
 All blog posts
All blog postsLabelbox•July 17, 2024
Streamlining large-scale data exports: The evolution of Labelbox’s Export System to a streamable architecture with fairness in place

Introduction
In the world of data management and labeling, efficient data export processes are critical. They ensure that large datasets can be quickly and accurately transferred, validated, and utilized for various applications. At Labelbox, we recognized the need to evolve our export system to meet growing demands and address key issues faced by our users. This blog post will delve into the journey of transforming our export system to a more efficient streamable architecture, highlighting the challenges, solutions, and benefits along the way.
Background
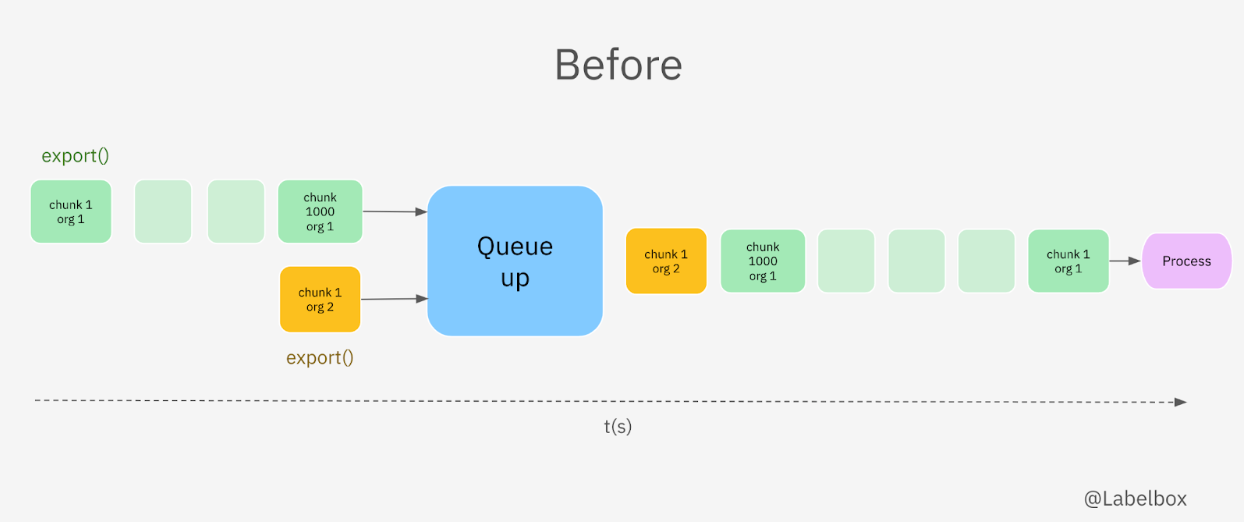
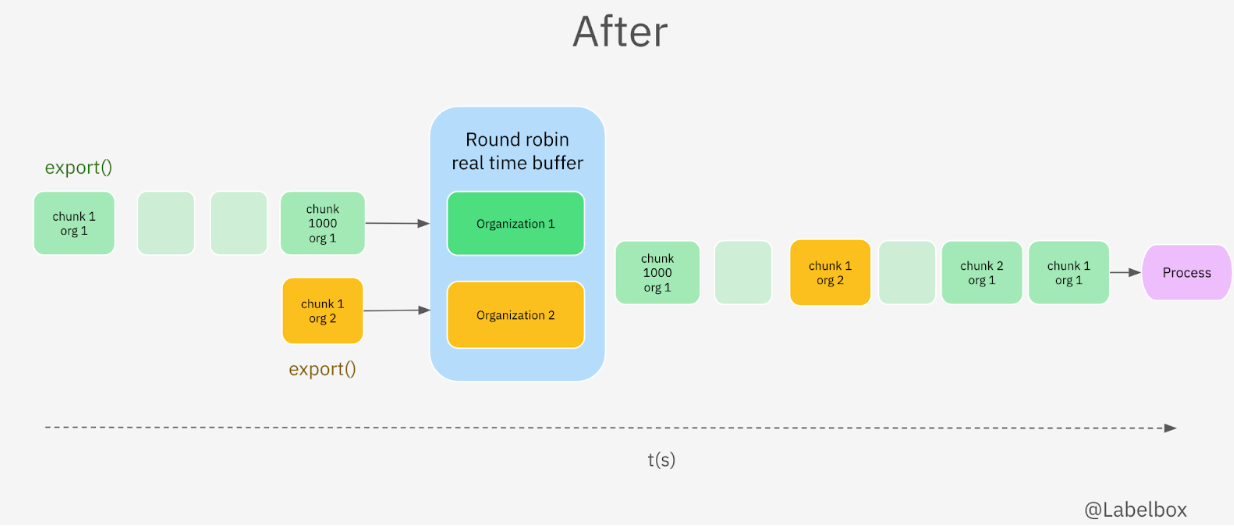
Previous Challenges of our Export System
When we first created our Export system, we aimed to provide a robust solution for data export. However, it quickly became apparent that there were significant drawbacks:
- Chunk combining phase: This phase was time-consuming, especially for larger exports. It involved fetching and validating data, then merging chunks, which not only extended processing times but also imposed limitations on the size of exports due to underlying service constraints.
- Stateful communications: Internal communications between services were stateful, leading to issues such as stale exports when pods were recycled.
Our strategy
Transition to streamable exports
To address these issues, we introduced a streamable Export System in early 2024. This new system aimed to resolve the inefficiencies of the previous version by adopting a streamable approach.
- Iterator approach: The new SDK API utilized an iterator approach, allowing customers to process large-scale data exports without needing to load the entire export into memory. This was particularly advantageous for handling extensive datasets.
- Backend improvements: Despite the enhanced backend capabilities, the majority of our traffic continued to rely on the non-streamable system.
Seamless transition
With growing demand pushing the limits of our non-streamable architecture, we had to devise a seamless transition strategy for our customers:
- Back-porting streamable backend: We decided to back-port the Streamable backend to our .export_v2 methods. This allowed the SDK to utilize the new infrastructure behind the scenes, mapping outputs and errors to legacy data types. This approach ensured minimal disruption to our users.
- Feature flags with LaunchDarkly: By leveraging feature flags facilitated by LaunchDarkly, we were able to roll out this change without risking stability, allowing us to monitor and control the transition effectively.
Addressing performance issues
Despite these improvements, we encountered performance-related issues reported by our customers:
- Export process: Our export process involves generating a list of chunks (500 data rows per chunk) from Elasticsearch based on user-provided filters. These chunks are then pushed onto a pubsub queue for processing by workers.
- Queue management: The FIFO system of the queue led to fairness issues, especially during peak hours. Customers exporting large datasets could cause delays for others with smaller exports.
To solve this, we implemented a more sophisticated queue management system using the BullMQ framework.
BullMQ framework for fairness
The premium version of BullMQ allowed us to implement a round-robin system, ensuring fair processing across different organizations:
- Round robin system: Each organization was assigned to its own bucket, and we adjusted the system to use priorities and a weighted buffer to manage chunks.
- Tracking and scaling: By tracking the number of chunks being processed for each organization and employing horizontal scaling, we achieved fairness and maximized throughput.
Conclusion
The evolution from to a streamable architecture has significantly improved the efficiency and fairness of our data export processes at Labelbox. By addressing key challenges and leveraging advanced queue management systems, we have ensured that our users can handle large-scale data exports more effectively. As we continue to innovate and refine our systems, we remain committed to providing the best possible experience for our customers.
Further reading
For more detailed technical documentation and insights, please refer to the following resources:


