
 All blog posts
All blog postsManu Sharma•June 15, 2023
How to automate labeling for product categorization with LLMs
This is the second post in a blog series by Karen Yang, Senior AI PM, showcasing how Model Foundry brings the power of foundation models into Labelbox.
Overview
Product tagging and categorization are essential components for the modern shopping experience. It powers intuitive product search results, personalized recommendations, product exploration, marketing campaigns, and is an ad engine.
Product categorization can be a labor-intensive process, as the tags and categories are usually created manually or crowdsourced by questionnaires from sellers and then moved through a review process. A popular e-commerce website can easily have tens of thousands of product listings with hundreds of categories to choose among. Reading over each of the products’ descriptions and deciding on the correct category can be a daunting task.
In recent years, large language models (LLMs) have become very powerful at common sense reasoning, contextual understanding, and information processing. They often have a strong zero or few shot performance on various use cases. In the case of product categorization, many LLMs are exposed to large amounts of similar data during their web-scale training process. Therefore, they generalize well for understanding and extracting product features, target audiences, and uses.
In this blog post, we will walk through how to use LLMs to instantly categorize products and provide relevant product summaries from their HTML text descriptions. By leveraging LLMs, product categorization can be largely automated with high accuracy, allowing subject matter experts to focus their attention on model evaluation rather than reading every single sentence.
Experiment setup
For this example, we took samples of sixteen product categories from the Etsy retail products dataset on Kaggle. It contains a wealth of information, including long-form product descriptions, categories, reviews, sellers, and other relevant information. For this use case, we are only interested in assessing an LLM’s ability to predict the product categories from the long description, as well as their ability to generate a summary (or name) to highlight the product’s features.
The 16 classes are:
["Toys & Games < Games & Puzzles",
'Art & Collectibles < Photography',
'Weddings < Decorations',
'Weddings < Gifts & Mementos',
'Art & Collectibles < Painting',
'Toys & Games < Sports & Outdoor Recreation',
"Shoes < Women's Shoes",
'Art & Collectibles < Drawing & Illustration',
'Accessories < Hair Accessories',
'Toys & Games < Toys',
'Accessories < Baby Accessories',
'Pet Supplies < Urns & Memorials',
'Art & Collectibles < Prints',
"Shoes < Girls' Shoes",
"Shoes < Unisex Kids' Shoes",
'Weddings < Accessories']Some of the categories are within the same high-level category group and thus are semantically similar to each other. Appropriate classification requires contextual understanding rather than simple keyword searches to get good classification results.
Model and prompt set up
With Labelbox’s soon-to-be released Model Foundry, you will have access to a range of popular models, including third-party APIs and open source models. You can browse available models and read more about their intended uses and feasible ontology here.
In this experiment, we will use ChatGPT (gpt-3.5-turbo) as a demonstration, since its prompt-based interface makes it flexible to describe our problem and preference, and it can process both the classification and the summary generation tasks together.
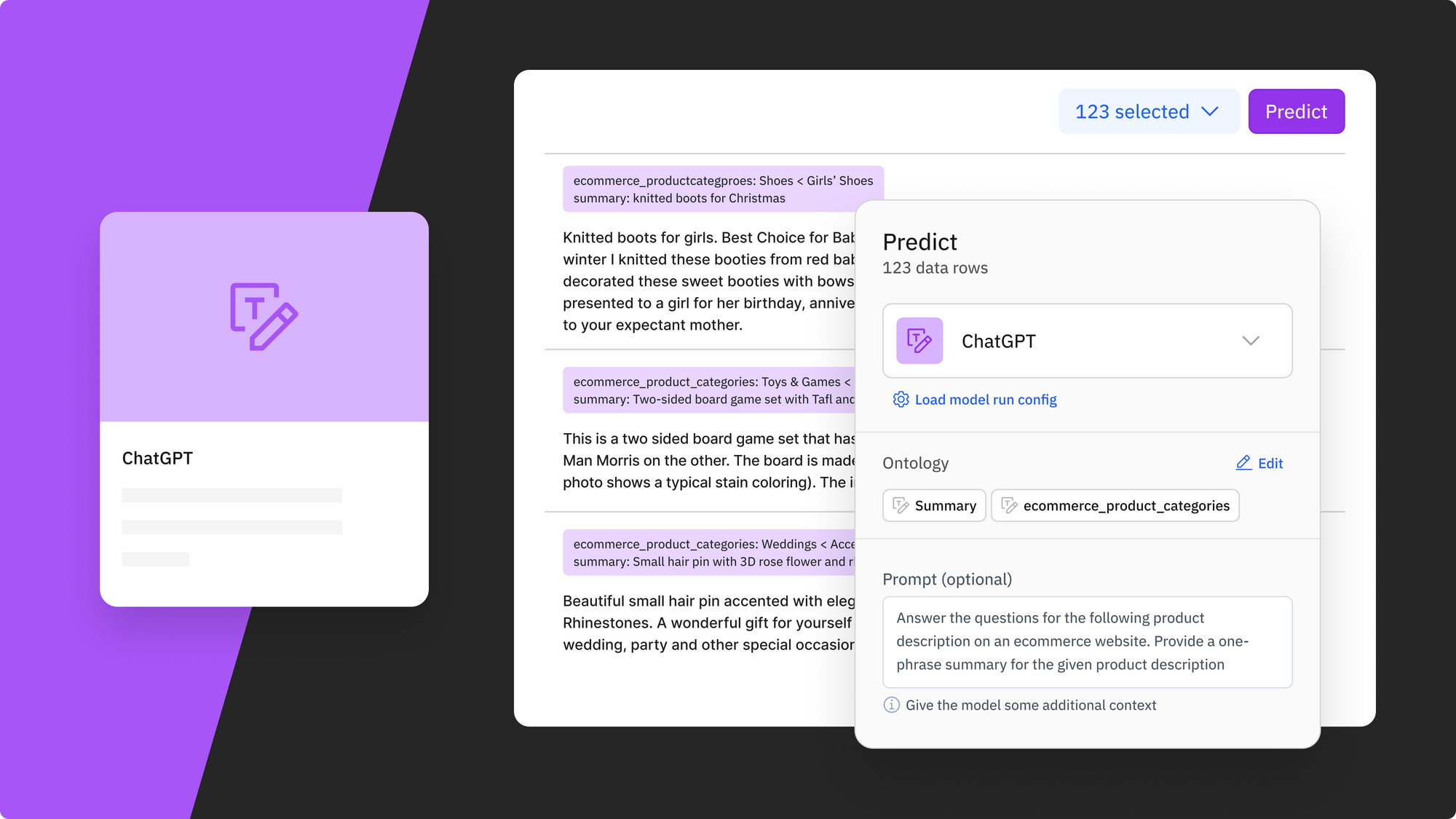
Creating effective prompts for large language models that work well for your use cases is an art. Model Foundry makes it easy to generate a prompt template that works out of the box. All you need to do is define the ontology and optionally provide some instructions and examples – similar to how you would set up a labeling project. As you can see in the screenshot above, you first define the ontology for this model job. In this example, we asked the model to do a radio classification of "ecommerce_product_categories", with the sixteen classes as options, and we also asked the model to provide a summary, formulated as a free text question.
Once you have selected your ontology, a prompt template will automatically be populated, as seen in the ‘Prompt’ text box. This auto-configured prompt template explains your goal to the model, and asks the model to return it in a structured format so that it can easily be parsed and integrated into a downstream workflow. If you want to run some prompt engineering and add additional context, you can freely modify the template.
Another part of the template is the optional ‘Examples’ section. You can add a few example pairs of product descriptions with the expected answer, to inform the models what your preferences are. Studies have shown that LLMs can improve performance with this kind of few-shot in-context learning.
Lastly, you can change the hyperparameters of the chosen model if you don’t want to use the default ones. For example, with ChatGPT, you can set temperature, max_tokens, top_p, etc.
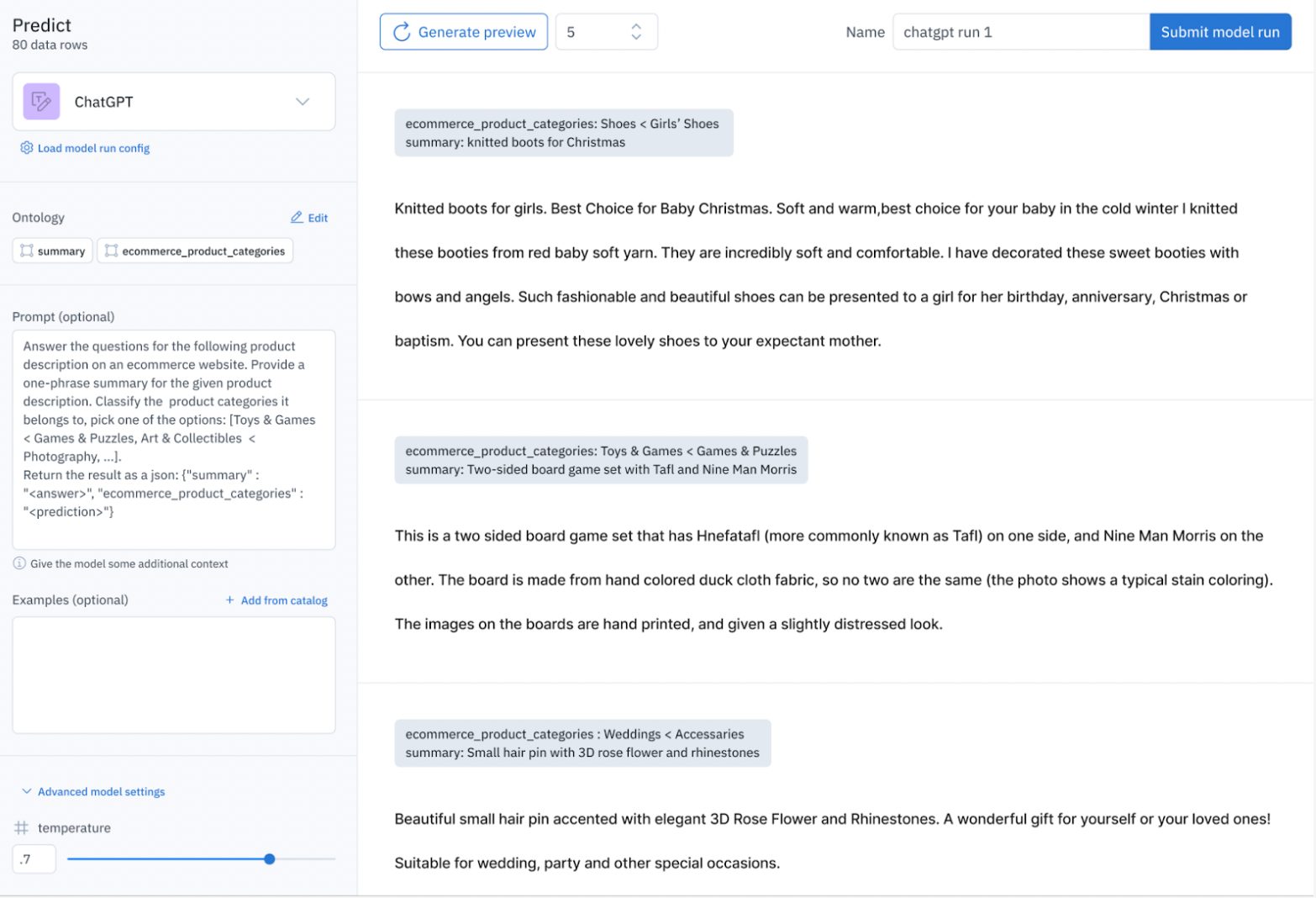
You can generate a preview on a small sample of your selected data. In the image above, you can see some of the generated previews. This allows you to understand whether the model configuration meets expectations on a small sample of data before bulk processing. Based on the preview results, you can go back and modify the model parameters and prompts to your satisfaction. Once you are happy with the model configuration, you can submit all the data rows for inference.
Results
Visualize model predictions and send to project as pre-labels
Once the model job is done, you can visualize and evaluate the results of the ChatGPT on product categorization and summary in Labelbox Catalog and Model.
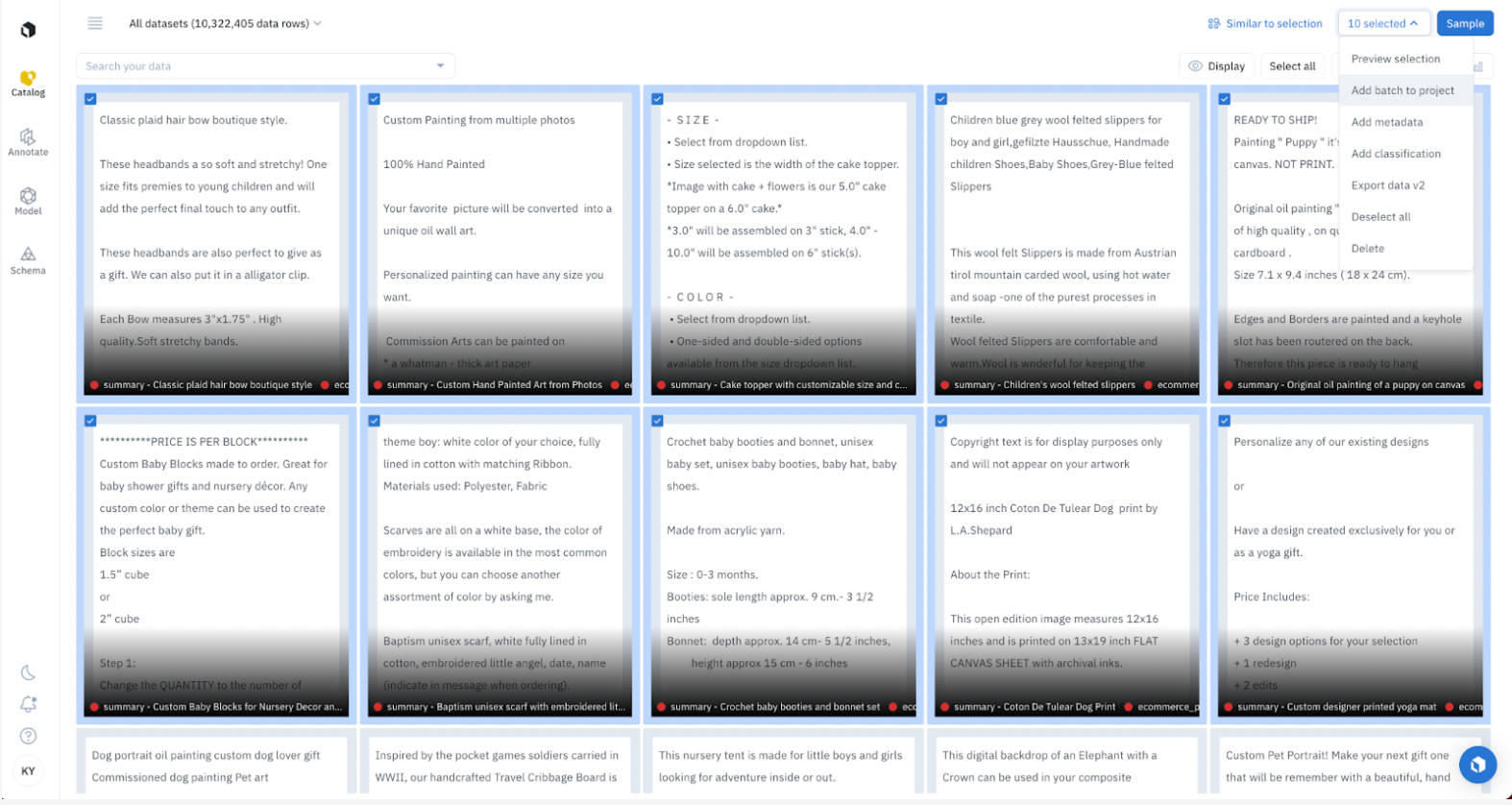
Evaluating model results
To conduct an analysis of a model, it is helpful to compare the predictions of each model with some known ground truth labels side-by-side. It is also essential to conduct a holistic metric analysis that evaluates the model's overall performance on the task. Labelbox’s model run page gives you such a comprehensive view. At the end of each Model Foundry job, a model run will be automatically populated for your analysis.
For example, say we have created and labeled a small set of known hard cases as the golden evaluation ground truth labels to test model performance. We can upload the ground truth labels to the chatGPT run 1 model run we just created via Model Foundry. Now we are ready to evaluate the qualitative and quantitative performance of ChatGPT on our task.
Quantitative evaluation
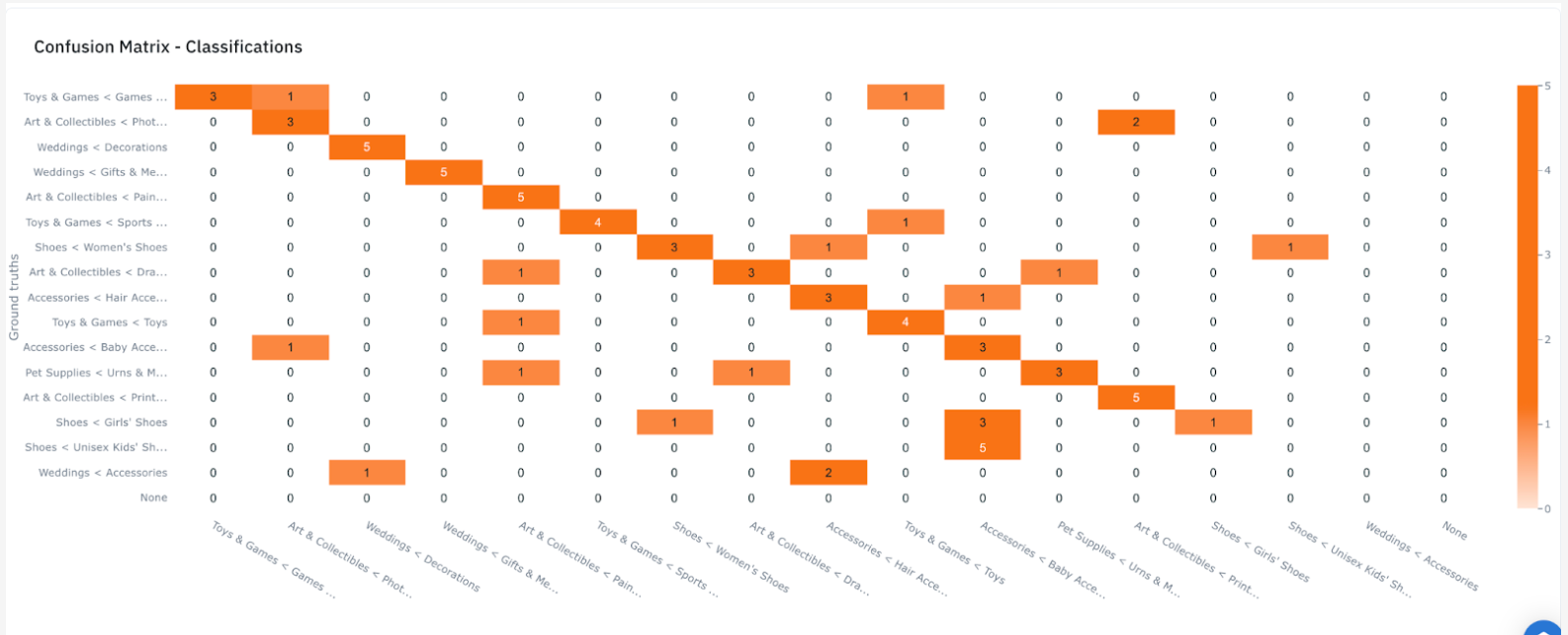
Let’s take a look at the metrics tab first. Here, we can quickly see where the model got things wrong. For example, the model seems to have most of its mistakes in the Shoes category. It has mistaken products from Shoes < Unisex Kids’ Shoes as an Accessories < Baby Accessories product five times, and Girls’ Shoes to Baby accessories three times. It has twice mistaken a product in Wedding < Accessories to be in Hair Accessories.
The model run metrics page also auto-computes the precision, recall, and F1 scores for your model’s given ground truth labels, making it easy to evaluate and compare the quantitative performance of your model. In this experiment, we can see that the model has a 80%+ recall score.
Meanwhile, from the confusion matrix, we can see the model tends to struggle in classes with similar meanings. To dig in further, we can switch to a qualitative view to read the actual places where the mistakes happen, and understand why the model made the mistakes.
Qualitative evaluation
In Model, you can filter the data rows based on metrics. Instead of reading through every data row, you can hone in on just the problematic ones. For example, to understand the false positives for the class Shoes < Girls’ Shoes, you can quickly build and use a metrics filter in Labelbox Model to filter for exactly that, and it will automatically pull out the few data points that meet that criteria.
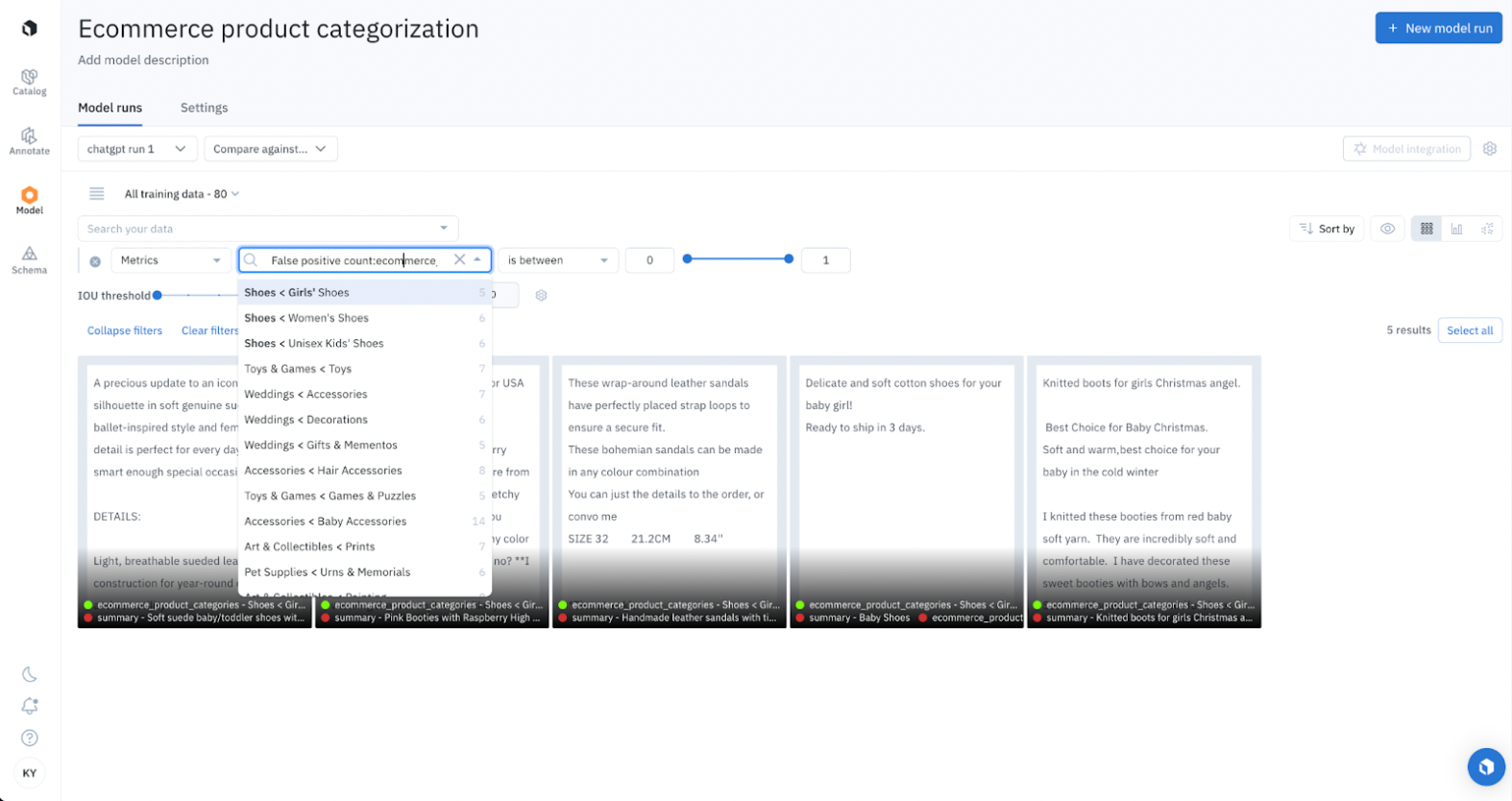
With the information we have now, it’s easy to see why the model is confused: The product descriptions fit into both categories.
Here is one example: the ground truth label (taken from the original Kaggle dataset) categorizes the product as Girls’ shoes, and the model categorizes it as a Baby accessory — and both are technically accurate. In this case, what should we do if we want to improve the model further? We can clarify the model’s criteria by creating more specific instructions and examples, change the category terminology and domain so that they overlap less, or update the ontology so that one product can be listed in multiple categories.
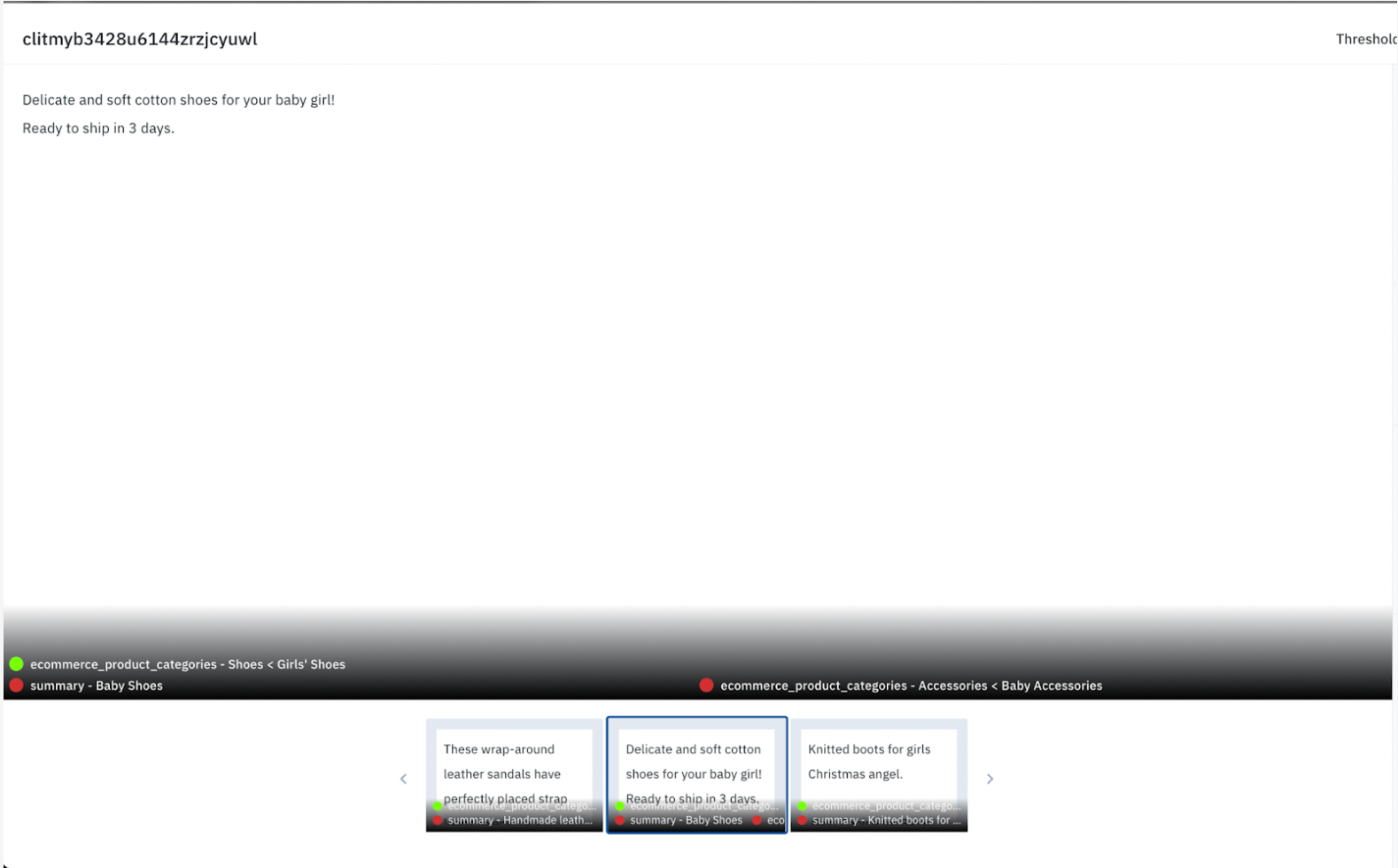
Now let's take a look at whether the model is doing a good job summarizing the product descriptions into short phrases. These descriptions can be used for naming or search relevance. ChatGPT can generate succinct and accurate short product descriptions.
Conclusion
We’ve walked through the process of using a language model (ChatGPT) to generate predictions on product categorization and summary, and evaluate them in depth. The entire process, from problem definition to generating pre-labels, and running evaluation took less than 10 minutes. In our analysis, we see that the model gave largely satisfactory results in a zero-shot setting. This shows the potential of applying large language models to automate the bulk part product categorization tasks.
One of the most important components of building a productive model automation workflow is a quick iteration cycle for improving model prompts and configurations and evaluating the model results. With Labelbox Model, we can gain a more transparent and holistic view of the model performance. By zooming into the classes and data rows where the model failed, we can quickly understand that most of the model’s mistakes were due to the ambiguity of the category definition or because a product fits into multiple categories.
From there, subject matter experts can further improve and guide the model prediction process, by adding more examples in the prompts, iterating on the ontology and instructions, or fine-tuning the model if the previous efforts are not enough. With a few iterations, they can improve the model to be more accurate and aligned with their preferences in this use case.
Labelbox recently announced early access to Model Foundry – the easiest place to build model prediction workflows based on your use case, integrate model results with your labeling workflow, and compare and evaluate model results.
Join the waitlist and stay tuned for the next blog on how to use Model Foundry to enrich images and videos for computer vision use cases.


