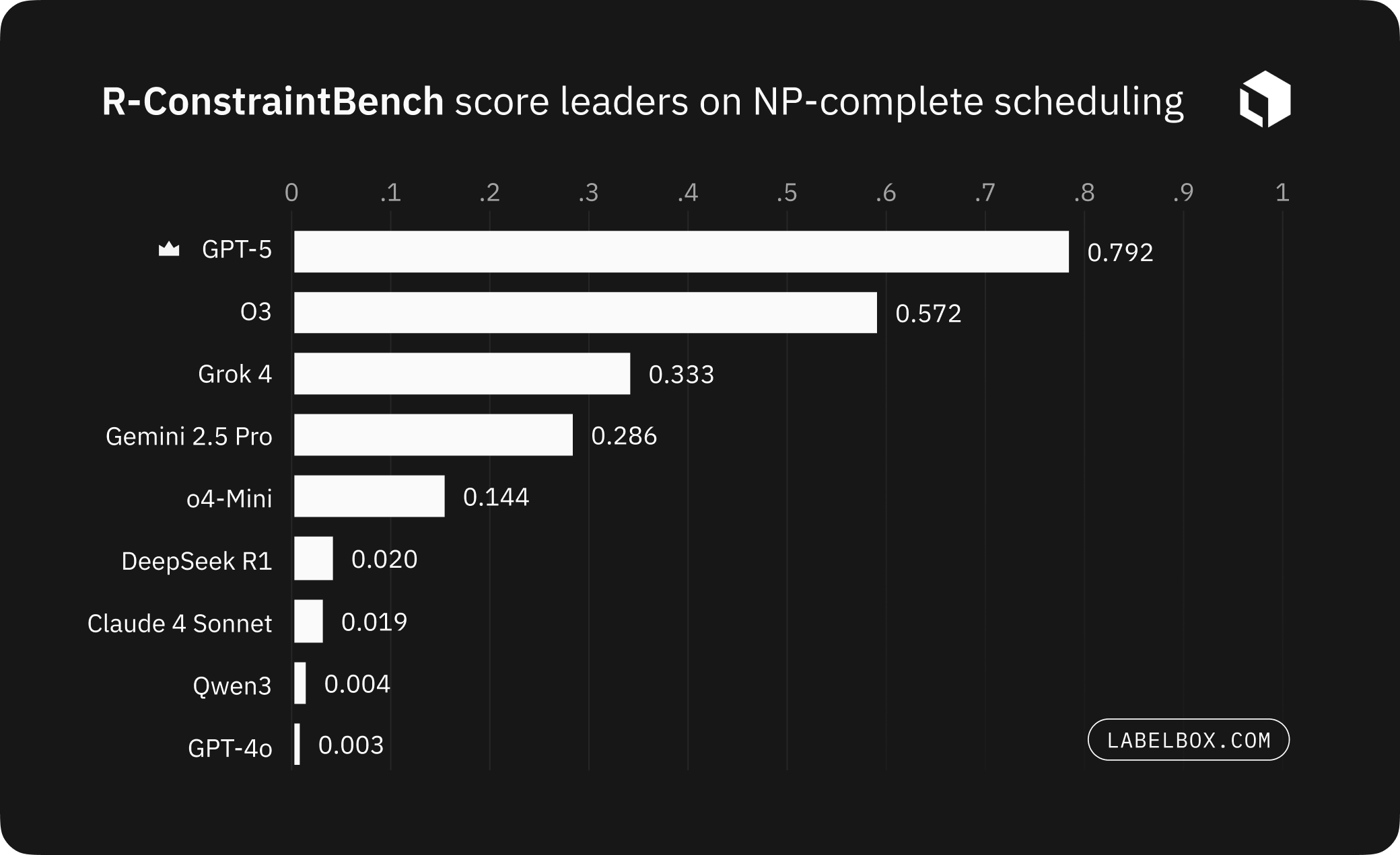
R-ConstraintBench challenges leading LLMs on scaled task difficulty across hundreds of levels and encoded realistic operational rules to rigorously measure feasibility. Our initial findings show that no current model maintains consistent feasibility under realistic, high-complexity scenarios. On synthetic stress tests, o3 demonstrates the highest feasibility, closely followed by GPT-5. In a domain-grounded data center migration benchmark, GPT-5 takes the lead, outperforming Grok 4.
Introducing R-ConstraintBench
R-ConstraintBench is a rigorous feasibility benchmark for real-world operational planning that generalizes to constraint-sensitive reasoning. It evaluates how well large language models maintain constraint-satisfying schedules as task complexity scales and tests whether performance on synthetic tasks transfers to real-world scenarios.
Effective scheduling under tight resource, temporal, and operational constraints is critical in domains such as data center migration, where even minor errors can incur multi-million dollar costs. Despite this, the reliability of LLMs on complex, high-stakes project schedules has remained largely unquantified. R-ConstraintBench provides the first systematic framework to measure it.
Our methodology
R-ConstraintBench simulates the progressive complexity of real-world operations, introducing one constraint at a time. Tasks are incrementally tightened, with additional rules reflecting challenges faced by real schedulers, including maintenance windows, deadlines, and exclusive resource requirements. Generated plans are then evaluated against all specified constraints, and performance metrics are aggregated to emphasize reliability under high-difficulty conditions.
- Difficulty ramp: Each level adds one more binding constraint; later levels are harder by design.
- Operational rules: Inject resource downtime, time windows, and no-overlap equipment constraints.
- Two tracks:
- Synthetic “advanced constraints” (multi-constraint interaction stress test)
- Real-world data center migration (operational grounding)
- Scoring:
- WAUC (weighted area-under-curve): Average feasibility across all levels with higher weight on later, harder levels (so sustained performance at high difficulty counts more).
- Breakpoint: The first level where feasibility falls below a viability threshold (e.g., 70%), indicating where reliability starts to collapse.
A look at the results
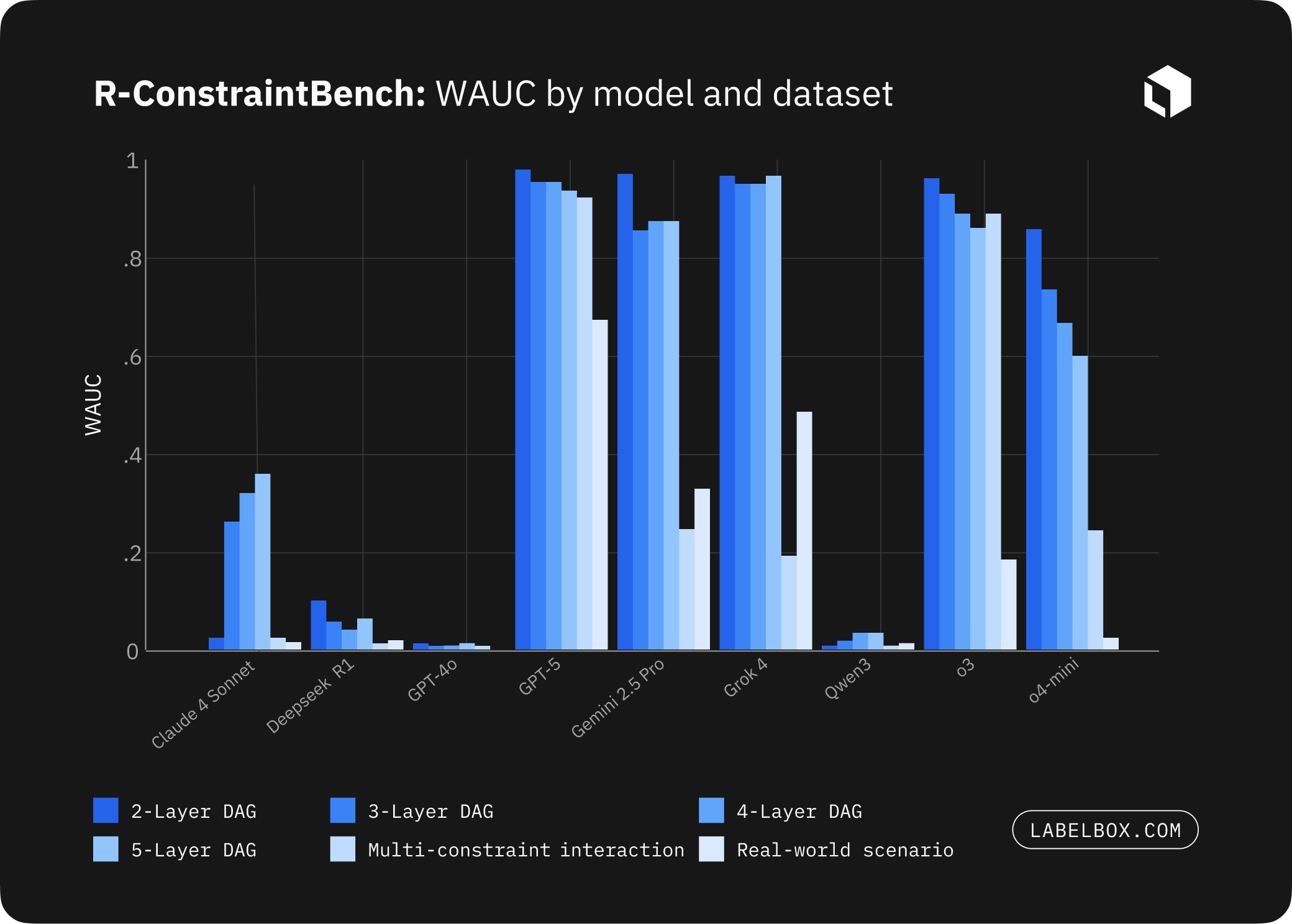
- Synthetic advanced constraints: o3 leads (WAUC 0.931), with GPT-5 close behind (0.924)
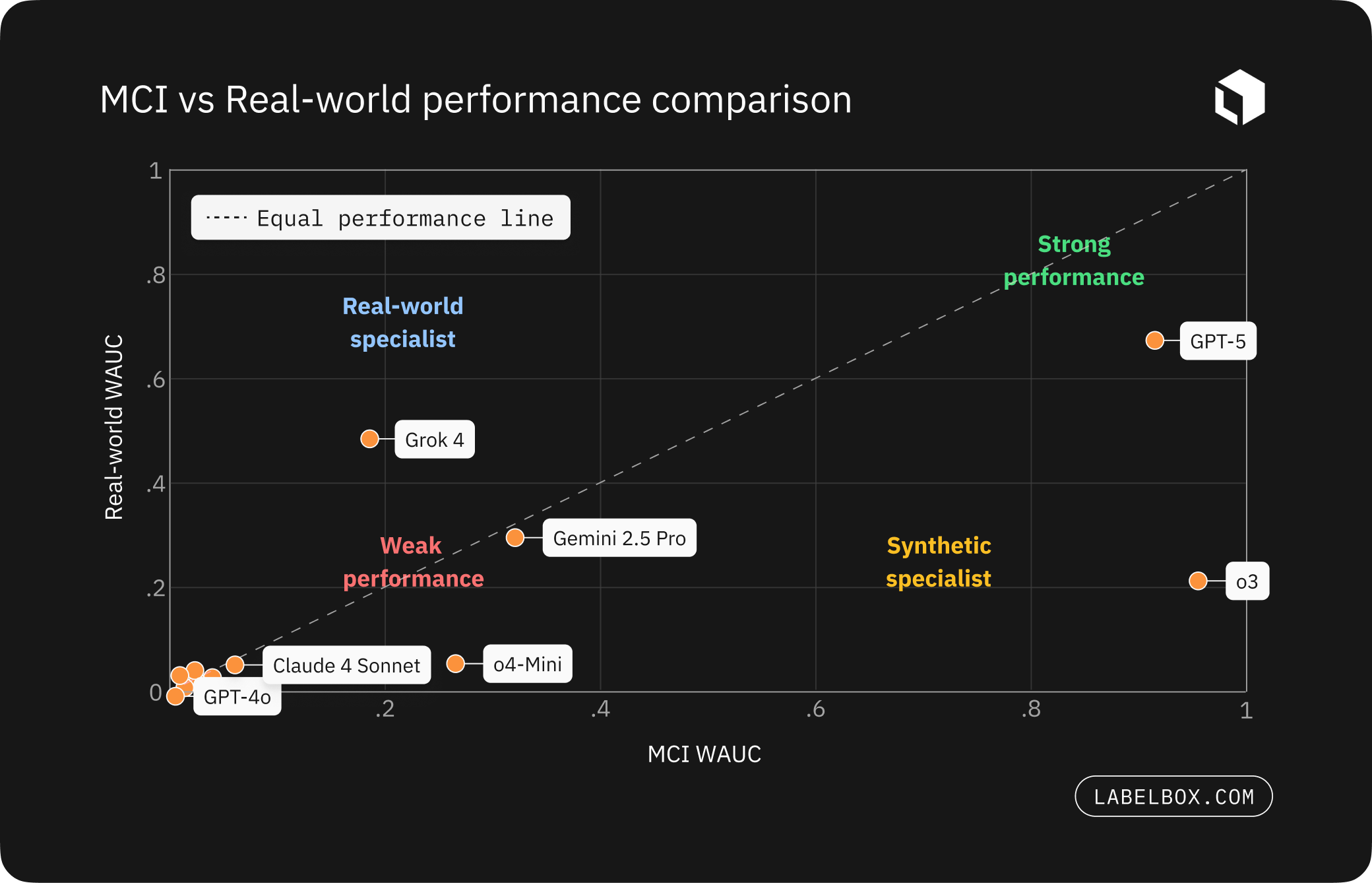
- Real-world migration: GPT-5 leads (WAUC 0.661), followed by Grok 4 (0.483); o3 drops to 0.214 – clear evidence of a domain gap LLMs must close
- Why LLMs are failing: dominant failures vary by model. For example, disjunctive overlaps for Grok 4 and Gemini vs. precedence misses for GPT-5 and o3, pinpointing next model improvement targets.
What we learned
- Constraint interaction is the bottleneck:
- When maintenance windows, deadlines, and exclusivity overlap, model feasibility often declines. The problem is not precedence alone but maintaining global consistency under heterogeneous rules.
- Synthetic success doesn’t guarantee domain transfer:
- State-of-the-art models that perform well on synthetic datasets do not always perform strongly on real world use cases, showing that transfer depends on domain specific constraint couplings and must be validated with domain grounded evaluations.
- Late-band collapse is universal
- Even leading models tend to show low feasibility at high constraint densities, underscoring why teams evaluate how performance scales rather than relying on a single aggregate score.
- Failures are diagnostic
- Leading models are failing for different reasons. This makes R-ConstraintBench valuable for guiding targeted improvements, whether in handling temporal windows or maintaining precedence under load.
Why it matters
R-ConstraintBench provides labs with a practical framework to assess whether LLM-generated plans remain executable under operational pressure. It identifies feasibility breakdowns, pinpoints which constraints drive failures, and evaluates whether gains on synthetic tasks can transfer to real-world scenarios.
Key actionable areas for improving performance on these tasks include:
- Teach global consistency under interacting constraints: Train models to satisfy multiple rule types at once (deadlines, downtime, exclusivity, capacities) rather than just deeper graphs.
- Train & test on real-world cases: Use domain-grounded examples and evaluate on held-out domains to strengthen overall reasoning and check that gains transfer beyond synthetic tasks.
- Fix what fails: Use failure signatures (precedence, temporal, disjunctive, resource, format) to target improvements and build focused datasets to improve model reasoning performance in the pinpointed areas.
Read the full paper and get in touch
You can read the full paper here on arXiv.
Interested in running R-ConstraintBench on your workflows or creating constraint driven training datasets? We would be happy to help, whether it is leveraging R-ConstraintBench directly or setting up a private benchmark for faster frontier model evaluation.
Get in touch and we would love to hear your feedback. We are also expanding this benchmark to cover more real world scenarios, so stay tuned.


