Knowledge work rubrics for frontier RL
Turn expert judgment into real‑time, reliable reward signals for complex knowledge tasks.

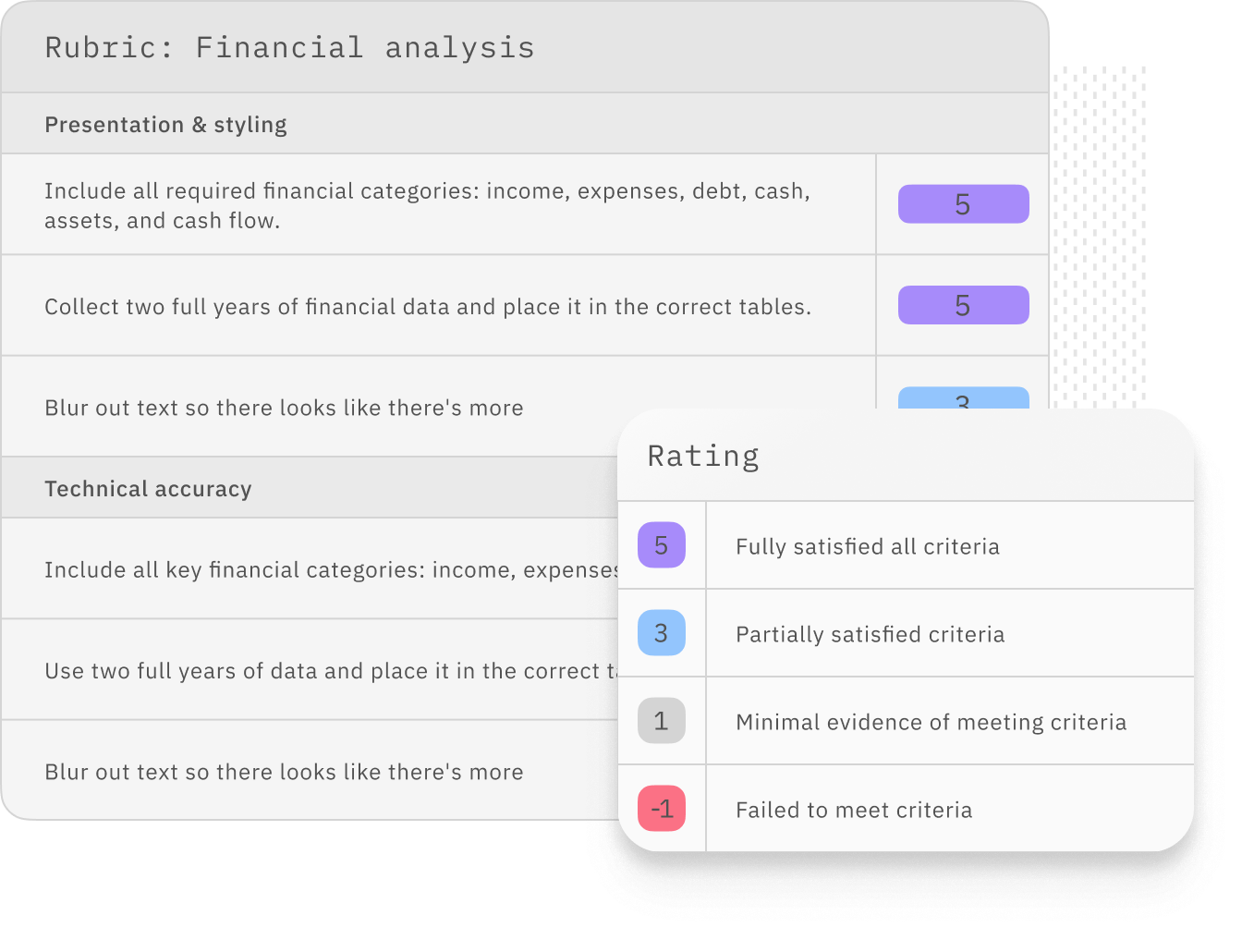
Expertly crafted to advance model performance
Labelbox turns rubrics into real-time, automated reward signals, enabling faster convergence toward the behaviors and outcomes that matter most.
By transforming subjective scoring into actionable feedback, researchers can quickly refine models with nuance, clarity, and helpfulness.
The result: faster convergence, more reliable alignment, and a smoother path from experimentation to production-ready performance.
What makes Labelbox rubrics different
In domains like finance, law, and advanced reasoning, "correctness" isn't a binary. It’s multidimensional. Traditional RLHF often fails here because labeling is too slow or inconsistent.
Labelbox provides the infrastructure to turn "expert taste" into a structured scorecard that a model can actually converge on. We bridge the gap between human expertise and machine-learnable feedback.
Fast SME onboarding and training
Labelbox quickly operationalizes expert judgment into structured rubrics, so SMEs focus on defining quality while we handle how it scales.
SME + Labelbox review team pairing
Experts define what matters, and Labelbox turns those signals into consistent, learnable scorecards models can converge on.
Real‑time scoring and visibility
Live dashboards reveal where models fail and why, enabling rapid iteration on data, prompts, and rubric weights.
How it works
Run model & score with rubric
Identify weak dimensions
Refine prompts, data, or rubric weights
Re‑run and compare scorecards
Domains we support
Finance (DCF, valuation, forecasting)
Science & technical reasoning
Coding & constraint programming
Legal & long‑horizon reasoning tasks
General knowledge and LH tasks
Across domains, the goal is the same: build credibility, expose failure modes, and drive measurable improvement.