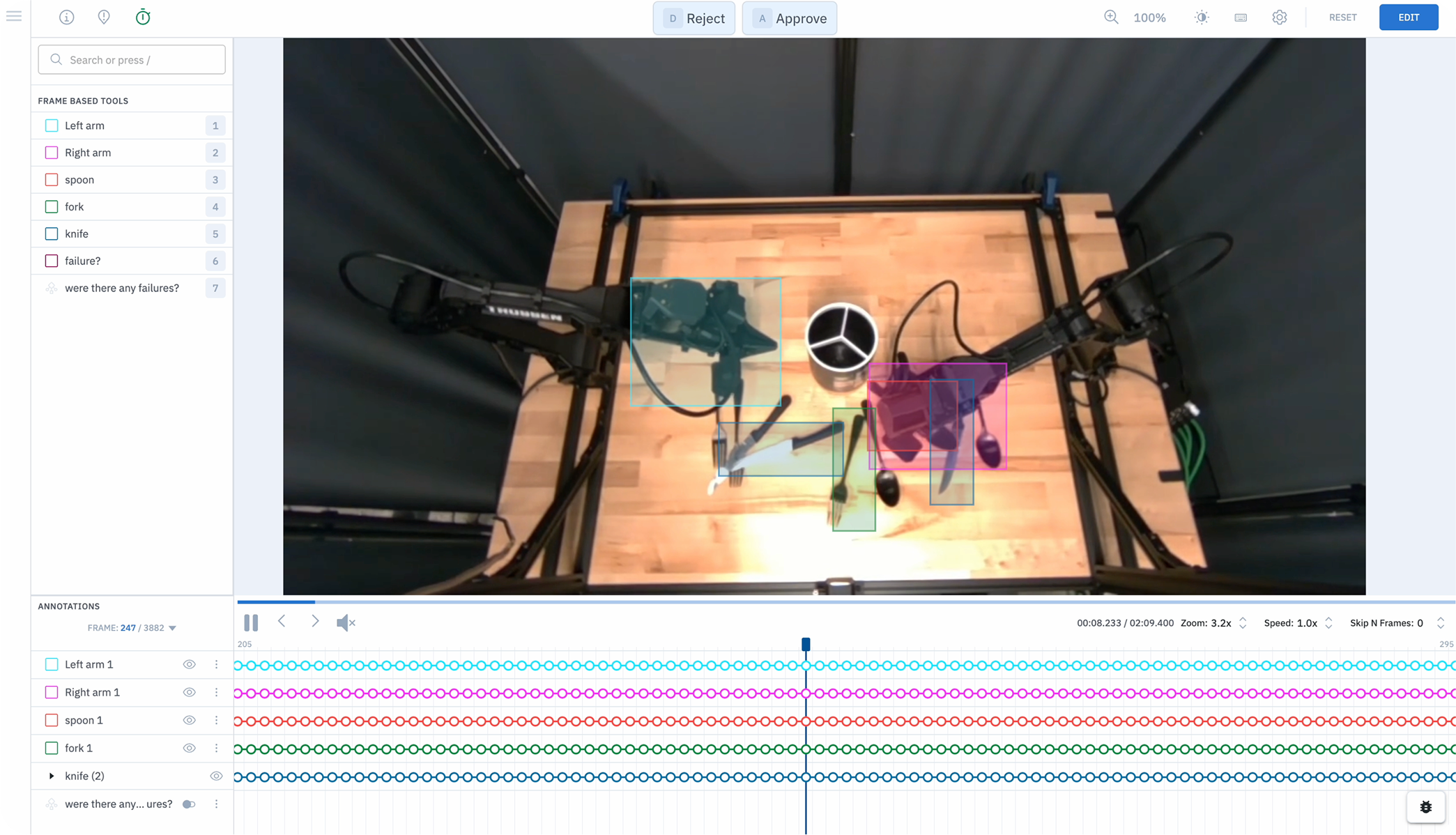
From teleoperation to general-purpose intelligence, advance your AI-driven robotics capabilities with cutting-edge data and highly skilled operators from Labelbox
From code generation to constraint programming, Labelbox provides leading AI labs with the trainers and tools needed to advance the coding capabilities of frontier models
Build the next generation of AI agents and solve the training bottleneck with scalable, human-based trajectory training and evaluation
Supercharge your reinforcement learning with verifiable rewards (RLVR) pipeline to improve your model’s reasoning and planning capabilities–essential skills for the next generation of AI agents
Train AI to think critically and solve the world’s most complex problems, from human-like chain-of-thought (CoT) to advanced mathematics to sophisticated coding challenges.
Advance your GenAI audio capabilities, from multi-turn conversations to real-time translation, with studio-grade audio data and human evaluations from Labelbox
Train apps and GenAI models to better recognize and understand the structure and content of an image for accurate generation and manipulation of visual tasks
Enable continuous improvement and optimization to ensure your GenAI models evolve and adapt to diverse user preferences over time with reinforcement learning.
Train GenAI models with new responses to track ongoing situational and contextual interactions and engage in coherent, natural dialogue
Identify the emotional tone and opinion expressed in GenAI model responses or simple text data for greater insights and holistic, context-aware responses
Enable cross-lingual capabilities and improve multilingual understanding in generative AI models to help bridge language gaps.
Categorize text data, train models to produce contextually accurate responses, or fine-tune models to classify inputs into specialized categories and predefined classes of text.
Produce human-like, contextually accurate content for summarization, translation, and other multimodal applications.
Automatically categorize images to understand their content and patterns so apps and GenAI models can make accurate decisions based on image classifications.
Create high-quality, multilingual datasets to train your AI models to understand and serve users across diverse languages and cultures
From text-to-video generation to video analysis, Labelbox provides proven tools and expert services to help differentiate your generative AI video models
Guide image and video generation, text-to-image/text-to-video synthesis, scene composition and more with detailed spatial and semantic information about objects in an asset.
Train models to generate images for text-to-image applications or provide training sets to help models understand and describe what’s show in an image for more human like engagement
Unlock a new generation of AI capabilities by generating high-quality data and performing expert-led human evaluations to train your models on text, images, video, and audio data
Get started for free or see how Labelbox can fit your specific needs by requesting a demo