
 All guides
All guidesEvaluating leading text-to-speech models

To explore our latest in speech generation evaluation, visit Labelbox leaderboards. By leveraging our modern AI data factory, we're redefining AI evaluation. Our new, innovative approach combines human expertise with advanced metrics to surpass traditional benchmarks.
The evolution of Text-to-Speech (TTS) models has been groundbreaking, with various companies offering high-quality solutions for a range of applications. Whether it's enhancing accessibility, automating customer service, or generating voiceovers, TTS models play a vital role in today's digital landscape.
We recently evaluated the performance of six leading TTS models—Google TTS, Cartesia, AWS Polly, OpenAI TTS, Deepgram, and Eleven Labs—using key evaluation metrics such as Word Error Rate (WER) and human preference ratings.
To provide an in-depth analysis, we evaluated each model on 500 prompts. Each prompt was reviewed by three expert labelers to ensure accuracy and provide diverse perspectives.
Evaluation Process
To capture subjective human preference, we first set up the evaluation project using our specialized and highly-vetted Alignerr workforce, with consensus set to three human raters per prompt, allowing us to tap into a network of expert raters to evaluate speech outputs across several key criteria:
Word Error Rate (WER)
WER measures the accuracy of the generated speech by calculating the number of insertions, deletions, and substitutions compared to a reference transcription. The lower the WER, the better the model performed in terms of generating accurate and coherent speech.
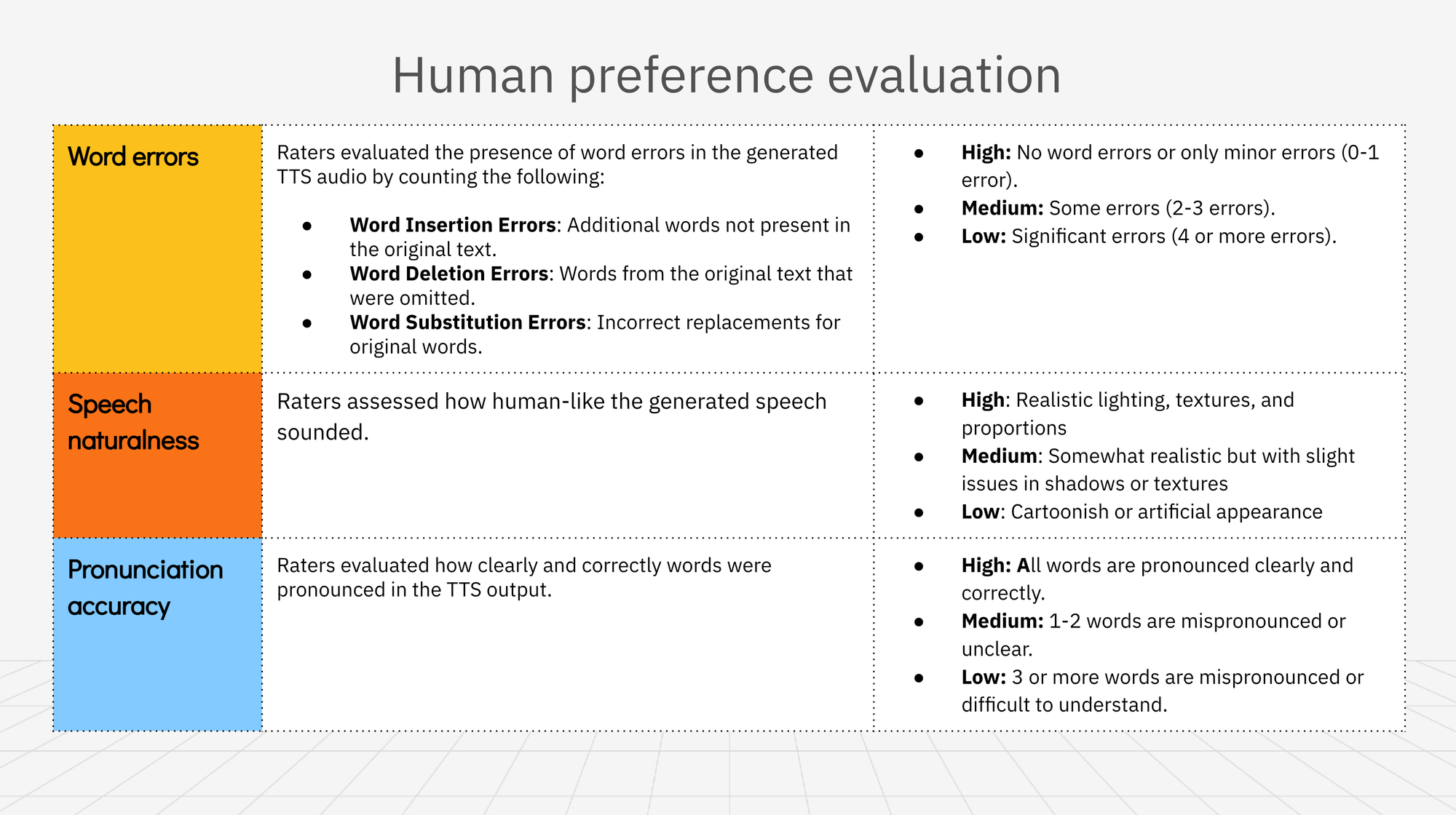
Word errors
Raters evaluated the presence of word errors in the generated TTS audio by counting the following:
- Word Insertion Errors: Additional words not present in the original text.
- Word Deletion Errors: Words from the original text that were omitted.
- Word Substitution Errors: Incorrect replacements for original words.
Scoring
- High: No word errors or only minor errors (0-1 error).
- Medium: Some errors (2-3 errors).
- Low: Significant errors (4 or more errors).
Speech naturalness
Raters assessed how human-like the generated speech sounded.
Scoring
- High: Very human-like, natural flow with appropriate pauses and inflections.
- Medium: Some human qualities but with occasional robotic or awkward elements.
- Low: Clearly robotic or artificial, with choppy or monotone speech.
Pronunciation accuracy
Raters evaluated how clearly and correctly words were pronounced in the TTS output.
Scoring
- High: All words are pronounced clearly and correctly.
- Medium: 1-2 words are mispronounced or unclear.
- Low: 3 or more words are mispronounced or difficult to understand.
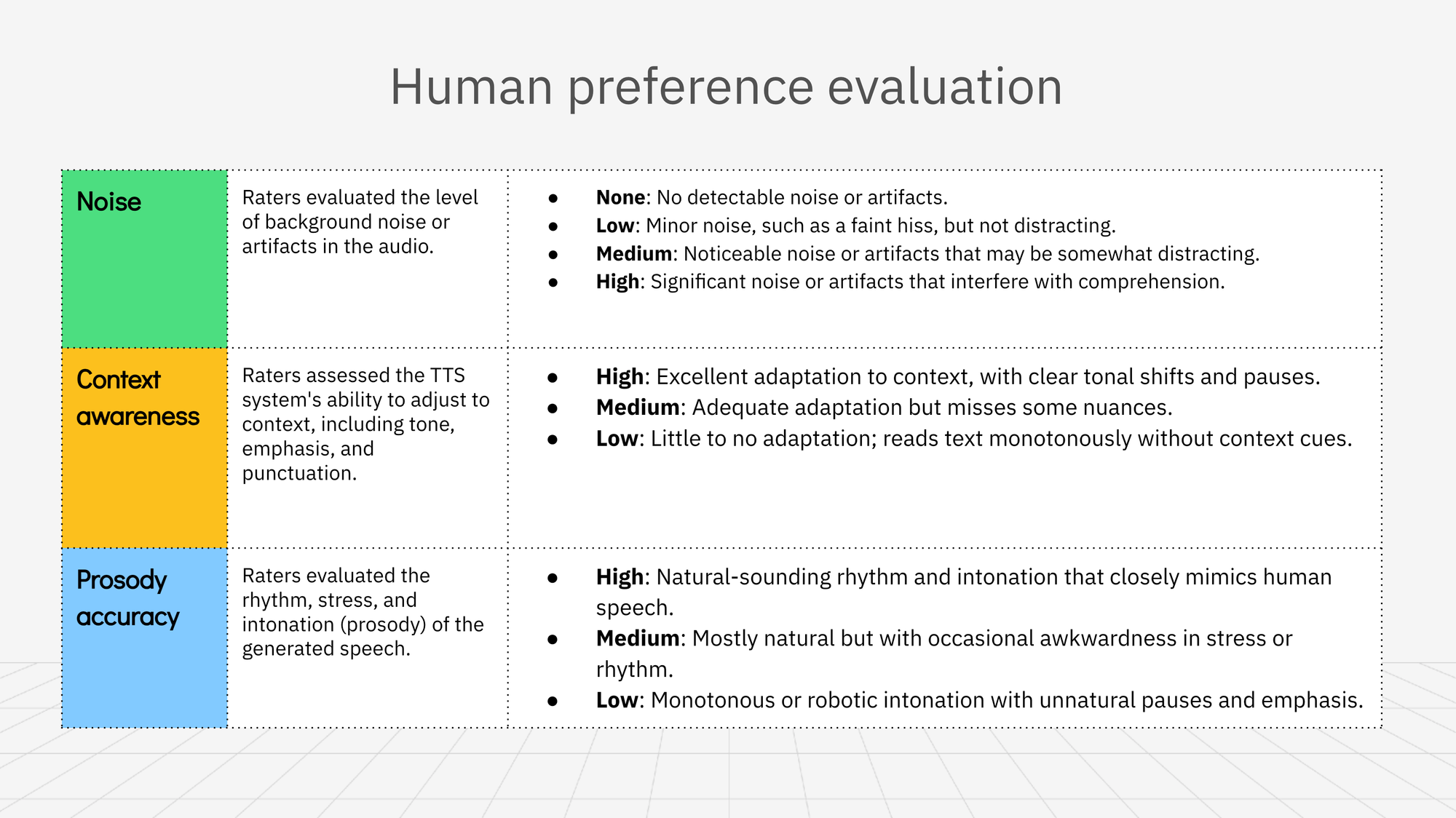
Noise
Raters evaluated the level of background noise or artifacts in the audio.
Scoring
- None: No detectable noise or artifacts.
- Low: Minor noise, such as a faint hiss, but not distracting.
- Medium: Noticeable noise or artifacts that may be somewhat distracting.
- High: Significant noise or artifacts that interfere with comprehension.
Context awareness
Raters assessed the TTS system's ability to adjust to context, including tone, emphasis, and punctuation.
Scoring
- High: Excellent adaptation to context, with clear tonal shifts and pauses.
- Medium: Adequate adaptation but misses some nuances.
- Low: Little to no adaptation; reads text monotonously without context cues.
Prosody accuracy
Raters evaluated the rhythm, stress, and intonation (prosody) of the generated speech.
Scoring
- High: Natural-sounding rhythm and intonation that closely mimics human speech.
- Medium: Mostly natural but with occasional awkwardness in stress or rhythm.
- Low: Monotonous or robotic intonation with unnatural pauses and emphasis
Prompts curation process
The diverse set of prompts used in our TTS evaluation provides a comprehensive test of model capabilities across multiple dimensions.
Consider these examples:
"Wow! Did you see the fireworks last night? They were spectacular!"
This short, exclamatory sentence tests the model's ability to convey excitement and emphasis. It challenges the TTS system to appropriately modulate tone and pitch to express enthusiasm.
"I wish you were on the right path...I-I-I truly do, but you're not,' he said sadly."
This prompt evaluates the model's handling of emotional nuance, hesitation (indicated by the stuttering "I-I-I"), and the use of ellipsis for pauses. It also tests the system's ability to convey sadness as specified in the dialogue tag.
"Alright, listen up, team! The mission briefing is as follows: Operation Nighthawk commences at 0300 hours. Rendezvous at coordinates 51°30'26.5"N 0°07'39.0"W. Your login credentials for the secure server are: Username: NightOwl_Alpha, Password: 3ch3l0n_X9#. Remember, this is a stealth operation. Radio silence must be maintained except for emergency protocol Sierra-Tango-Seven. If compromised, use the failsafe code: Zulu-Yankee-4-7-2-Bravo. Any questions? No? Then synchronize your watches... now. Good luck, and godspeed."
This complex prompt tests multiple aspects:
- Technical pronunciation of alphanumeric strings and military jargon
- Conveying urgency and authority
- Handling of coordinates and precise numerical information
- Proper pacing for a lengthy, detailed instruction set
- Appropriate pausing, indicated by punctuation and paragraph breaks
These prompts demonstrate how we cover a range of linguistic features, emotional tones, and formatting challenges. They span from simple exclamations to complex, technical instructions, ensuring a thorough assessment of prosody, emphasis, and versatility.
This diversity in prompts matters because it enables a comprehensive evaluation that reflects real-world applicability. By covering such a broad spectrum of scenarios, we can identify specific strengths and weaknesses in each TTS model, allowing for fair comparisons and pinpointing areas for improvement. Whether it's expressing joy over fireworks, conveying emotional conflict, or delivering a detailed mission briefing, these prompts help us ensure that TTS models can handle the variety and complexity of human communication.
Overall Ranking best to worst model samples
Raters ranked each TTS sample from best to worst based on performance across all categories above.
Model configurations used at test time
- OpenAI
- Model: tts-1-hd
- Voice: alloy
- Google Text-to-Speech (TTS)
- Model: Default
- Voice: Default with neutral gender voice
- ElevenLabs
- Model: eleven_monolingual_v1 (As of 30th September, eleven_monolingual_v1 is an outdated version and Labelbox will run a new experiment with eleven_multilingual_v2 in the future)
- Voice: pMsXgVXv3BLzUgSXRplE
- Deepgram
- Model: aura-asteria-en
- Voice: Default
- Amazon Polly
- Model: Generative
- Voice: Ruth
- Cartesia
- Model: sonic-english
- Voice: Teacher Lady
We selected these models for our evaluation as they represent the cutting-edge offerings from leading companies in the TTS space, showcasing the latest advancements in voice synthesis technology.
Results
Our evaluation of 500 diverse and complex prompts provided valuable insights into the capabilities of Google, Cartesia, AWS Polly, OpenAI, Deepgram, and Eleven Labs TTS models. Each prompt was meticulously assessed by three different raters to ensure accurate and diverse perspectives. This rigorous testing highlighted the strengths and areas for improvement for each model.
Let's delve into the insights and performance metrics of these leading TTS models:
Rank distribution percentages
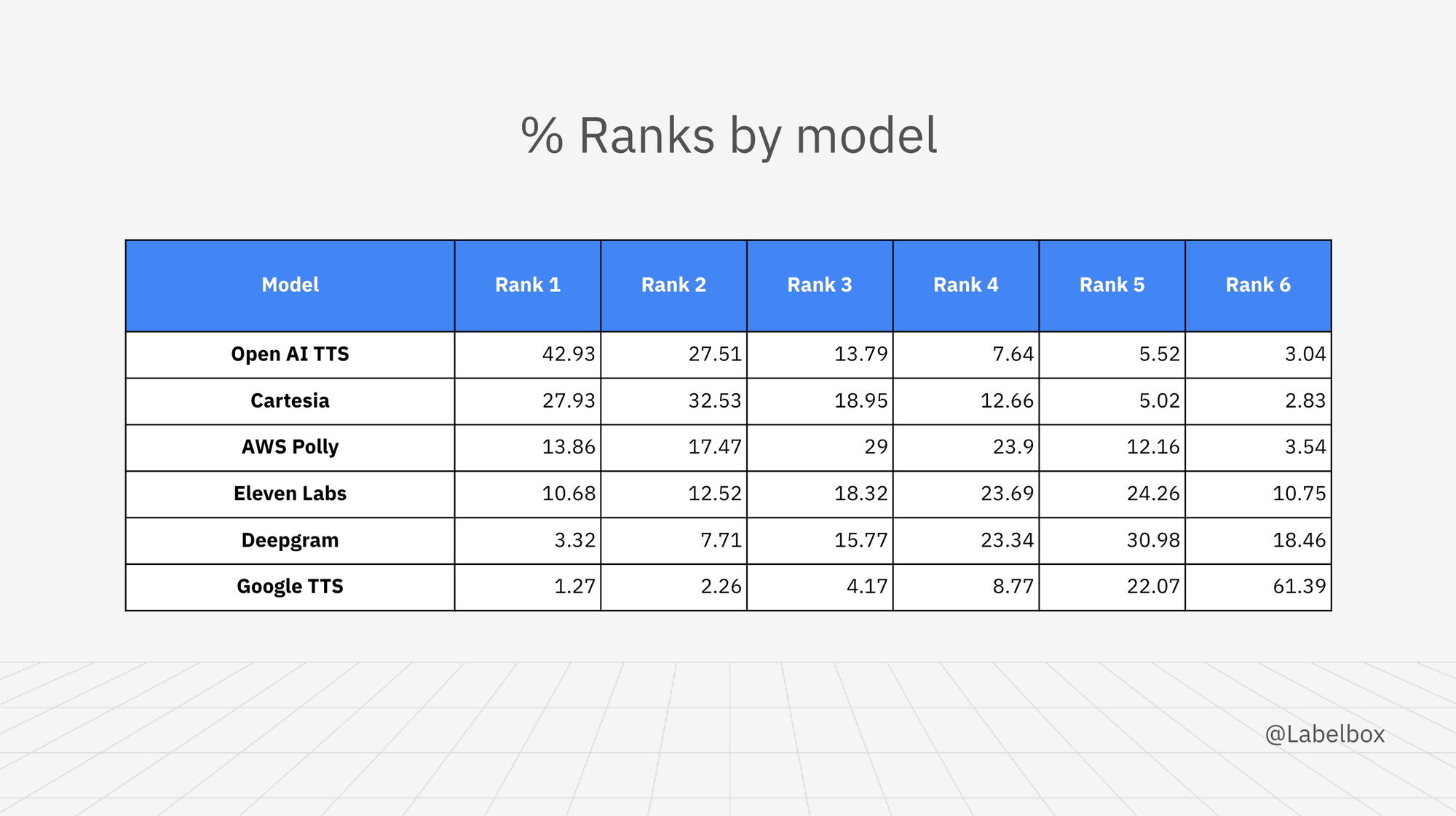
Overall ranking
- Rank 1: (Open AI TTS) - occurred 607 times, 42.93%
- Rank 2: (Cartesia) - occurred 460 times, 32.53%
- Rank 3: (AWS Polly) - occurred 410 times, 29.00%
- Rank 4: (AWS Polly) - occurred 338 times, 23.90%. Followed by Eleven labs as a close second with occurrence 335, 23.69%
- Rank 5: (Deepgram) - occurred 438 times, 30.98%
- Rank 6: (Google TTS) - occurred 868 times, 61.39%
Note: Rank is determined by the most frequently selected model for each position, which is why some AWS Polly appears twice.
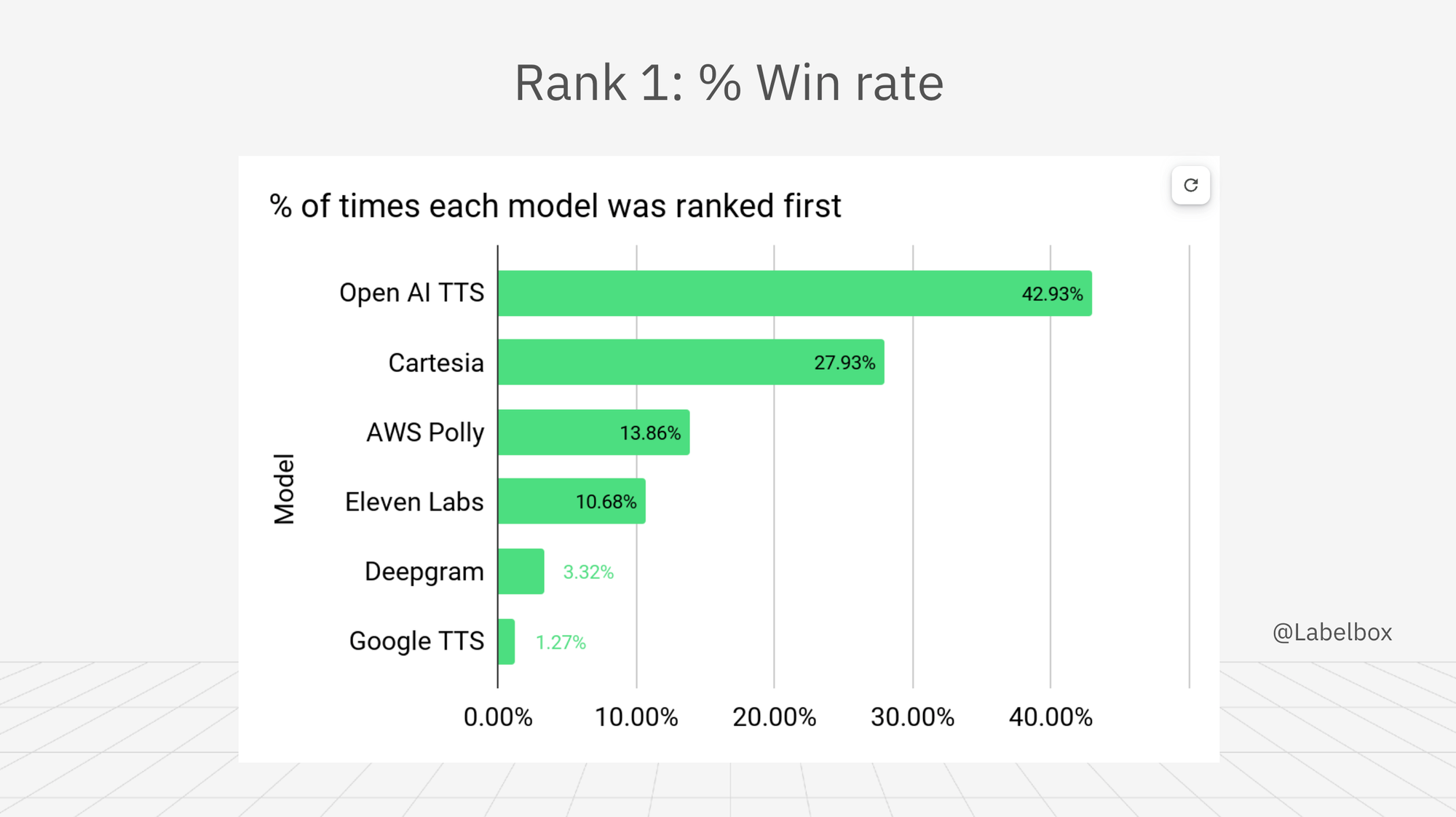
Fig: % of times each model was ranked first.
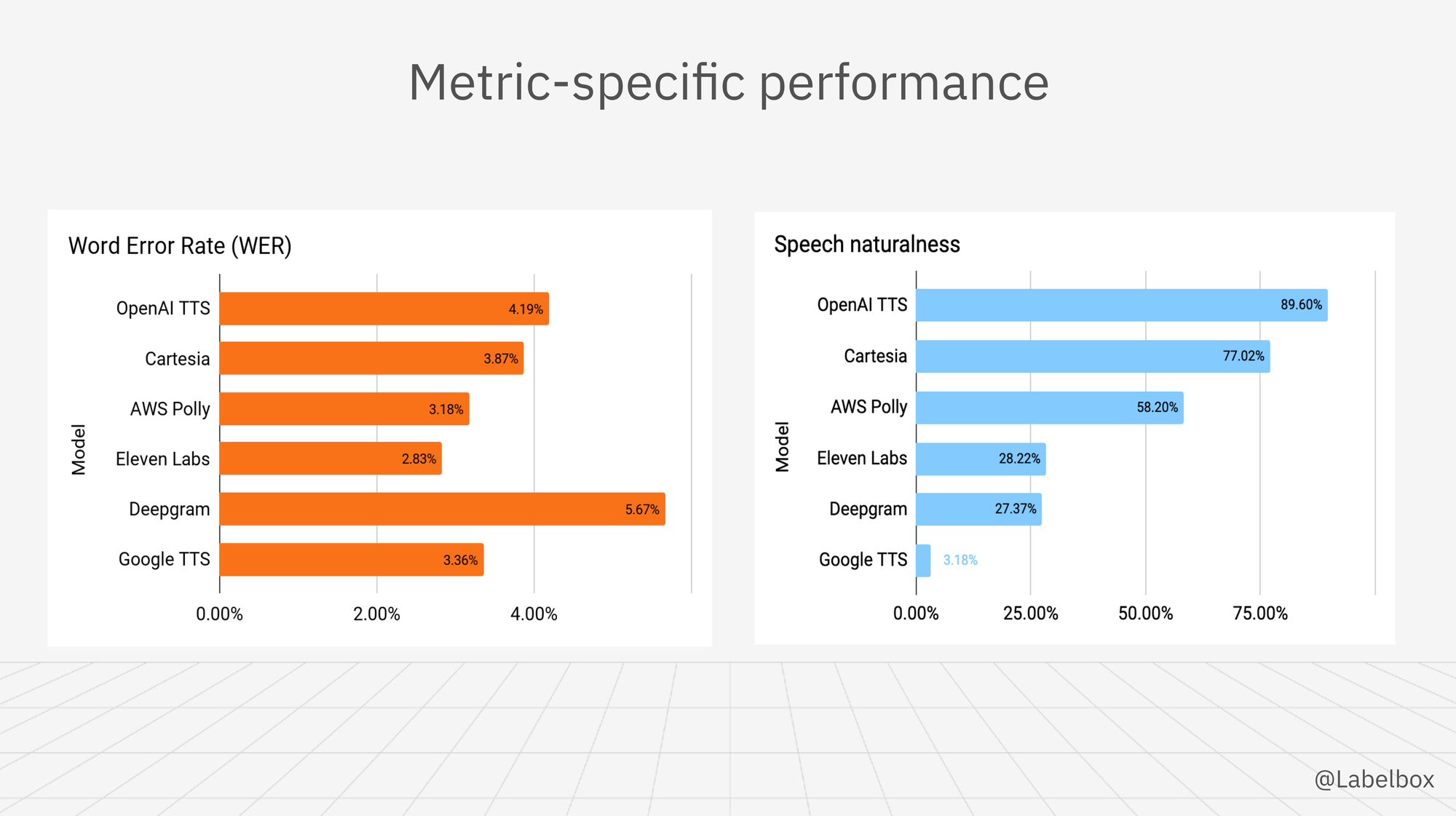
Word Error Rate (WER) Results
The WER scores offer an objective look at how accurately each model converts text to speech.
- Deepgram: 5.67%
- OpenAI TTS: 4.19%
- Google TTS: 3.36%
- AWS Polly: 3.18%
- Cartesia: 3.87%
- Eleven Labs: 2.83%
Eleven Labs achieved the lowest WER at 2.83%, making it the most accurate model. Deepgram, however, had the highest WER at 5.67%, indicating room for improvement in transcription accuracy.

Model-Specific Performance Results
Let's understand the relative strengths and weaknesses of each TTS model based on key evaluation criteria.
OpenAI TTS
- Word Error Rate (WER): 4.1898%
- Speech naturalness: High in 89.60% of cases
- Pronunciation accuracy: High in 87.13% of cases
- Noise: None in 92.29% of cases
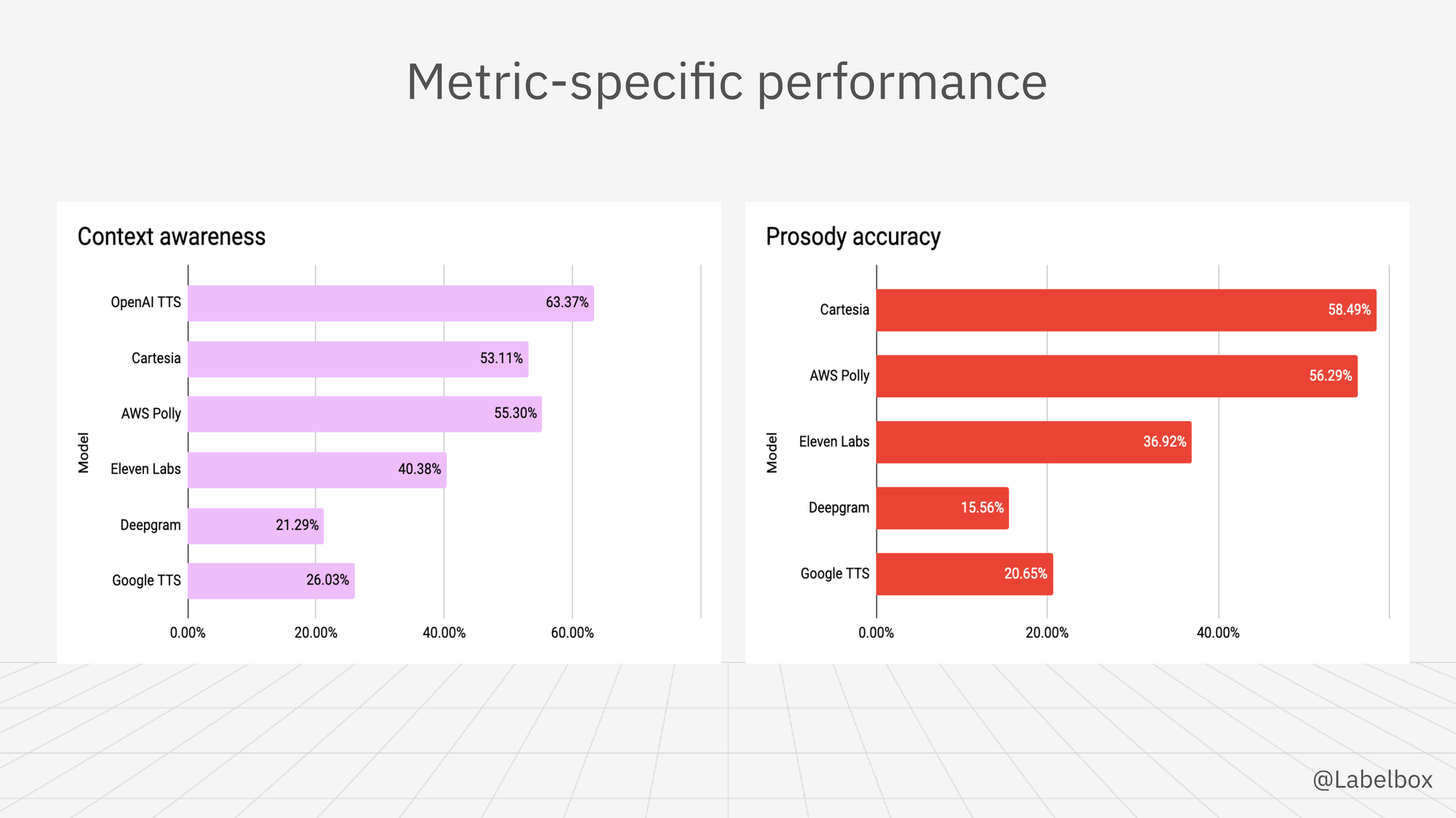
- Context awareness: High in 63.37% of cases
- Prosody accuracy: High in 64.57% of cases
OpenAI TTS excels at producing natural-sounding speech, making it a top choice for applications requiring lifelike vocal output. It demonstrates exceptional accuracy in pronunciation and performs excellently in producing clean audio with minimal background noise. The model shows strong capabilities in understanding and conveying contextual nuances in speech and is proficient in delivering appropriate intonation and rhythm. Despite ranking high in human preference, it shows moderate accuracy in word reproduction.
Examples
Cartesia
- Prosody accuracy: High in 58.49% of cases
- Context awareness: High in 53.11% of cases
- Noise: None in 93.49% of cases
- Pronunciation accuracy: High in 80.98% of cases
- Speech naturalness: High in 77.02% of cases
- Word Error Rate (WER): 3.8707%
Cartesia demonstrates good accuracy in word reproduction. While not as consistent as OpenAI TTS in naturalness, it still performs very well in producing natural-sounding speech. It shows excellent accuracy in pronunciation and excels at producing clean audio with minimal background noise. The model displays good capabilities in understanding contextual nuances and performs well in delivering appropriate intonation and rhythm.
Examples
AWS Polly
- Prosody accuracy: High in 56.29% of cases
- Context awareness: High in 55.30% of cases
- Noise: None in 89.39% of cases
- Pronunciation accuracy: High in 84.72% of cases
- Speech naturalness: Medium in 58.20% of cases
- Word Error Rate (WER): 3.1770%
AWS Polly shows very good accuracy in word reproduction, ranking second among the models. It struggles more with producing natural-sounding speech compared to top performers but maintains excellent pronunciation accuracy. The model performs well in producing clean audio and shows good capabilities in understanding contextual nuances and delivering appropriate intonation and rhythm.
Examples
Eleven Labs
- Word Error Rate (WER): 2.8302%
- Speech Naturalness: Medium in 44.98% of cases
- Pronunciation Accuracy: High in 81.97% of cases
- Noise: None in 80.27% of cases
- Context Awareness: Medium in 44.70% of cases
- Prosody Accuracy: Medium in 46.25% of cases
Eleven Labs demonstrates the best accuracy in word reproduction among all models. It shows mixed results in producing natural-sounding speech but maintains excellent pronunciation accuracy. The model performs reasonably well in producing clean audio but has more noise issues than some competitors. It shows moderate capabilities in understanding contextual nuances and has room for improvement in delivering appropriate intonation and rhythm.
Examples
Deepgram
- Word Error Rate (WER): 5.6743%
- Speech Naturalness: High in 57.78% of cases
- Pronunciation Accuracy: High in 64.43% of cases
- Noise: None in 88.83% of cases
- Context Awareness: Medium in 53.18% of cases
- Prosody Accuracy: Medium in 55.52% of cases
Deepgram shows the highest error rate in word reproduction among all models. It performs moderately well in producing natural-sounding speech and demonstrates good accuracy in pronunciation, although lagging behind some competitors. The model performs well in producing clean audio with minimal background noise but shows moderate capabilities in understanding contextual nuances and delivering appropriate intonation and rhythm.
Examples
Google TTS
- Word Error Rate (WER): 3.3574%
- Speech naturalness: Low in 78.01% of cases
- Pronunciation accuracy: High in 77.30% of cases
- Noise: None in 89.46% of cases
- Context awareness: Medium in 39.25% of cases
- Prosody accuracy: Low in 45.83% of cases
Examples
Conclusion
Our comprehensive evaluation reveals that while Eleven Labs leads in transcription accuracy with the lowest WER, OpenAI TTS emerges as the top choice when it comes to human preference, particularly for speech naturalness, pronunciation accuracy, and prosody.
Conversely, Google TTS, despite a relatively low WER, ranks last in human preference due to poor performance in categories like speech naturalness and context awareness. This demonstrates the importance of a balanced evaluation that considers both quantitative metrics like WER and qualitative factors like user satisfaction.
As the TTS field continues to evolve, the key to further advancements will lie in combining high transcription accuracy with natural, expressive, and context-aware speech. Models like OpenAI TTS and Eleven Labs are setting the standard, but there remains room for improvement across all models to fully meet the growing demands of diverse TTS applications.
In summary, while WER is crucial, the broader context of user experience—focusing on factors like speech naturalness, context awareness, and prosody accuracy—is essential in evaluating the overall effectiveness of TTS models.
Get started today
The comprehensive approach to evaluating text-to-speech models presented here represents a significant advancement in assessing AI-generated speech. By leveraging this methodology alongside Labelbox's cutting-edge platform, AI teams can dramatically accelerate the development and refinement of sophisticated, domain-specific speech generation models.
Our solution offers:
- Efficient dataset curation
- Automated evaluation techniques
- Human-in-the-loop quality assurance
- Customizable workflows for TTS model assessment
If you're interested in implementing this evaluation approach or leveraging Labelbox's tools for your own text-to-speech model assessment, sign up for a free Labelbox account to try it out, or contact us to learn more.



