
 All blog posts
All blog postsLabelbox•October 29, 2021
You’re probably doing data discovery wrong

Building an efficient and intuitive data pipeline for developing AI systems has never been a simple task but the ability to quickly and easily search for data has continued to be a significant obstacle for machine learning (ML) operations teams.
Labeled data is the foundation of your AI system, but is one of the hardest assets to store, evaluate, and visualize efficiently. Even best-in-class ML teams historically haven’t had a perfect solution for interacting with their unstructured and structured data.
After speaking with countless teams that rely on patchworks of open source, homegrown, and paid solutions just to manage and interact with their data, we’ve identified the three areas companies building AI most want to improve when it comes to data discovery and classification. Improvement in these three areas will help tremendously in speeding up the iteration cycles associated with improving your model as well as making your entire workflow more efficient.
Consolidate your unstructured, distributed data
ML teams that store and interact with all of their unstructured data and associated metadata in one place can spend more time improving model performance and less time managing distributed data. Most ML teams want to leverage data from across their broader organization for testing and training their models.
While the ML team may be responsible for building the data pipeline, the data itself often belongs to other teams and products in the organization and is serving its own purpose unrelated to the ML product. Since blob storage like AWS and GCP is effectively infinitely scalable and available at a relatively low commodity price, the depth and breadth of these distributed data stores can get unwieldy very quickly.
At complex organizations and large enterprises, this means ML teams are often responsible for accessing data from multiple data stores and need to run complex join operations to connect metadata and break down silos. This leads to slower iteration velocity and project delays related to managing and finding data.
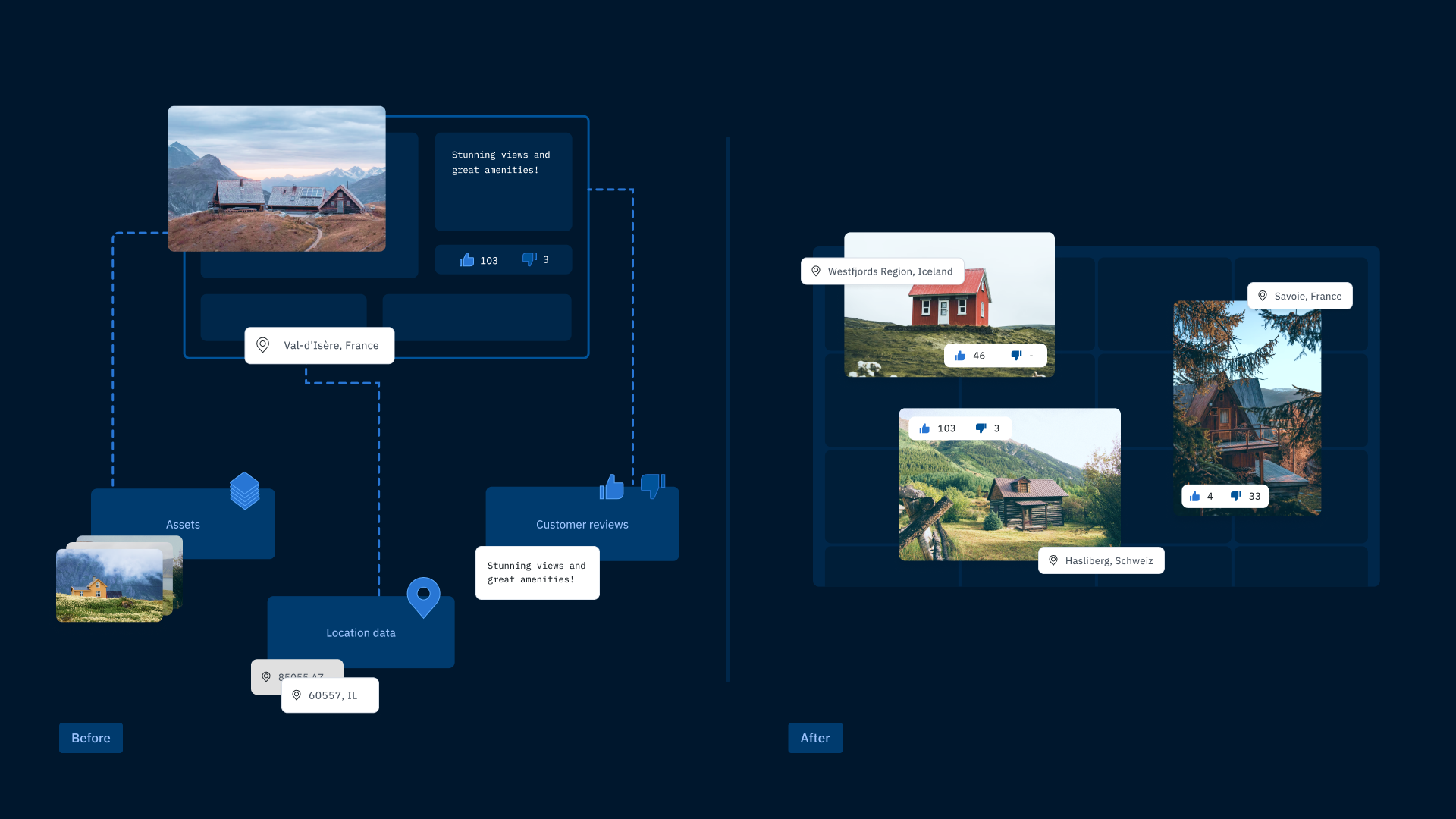
With a consolidated database for teams to query their data and related metadata in one place, teams will not only be able to find the right data faster, but they’ll have a better understanding of the scope of data that’s available to them for building ML products. While building a centralized database is more effective than finding and managing data one database at a time, it’s time intensive to build and maintain, and still limited in its ability to visualize labeled or unlabeled data in an intuitive, purpose-built way.
Search for data without using code
Teams want to quickly and confidently answer the question of “what kind of data do we have?” to facilitate faster iteration and better collaboration. Too often, ML engineers need to write one-off queries to find data, whether it’s labeled or unlabeled. This process bottleneck can get in the way of team collaboration and is an inefficient use of ML engineer resources.
Finding the right data, whether it’s a handful of images to illustrate the complexity of a real-world edge case or gathering a batch of data to send to a labeling project, shouldn’t require writing custom scripts or joining columns in different databases.
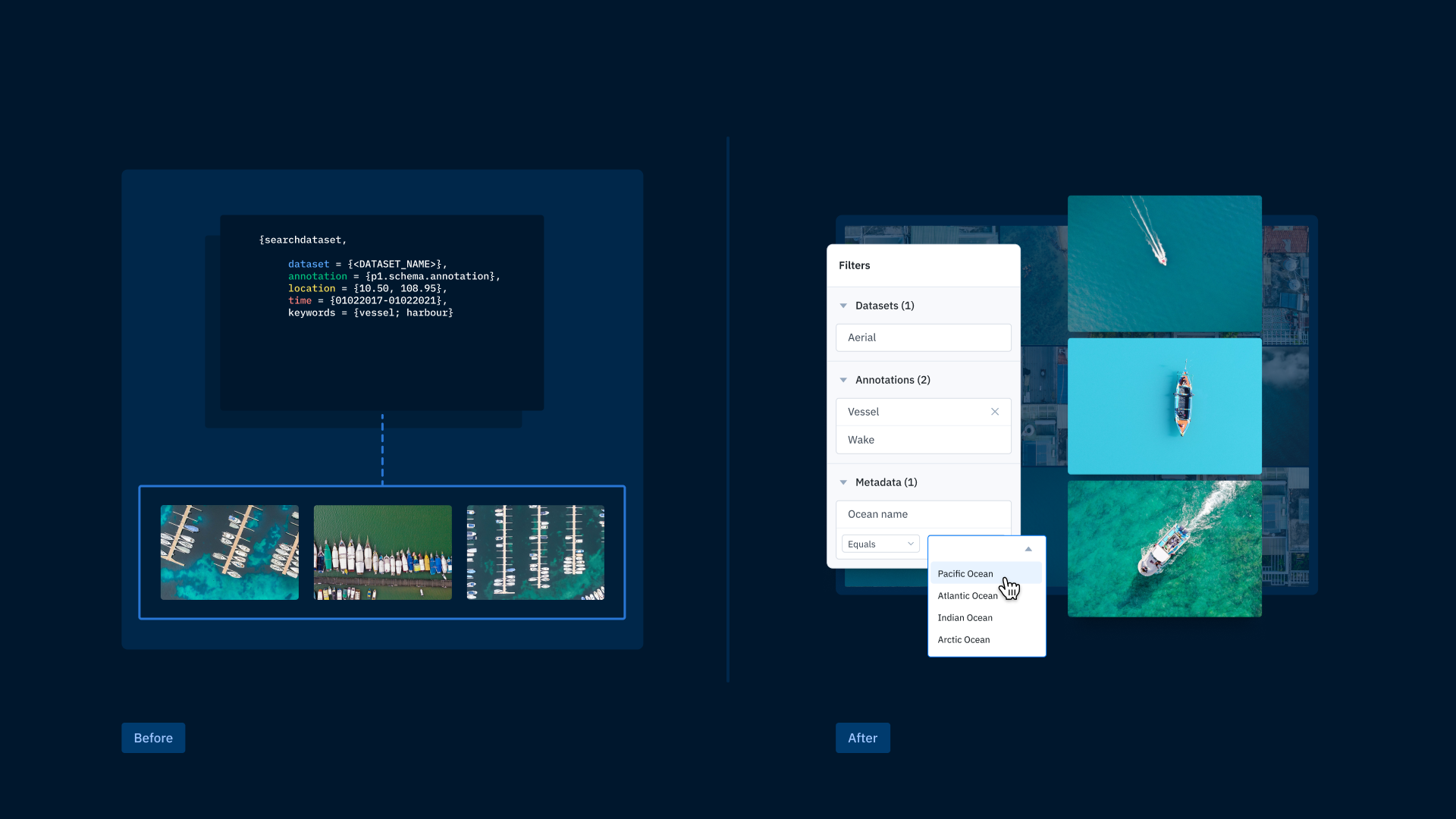
It’s important that all team members, whether they’re ML engineers, product managers, or in labeling operations, have the tools they need to find and prioritize data. Some teams accomplish this by building image services on top of their homegrown databases so teammates can find data and related metadata without code. This can be an effective solution if done correctly, but it needs to be maintained and updated as your data evolves and expands. Adopting a flexible and scalable code-free search is ultimately going to be a faster, more powerful solution.
Visualize labeled data to better understand model performance
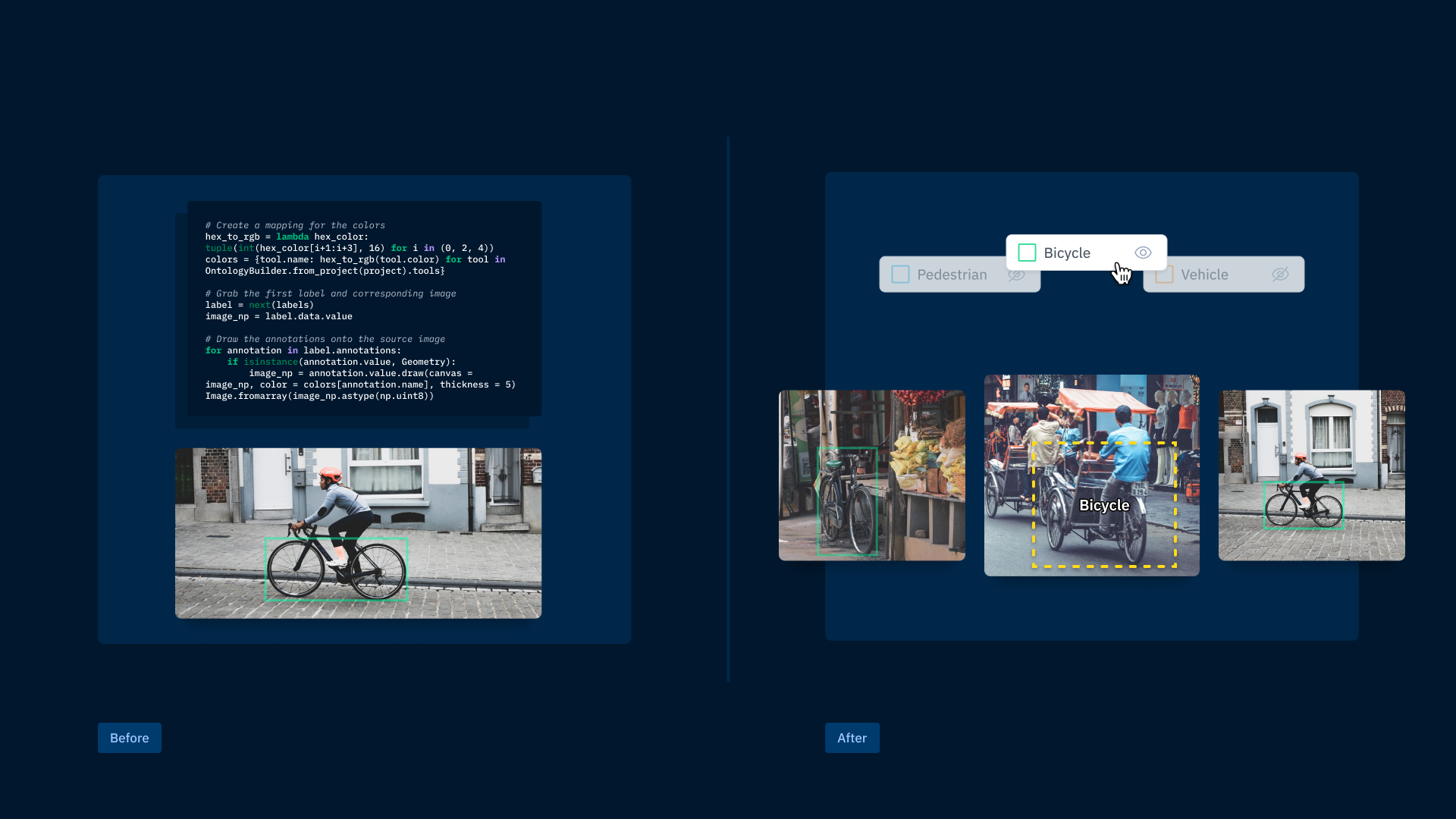
Being able to quickly visualize labeled data is an essential part of understanding and improving model performance. Whether a piece of data is labeled by hand or machine, you need to be able to reliably and simply visualize it without code so you can better understand how your training data impacts model performance. Looking only at metrics like precision and recall or IoU tells a valuable but incomplete story, and visualizing a representative distribution of labeled data is incredibly challenging when you have to rely on querying data and overlaying annotations in notebooks. Quickly visualizing labeled data is an important step in understanding the complexity of your real-world data and model performance.
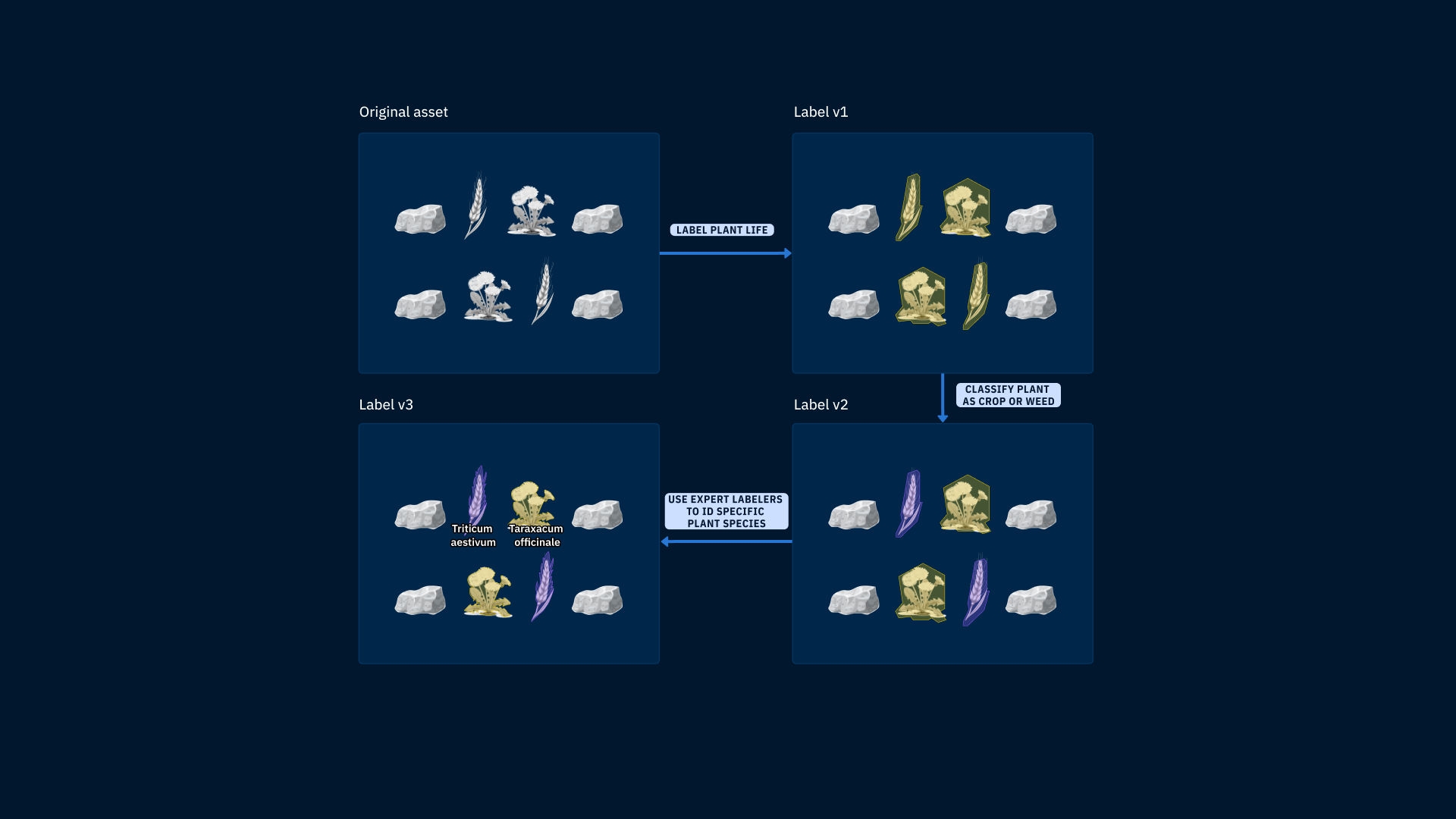
To add another layer of complexity, ML teams often create multiple labels for a single asset. Whether they’re labeled multiple times with iterative models, or as part of a multi-step workflow, it’s crucial to be able to tie these labels back to the same asset and visualize them in one place. For example, to build a product that identifies species of plants, an ML team might build a multi-step workflow to improve efficiency and use expert labeler time effectively. Each of the following steps in this scenario could generate a new label, and it’s essential to be able to visualize each iteration of the label in connection with the original asset in one place.
While homegrown databases may be able to aggregate and search across your labeled data, they often fall short when it comes to being able to visualize the assets and their labels. Teams often have to rely on manually loading labels into notebooks for inspection which is neither scalable nor discoverable by less technical teammates. Without being able to quickly and easily visualize labeled data, teams are left in the dark and need to apply more time and effort to understand the nuances of their labeling pipeline.
Keep your data at your fingertips
Hearing regular feedback on the frustrations and needs listed above is what led us to build Catalog as the central hub of Labelbox. Securely connect Catalog to your storage providers so you can search and filter through all of your data in one place. Labelbox supports integrating with AWS S3, GCP, or Azure buckets with native Identity and Access Management (IAM). Once in Catalog, find unlabeled and labeled data with intuitive UI filters like annotation class, dataset, metadata, and more. Quickly visualize all your data in gallery view and see additional attributes and associated labels in the detailed carousel view. Put simply, see every detail of your data in one place.
Final thoughts on unstructured and structured data discovery tools
Improving each of the three elements noted here will lead to a far more efficient process and allow data scientists to focus on core training data issues instead of building scripts and searching for relevant data. If you want to learn more about how Catalog can help your team, just sign up for a demo here.


