Enterprise RLHF for large language models
Differentiate your LLMs with better data. A complete solution combining the best tools and fully managed services for reinforcement learning from human feedback (RLHF) and LLM evaluation.


Generate high-quality data for alignment
Ensure helpful, trustworthy, safe outputs with highly accurate datasets for instruction tuning, RLHF, and supervised fine-tuning.
Tap into a network of highly skilled professionals (graduates, engineers, domain experts) who have trained LLMs before and have delivered projects for leading frontier model developers such as Cohere, OpenAI, etc.
Curate, annotate, and prepare datasets with the best of human and AI-assisted data preparation.

Ship LLMs confidently with human-centric evaluation
Empower human experts to validate model outcomes with advanced capabilities for benchmarking, ranking, selection, NER, and classification.
Evaluate pre-recorded and live chats with support for multi-turn conversations.
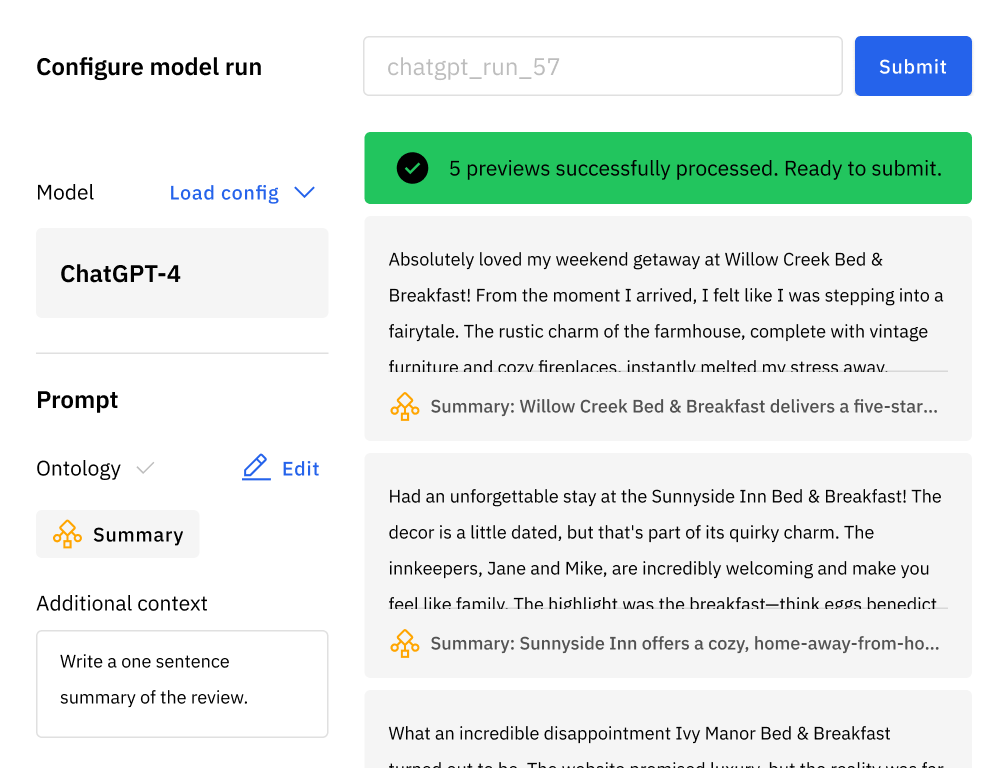
Enrich your data and automate common tasks with LLMs
Automate data labeling and augmentation tasks with Model Foundry. No-code data enrichment with leading closed-source and open-source LLMs at a fraction of the time and cost.

Prioritize the right user feedback to improve LLMs
Zero in on feedback and cases that matter with powerful curation and discovery capabilities. Support for native vector search and similarity searches.