
 All blog posts
All blog postsLabelbox•May 6, 2025
How to fill your RLVR pipeline with advanced reasoning data

Unlocking the next level of AI performance and utility, particularly for complex tasks requiring sophisticated planning and execution (the foundation of future AI agents), demands more than just scale. It requires robust reasoning capabilities.
Reinforcement learning (RL)—or specifically the fast growing adoption of Reinforcement Learning with Verifiable Rewards (RLVR)—offers a powerful and efficient pathway to teach models how to reason effectively, especially for problems with clear, verifiable solutions.
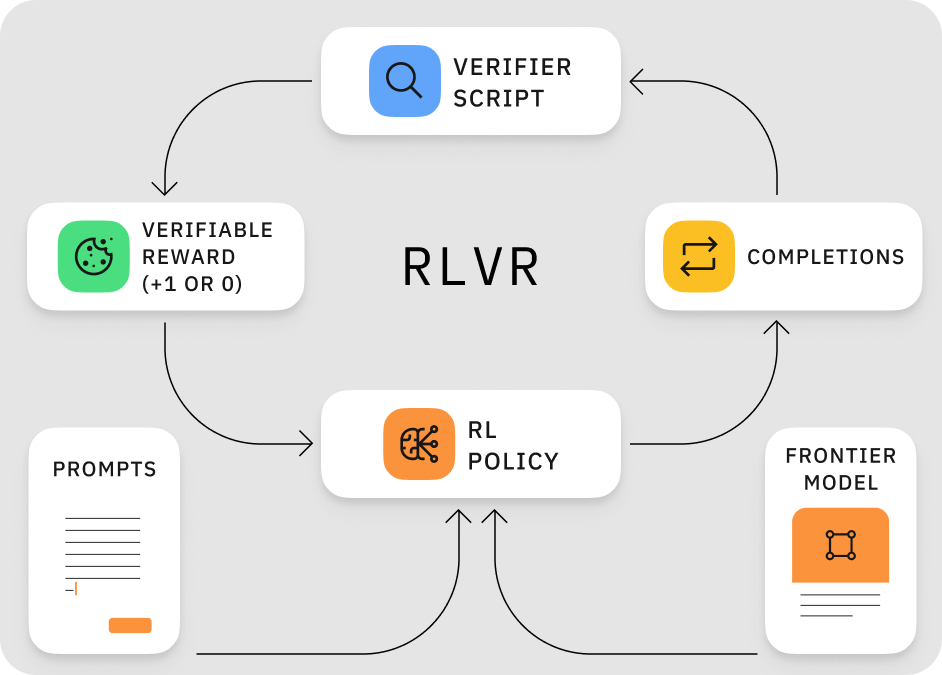
At Labelbox, we're pioneering RL data services designed to supercharge this process and fill your AI training pipelines. Read below to discover how we’re approaching this problem and already helping some leading AI labs dramatically improve the reasoning capabilities of their frontier models.
RL vs. DPO/RLHF: Choosing the right method for enhanced reasoning
As AI development matures, training methodologies are evolving. Alignment, whether through the classic RLHF (Reinforcement Learning from Human Feedback) methods or more recent DPO (Direct Preference Optimization) methods, has been instrumental in aligning models with human preferences. These methods are important for subjective tasks like adjusting tone and improving conversational flow. The tuning methods involve humans comparing two model outputs and indicating which is "better," guiding the model towards preferred styles and behaviors.
But what is “better” is a complicated question (and beyond the scope of our blog today). DPO and RLHF is critical to aligning AI models with human preferences, and is one reason we operate our diverse, global network of Alignerrs.
However, when it comes to tasks demanding objective correctness—like mathematical calculations, code generation, logical deduction, or complex planning—a different flavor of RL shines: Reinforcement Learning from Verifiable Rewards (RLVR). Instead of subjective preference, RLVR relies on a clear, often binary (correct/incorrect) signal based on whether the model's output meets predefined criteria.
Why is this crucial now? As we move towards AI agents that need to perform multi-step tasks accurately in the real world, their underlying reasoning must be sound. RLVR is ideal for instilling this logical rigor. It allows models to learn complex procedures by receiving unambiguous feedback on their problem-solving attempts. This ensures the model develops accurate internal logic before attempting to use tools or interact with external systems—a critical prerequisite for reliable agentic behavior.
Training a leading frontier model: A case study in scaling RL for reasoning
Labelbox is already at the forefront, collaborating with leading AI labs to enhance their models' reasoning abilities through targeted RL strategies. In a recent successful engagement, we partnered with a major AI research lab grappling with the challenge of scaling RL training specifically for complex planning tasks. Their goal was ambitious: significantly improve their model's ability to reason through intricate scenarios, laying the groundwork for advanced agentic capabilities.
This wasn't a standard data annotation project. It required a sophisticated approach to generate the high-quality, diverse data needed to train a model on planning across various domains. Our process involved defining problem domains, generating a diverse set of prompts, and developing verifiable reward functions.
The result? We successfully helped the lab supercharge their RL pipeline, improving their model's reasoning and agentic task performance by over 15%.
Building agent-ready RL pipelines with Labelbox
The success of this project highlights a core Labelbox capability: providing the specialized data generation, advanced verification services, and proven system needed to fuel sophisticated RL pipelines. We understand that teaching models complex reasoning requires more than just raw data; it requires structured, diverse, and verifiable training signals.
Our framework, proven with leading labs, is repeatable and scalable:
1) Collaborative domain definition: We work with you to identify the critical reasoning domains your models need to master.
2) Systematic prompt generation: Leveraging our expertise and your domain knowledge, we create vast sets of realistic problem variations, focusing on linguistic, structural, and parametric diversity. Our methodology includes varying:
- Structure/format: Paragraphs, bullets, markdown tables, etc.
- Information ordering: Changing the sequence of constraints and details.
- Tone & phrasing: Formal, informal, shorthand, detailed explanations.
- Syntax & specifics: $ vs USD, 14:00 vs 2 pm, numerical vs. written numbers.
- Constraint presentation: Grouping vs. distributing constraints.
- Placement of key Info: Varying where critical data like budgets or deadlines appear.
3) Verifier reward function development: We design and implement custom verifier and solver programs that provide the objective, automated reward signals necessary for efficient RL training.
4) Expert execution: We utilize Labelbox's extensive, highly skilled Alignerr network, who are expert AI trainers adept at handling the complexity of prompt generation, data structuring, and refinement needed for these advanced projects.
This comprehensive approach allows us to generate the precise inputs needed to train your models on nuanced reasoning across any domain, preparing them for the complex, multi-step tasks required by sophisticated AI agents.
Build more capable, agentic-ready models
The ability to reason effectively is the next frontier for AI. Reinforcement Learning, particularly reinforcement learning with verifiable rewards, provides a direct path to teaching models the complex logic required for advanced applications and agentic behavior. Labelbox offers the expertise, process, and scalable resources to generate the high-quality reasoning data and RL services needed to accelerate your model development.
Ready to supercharge your RL pipeline and prepare your models for the future of AI? Learn more about Labelbox's RLVR solution or contact us to discuss your immediate data needs.
Let Labelbox help you build models that don't just predict, but reason.


