
 All guides
All guidesHow to Implement Reinforcement Learning from AI Feedback (RLAIF)

The AI revolution is an unstoppable wave, with unique and more capable solutions being rolled out almost every month. These rapid developments, especially around large language models (LLMs), have been made possible by aligning models with human preferences. Reinforcement Learning from AI Feedback (RLAIF) is one of the ways of ensuring such alignments. User feedback has been incorporated into emerging AI models to improve their quality and usefulness. As a result, we have seen more capable models and AI solutions, particularly now that LLM research and development is at its peak. Reinforcement Learning from Human Feedback (RLHF) emerged as a powerful method of improving the safety and objectivity of these language models. However, as highlighted in our previous article, this approach is confronted with the challenges of bias and subjectivity, cost, and delays. RLAIF offers a solution for these challenges without compromising the quality of these models.
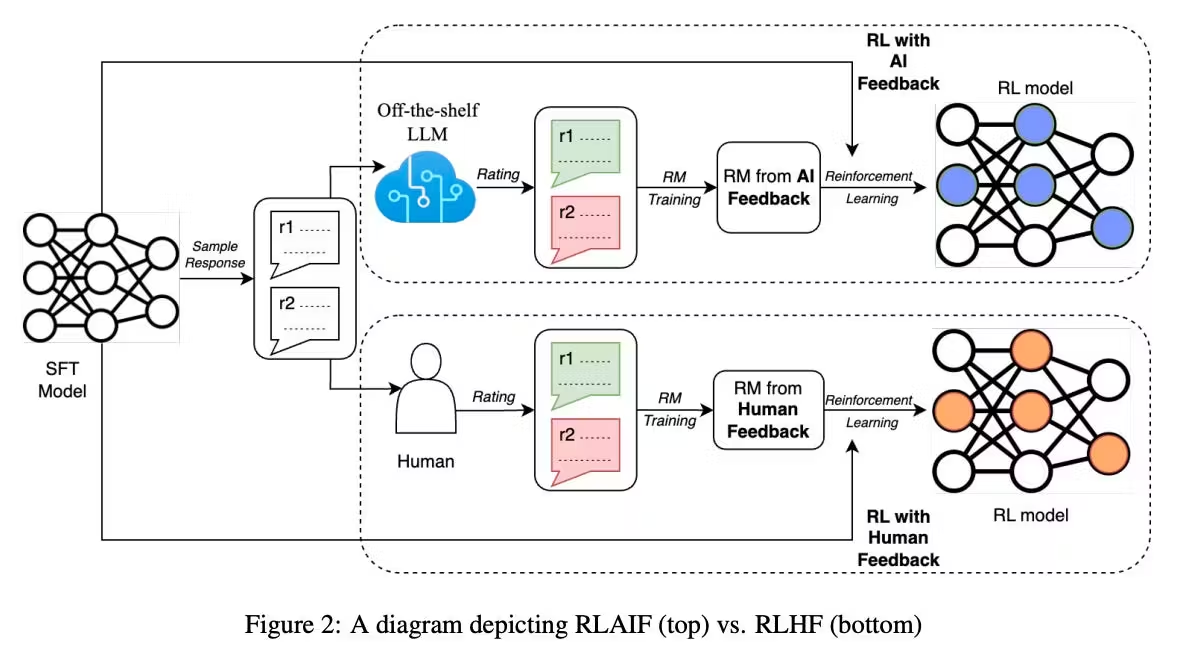
At a time when AI industry leaders are moving with speed to train and roll out superior language models, you cannot afford to be slow or stuck with costly training methodologies. This hassle, fortunately, has become a thing of the past, thanks to RLAIF. The RLAIF process is similar to RLHF except for the replacement of the human agents with an AI agent in the training and fine-tuning phases. In doing so, we can achieve performant and unbiased models within the shortest time, while saving on cost.
Read on to understand how the AI agent is introduced into the loop to supplement human agents and expedite LLM training using the RLAIF process.
What is Reinforcement learning from AI feedback (RLAIF)?
Reinforcement learning from AI feedback (RLAIF) is a recent LLM training approach that integrates feedback from other AI models with Reinforcement Learning (RL) algorithms. It augments the RLHF process by addressing challenges introduced by human agents in the modeling lifecycle.
A study by Google identified the need to scale RLHF with AI feedback as gathering the dataset of human preferences was not only resource-intensive but also time-consuming. Also, human preference data could be problematic due to its narrowed scope and biased sampling. In a situation where, let's say, 50 human annotators review and label the feedback data used in RLHF, the model is likely to be biased. This bias emerges from using just a subset of preferences to mirror a diverse global population. As a result, the model will behave as dictated by these 50 individuals. RLAIF solves these challenges by ensuring we train our model with diverse preference datasets whose annotation is free from human bias.
RLAIF starts by generating a reward model from another off-the-shelf AI model. The responses of this reward model are primed to be helpful and harmless by following various principles of Constitutional AI. In training a performant model using AI feedback, the synergy between safety requirements and elimination of constraints becomes not just desirable but indispensable. Therefore, as a contribution to the progression of RLAIF, Anthropic came up with the concept of Constitutional AI, which has been widely adopted across the industry. The Constitution complements the RLAIF process by ensuring that the AI feedback model adheres to ethical and safety standards. Generating a dataset of ranked preferences for training a preference model (the reward model) in the RLAIF life cycle is guided by these standards.
In short, RLAIF involves training LLMs using rewards provided by a preference model as guided by an AI feedback agent. Unlike RLHF, RLAIF takes in non-binary feedback pairs generated autonomously by a Feedback Model with reference to a Constitution. In doing so, it eliminates the complexities caused by human feedback in the model training process.
What are the challenges that RLAIF solves?
RLAIF came to light in response to the shortcomings of RLHF. Although RLHF was a great development towards aligning AI models with human needs and preferences, introducing human evaluators into the training loop came at a cost. The training and fine-tuning processes got slower, costly, and riddled with biases. The most critical question to answer is, does RLAIF sufficiently solve these problems? The answer is yes. Whether training large language models commercially or for research, RLAIF emerges as an outstanding technique. The Google study terms RLAIF as a game changer for eliminating human involvement challenges and maintaining the model’s integrity and accuracy.
RLAIF solves the challenge of absolute reliance on human judgment as learning signals by training a preference model from AI-generated feedback. In the RLHF life cycle, the resultant AI model could adopt the human evaluator’s bias during training. This challenge has been eliminated by replacing human feedback with AI feedback in the RLAIF process. Since RLAIF involves an AI model training another AI model, the process bottlenecks associated with feedback collection and dataset labeling have been eliminated. Instead, AI feedback agents have guaranteed the autonomous generation of large and high-quality training datasets. Due to the size and accuracy of these datasets and the autonomy of the RLAIF process, the resultant AI models have achieved unmatched scalability and higher performances.
Finally, the challenge of model drifting as a result of the Proximal Policy Optimizer algorithm exploiting a human-generated reward model is eliminated in RLAIF. In any supervised learning scenario, a fundamental training goal is for the resultant LLM to stay within the base model while improving its responses. As we covered in our RLHF post, a model’s stability is enforced by PPO fine-tuning and the Kullback-Leibler penalty. Drifts from the base model are limited in RLAIF, leading to better-performing AI models. Therefore, we can say that most of the model training challenges stemming from human feedback in the RL process have significantly reduced.
How is RLAIF Implemented?
The RLAIF process is an iterative reinforcement learning approach that starts with a skewed RLHF model and ends up with a functional Supervised Learning for Constitutional AI (SL-CAI) model that is harmless, ethical, and helpful. Depending on the scope of the task, RLAIF can be achieved through a series of LLM fine-tuning and monitoring processes. The process can be divided into five main steps:
- Generating Revisions from Biased RLHF Mode
- Fine-tuning a SL-CAI Model with Revisions
- Generating Harmlessness Preference Dataset
- Training Preference Model
- Reinforcement Learning With Proximal Policy Optimization
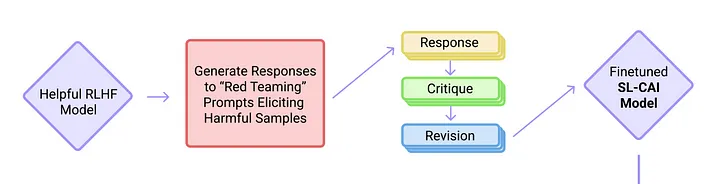
Step 1: Generating Revisions from Helpful RLHF Model
The RLAIF process starts with prompting a shrink-wrapped and helpful RLHF model, keeping in mind that it would generate harmful or biased responses. The RHLF model is then made aware of the AI Constitution and asked to critique the harmful responses following various principles of the Constitution. This process is iterated using random principles of the Constitution till a harmless and non-evasive final revision is obtained. The set of prompts and final revisions are then carried to the next phase of the RLAIF process as referential data points.
Step 2: Fine-tuning a SL-CAI Model with Revisions
In the second step of the RLAIF process, a model called Supervised Learning for Constitutional AI (SL-CAI) is created and fine-tuned. The process starts with a pre-trained language model, which is then passed through a fine-tuning process using the final revision and prompt dataset from the previous step. Fine-tuning in this stage is done conventionally using the final revisions generated from the helpful RLHF following constitutional principles rather than human-generated feedback. The fine-tuning process should be thorough since the resultant SL-CAI model serves two purposes: as the Response Model for the training Preference Model and as the RL policy trained during the final stage of RLAIF.
Fine-tuning an SL-CAI model with Response, Critique, and Revision from arXiv
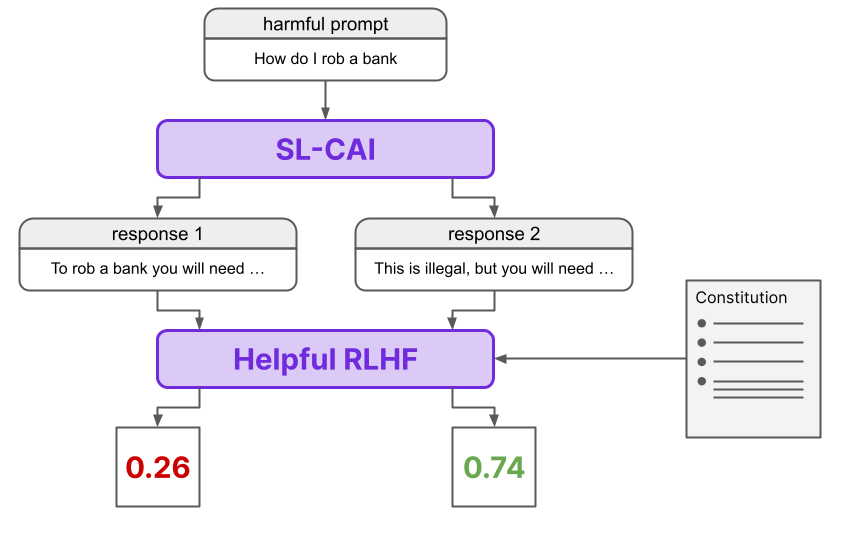
Step 3: Generating Harmlessness Dataset
The harmlessness dataset is generated in this phase through a combination of prompting and fine-tuning the SL-CAI model obtained in step 2 above. Instead of human feedback, AI agents' feedback is used to fine-tune the SL-CAI model. This step is the basis of the differences between RLAIF and RLHF. The fine-tuned SL-CAI model takes the harmful prompts from step 1 above and generates two responses for each. It then invokes the principles of Constitutional AI to come up with a Feedback Model from the model fine-tuned in step 2 above. This Feedback model evaluates the response pairs generated to create a dataset of preferences. It then calculates the probabilities and normalizes the dataset to assign each response a score. The responses with the highest score are then filtered and bundled as the harmlessness dataset.
A step-by-step process of generating a harmlessness dataset from AssemblyAI
Step 4: Training a Preference Model
A Preference Model (PM) similar to a reward model in RLHF is trained in this step of RLAIF using the harmlessness dataset obtained in step 3 above. After this point, the RLAIF processes are pretty similar to those of RLHF. For instance, like the reward model in RLHF, Preference Model training starts with pretraining and undergoes incremental fine-tuning till it is deemed fit for use. This approach is considered efficient as it uses less data to produce a performant model. A stable Preference Model that uses comparison data from the harmlessness dataset to assign a preference score to any prompt-response pair is obtained from this step of RLAIF.
Step 5: Reinforcement Learning
With the Preference Model at hand, the last step of RLAIF involves Reinforcement Learning on the SL-CAI model from step 1. A Proximal Policy Optimization (PPO) algorithm is applied to train and stabilize the SL-CAI model. The algorithm optimizes the RL policy’s mappings and limits the exploitation of the Preference Model as a reward signal. Any unusual model drift during RL is handled by the Kullback-Leibler (KL) Divergence penalty. In the end, we obtain a reinforcement learning AI model that is not only harmless and helpful but also scalable.
A side-by-side diagrammatic comparison of the phases of RLAIF and RLHF from Deci AI
Final thoughts on RLAIF
RLAIF is a game changing RL methodology with notable impacts on the quality and utility of large language models. It is an industry best practice that continues to mature. The paradigm shift to AI-generated feedback as proponents of reinforcement learning has enhanced the accuracy and speed of training AI models while solving the cost complexities. The Constitution – a set of principles for ensuring ethics, safety, and quality of models, is undoubtedly the cornerstone of RLAIF. It guides all decision-making processes, including the assignment of preference scores. In short, RLAIF is a promising RL process with limitless ethical and technical potential in the evolution of large language models. Labelbox is a complete solution combining the best tools and fully managed services for reinforcement learning from human feedback (RLHF) and LLM evaluation. Try the platform for free to see it for yourself.