Use case
Reinforcement Learning with Verifiable Rewards
Supercharge your reinforcement learning with verifiable rewards (RLVR) pipeline to improve your model’s reasoning and planning capabilities–essential skills for the next generation of AI agents

Why Labelbox for RLVR

Supercharge your RL pipeline
Effortlessly form a team of expert AI trainers to create diverse, high-volume prompt and verifier datasets across multiple domains.

Harness world-class AI experts
Access our specialized Alignerr network for nuanced prompt engineering and robust verifier development.

Deliver verifiable data quality
Implement rigorous processes to generate accurate prompts and reliable verifiers for objective rewards to fill your RL pipeline.

Accelerate agentic readiness
Get the precise data inputs needed to efficiently train models for complex reasoning and planning tasks to set the stage for advanced AI agents.

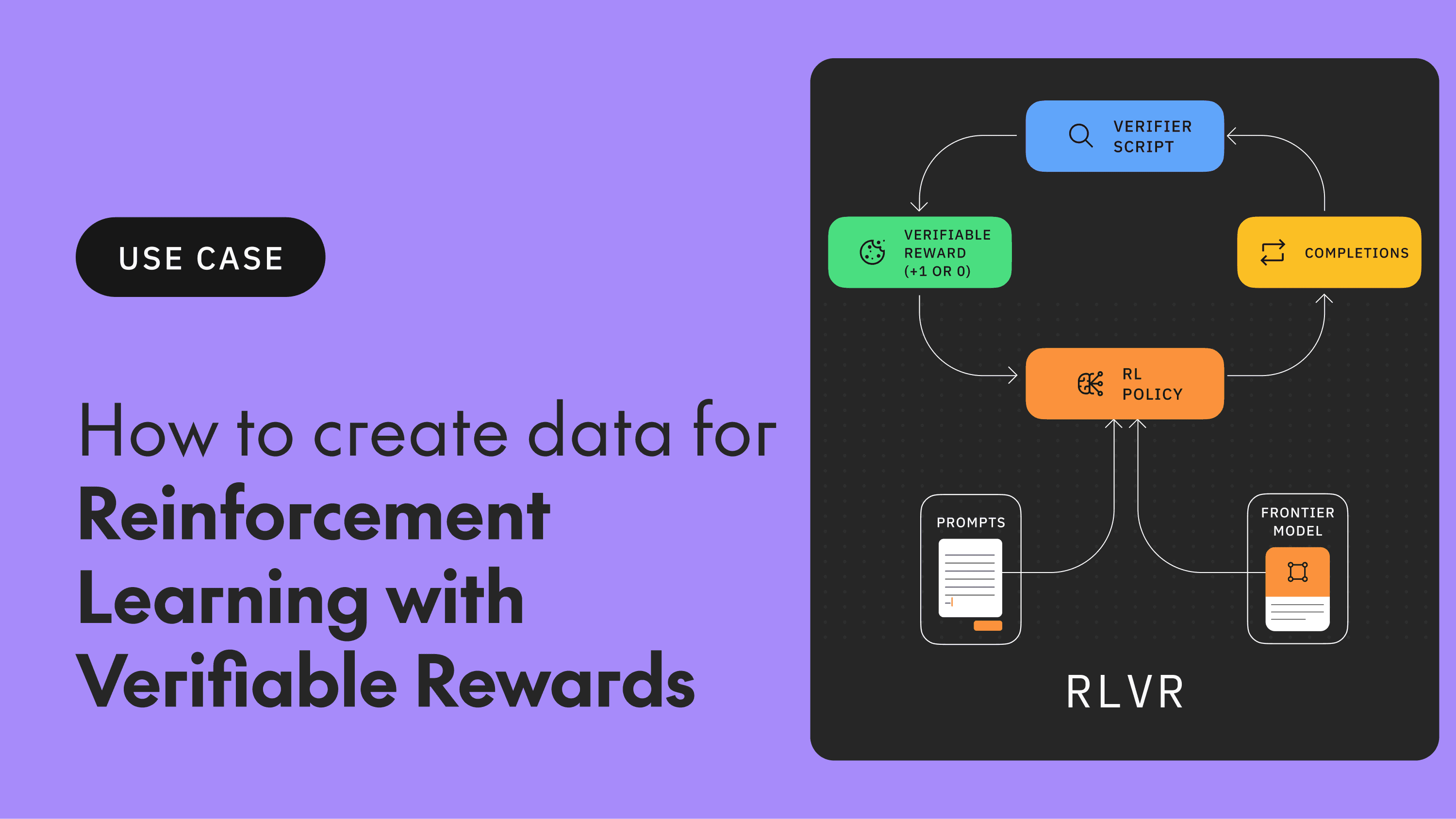
The power of reinforcement learning with verifiable rewards
RLVR is a powerful AI training technique teaching models skills like reasoning, math, and coding through clear, objective feedback. Unlike subjective preference tuning (RLHF), RLVR uses automated "verifiers" to reward models based on whether their output is demonstrably correct, driving improvements in accuracy and logical soundness critical for reliable AI.
Powering frontier models with RLVR use cases
Complex math & science
Train models for accurate, step-by-step problem-solving in key STEM domains.
Code generation & execution
Teach models to write functional code that passes predefined tests.
Multi-step planning & scheduling
Improve agentic abilities in logistics, resource allocation, and task management.

Precise instruction following
Train models to strictly adhere to complex formatting or content rules.
Automated theorem proving
Develop models capable of constructing valid mathematical or logical proofs.
Agent tool use validation
Train AI agents to utilize external tools correctly based on verifiable outcomes.

The challenge scaling high-quality RLVR data
Successfully implementing RLVR is challenging. Generating the necessary volume and diversity of high-quality prompts across complex domains requires significant effort and expertise. Creating robust, accurate verifiers for each task to provide reliable reward signals is a complex engineering hurdle that often bottlenecks frontier model development.

Supercharge your RLVR pipeline with Labelbox
Labelbox streamlines your RLVR pipeline with comprehensive data services. We combine our platform, proven methodologies, and skilled Aligner network to define problem domains, generate vast sets of diverse prompts, and create detailed evaluation rubrics that codify exactly what “success” looks like.
Alongside these rubrics, we develop the custom code-based verifiers needed for precise, consistent RL training, delivering the structured, high-quality inputs that supercharge your model’s reasoning and reliably measure its performance.
Tap into the Alignerr Network, operated by Labelbox, to hire skilled AI trainers for model evals, data generation, and labeling
Customer spotlight
A leading AI lab aimed to improve its large language model (LLM) for K-12 STEM education by identifying its weaknesses. Labelbox's Labeling Services, in collaboration with the Alignerr network, assembled a team of STEM experts with advanced degrees in fields like chemistry, biology, and engineering. These experts created multimodal prompts (text and image) and accurate answers to assess the model. Their work helped pinpoint the LLM’s limitations, enabling the lab to target areas for improvement.
Learn more >