Use case
Coding tasks
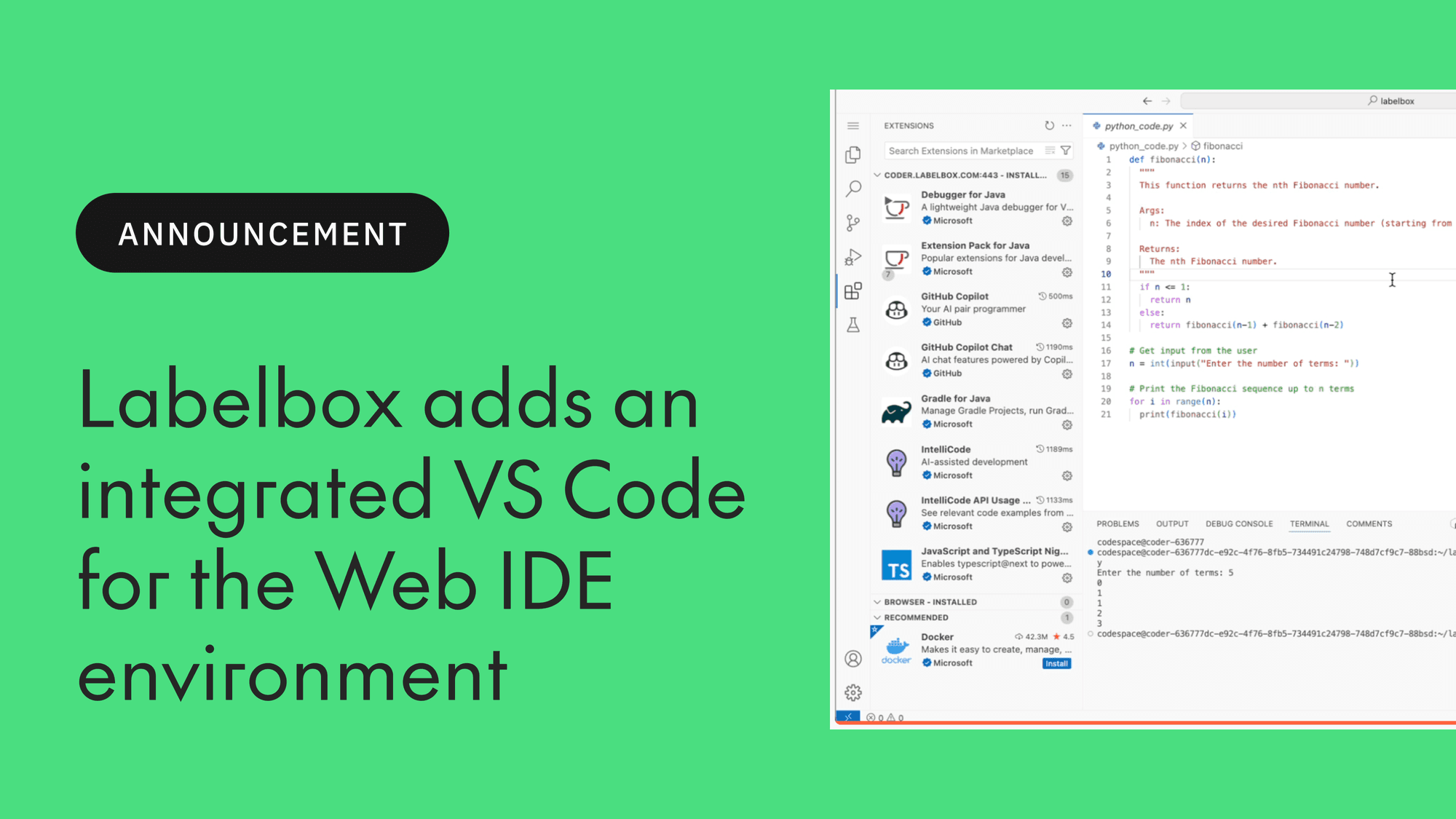
From code generation to constraint programming, Labelbox provides leading AI labs with the trainers and tools needed to advance the coding capabilities of frontier models

Why Labelbox for coding

Increase data quality
Generate high-quality data by combining advanced tooling, humans, AI, and on-demand services in a unified solution.

Customize evaluation metrics
Tailor your workstream to evaluate code functionality, style, efficiency, security or more with custom annotations.

Access coding experts on-demand
Access coding experts to provide tailored support, from evaluating code correctness to enforcing style guidelines.

Collaborate in real-time
Enjoy direct access to internal and external labelers with real-time feedback on labels and quality via Labelbox platform.

Unlocking the power of AI for code
AI coding tasks encompass a wide range of applications, including code generation, code completion, code translation, code review, and code optimization. By training AI models on these different coding tasks, you can unlock new levels of efficiency, accuracy, and creativity in software development.
Diverse frontier coding use cases
Evaluating multi-dimensional code quality
Assess AI-generated code across criteria like correctness, readability, efficiency, scalability, and style to improve usability and trust.
Testing multi-step reasoning & planning
Evaluate how well AI systems decompose complex coding problems into logical steps and implement them correctly.
Labeling functional correctness and bugs
Annotate AI-generated code for runtime correctness, logical flaws, and common bug types to improve model reliability.
Correcting coding behavior with RLVR
Train and evaluate AI models using programmatically verifiable rewards to reinforce correct coding behaviors and outputs.
Generating full apps from prompts
Assess full model performance in generating the best frontend, backend, and data logic from a prompt (prompt-to-app).
Curating domain-specific code benchmarks
Build targeted datasets for niche domains like embedded systems, smart contracts, or data pipelines to test specialized skills.

Why coding is hard for AI
Training AI models for coding tasks is uniquely challenging. Code requires precise syntax, logical reasoning, and an understanding of complex dependencies. Traditional AI approaches often struggle with these nuances, leading to errors, inconsistencies, and unexpected behavior.

Optimize AI coding tasks with Labelbox
Use Labelbox to efficiently create and manage high-quality code datasets, evaluate model performance with expert feedback, and generate new training data to improve accuracy and address edge cases. The Labelbox platform streamlines the entire process, accelerating your time to value and maximizing your AI investments.
Tap into the Alignerr Network, operated by Labelbox, to hire skilled AI trainers for model evals, data generation, and labeling
Customer spotlight
Labelbox's intuitive tooling coupled with post-training labeling services offered a collaborative environment where Speak's internal team, along with external data annotators, could work together seamlessly. Learn more about how Speak uses Labelbox to improving the quality and efficiency of their data labeling.
Learn more >