
 All blog posts
All blog postsLabelbox•March 28, 2023
Upload custom embeddings to find similar data, a new way to label video data, and more.
This month, we released several updates that help you explore and organize your data, label faster than ever, and quickly identify model errors. You can now upload custom embeddings, label video data with step interpolation over linear interpolation, simplify your workflow with SDK improvements, and send model predictions as pre-labels to your labeling project. Read on to learn more about the latest improvements to help you iteratively interact with your data and build better models.

Upload custom embeddings to surface high-impact data
An embedding is a technique used to represent data, such as words or images, as vectors of numerical values in a high-dimensional space. Embeddings can make data exploration easier and can help you quickly surface similar data of interest.
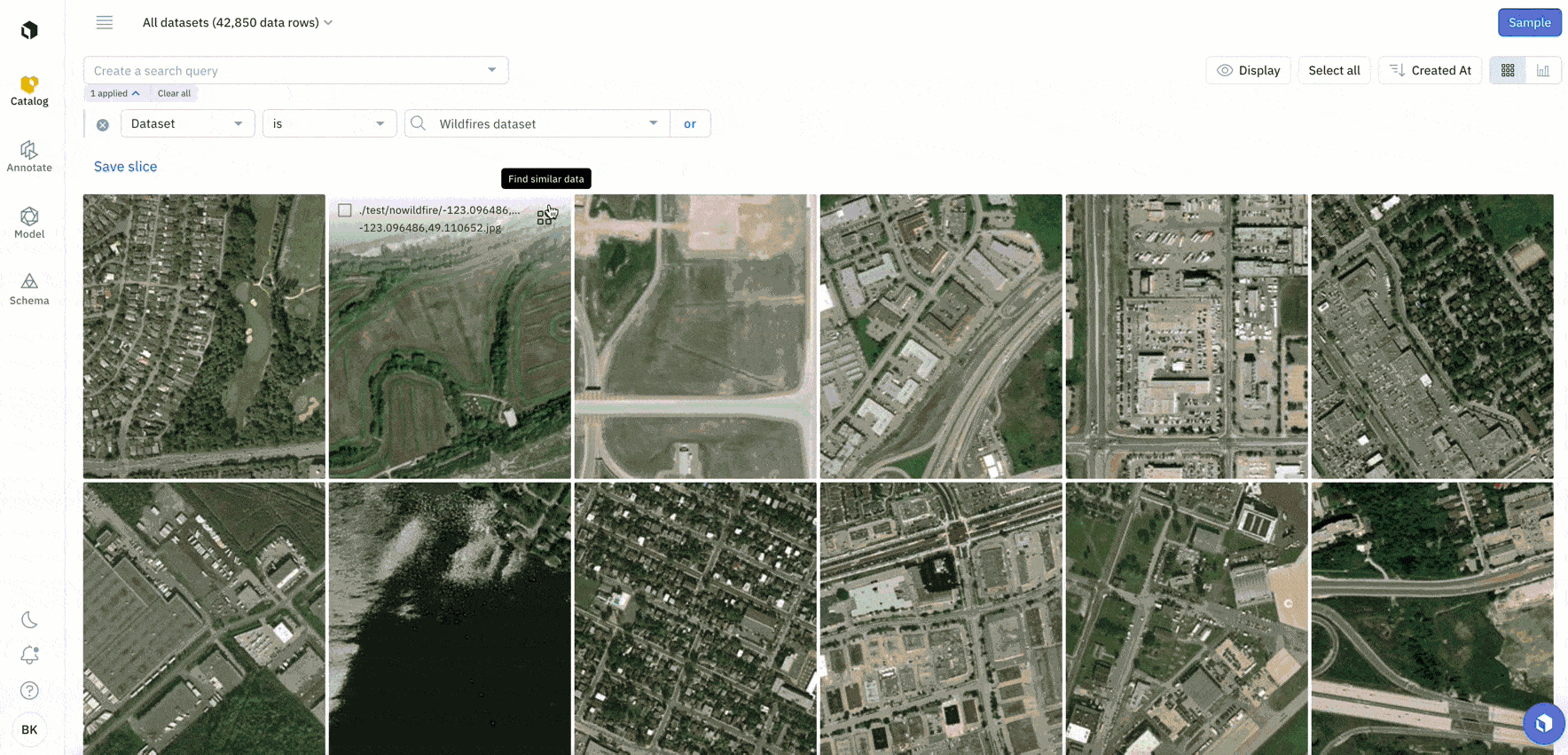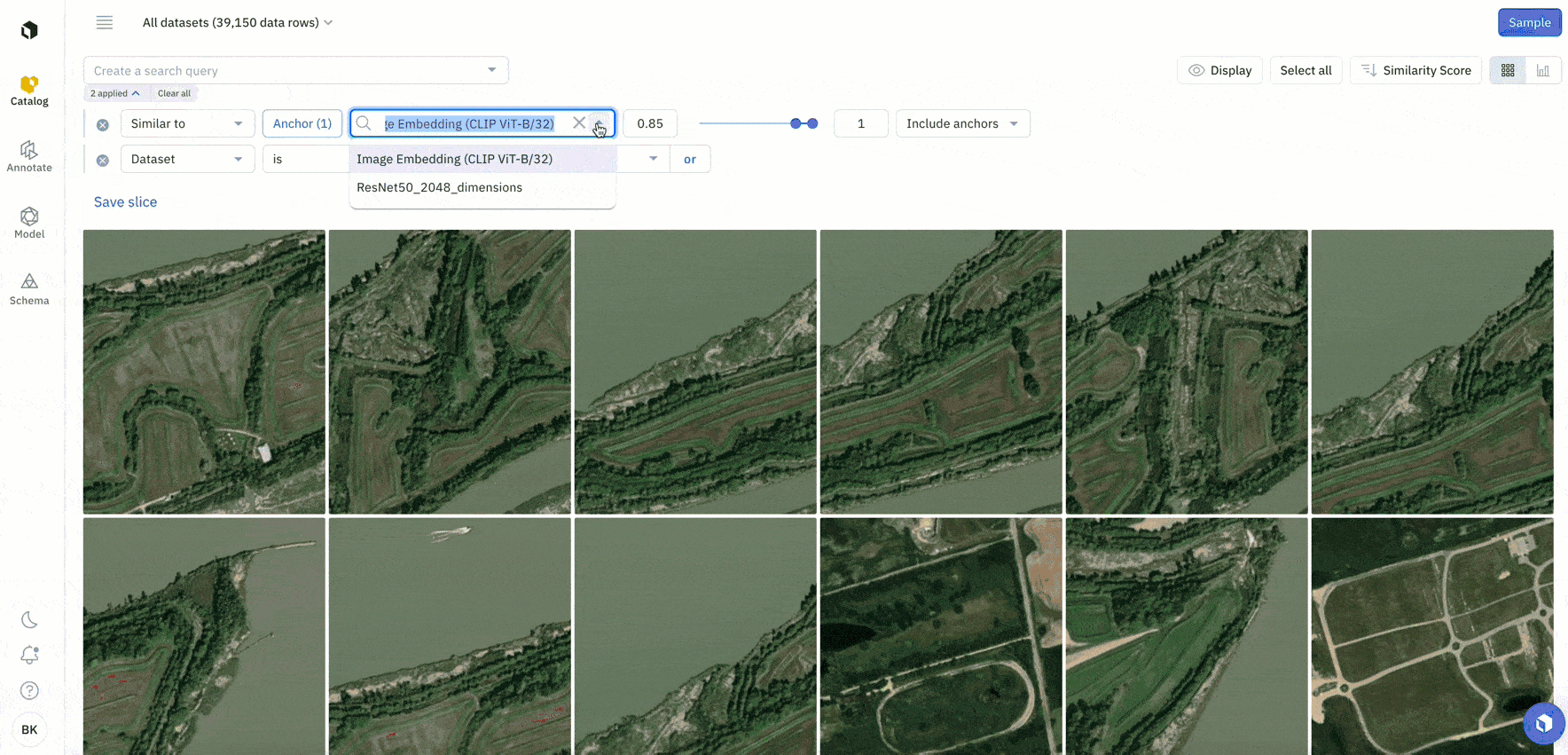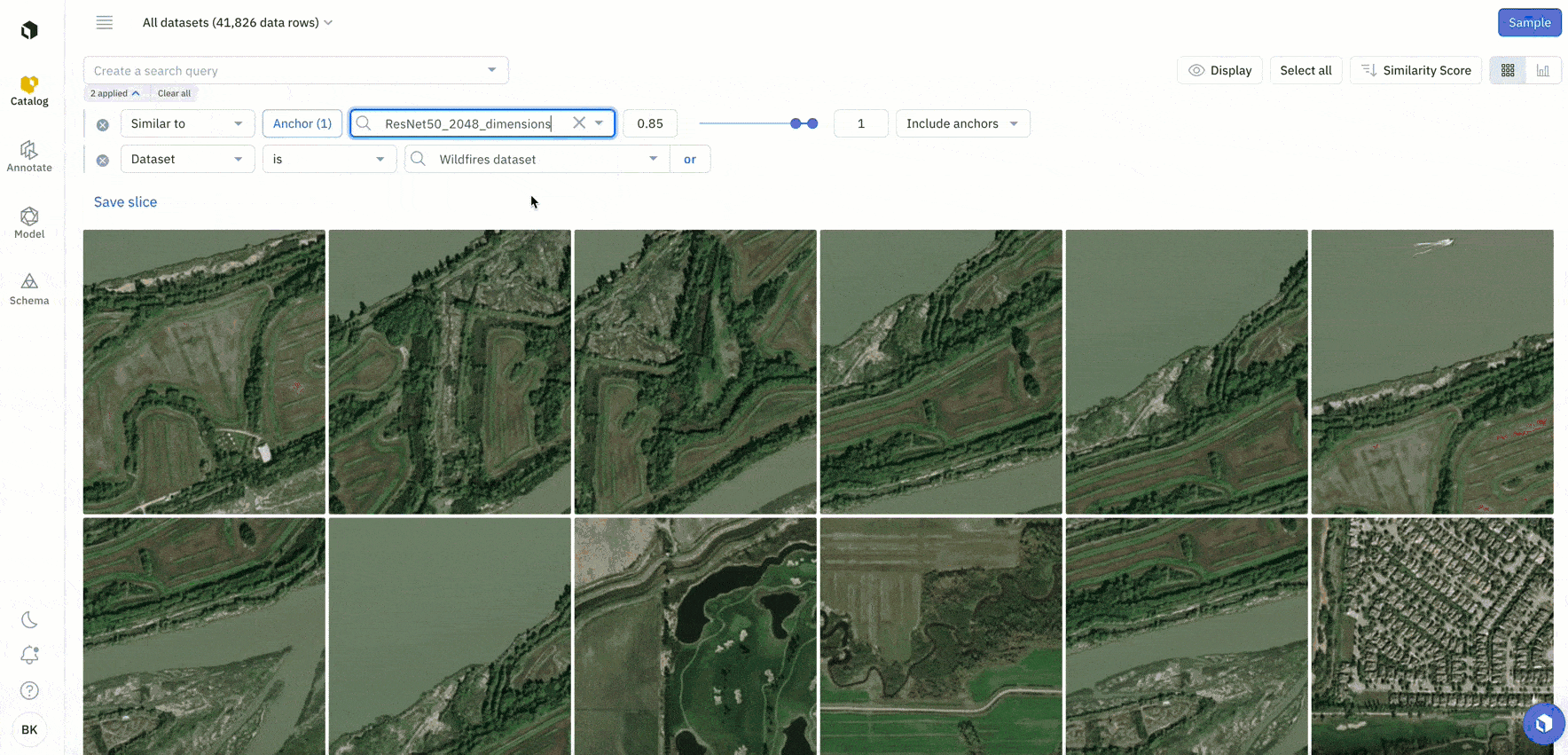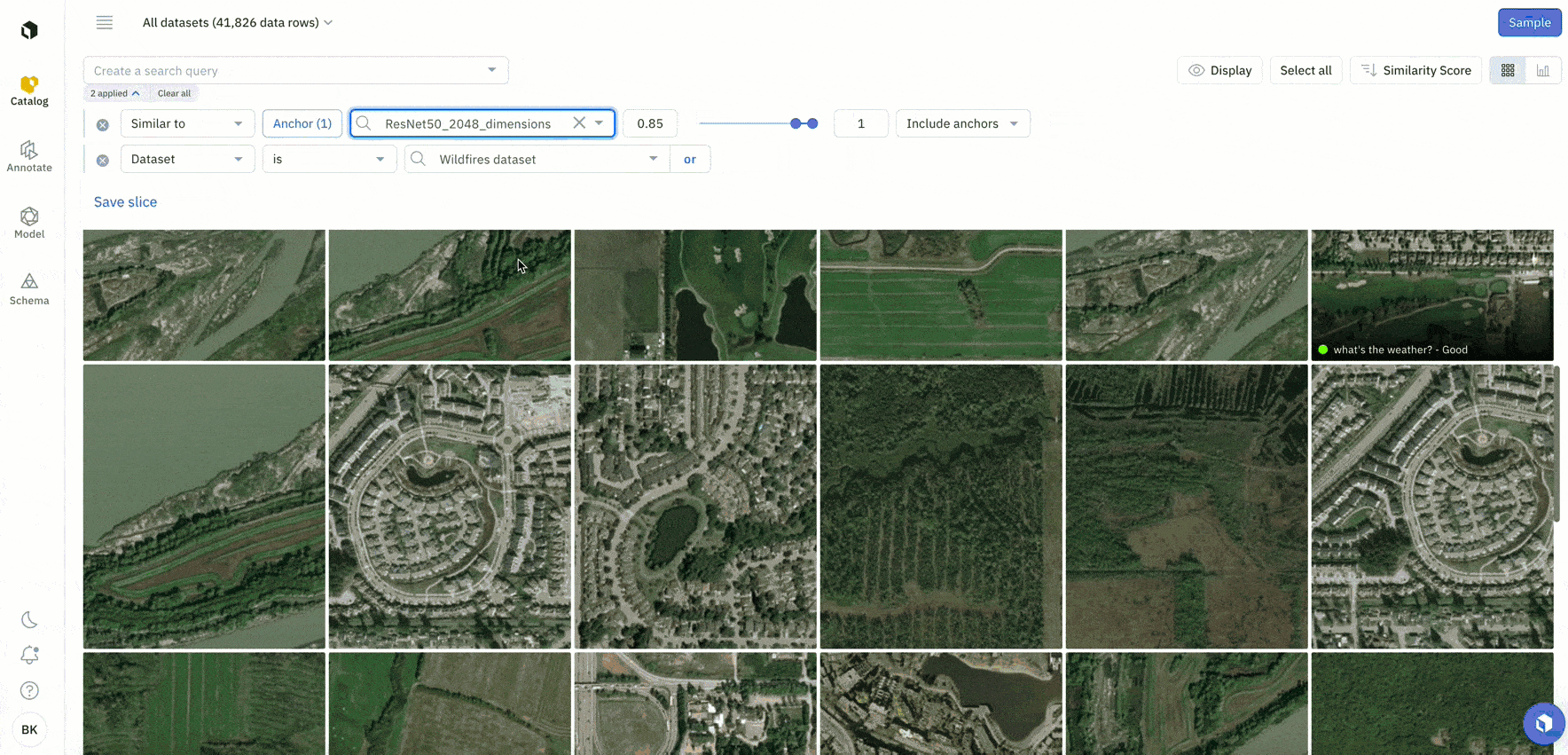
You can now upload up to 100 custom embeddings per organization in Catalog. To learn more about how to upload custom embeddings, you can check out the following resources:
- You can follow the above notebook to generate custom embeddings today. Note that this is a temporary Github repo that has been built by Labelbox. This notebook will become a part of the Labelbox Python SDK in the coming months.
- Our latest guide on: Using Labelbox and foundation models to generate custom embeddings and curate impactful data.
- Our documentation on custom embeddings and conducting a similarity search.
In addition to uploading custom embeddings, when you connect your data to Labelbox, we automatically compute off-the-shelf embeddings on your data. This includes:
- CLIP embeddings for images, tiled imagery, and documents
- All-mpnet-base-v2 embeddings for text and HTML data
While these off-the-shelf embeddings are a useful starting point for you to explore your data and conduct similarity searches, there might be some cases where you want to use your own custom embeddings. You can easily compare the results of these custom and provided off-the-shelf embeddings in Labelbox to discover the best embeddings to use for data selection.

SDK improvements
We have improved SDK capabilities to extend the feature updates offered in Labelbox UI. Version 3.40.0 includes notable functional improvements across global keys, model run, ontology, batches, and annotation import to help you better access all of the functionalities of the Labelbox API.
These improvements include:
A new way to export your data
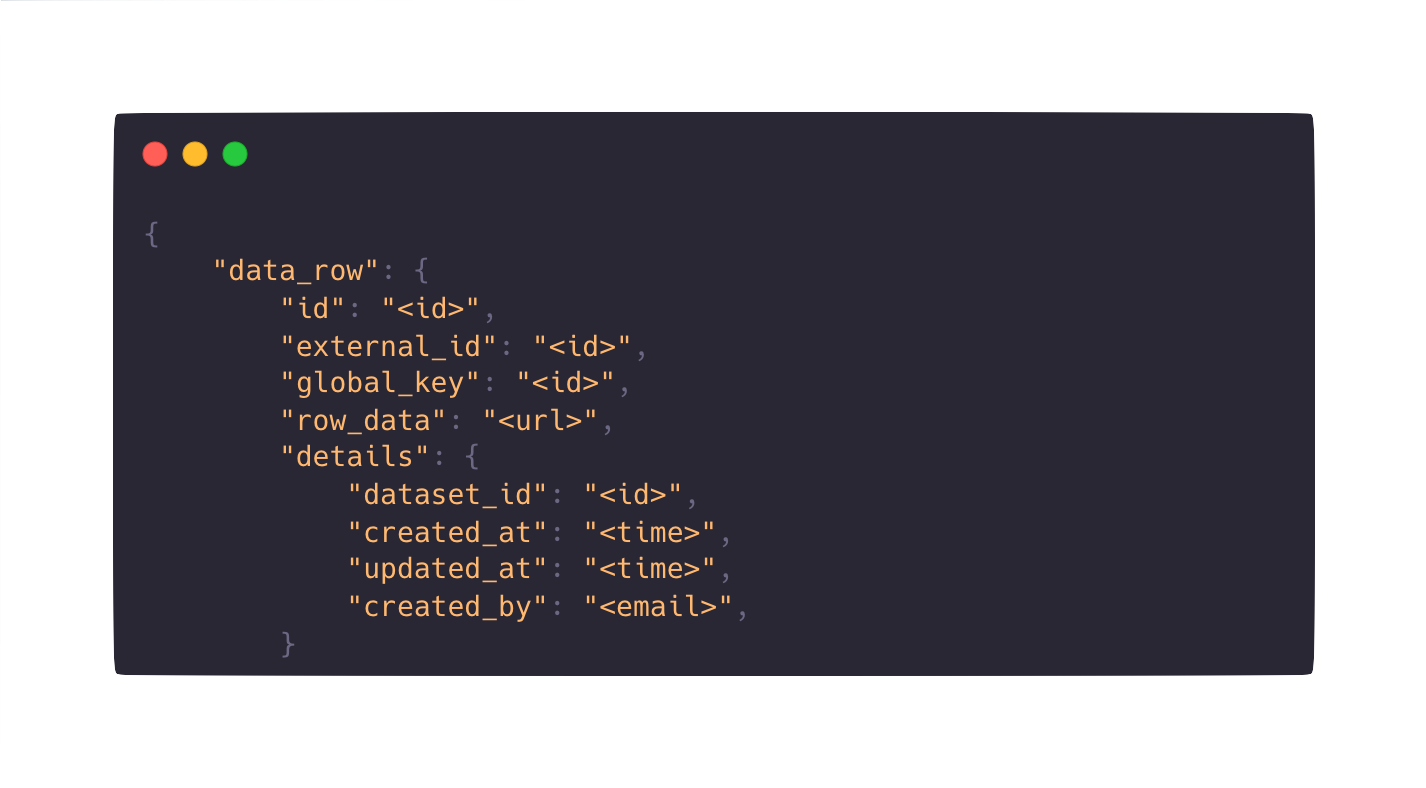
- The new Export v2 workflows (beta) we released in the Labelbox user interface are now also available via SDK.
- With Elasticsearch-based queries, you can apply filters to select which data rows from your project to include for export.
- This updated, data row-centric format empowers you to include or exclude variables based on your project needs. Offering a more seamless user experience, the export format more consistently mirrors our import format and aligns with annotation schema available in the platform.
- Export v2 support in the SDK is currently available for: projects in Annotate and from a model run. We will soon be releasing SDK support for data in Catalog.
- Please refer to our documentation for more detailed instructions on how to export your data through the UI or through the Python SDK.
Simplify annotation imports (pre-labels, ground truth, model predictions) with global keys
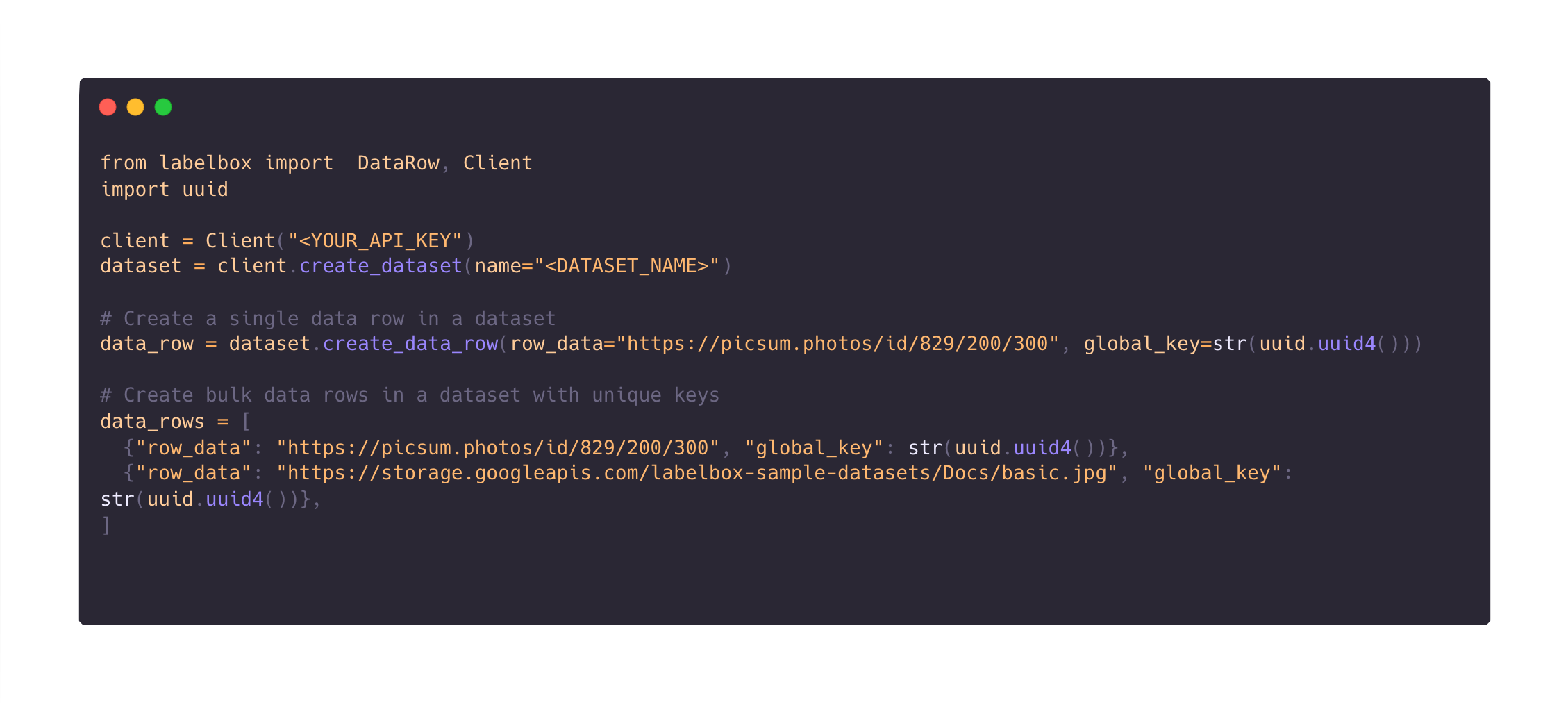
All Labelbox users can leverage global keys to streamline the annotation import experience and to surface specific data rows in Catalog faster than ever.
Global keys are helpful in avoiding duplicate data in Catalog, as each global key is unique to one data row at the organization level. Rather than waiting for your data rows to process and manually having to export and match IDs, global keys facilitate a streamlined workflow.
With this SDK update, you can now:
- Upload data rows and annotation imports (pre-labels, ground truth, model predictions) in a single call with global keys
- Create batches of data rows using global keys
To learn more about how to upload annotations with global keys, check out our documentation.
You can also click to see the annotation import workflow based on the data type of interest: Image | Video | Text | Geospatial | Documents | Conversational

Label videos with step interpolation
Rather than linearly tracking objects to the next keyframe in videos, we’re offering the option for users to label videos with step interpolation.
While linear interpolation can be helpful in use cases where you want to linearly and smoothly track an object in your video, there are some use cases in which you want the annotation to stay in the exact same position until the next keyframe.

With step interpolation:
- Instead of a linear transition between keyframes, objects will remain in the same geometric position until the next keyframe
- This is mirrored in the video’s export file — frames will show the same bounding box height and width until the next keyframe (where it will display a different value based on where the annotation was moved to)
For now, this is only available at the organization level, meaning you can enable step interpolation and turn off linear interpolation for video projects across your organization. We’re currently working on making this feature at the project and feature level.
If you wish to disable linear interpolation and replace it with step interpolation for your organization, please contact jpatel@labelbox.com.
Architectural improvements to enhance labeler productivity
We’ve introduced a few core architectural improvements to enhance the labeling experience and data ingestion capabilities:
- A faster labeling experience in the APAC region: Labelers in the APAC region can now label with latency less than a hundred milliseconds. If your labeling tasks are designed within operating range and following our recommended best practices, you should experience little to no latency while annotating.
- Upload more data rows at scale: Over the next few weeks, we’ll be rolling out a high-throughput data ingestion system. This will dramatically increase the number of data rows that are ingested in Catalog, enabling you to import extremely large datasets that range from 100 million to billions of data rows.

Send model predictions as pre-labels to a labeling project
Labelbox model-assisted labeling (MAL) workflows allow you to import computer-generated predictions — or annotations created outside of Labelbox — as pre-labels. Although they’ll still require human review, these imported annotations help decrease human resource demand and expedite human labeling workflows.
Evaluating how your model performs on these predictions will help identify and target new edge cases and data discrepancies where your model has demonstrated poor performance and thus needs improvement or fine-tuning.
We’ve implemented new features to empower more human-in-the-loop engagement towards identifying the data necessary to streamline annotations and boost model performance.
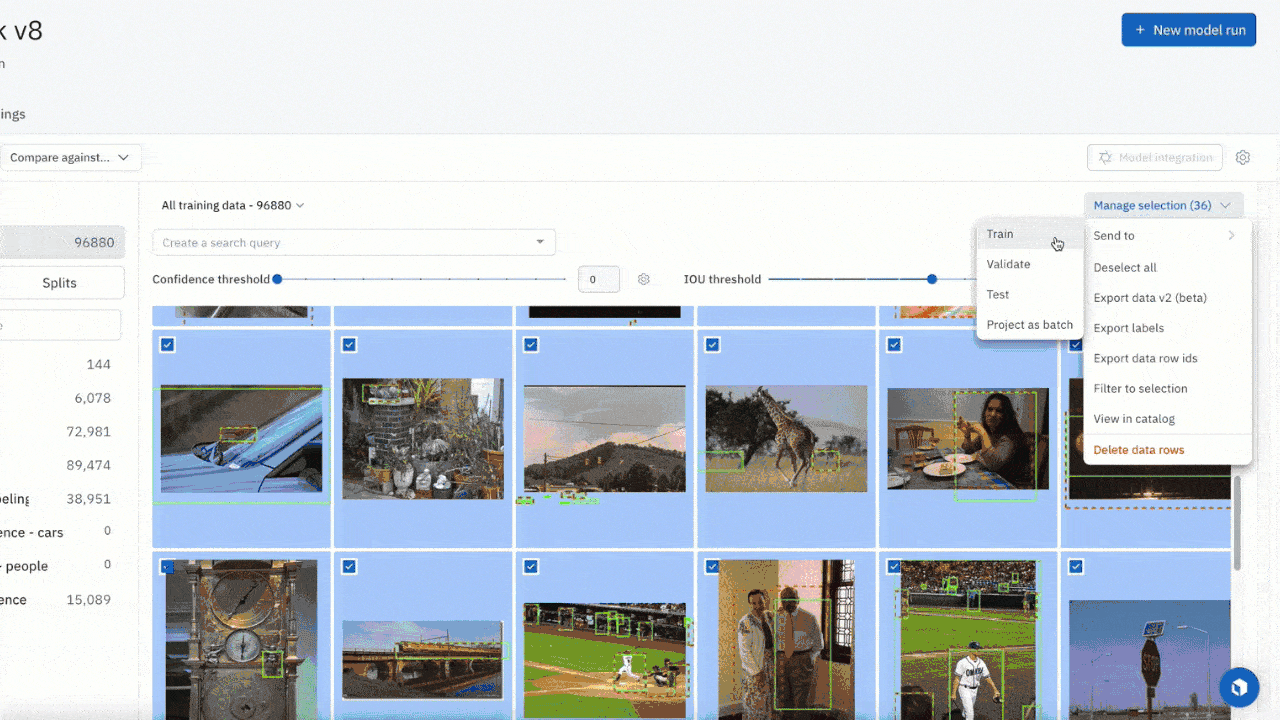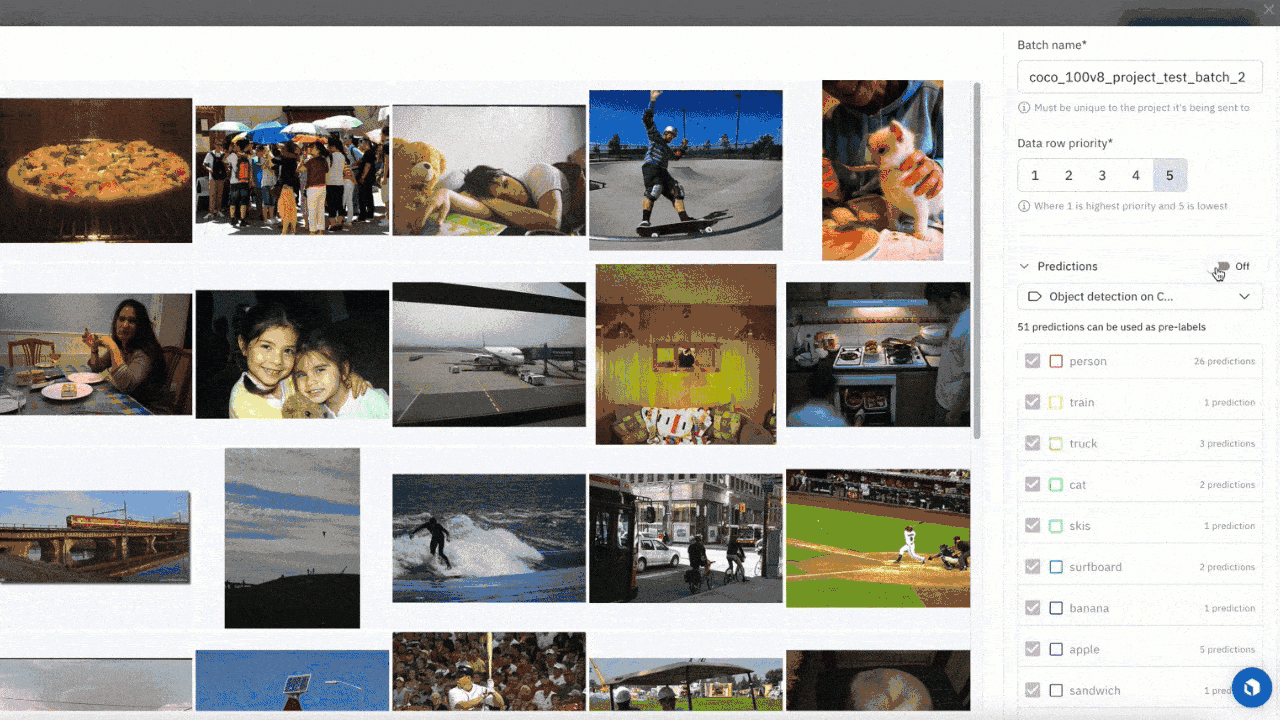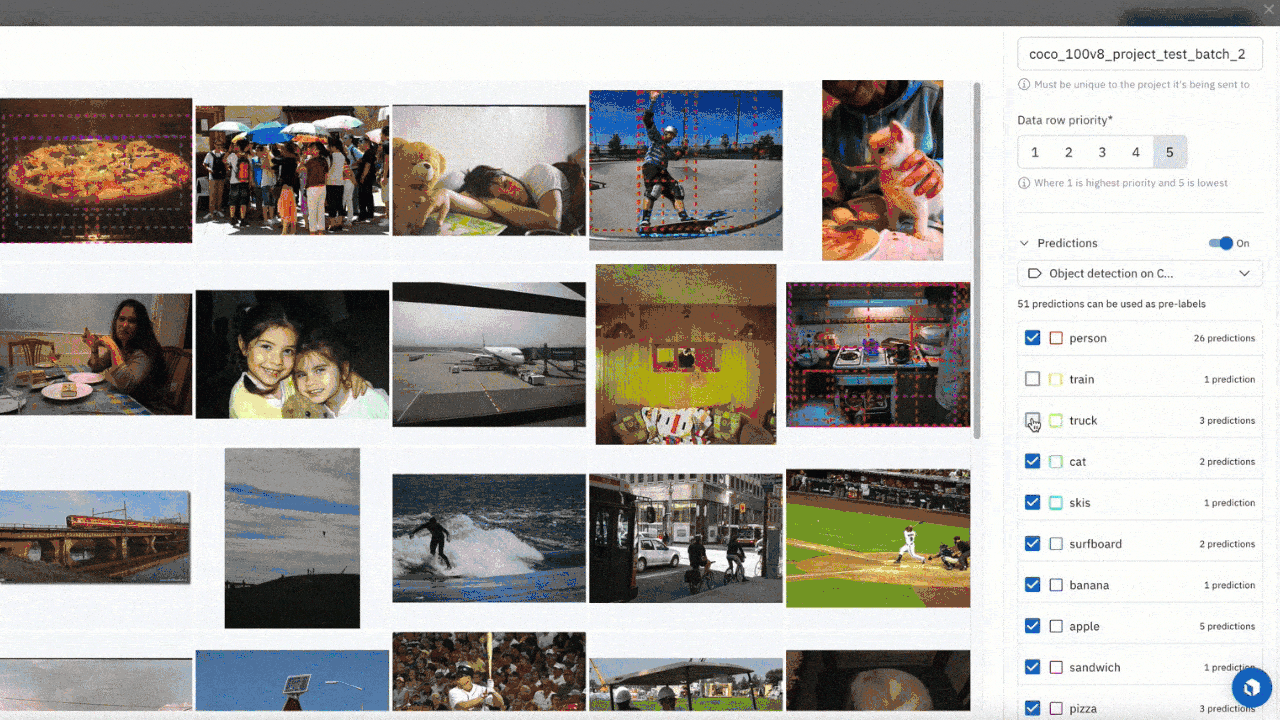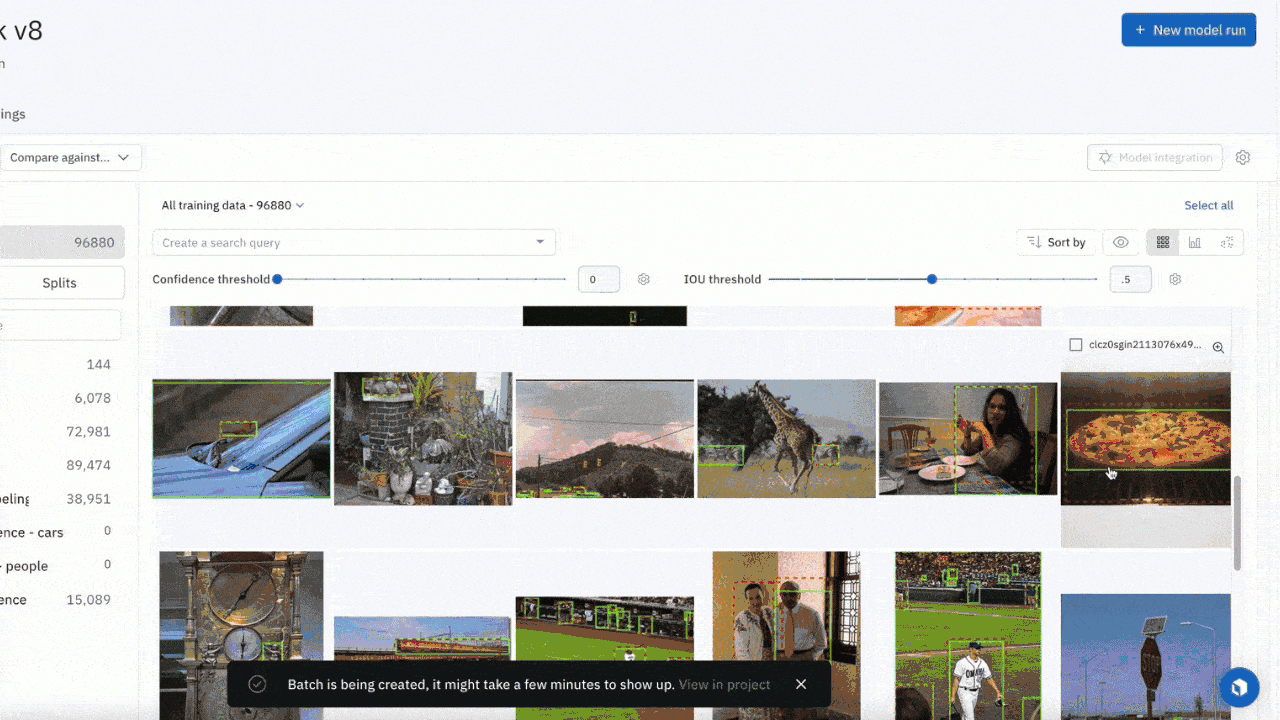
- You can now send predictions that are stored in a model run, as pre-labels, to your labeling project. For models that have already spent time confronting real world data, this workflow will help you quickly identify areas where model confidence is low and send that data for labeling and later retraining.
- This workflow empowers you to prioritize which assets to label by visually confirming model predictions before selecting the highest impact assets to send to your labeling project. It also helps you select a subsection of model predictions to address known performance issues due to data drift, out-of-distribution data or even rare data samples that your model has encountered.
To do uncertainty sampling where you prioritize low-confidence predictions, you can:
- Upload all model predictions from your model run
- After you review the model predictions, identify classes where your model has demonstrated poor performance
- Select these low confidence prediction data rows and submit them to a project for future labeling
Check out our latest product guides on...
- How to use prepare unstructured data for AI and analytics in Databricks
- Using Labelbox and foundation models to generate custom embeddings and curate impactful data
- How to fine-tune large language models (LLMs) with Labelbox
- An introduction to model metrics
- Using Labelbox and Weights & Biases to fine-tune your computer vision projects


