
 All guides
All guidesIntroduction to Computer Vision

What is computer vision?
Computer vision is a field of Artificial Intelligence (AI) technology that enables computer systems to perform tasks that require visual perception. In simpler terms, computer vision helps a system mimic human sight. It’s typically used in different visual applications such as computer security surveillance, manufacturing line quality inspection, cars, drones and robots navigation, medical imaging diagnosis, or automated retail stores.
Computer vision is a challenge in machine learning as the visual world is complex and vast, and computers are designed to work best with constrained problems.
For example, a computer can quickly be programmed to perform a task like identifying images in a database with “flower” in the file name, but asking it to identify flowers within a set of images is a far more difficult task. Not all flowers look the same, and the computer will have a hard time identifying the differences in images due to lighting, camera angles, camera types, image quality, and more.
However, computer vision algorithms have recently become more robust and accessible with the availability of public datasets, which help train models. However, for enterprises embracing computer vision initiatives, publicly available algorithms and datasets may not meet their requirements.
Enterprise businesses need models trained on their own data for specific use cases, whether it's identifying cancer cells in microscope images of tissue samples, tracking vehicle movement, or finding weeds in photos of crops in a field. Many companies are also discovering the need for computer vision models trained on video data, or a combination of video and image data, to ensure that the training data is more representative of what the model will need to achieve performant AI. As a result of these challenges, machine learning models built for enterprise use cases are frequently more complex and more difficult to create.

Common computer vision use cases
Let’s explore a couple of basic computer vision applications, along with some examples of enterprise use cases for computer vision.
Object detection
Object detection is used for locating an object or objects within an image or a video frame from a video source. Object detection is one of the computer vision technologies used to automatically identify instances of semantic objects in natural scene images. To detect an object means to estimate its location relative to other objects within a framework model.

This is a common computer vision use case used across industries. For example, farmers use AI solutions with models trained for object detection to find weeds, damaged plants, or other problems in photos of their field, saving them significant time and money. This type of machine learning model allows for more efficiency within crop growing, such as the ability to spray weeds only in affected areas rather than the entire field.
In order to properly train a model for object detection, AI teams will need to first gather their dataset — images of the field — and have an expert botanist or agronomist label them by hand. These annotated images are then fed into the algorithm to train it. To achieve the level of accuracy required to allow farming businesses to rely on the model, the algorithm will likely need to be trained over several iteration cycles.
Object detection is often used in tandem with many other computer vision applications, including:
- Object classification: The model identifies the category for each object in the image, such as the type of weed in an image of a field
- Object identification: The model finds each object in the image and identifies it
- Object verification: The model decides whether a specific object is in an image
Image segmentation
Image segmentation examines every pixel in an image and classifies it based on whether it belongs to a specific object. This creates a mask that defines the exact shape of the object, rather than encompassing the object in a box. Object segmentation is particularly useful when it’s important not only to identify an object but also the shape or orientation of the object.
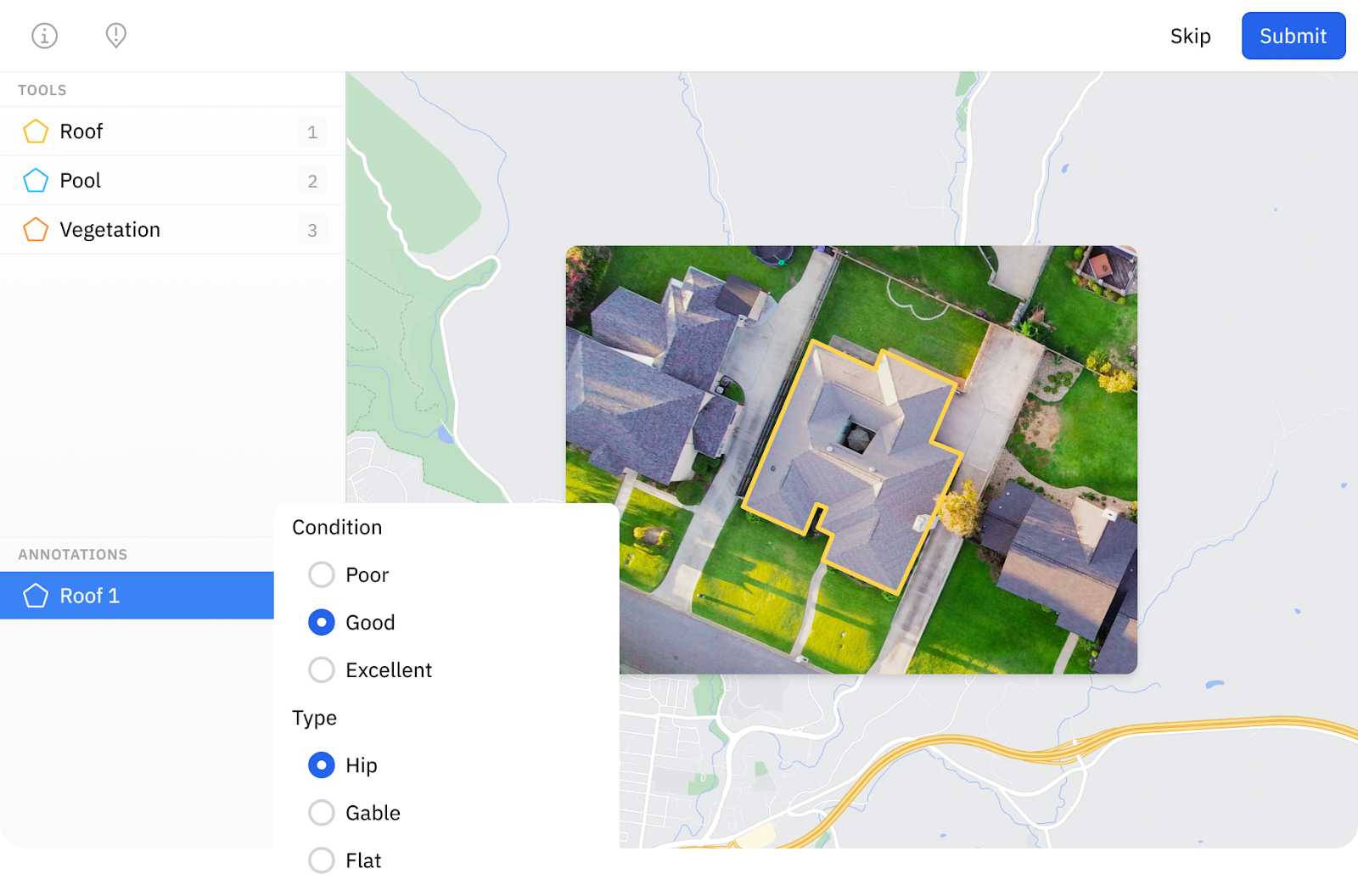
One example of image segmentation is an insurance use case, where a computer vision model evaluates buildings and their surroundings in an aerial image to assess risk and damage. In this case, it’s important for the model to detect the exact shape of an object — say, a collapsed wall — rather than identify the object with a bounding box.
How to train a computer vision algorithm
There are four basic steps for training a computer vision model:
- Understanding the business requirement for computer vision
- Creating a training dataset
- Training the model and assessing its accuracy
- Iterating with new training data until it reaches the desired accuracy
Understanding the business requirement for computer vision
The first step for any computer vision project is understanding the problem you're trying to solve. For example, if an e-commerce clothing company wants to tailor store recommendations based on their customers' personal style, it would benefit from a computer vision model that identifies and categorizes each piece of clothing in their catalog. A relatively simple model might be trained to analyze an image and note the following information about the piece of clothing within it:
- SKU#
- What type of item it is (top, bottom, dress)
- The color of the item
- Any patterns or prints on the item
With a computer vision model that accurately identifies this data, the company would then be able to ensure that a prospective customer receives tailored recommendations based on their purchase history and other demographic or psychographic data.

A more complex version of this computer vision model would be trained to categorize apparel further down to the type of fabric, style (such as a button-down compared to a v-neck shirt), what other pieces in the catalog it might be paired with, and more.
Creating a training dataset
Once the AI team has determined exactly what they want their computer vision model to do and what role it will play, they must then develop the training data set.
Training data is arguably the most crucial element of the machine learning process. High-quality training data will accelerate your computer vision model's path to production while low-quality data may cause expensive delays and a poor performing model. The model learns to “see” based on what it is given, so ensuring that your training data is accurate and representative of what the model will need to evaluate in production is paramount to success.
To create robust training data, your AI team will need to start by gathering a relevant, diverse dataset. For the e-commerce example mentioned earlier, the dataset would need to include images of every type of item in their catalog. If the training dataset consisted only of images of tops, the model wouldn’t be able to wear pants or dresses. Gathering a dataset for this use case is relatively simple since presumably the company would already have images of every item they’re selling.
However in some other use cases, this data may not be so easy to get. For example, an AI team tackling a medical imaging use case might have a much more difficult task in gathering the necessary data due to privacy restrictions, a lack of demographic variety in the available data, or variations caused by different cameras or microscopes, etc.
Once a dataset has been gathered, the team will need to annotate each image by drawing bounding boxes or segmentation masks over each object and carefully labeling them according to the project guidelines in order to train the computer vision model. These guidelines will be the basis for the dataset’s ontology — the organizational system that classifies each item identified in the dataset.
For example, a machine learning model being trained to identify and assess the ripeness of bananas might use an ontology like this:
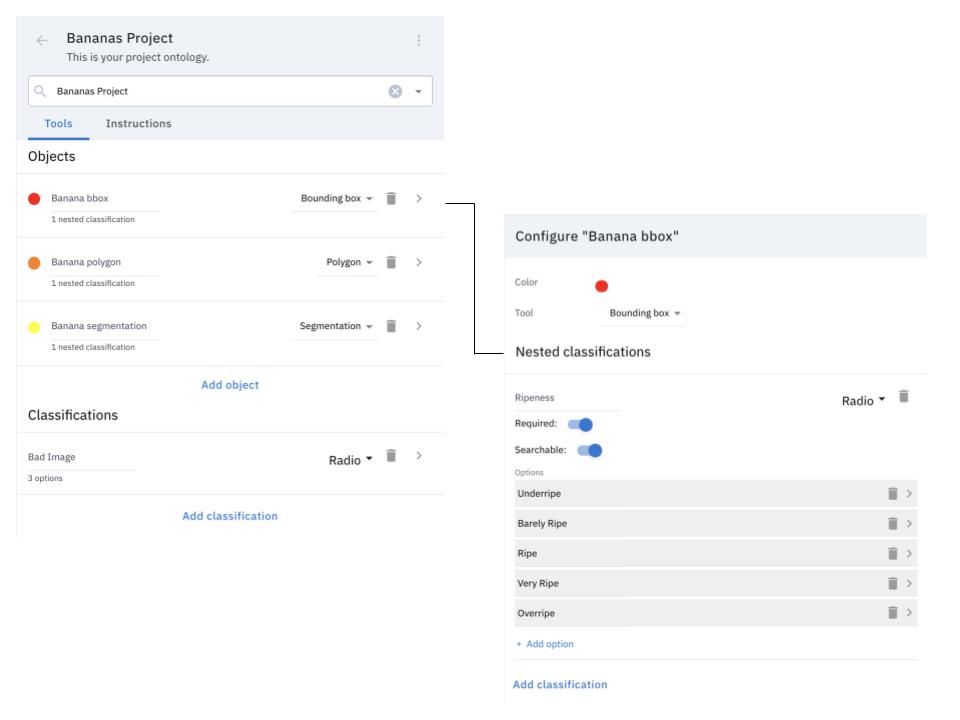
Categorizing every item pictured in a dataset is more complicated than it sounds. The team needs to take the following into consideration:
- The geographic location of those who are labeling images as names of items can differ widely in different places. For example, “pants” has a different meaning in the United Kingdom than it does in the United States.
- How to nest categories. Will the model recognize a jumpsuit as a type of pants, a type of dress, or will it get its own category?
- How they’ll address any ambiguities that come up during the process.
One of the best impact-for-cost actions an AI team can take to improve model performance is by iterating and updating the annotations, ontology, along with labeling guidelines, to fine tune the outputted training data, while they train and iterate on the model itself.
Training, assessing, and iterating on your computer vision model
Once the AI team has generated the first training dataset, they’ll feed the dataset into the model and assess its accuracy. The AI engineers might determine where the model has the lowest accuracy — for example, it might have extra difficulty finding the difference between long-sleeved shirts from sweaters — and use that information to create another dataset consisting mainly of long-sleeved shirts and sweaters, or update the existing labels on images of these shirts and sweaters, so the model can better identify them.
Usually, the process of getting a computer vision model to production-level accuracy requires multiple training datasets, and the improvement in model performance will generally be smaller with each iteration.
Best practices for enterprise computer vision
Training a computer vision model for an enterprise use case can be an extensive process, but there are a few actions that AI teams can take to ensure a smoother, faster journey to production.
- Establish a robust labeling operation. Data labeling is a fundamental part of the training process as it can make or break your entire AI initiative. Take time to find an experienced labeling team that understands your business requirements, implement quality management systems within your labeling workflow that incorporates domain expertise, and ensure that your entire labeling pipeline, from data lake to model input, is secure and seamless.
- Ensure that you also find the right tools for the job. Fledgling AI teams often use free, open source labeling tools and pull together disparate systems and workforces to annotate their data, using USB drives and spreadsheets to transfer data and organize their operations. However, enterprise teams with the intention to grow would do better to invest in best-in-class solutions. An enterprise-ready AI data engine, for example, will help them scale and securely connect all the people, processes, and data for their needs.To learn more about how an AI data engine can benefit your enterprise computer vision initiatives, read the guide to AI data engines.


