Large language models
Accelerate innovation and time to value with LLMs
Large Language Model (LLM) systems require adequate context to effectively enrich data and automate data tasks. Use Labelbox to generate human preference datasets, integrate with fine-tuning APIs from leading model providers & hubs, and validate outcomes with human experts.

Advancing state-of-the-art LLM products from leading enterprises





Customer spotlight
How Dialpad advances AI development in NLP and LLMs with Labelbox
Dialpad, a leading AI-powered customer intelligence platform company used fine-tuning to build a powerful LLM over five years via five billion minutes of business conversations. The model offers out of the box capabilities to businesses to accurately summarize business calls, extract important insights and offer in-the-moment coaching to sellers and customer reps. Advanced discovery, curation, and annotation capabilities were crucial for building high-quality training datasets. Human evaluation was also critical to ensure quality outcomes before the system was turned live. Labelbox enabled this organization to accelerate the creation of the LLM by 75% through rich, integrated capabilities for data preparation and human evaluation.

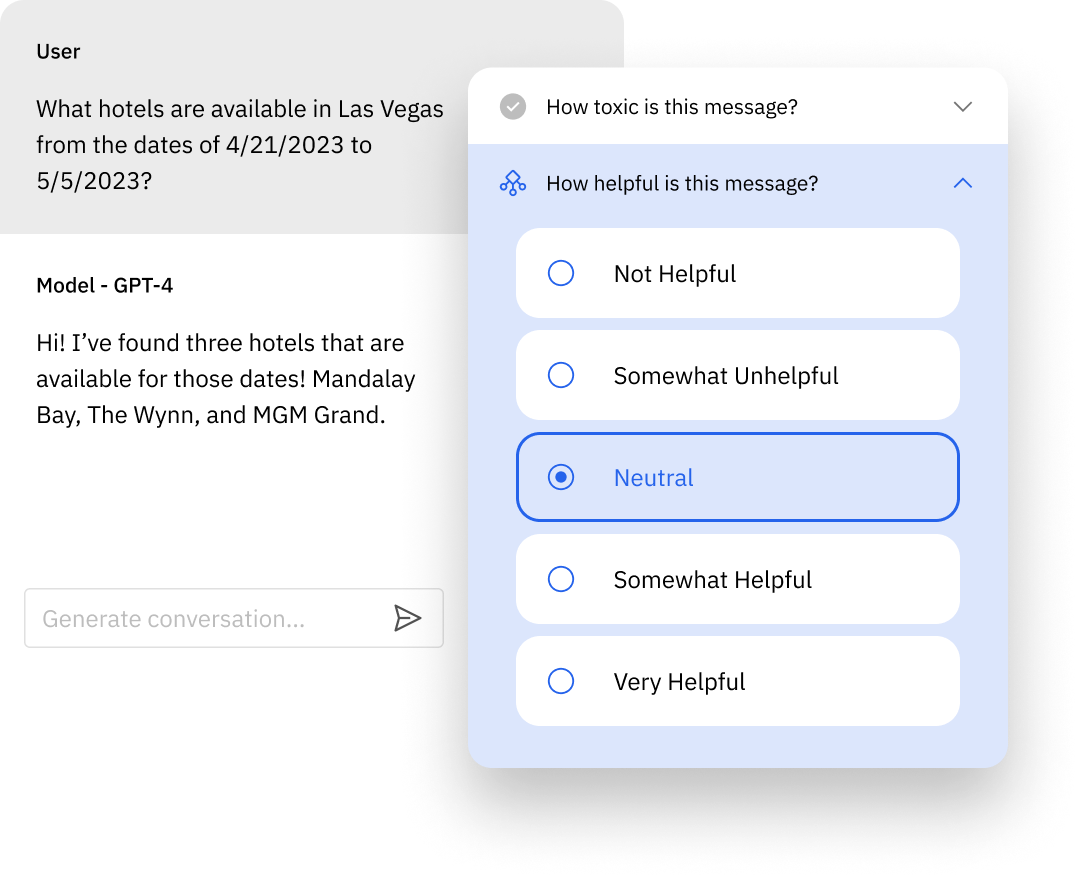
Ship LLMs confidently with human-centric evaluation
Empower human experts to validate model outcomes with advanced capabilities for benchmarking, ranking, selection, NER, and classification.
Evaluate pre-recorded and live chats with support for multi-turn conversations.
Generate high-quality data for alignment
Ensure helpful, trustworthy, safe outputs with highly accurate datasets for instruction tuning, RLHF, and supervised fine-tuning.
Curate, annotate, and ready datasets with the best of human and AI-assisted data preparation.

Prioritize the right user feedback to improve LLMs
Zero in on feedback and cases that matter with powerful curation and discovery capabilities. Support for native vector search and similarity searches.

Fine-tune LLMs with integrations to leading model providers
Access leading models from OpenAI, Cohere, and Anthropic, as well as top open source models, from within the platform for streamlined fine-tuning flows.
Integrations with Vertex AI, Databricks, and other leading MLOps pipelines so you can launch fine-tuning jobs from within Labelbox.
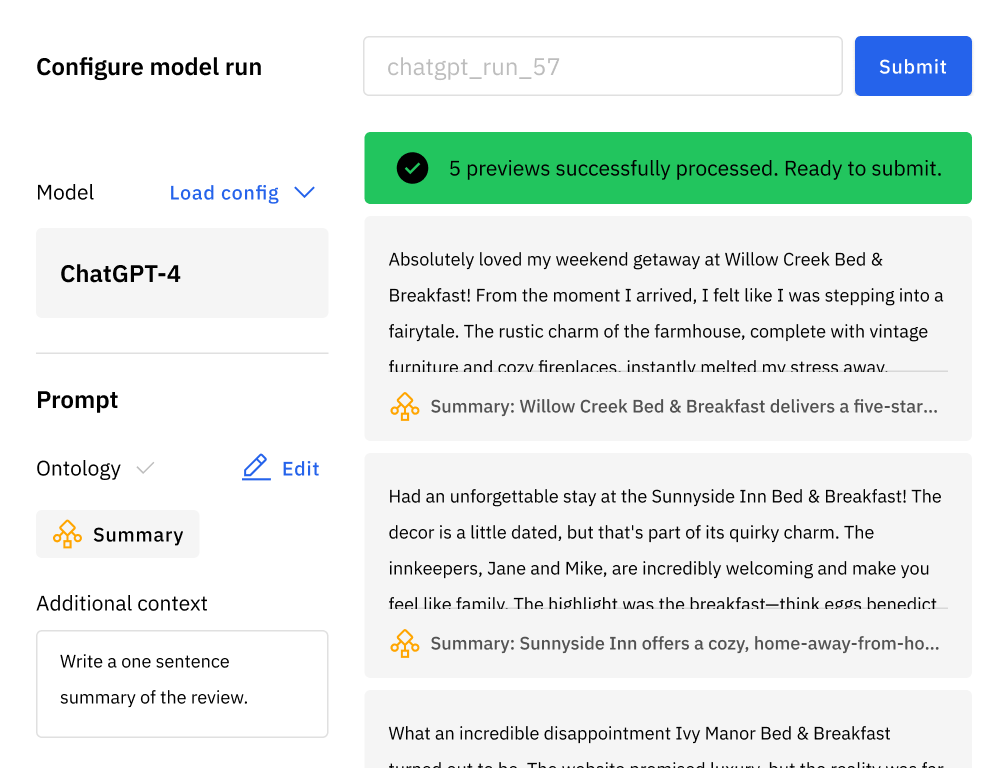
Enrich your data and automate common tasks with LLMs
Automate data labeling and augmentation tasks with Model Foundry. No-code data enrichment with leading closed-source and open-source LLMs at a fraction of the time and cost.