
 All blog posts
All blog postsLabelbox•November 2, 2023
How the World Series Champions Texas Rangers built a winning team with AI and analytics

When we typically think about data science in baseball, we think about numbers: box scores, the velocity of fastballs, runs batted in (RBI). In short, the science of sabermetrics is based entirely on quantitative data. Any insights based on players’ public perception and their performance history remained in the often limited and heavily biased domain of avid fans and experts who devoted their careers to the sport.
As large language models (LLMs) and generative AI became more widely available, however, one MLB club with an R&D team positioned with the data-driven and innovation-focused culture to experiment with these new technologies began aggregating, cataloging, and running powerful summarization and sentiment analysis procedures on some of the vast amounts of text data pertaining to baseball players, other MLB, minor league, and international teams, baseball beat reporters, and more.
Read on to learn how the Texas Rangers Baseball Club used this text data to inform player drafting and trading decisions and build a team that secured their first World Series win in November 2023. To learn more, watch the on-demand webinar on the topic, featuring Alexander Booth, Assistant Director of R&D at the Texas Rangers Baseball Club.

Building a winning AI strategy for extracting insights from text data
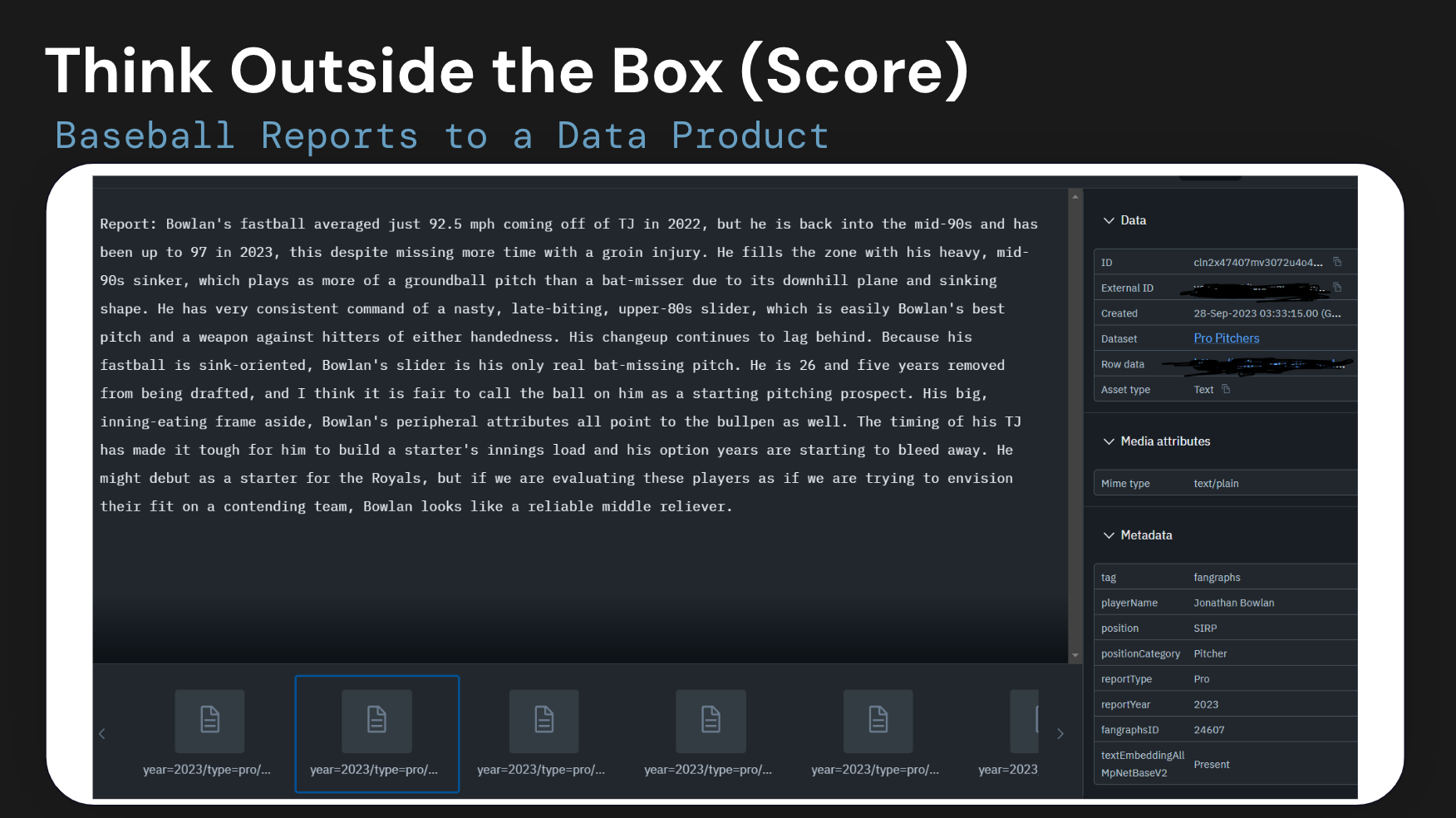
The R&D team at the Texas Rangers Baseball Club drew text data from thousands of scouting reports, articles from various publications and sports journalists, fan-made blogs and media, and more. They then set out to build an LLM-powered solution with the goal of extracting sentiment toward specific players, drawing out statements about their specific strengths and weaknesses, and making the vast amount of data more digestible for their front office decisionmakers at the club.
To organize, catalog, and add metadata to their data, the team chose a cloud-based solution with Databricks. With the Unity Catalog, MLflow, and Delta Lake solutions, the team erased silos within their disparate data scientists and implemented an efficient way to store and manage their unstructured data.
Before processing this data through any LLMs, however, it still needed to be labeled with a complex ontology that included players, teams, publications, writers, date and time, and much more. Every blog post, article, and even tweet needed to be tagged with this information. The Rangers’ R&D team decided on a software-first approach and chose Labelbox as their solution, which was easily integrated with their Databricks Delta Lake via the Python SDK developed by the two technology partners.
In addition to a robust, intuitive labeling system, Labelbox also provided Model Foundry, a new solution that enabled the team to integrate and experiment with various LLMs. With Model Foundry, they were able to leverage LLMs to add structure to raw data, pre-labeling text data by finding references to specific players. This process helped the team to prioritize specific data for manual labeling, ensuring that data relevant to current projects and enabled their front office to discover player insights quickly and easily.
“We love our initial use of Model Foundry. Instead of going into one of these unstructured text datasets blindly, we can now use pre-existing LLMs to pre-label the data or pre-tag some parts of it, like finding all the references to names of players in articles….There are a lot of pre-trained models in there like GPT and LLaMA, that you can reference and then run some of these text objects through to find insights. We're definitely utilizing Model Foundry in that regard as a co-pilot for training data,” says Alexander Booth, Assistant Director of R&D of the Texas Rangers Baseball Club in a recent webinar.
With Databricks and Labelbox, the Rangers R&D team built a successful automated ML lifecycle. Their scripts scraped and transported text data into their Delta Lake, transformed and cataloged that data Databricks solutions, used the Python SDK to upload data into Labelbox for pre-labeling via LLMs and then manual labeling, and sent back into Databricks along with new labels for training. Labelbox is also used for model evaluation afterwards to ensure improvement and set the direction for their next iteration cycle.
Making AI-powered, data-driven, game-changing decisions
Adding players to an MLB baseball team hasn’t been solely based on intuition since The Oakland A’s implemented their winning moneyball strategy. Today, the Texas Rangers take it even further by leveraging text data pertaining to players’ past performances, strengths, and weaknesses to inform player acquisition decisions. Two of their players, Evan Carter and Josh Young, were drafted early in their careers. The decision to draft them was informed by scouting reports and articles about their high school and college games — information usually ignored by MLB teams.
Acquiring players is far from the only data-driven decision that the Rangers make. Coaching and training strategies are informed by players’ strengths, skills, and performance. Each players’ performance, including reaction times, aim, strength, etc. are analyzed and taken into account, ensuring that each player receives training personalized to them and maximize their improvement on the field.
All players in the club also receive digestible information about opposing players and their typical tactics and strengths, powered by AI-driven insights, to enable them to make informed in-game decisions.
"I think that investing in AI and machine learning is one of the best decisions that any sports organization can make, for both increasing player value and aiming to win every pitch, play, and shot, and from there, trying to win the game,” says Booth.
The Rangers are also focused on making data available and accessible more widely within the club. “In my opinion, if anyone in the Rangers has a question that can be answered with data, they should be empowered to go find those answers themselves,” says Booth. The team is also exploring AI-powered solutions based on video data to analyze games, player performances, and study specific biomechanics and movements that cause injuries.
The team is also making plans to elevate the fan experience as they head to the 2024 Major League Baseball All-Star Game, which they will be hosting at their home stadium in Arlington, Texas next July. Projects in the works include a chatbot that fans can use for specific questions about stadium rules, discounts based on past pre- and post- game trips to local restaurants and attractions, and fan acquisition plans that center on drawing soccer fans arriving to the area for the 2026 FIFA World Cup.
When it comes to building a winning AI strategy, the results speak for themselves. On November 1, 2023, the Texas Rangers, a team built and trained with information extracted via AI, became World Series champions for the first time.


