
 All blog posts
All blog postsLabelbox•May 15, 2025
Prompt to production: How to improve AI app generators with rubric evals

The ability to transform a simple text prompt into a fully functional web application is no longer science fiction. Functional "prompt-to-app" or "AI app generator" solutions are rapidly emerging and fueling the next evolution in coding capabilities of frontier models.
As this new frontier expands, the journey from an initial AI-generated app to a sophisticated, secure, and user-friendly production-ready application is fraught with challenges. To truly unlock the transformative power of AI app generators, the underlying frontier models require detailed training data and robust evaluation frameworks—precisely what Labelbox delivers to help build more reliable, versatile, and intelligent AI-powered development tools.
Read on to learn about the most common hurdles facing today’s AI app generators and to learn about our approach to helping them improve their prompt-to-app coding capabilities.
What are AI app generators and prompt-to-app tools?
AI app generators, also known as prompt-to-app or AI app builder solutions, use frontier AI models to translate user prompts directly into fully functional, standalone web applications. Startups like and Bolt, Lovable and Tempo along with offerings like v0 from Vercel are at the forefront of the AI app generator landscape.
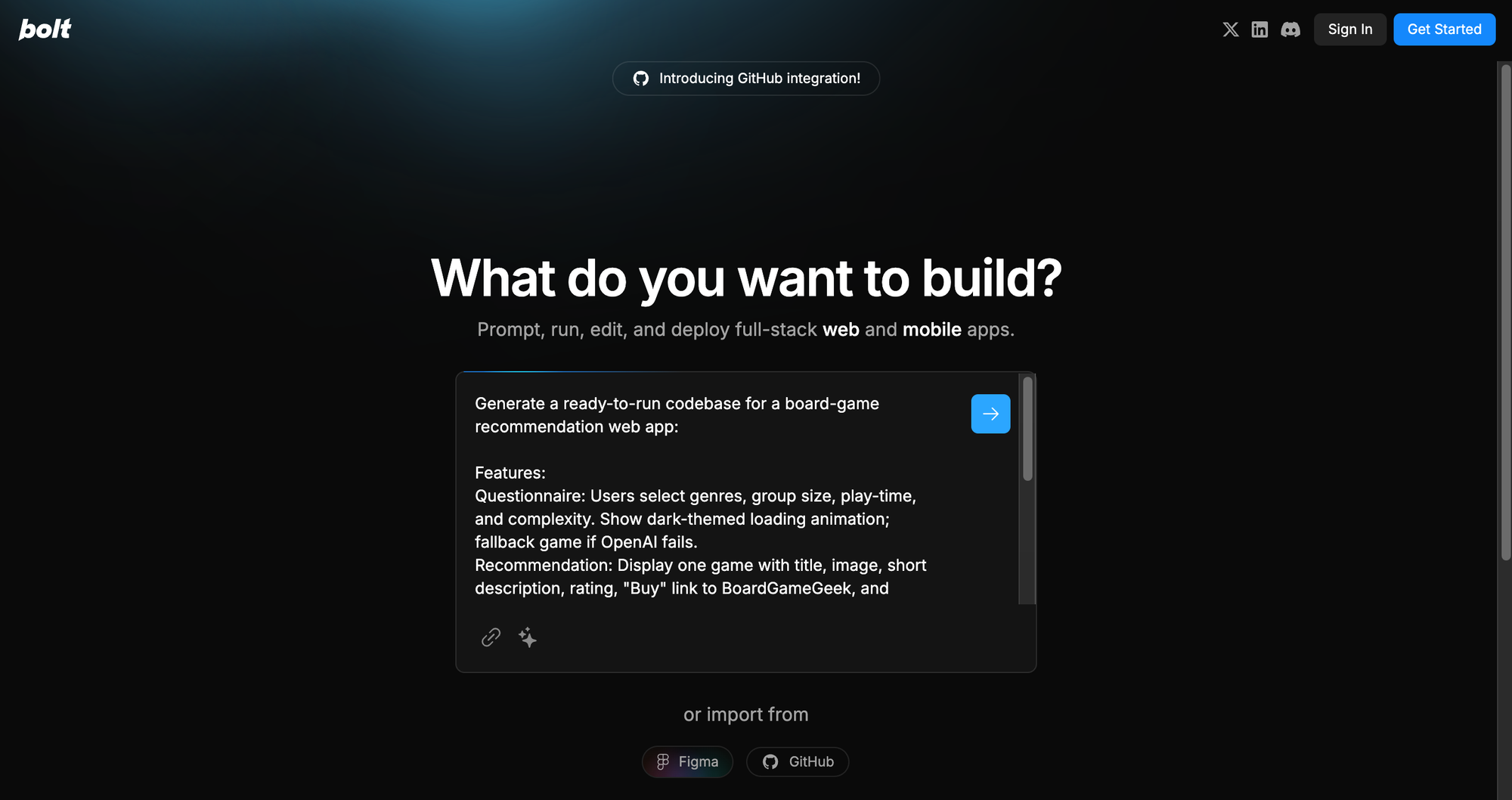
This technology marks a transformative shift in software development by allowing users, regardless of their coding expertise, to create interactive and dynamic products simply by describing their intentions in natural language. They offer a new level of abstraction where natural language and visual concepts replace traditional SDKs and frameworks.
These AI app generators are a significant focus for AI labs today due to the immense potential they hold and the rapidly growing demand for such capabilities. The ability to seamlessly convert user intentions into robust applications represents a new competitive frontier for both foundational AI model developers and coding application startups. Leading AI labs are investing heavily in this area to push the boundaries of AI and deliver truly transformative tools that can significantly lower the barrier to software creation.
Hurdles: Why today's AI app generators need a boost
While the early successes of AI app generators are impressive, persistent challenges hinder their full potential. Current platforms often struggle with:
- Interpreting complex user needs: Translating nuanced or intricate user requirements into accurate application logic remains a significant hurdle.
- Ensuring code quality and security: The generated code may lack the robustness, security standards, and efficiency required for production environments.
- Crafting intuitive user experiences: Creating truly engaging and intuitive user interfaces (UI) and user experiences (UX) through AI alone is a complex task.
- Addressing "big-picture" thinking: AI models can falter when tasks require a deep contextual understanding of how different components of an application interconnect or how changes in one area impact others.
- Avoiding bias: AI models can inadvertently perpetuate biases present in their training data, leading to unfair or skewed application behavior.
These limitations highlight that while AI can significantly lower the barrier to entry for application creation, the path to deploying complex and reliable software requires a more refined approach.
How to elevate AI app generators with superior data and evaluation?
Significant advancements in two core areas are crucial to overcoming these challenges: data and evaluation. This is where Labelbox's expertise and experience working with leading AI labs to solve this exact problem becomes paramount.
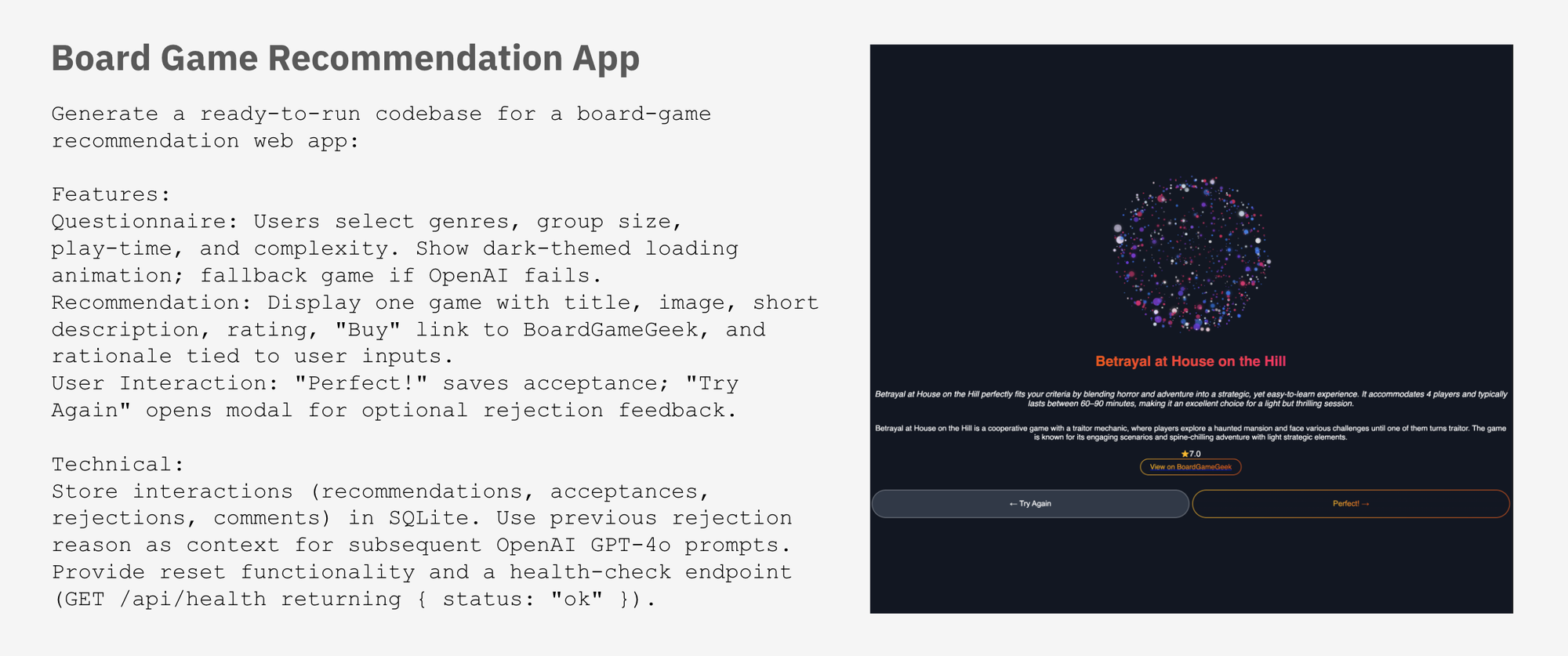
To build more capable prompt-to-app systems, models need to be trained on high-quality, diverse, and highly specific datasets. Labelbox facilitates the creation of these crucial datasets, moving beyond generic code repositories to include:
- Targeted training datasets: We help develop comprehensive suites of meticulously crafted examples, featuring diverse user prompts and their corresponding validated, working application code and structures. This includes specialized data for UI/UX best practices, secure coding standards, and complex application logic.
- Ethical and quality-focused annotation: Ensuring data is annotated with precision and sourced ethically is critical for building fair and capable AI systems.
While, current benchmarks often fall short in assessing the true capabilities of AI app generators, Labelbox champions more holistic and human-centric evaluation methodologies that rigorously measure:
- Functional correctness: Does the application perform as intended based on the prompt?
- Code quality & security: Is the generated code well-structured, efficient, and secure?
- Usability: Is the application intuitive and easy to use?
- Alignment with user intent: How well does the final application match the user's original vision?
This is achieved by employing an integrated methodology, actively providing prompt-to-app data and iterative enhancement for leading AI labs. This framework includes:
- Reviewing model-generated applications: Analyzing prompts and application structures to identify issues.
- Ensuring code executability: Transforming initial AI outputs into fully working web applications.
- Error diagnosis and resolution: Systematically executing applications, documenting failures, and capturing issues for targeted model retraining.
- Iterative model evaluation: Submitting refined prompts and corrected components back to the model, rigorously assessing improvements, and manually resolving persistent issues when necessary. This involves techniques like Reinforcement Learning from Human Feedback (RLHF) to align AI outputs with human preferences.
A detailed framework for this process involves meticulous steps from environment setup and baseline capture to model output evaluation and, if needed, human-crafted "golden solutions" to ensure the highest quality. This iterative feedback loop is essential for refining AI models and fostering a collaborative relationship between human developers and AI.
Defining success: The importance of a comprehensive rubric for evaluation
To objectively improve AI app generators, evaluation must go beyond simple pass/fail metrics. Labelbox advocates for and utilizes comprehensive rubrics to analyze and rate AI-generated web applications across multiple criteria.
These rubrics assess aspects like, but not limited to: core requirements implementation, user interface quality & responsive design, authentication & security, and error handling & performance optimization.
Each criterion is worth a certain number of points, with critical criterion worth more points. An example rubric for web application may look like the following. In this example, an excellent solution scores between 42 and 46 points and then good, satisfactory, needs improvement, and failing solutions fall into point totals below that.
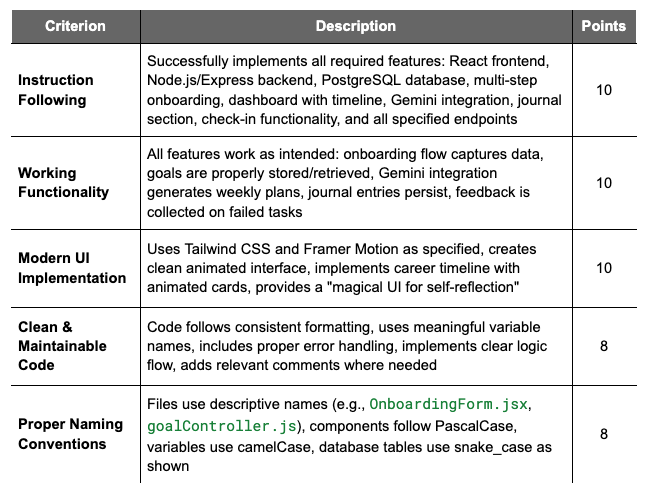
By embracing a detailed evaluation framework, you can gain deeper insights into your model’s performance and identify specific areas for improvement.
Improve prompt-to-app capabilities today
The emergence of prompt-to-app technology represents a monumental shift in software development. While the path to perfecting these AI app generators has its hurdles, the combination of advanced AI models with high-quality, specialized training data and rigorous human-in-the-loop evaluation offers a clear way forward.
Labelbox prides itself on being at the forefront of this evolution, providing the critical data infrastructure and expertise to help train and refine the frontier models that will power the next generation of AI-driven development.


