
 All blog posts
All blog postsLabelbox•April 18, 2025
New Complex Reasoning Leaderboard: Gemini 2.5 debuts at the top

Adding to our suite of Labelbox Leaderboards covering image, video, audio, and multimodal reasoning, we are thrilled to unveil a brand new evaluation: the Complex Reasoning Leaderboard. As frontier models become increasingly powerful, understanding their core reasoning and problem-solving capabilities is paramount.
This new leaderboard rigorously assesses top AI models against some of the most demanding tasks available today. We performed a series of simulations that tested a broad variety of reasoning capabilities, ranging from pure mathematics and programming assessments, to temporal, spatial and more abstract forms of reasoning. Leveraging intricate evaluations designed and executed by our expert Alignerr network, we've captured crucial insights into how the latest AI models perform.
We're excited to share these findings, offering the AI community a clear, data-driven view into the current state-of-the-art for AI reasoning.
Complex reasoning leaderboard methodology
Our methodology for the new AI reasoning leaderboard focuses on three key principles:
- Diverse problem sets: We curated a battery of difficult problems across multiple domains, ensuring a rigorous assessment of each model’s ability to think critically.
- Comprehensive metrics: Beyond core accuracy in providing the right answer, our tests measured consistency, efficiency, and the quality of reasoning behind each solution.
- Advanced mathematics: By incorporating deeply theoretic and advanced mathematical reasoning components, we simulated challenges that AI systems might have in advanced STEM-related reasoning tasks.
To build the AI Reasoning Leaderboard, we first defined key reasoning domains—categories like mathematical reasoning, programming, theoretical computer science, physics, temporal and causal reasoning, as well as more involved topics like scientific inquiry and multi-step solutions.
We then leveraged domain experts from our Alignerr network to craft challenging prompts spanning these areas. The goal was to develop a diverse test set ranging in difficulty, allowing us to effectively distinguish model capabilities—ensuring most prompts challenged top models and included some that were too difficult for all models to correctly solve.
These experts used the Labelbox Platform, which was configured with a comprehensive ontology, to meticulously evaluate model outputs. Their assessment covered both the correctness of the final answer and the validity of the model's reasoning process (chain-of-thought), utilizing structured ratings and blind rankings.
We then collated, weighted, and analyzed this data to generate the final Complex Reasoning Leaderboard, offering insights into overall performance and specific reasoning strengths.
Findings: Complex reasoning still pushes the limits of current AI reasoning
For our new AI reasoning leaderboard, we challenged the top advanced AI models with a variety of complex problems. From math and physics puzzles to abstract reasoning tasks and coding, we are not only benchmarking the current state of AI reasoning but also identifying key strengths and areas for improvement.
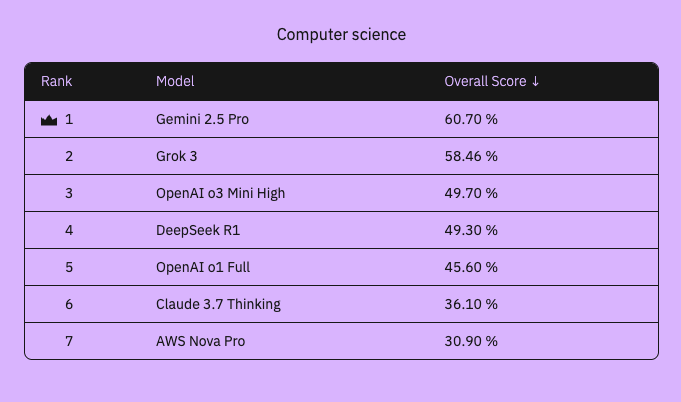
We dig more into the detailed results below, but our overall rankings revealed that Google Gemini jumped to the top of our leaderboards based on our unique, human-centric evaluations on complex AI reasoning.
Performance summary: Room for improvement on all models
Based on our most recent findings, we have determined that we are yet to see any reasoning model reach strong performance on our dataset. That is, no model has yet been able to surpass an aggregate reasoning and correctness score of 75%, and in fact many models have weak performance, which is an aggregate score of under 50%.
These results point to an existent gap in the market, and it highlights a need for further training and improvement to increase overall performance. Researchers need to focus on high visibility areas, like the ones we have covered in our dataset, in order to make these models more trustworthy and consistent in deployment.
- Models with overall weak performance (Overall Score < 50%): Claude 3.7 Sonnet, Gemini 2.0 Flash, DeepSeek-R1, Amazon Nova Pro
- Models with strong performance (Overall Score ≥ 75%): None
- Domain-specific performance results:
- Math & applied math: Gork 3 and OpenAI variants perform relatively better than others.
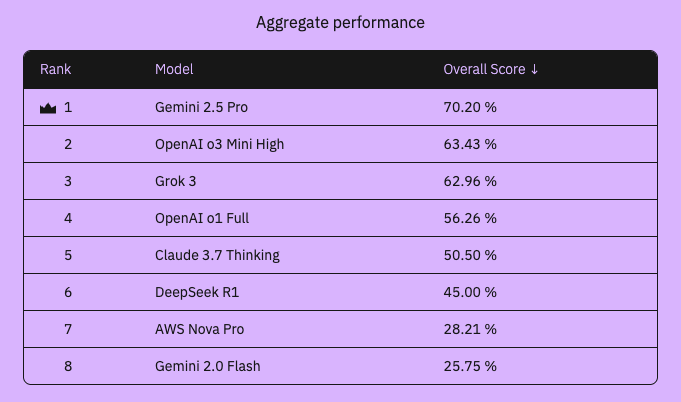
- Pure math, computer science, and general domains: Gemini 2.5 Pro swept the top spot in all three of these categories. OpenAI models, Grok 3 and DeepSeek R1 performed well after that, even though the majority of models showed low performance (<50%) in the computer science evaluations.
View the Complex Reasoning Leaderboard for the full performance results. On our webpage, we breakdown the results across five individual categories: math, applied math, pure math, computer science, and general reasoning.
Accuracy: Identifying those models with the correct answer
Here, we focus on the final answer and how often each model reaches the correct solution. Again, Gemini 2.5 Pro appears at the top, followed by OpenAi’s o3, Grok 3, Deepseek’s R1, and Claude 3.7 Thinking.
As we expected, the pattern among models who provide the correct final answer seems to almost directly mirror the pattern exhibited in models with the right reasoning. This suggests that multiple models are capable of delivering reliable answers across a variety of problem types, especially when they are correct in their reasoning.
Reasoning: Models with the right chain-of-thought
Evaluating the final answer tells only part of the story; scrutinizing how each model reasoned through complex prompts revealed critical differences in their problem-solving approaches and logical coherence.
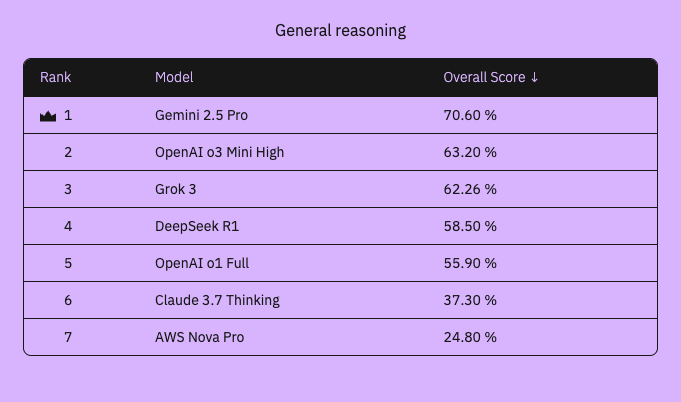
The reasoning performance of each model was compared to the correct reasoning frameworks for the advanced math and reasoning problems. Note that the focus here is not on the correct answer, but rather we validated the step-by-step logic and chain-of-thought (CoT) to verify how the models approached and attempted to solve the problems.
Our overall best performer, with clearly the highest clarity and correctness in its reasoning technique, was Google’s Gemini 2.5 Pro model. Grok 3 and OpenAI’s suite of models also put in a good performance, followed by Deepseek R1 and Claude 3.7 Thinking in quick succession. These models are all above that crucial 50% performance mark, making them more likely than not, on advanced and deeply complex questions, to be correct in their reasoning, which is massively improved from previous non-reasoning suites of models.
It is important to note that the overall performance of these models when it comes to complex reasoning tasks still has a long way to improve, leaving us excited and anxious to track this performance over time as we test the future iterations of all of these models moving forward.
Challenges: Building a challenging but not impossible dataset
As mentioned earlier, our goal was to create a challenge dataset that was hard enough to challenge these latest models but not so challenging where all the models failed, which would make a rankings and comparison impossible.
Finding this key middle ground was critical and below are some key statistics on the failures we measured:
- 76% of our complex reasoning prompts failed to be answered correctly by at least one of the tested models
- 9% of our questions were unsolvable (incorrect answer provided) by any of the models tested
- 7% of our questions had no models provided the correct reasoning
Final thoughts on reasoning leaderboard results
We have a clear top performer in reasoning as of now, and its Gemini 2.5 Pro model—although Grok 3 edged out Gemini in our Applied math evaluations. The remaining contenders all performed at a lower level across all of our sections, and in general performance as well. In general, models are not yet performing at a consistently high level across complex reasoning tasks—at least those focused on the math, coding and general reasoning topics we tested.
We define high performance as 75% aggregate performance or more, and as of yet, no model has been able to break this benchmark. Perhaps the next generation releases will be the first models to eclipse what we have determined to be a highly reliable reasoning model.
So as of now, there is a clear gap between current and desired performance, and a clear need for more and more advanced datasets of which these models can continue to build their advanced reasoning intuition.
Next update on leaderboards
Our simulation has proven invaluable in benchmarking advanced reasoning capabilities, providing us and our customers some clear insights into both the strengths and areas for growth of today’s AI models. Building on this research, we are looking ahead to our next phase of exploration—a focused evaluation of agentic models. We will rigorously assess how these systems operate autonomously in dynamic, real-world scenarios.
Thank you for reading about our latest Labelbox Leaderboards, and we hope to share more cool things with you soon!


