
 All blog posts
All blog postsSmit Nautambhai Modi•March 4, 2026
Introducing EchoChain: An audio benchmark for reasoning under pressure in full-duplex dialogue

Voice agents are moving beyond rigid turn-based designs toward continuous interaction, reflecting the shift toward more natural communication. In real conversations, users do not wait politely for an assistant to finish speaking. They interrupt, refine, correct themselves, and add constraints mid-utterance.
Modern full-duplex spoken dialogue systems (such as GPT-realtime-2025-08-28, Gemini Live-2.5-flash-native-audio, Grok Voice Agent, and Amazon Nova Sonic 2) are increasingly built to process speech continuously rather than enforcing strict turn boundaries.
Full-duplex spoken dialogue systems (FDSDS) promise more natural human–machine interaction by streaming comprehension and generation simultaneously. Existing benchmarks, however, largely split into two buckets: (1) turn-delimited evaluations that score end-of-turn answers under clean boundaries, and (2) full-duplex evaluations that prioritize floor-control behavior (latency, takeover, overlap handling) and sometimes add coarse semantic checks.
No benchmark directly measures whether a model can preserve and revise task state when new information arrives mid-utterance during ongoing speech generation, which motivates the three Dual-Stream Reasoning (DSR) failure modes we study: Contextual Inertia, Interruption Amnesia, and Objective Displacement.
We introduce EchoChain to address this gap by benchmarking Dual-Stream Reasoning (DSR) in real-time, full-duplex voice interfaces. EchoChain uses scenario-driven, multi-turn conversations in which users provide context-grounded interruptions during responses, dynamically updating constraints while the assistant is still speaking.
The central research question is whether leading full-duplex audio models can revise and continue their reasoning while responder speech is still streaming: can they adapt to new information and maintain task coherence as a user interrupts?
From turn-based dialogues to continuous reasoning
Most dialogue benchmarks assume half-duplex interaction: one speaker at a time, with the system responding only after the user finishes a complete utterance. That abstraction works for text chat and push-to-talk, but it mismatches the possible complexity of human input.
In real-world settings, users often revise their request mid-response (for example, “actually, change X to Y”), so the task is no longer a static input. Correctness becomes an online requirement: the model must update its active task state constantly, preserve all established requirements, and provide a comprehensive response to the user's query. Latency and smooth turn-taking still matter, but they are not sufficient; what we need to evaluate is reasoning during full duplex scenarios.
Instead of treating each turn as an offline input/output pair, our harness simulates live voice use: audio arrives as a stream, interruptions happen mid-response, and we capture how the model updates its continuation in real time.
In addition, the evaluation harness we’ve built tests models by deliberately inserting controlled interruptions during responses and recording the full conversation flow. This lets us see how well models adjust to changing instructions in real time. By keeping stimuli and timing consistent, the benchmark allows fair comparisons across different systems.
Performance is evaluated for each test instance and grouped into three main failure patterns. The process uses a two-stage pipeline: fast automated screening at first, followed by focused human review to ensure high accuracy in final results.
The hidden failure modes of voice agents
Interruptions reduce reasoning capabilities from turn-based evaluations. In early experiments, we took conversations that failed at the moment of interruption and replayed them without the barge-in.
In 40.22% of those cases, the model succeeded when allowed to complete its original turn uninterrupted. This result suggests that a substantial share of observed errors are failures triggered specifically by mid-generation updates. These interruption-induced dual-stream reasoning failures are classified under three categories:
- Contextual inertia occurs when a model is sent new information but continues reasoning as if no new information was received.
- Interruption amnesia refers to cases where updates are initially incorporated but are later overwritten as generation continues, showing a lack of persistence under streaming reasoning.
- Objective displacement happens when the model treats an interruption as a standalone request and ignores the original task, producing a coherent but incomplete response.

Why existing audio benchmarks miss this
As noted above, existing evaluations largely fall into two buckets: (1) turn-delimited benchmarks, and (2) full-duplex benchmarks that emphasize floor-control. Both are valuable, but neither is designed to isolate reasoning in post-interruption responses.
The core issue is that interaction fluency is not the same as reasoning robustness. A system can sound smooth, acknowledge an interruption, and resume quickly, yet yield an incorrect response, producing Contextual Inertia, Interruption Amnesia, or Objective Displacement.
How EchoChain works
Within the EchoChain framework, interruptions are standardized as model-independent inputs to evaluate if the assistant's subsequent response successfully integrates the pre-interruption context with the new requirements introduced during the interruption. We keep scenario context, system instructions, and persona information consistent across runs, and we inject context-grounded barge-ins using a deterministic schedule relative to assistant speech onset. This lets us study state revision during ongoing generation while minimizing avoidable variance. The framework is used to evaluate multiple full-duplex models, including GPT-realtime-2025-08-28, Gemini Live-2.5-flash-native-audio, Grok Voice Agent, and Amazon Nova Sonic 2.
The system is organized into four components: (1) scenario specification, (2) dialogue simulation and audio synthesis, (3) real-time runtime execution, and (4) automated plus human evaluation. A central orchestrator manages conversation flow, streams audio inputs, records interaction traces, and routes candidate failures into the evaluation pipeline.
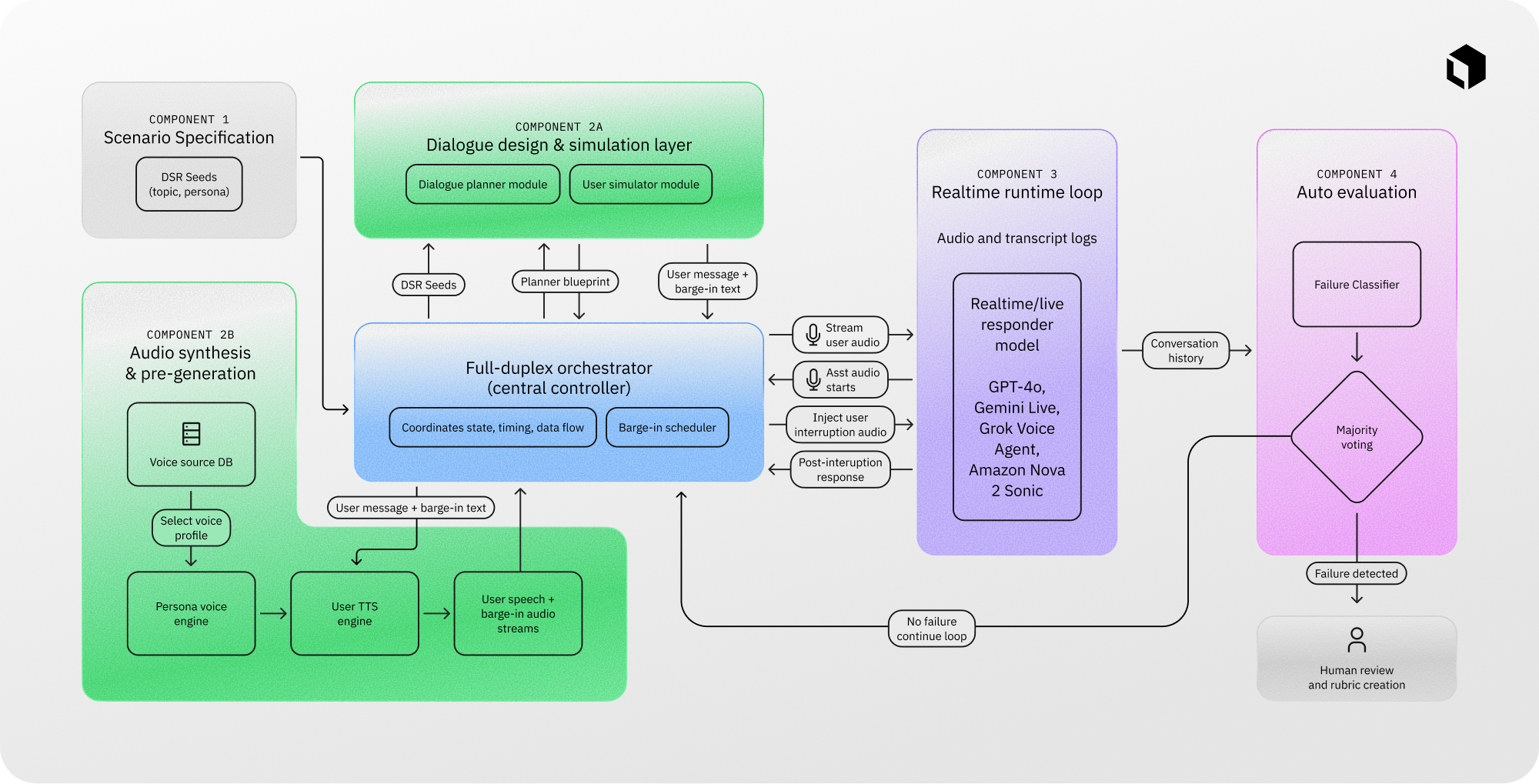
EchoChain begins from a library of DSR seeds like voice support calls, interview coaching, and multi-constraint planning and coordination. A planning module produces interruption-sensitive dialogue blueprints, and a user simulator generates both the primary user utterance and a context-grounded barge-in after an appropriate conversation context is established.
We then synthesize speaker-consistent user audio using a Persona Voice Engine and a TTS engine built on voice cloning, maintaining a consistent voice identity per session. A key design choice is pre-generating both the main utterance and the barge-in audio before the runtime loop begins, which keeps injection latency deterministic and avoids synchronization drift during the interruption window.
Evaluation uses a staged design for both scale and fidelity. Each interaction is segmented into the pre-interruption output, the interruption content, and the post-interruption continuation. A transcript-based classifier provides scalable first-pass screening against our DSR failure taxonomy, and human reviewers then adjudicate flagged cases by listening to audio alongside transcripts, applying a contextual screening rubric for realism and coherence and instance-specific pass/fail criteria to produce final labels.
Voice cloning validation (A/B testing)
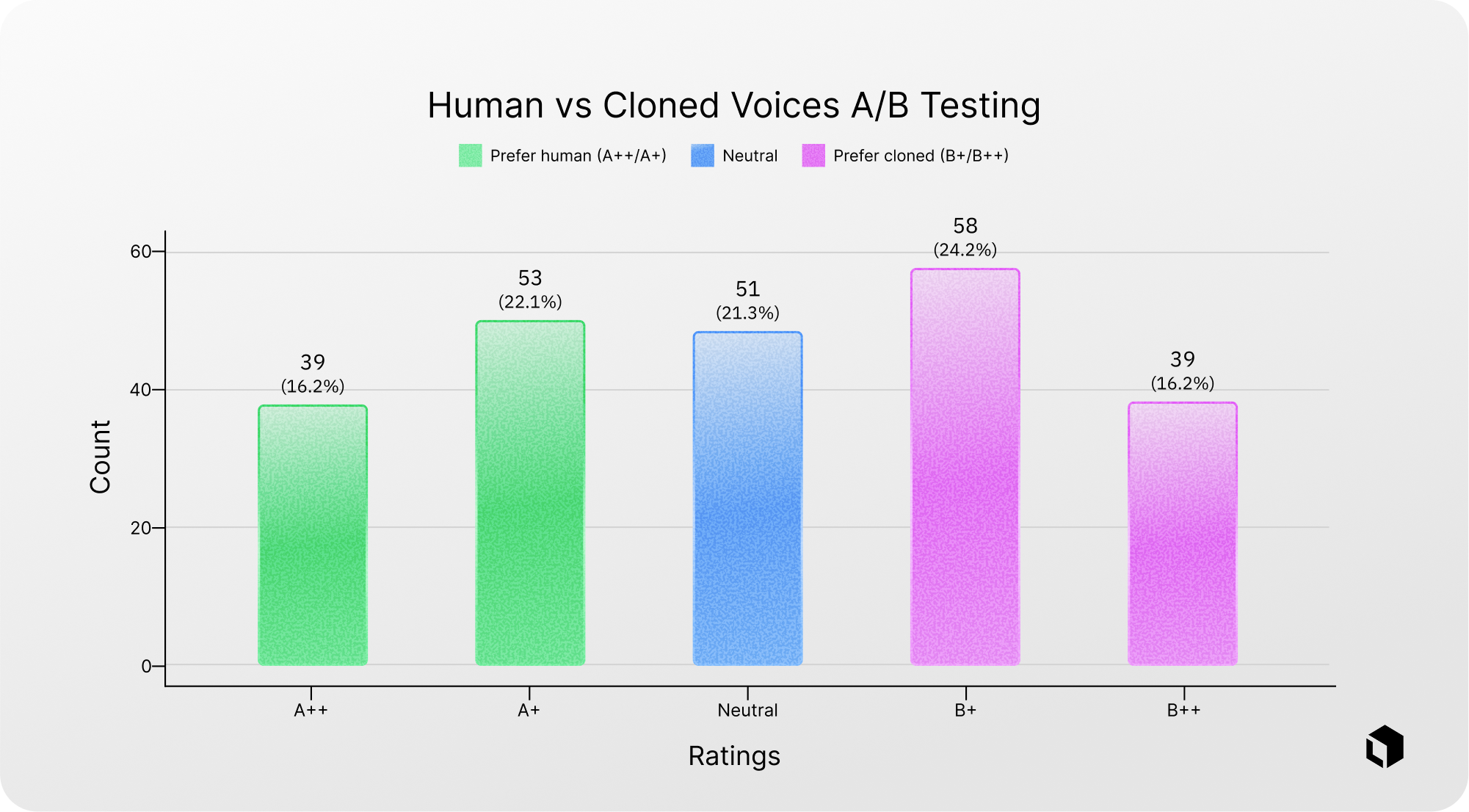
To validate that our cloned voices are a realistic proxy for human recordings, we ran a blind A/B listening study. Raters heard paired clips, one recorded by a voice actor and one produced by our cloning pipeline, without knowing which was which, and judged which sounded more human on a five-point scale (A++/A+ favor human, B+/B++ favor cloned, Neutral indicates no detectable difference).
Chart 1 summarizes the overall rating distribution: preferences are split roughly evenly between the human and cloned sides, and many judgments cluster in the “slight preference” and “neutral” bins rather than at the extremes. This pattern suggests the cloned voices are difficult to distinguish from human speech in this setting, supporting their use as a drop-in substitute for the user side of our benchmark.
What EchoChain reveals
Across evaluated models (including GPT-realtime-2025-08-28, Gemini Live-2.5-flash-native-audio, Grok Voice Agent, and Amazon Nova Sonic 2) we observe:
- Models often fail to properly integrate interruption information, even so far as ignoring the interruption entirely in some cases.
- A significant vulnerability in contemporary models is their deficiency in maintaining state persistence when subjected to input while they are still outputting.
The most common failure pattern observed was Interruption Amnesia, a phenomenon where mid-task interruptions alter the operational constraints. As a result, the model loses context and cannot comprehensively apply all necessary constraints in the following response.
The top-performing model achieved a DSR pass rate of 47.5%, suggesting that major improvements can be made in the space of handling interrupting user input.
Chart 2 is a graph showing how many failures each model had in the 3 failure classifications: contextual inertia, interruption amnesia, and objective displacement. It should be noted that Gemini Live-2.5-flash-native-audio had significantly more objective displacement failures than the other models by percentage. Amazon Nova Sonic 2 also shows an outlier ratio of failures in contextual inertia.
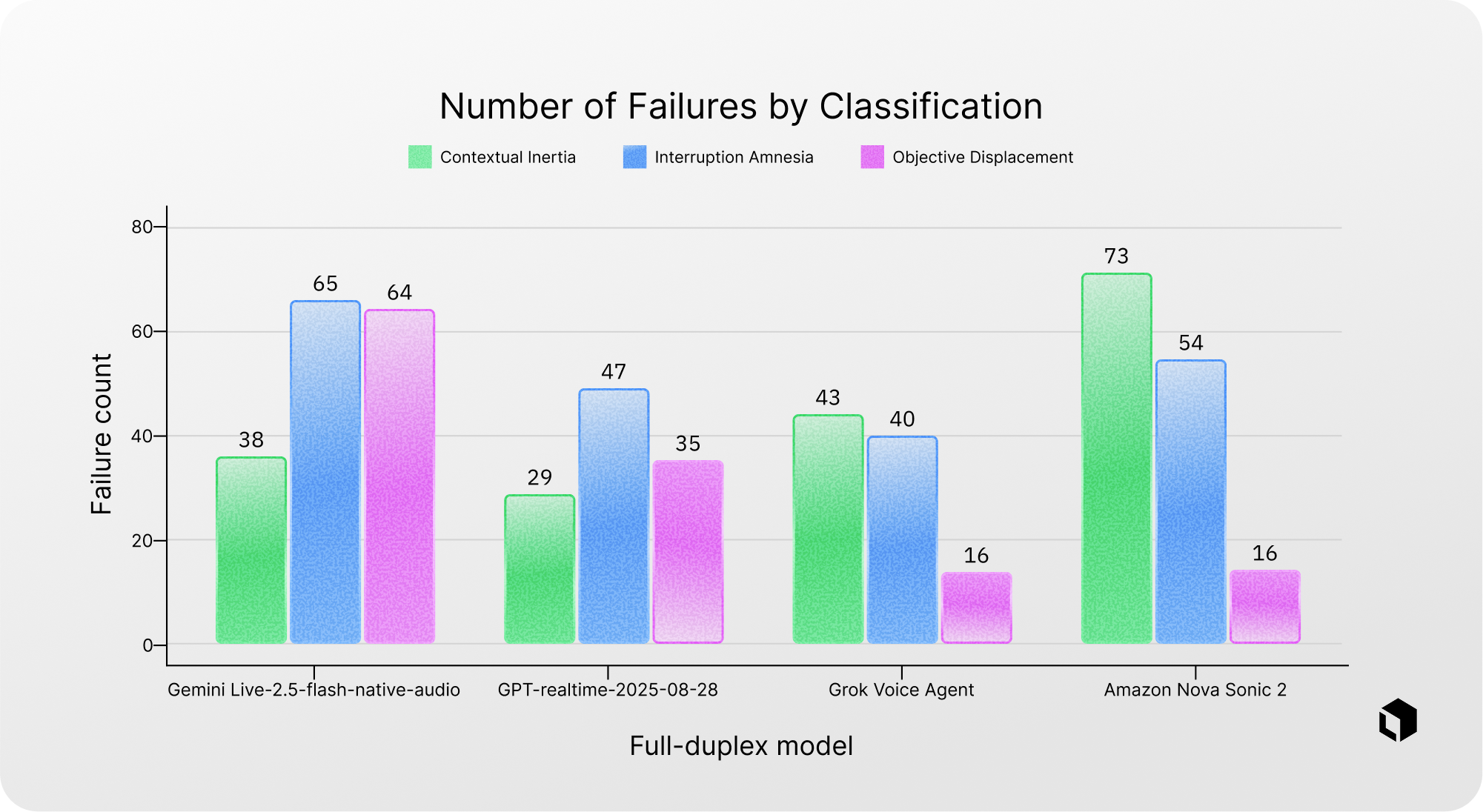
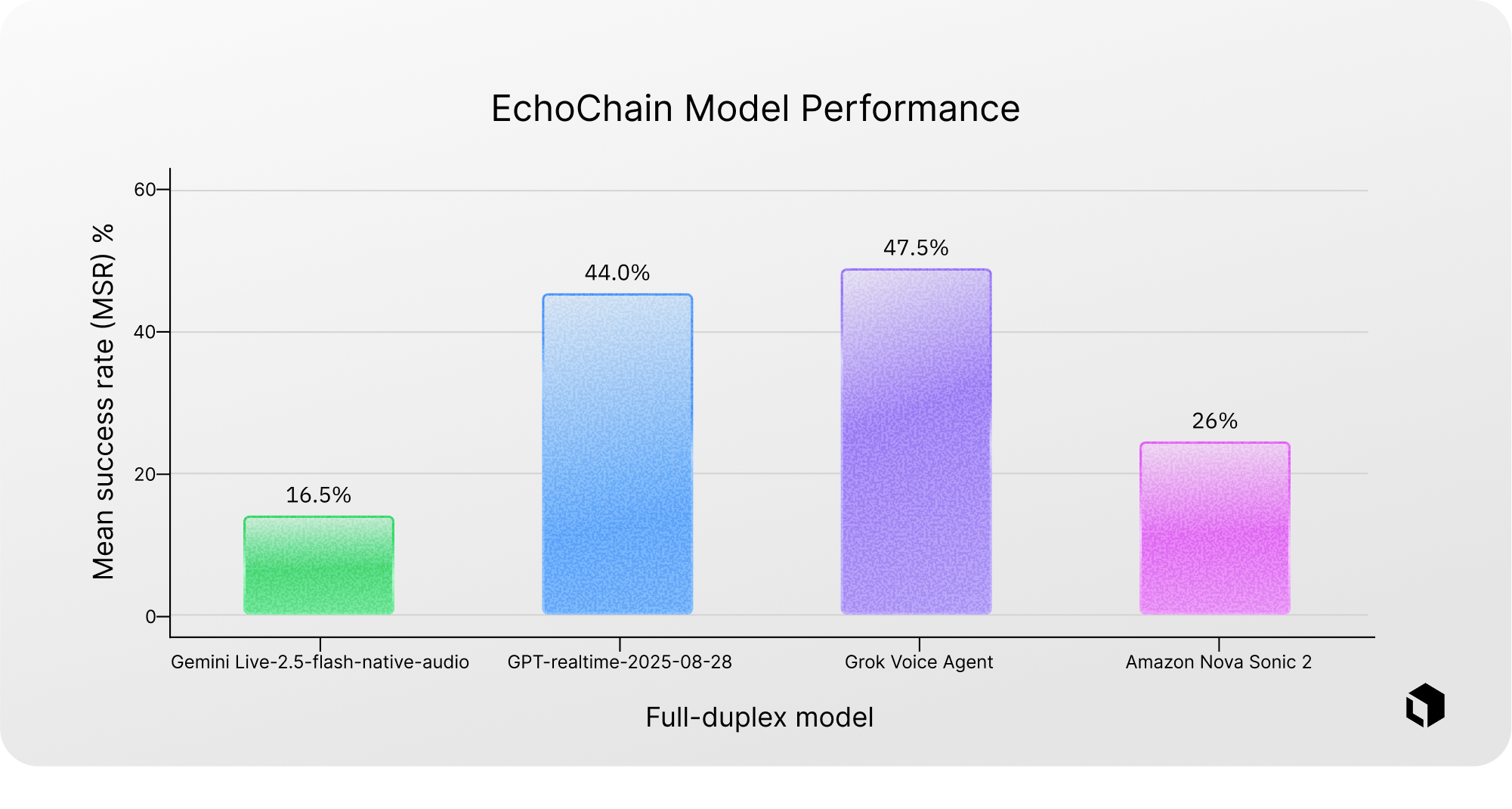
Chart 3 compares how often each model produces a successful response after an interruption in a cultivated data set of 200 rows using the EchoChain framework. Through this we see that Gemini Live-2.5-flash-native-audio passes 16.50% of the time. Above that we see Amazon Nova Sonic 2 passes 26% of the time. The top two performing models of GPT-realtime-2025-08-28 and Grok Voice Agent performed with a 44.0% and 47.5% success rate, respectively. Overall, these models perform relatively better on dual-stream reasoning under interruption, with Grok Voice Agent leading, but pass rates remain below 50%, indicating substantial headroom for improvement.
Audio sample from EchoChain. This conversation is an example of a failure of GPT-realtime-2025-08-28 in objective displacement. It also shows how a baseline conversation context is initially established before an interruption is introduced. Responses after the interruption are assessed for failures.
Why reasoning under pressure matters
As voice assistants become more capable and more autonomous, full-duplex interaction will move from a novelty to the default. People do not wait politely for a model to finish; they interrupt, correct details, and add constraints mid-response. In that world, correctness is not just “did the model produce a good final answer,” but “did it stay on track as the task changed in real time.”
For AI researchers, this exposes a distinct and under-measured failure surface: can a system reconcile prior commitments with new evidence? EchoChain is designed to isolate that capability under controlled conditions. By treating interruptions as standardized, model-agnostic interventions and ignoring floor-control competence (smooth turn-taking, latency), clearer attribution of failures to concurrent reasoning can be made.
Get in touch with us if you’d like to learn more about how we can customize EchoChain for your specific needs. Stay tuned for the full arXiv paper release.


