
 All blog posts
All blog postsLabelbox•December 13, 2024
Leaderboards: Multimodal reasoning now available & updated evaluations for image, speech and video

We’re excited to announce the latest round updates to Labelbox Leaderboards, an innovative and scientific process for ranking multimodal AI models that goes beyond conventional benchmarks. As we shared during the initial launch, we designed these leaderboards to address some of the most pressing challenges with AI model evaluation.
The Labelbox Leaderboards use expert human evaluations and a scientific approach to ranking in order to measure subjective qualities like realism and preference across multimodal reasoning, image, audio, and video models.
The leaderboard aims to offer the AI community transparency into the ranking process and is regularly updated to capture the evolving capabilities of these models, while providing detailed insights into model performance and user preferences.
Multimodal reasoning now available
The most significant update in this batch is the release of the new multimodal reasoning leaderboard that evaluates AI models based on their ability to mimic human-like understanding and decision making.

The reasoning leaderboard evaluates the best models from leading AI labs (including GPT4o, Gemini 1.5, Claude 3.5 Sonnet, Pixtral large and Llama 3.2-90b) on their abilities to conduct logical storytelling, detect differences in images, generate image captions, and perform spatial reasoning.
Updated image, speech, and video models evaluated
Labelbox’s most recent leaderboard update introduces advanced model iterations for model evaluations. For image generation, we’ve added Flux 1.1 Pro and Ideogram 2.0 models and re-run the evaluation for previous models.

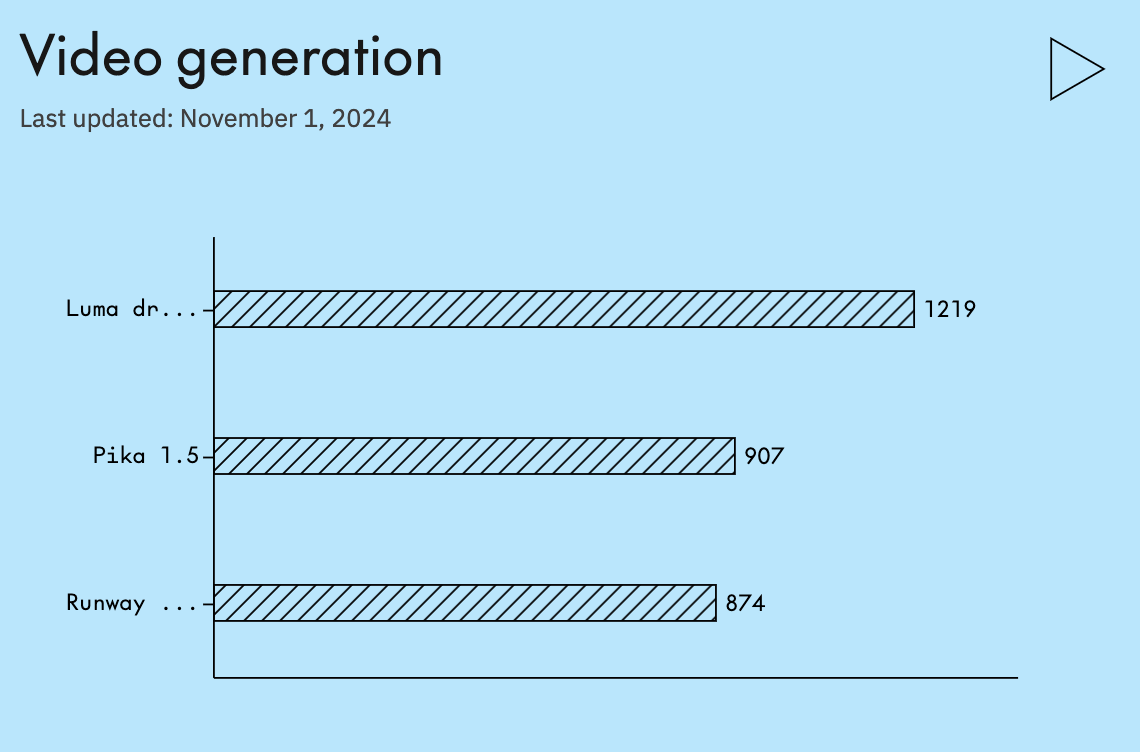
For text-to-video generation, Pika 1.5 and Luma Dream Machine have been updated. These models focus on improving realism and contextual accuracy.
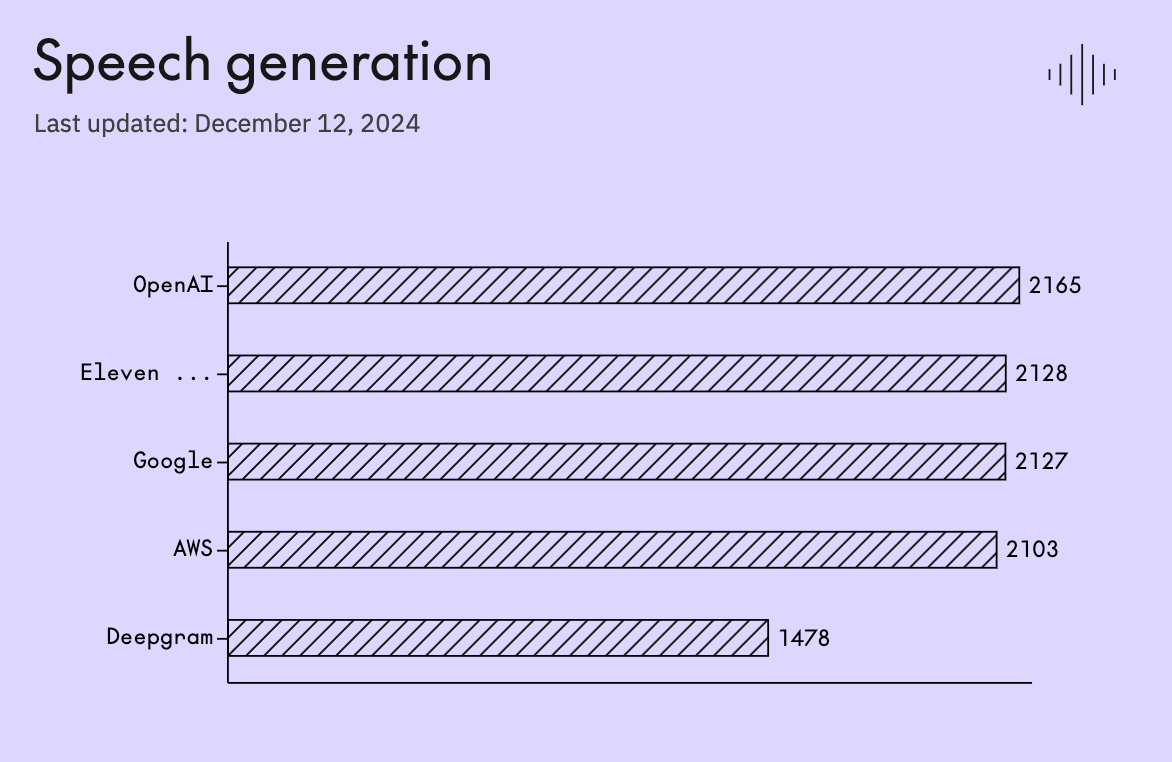
Additionally, we’ve updated our speech generation leaderboard with the latest versions of Eleven Labs, AWS, OpenAI, Google’s TTS and Deepgram. With this latest update, we’ve seen strong speech generation performance in Elo and Win % from OpenAI, ElevenLabs and Google. [Note: we are currently awaiting the latest version of Cartesia’s model and will update the leaderboard in the next study when we get access.]
Refined ranking system
Labelbox has enhanced its leaderboard ranking system with a refined Elo comparison, moving away from traditional multi-way comparisons to a more precise methodology inspired by chess rankings. Our updated Elo comparison now uses direct pairwise comparisons and win-rate calculations, starting with a 50% dataset for full comparisons. That is followed by 3-4 rounds on smaller subsets (under 25%), pairing models with similar scores. The iterative process continues until score fluctuations stabilize below 10 points, ensuring a precise and dynamic evaluation.
The new intelligent pairing system significantly reduces the cognitive load on experts who previously had to juggle 4-5 way comparisons simultaneously. The new system also produces more refined assessments. These updates elevate the accuracy and adaptability of model assessments for real-world applications.
Check out the latest leaderboards and get in touch
With this round of updates, we aim to advance AI evaluation by using expert human feedback and comprehensive metrics to assess subjective generative AI models. Stay tuned for further updates in the coming months.
We invite you to explore the leaderboards and to check out all of our latest evaluations across AI modalities and applications. If you’d like to evaluate your model as part of the next leaderboard update, contact us here.


