
 All blog posts
All blog postsLabelbox•May 16, 2025
Rubric evaluations: Fueling the next wave of reinforcement learning

The AI landscape is constantly evolving, and with it, the methods we use to train and evaluate sophisticated models. For complex tasks, particularly those leveraging reinforcement learning (RL), the traditional reliance on a single "golden answer" or "golden dataset" is proving insufficient. We're seeing a significant trend towards rubric-based evaluations, a methodology that provides the nuanced, actionable feedback necessary to refine and improve the next generation of AI.
Rubric evaluations offer a more granular and insightful approach, scoring responses across multiple dimensions. This provides specific, actionable feedback that is crucial for the iterative improvement cycles inherent in RL. As AI capabilities expand, the need for evaluation methods that can scale, provide detailed feedback, and align with automated processes is paramount.
Golden datasets vs. rubric-based evaluations
For a long time, the gold standard for evaluating AI models, especially in supervised learning, was the "golden dataset." This dataset contains curated examples of the ideal or correct answer for a given input. While useful for foundational tasks, this approach has limitations when applied to more advanced AI systems, particularly those using RL to navigate complex decision-making processes.
The challenges with relying solely on golden datasets for RL include:
- Limited scope for creativity and nuance: Many complex problems don't have a single "golden" answer. Think about evaluating the quality of code generated by an AI, the helpfulness of a chatbot's conversational turn, or the strategic soundness of a move in a complex game. A single correct answer often doesn’t capture the full spectrum of acceptable or even excellent responses.
- Difficulty in assessing partial correctness: RL agents often learn through trial and error, producing solutions that might be partially correct or demonstrate understanding of certain aspects of a problem but not others.
- Scalability issues for complex feedback: As tasks become more intricate, defining a comprehensive golden dataset that covers all desirable attributes and potential pitfalls becomes increasingly challenging and time-consuming.
Rubric-based evaluations address these limitations by providing a structured framework to assess responses against a set of predefined criteria, each with varying levels of achievement. This allows for a holistic, detailed understanding of an AI's performance. It is especially vital in RL, where the agent learns by maximizing a reward signal; rubrics help define that reward signal with much greater precision.
What are rubric-based evaluations
A rubric is a structured assessment tool that clearly outlines the criteria for evaluating a piece of work, the different levels of performance for each criterion, and the scoring guidelines. While traditionally used in education to assess student work and ensure consistent grading, rubrics are proving invaluable for evaluating the outputs of AI models.

In the context of AI, rubrics contain a set of criteria tailored to the specific task. For example, when evaluating AI-generated code, criteria might include adherence to naming conventions, efficiency, readability, and correctness. For AI-powered business research, criteria could focus on accuracy, relevance, comprehensiveness, and avoidance of jargon or unnecessary acronyms.
Rubric evaluations can range in complexity:
- Simple "correctness rubrics" may use a series of yes/no questions for each criterion. While easy to implement, they often lack the depth needed for nuanced tasks.
- Robust rubrics assign point values to each criterion, often weighted by importance. Critical aspects of a solution receive higher potential scores, directly impacting the overall evaluation.
AI model responses are then assessed against these criteria, either by human evaluators, an LLM-as-a-judge, or a combination of both. The outcome is a detailed score for each criterion and an overall score that can be benchmarked. For broad or multifaceted topics, different themes (e.g., clarity, relevance, instruction adherence) can each have their own custom rubric.
Key aspects of rubric evaluation include:
- Definition of criteria: Specific aspects of the performance to be evaluated
- Levels of achievement: Descriptions of performance quality for each criterion (e.g., Needs Improvement, Fair, Good, Excellent)
- Scoring guidelines: How scores are assigned or weighted for each level
- Clear communication: Shared understanding of expectations for the AI's output
- Fair and consistent assessment: Standardized framework for reliable evaluation
- Feedback: Specific, constructive insights pinpointing areas for model improvement
- Efficiency: Streamlined evaluation process due to clear, objective measures
Rubric evaluations are versatile and can be applied to diverse AI tasks, including AI application generators (prompt-to-app solutions), search query relevance, and the complex reasoning and chain-of-thought (CoT) capabilities of state-of-the-art models across numerous domains.
How does a rubric improve reinforcement learning (RL)?
For reinforcement learning systems to truly learn and improve, especially in complex environments, the feedback they receive needs to be more than just a simple reward. Rubric-based evaluations enhance RL processes by providing evaluation signals that are:
- High utility: Scores derived from rubrics align more closely with the real-world impact and quality of an AI's response. For complex prompts or situations, a simple right/wrong is insufficient. Rubrics offer detailed scores that reflect different facets of a solution, providing granular insights that can directly inform the reward mechanism in RL and guide the model toward more desirable behaviors. This addresses the common RL challenge of reward sparsity or misspecification.
- Clear: The evaluation criteria are explicit and easily understood. Each criterion targets a specific, well-defined aspect of the response. This clarity helps model builders and the RL agent itself (through the reward signal) to recognize precisely which areas need improvement.
- Consistent and reliable: When well-designed and based on the expertise of domain specialists, rubrics ensure that evaluations are dependable and reproducible.
- Efficient: While setting up a robust rubric requires initial effort, it can significantly streamline the evaluation process in the long run. By providing transparent and objective measures, rubrics can reduce the ambiguity and time often associated with evaluating complex AI outputs.
Furthermore, the structured nature of rubric evaluations makes them highly scalable for automated evaluation, including leveraging LLMs as judges. The detailed, multi-dimensional feedback from rubrics can be more effectively translated into the reward signals that drive RL policies, leading to more sophisticated and reliable AI systems. This also aligns with the increased investment in tools and platforms designed for LLM-as-a-judge evaluations.
Examples of modern rubrics for AI training
The application of rubrics in AI evaluation is broad and expanding. Here are a few examples:
- Evaluating AI-generated code: Criteria could include correctness (does the code run without errors and produce the desired output?), efficiency (is the code optimized for speed and resource usage?), readability (is the code well-commented and easy to understand?), security (does the code avoid common vulnerabilities?), and adherence to style guidelines.
- Assessing chatbot responses: Rubrics can evaluate helpfulness (does the response accurately and completely answer the user's query?), relevance (is the response on-topic?), tone (is the tone appropriate for the context?), safety (does the response avoid harmful, biased, or inappropriate content?), and conciseness (is the information presented without unnecessary verbosity?).
- Judging creative writing or content generation: Criteria might involve originality, coherence, grammatical correctness, engagement, adherence to prompt constraints, and stylistic consistency.
- Evaluating complex reasoning (e.g., Chain-of-Thought): Rubrics can break down the reasoning process, assessing the logical validity of each step, the accuracy of factual claims, the completeness of the argument, and the clarity of the explanation.
In each of these cases, a rubric allows for a much richer assessment than a simple "good" or "bad" label. It identifies specific strengths and weaknesses, providing clear pathways for improvement.
Each criterion is worth a certain number of points, with critical criterion worth more points. An example rubric for web application may look like the following. In this example, an excellent solution would receive between 42 and 46 total points across the 5 criteria. Good, satisfactory, needs improvement, and failing solutions would fall into point totals below that.
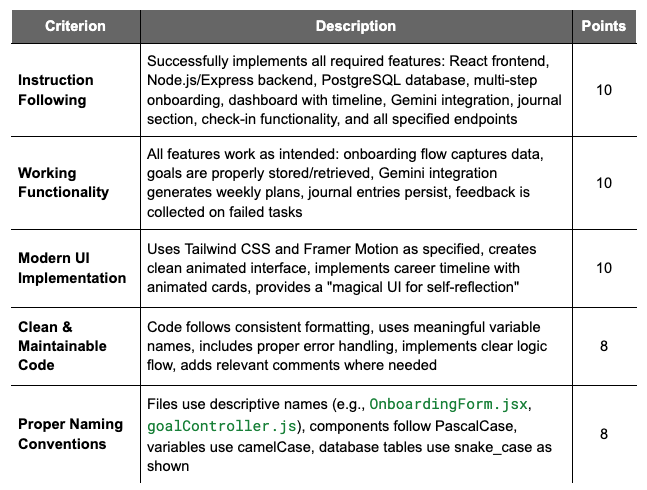
Labelbox services: Adopt rubric-based evaluations
At Labelbox, we partner with leading AI labs to pioneer rubric-based evaluations for their most advanced frontier models. These sophisticated evaluations are crucial for training models on complex responses and are in high demand due to their powerful, actionable insights. Leveraging our Alignerr network of specialized domain experts, we collaboratively develop custom rubrics. These are then seamlessly applied through our platform, supporting human evaluations and integration into automated LLM-as-a-judge systems.
This collaboration has enabled us to establish a robust, repeatable framework for generating high-utility evaluation data. Our methodology ensures that AI models are assessed with the necessary depth and nuance:
- Define clear tasks & outcomes: We start by precisely articulating the AI's objective and the characteristics of a high-quality response or output.
- Develop custom rubrics: We develop rubrics that pinpoint key criteria essential for task success, establish distinct achievement levels for each criterion, write clear descriptors for each performance level, and assign weighted scores.
- Leverage expert & AI evaluators: Utilize human domain experts from the Alignerr network, trained annotators, or LLMs-as-judges, ensuring consistency through training and calibration.
- Conduct rigorous evaluations: Systematically assess AI outputs against the rubric, covering various data types like text, code, or images.
- Score, aggregate & analyze: Calculate detailed scores for individual criteria and overall performance, identifying specific strengths and weaknesses.
- Drive iterative improvement: Translate rich rubric feedback into actionable insights to refine models, adjust training data, or optimize RL reward functions.
A key reason we are using rubric-based assessment more and more over traditional right/wrong evaluations is its ability to identify partial correctness. An AI response might meet some criteria exceptionally well while falling short on others. Rubrics capture this nuance, providing a more accurate and actionable picture of the model's capabilities. This detailed feedback loop is crucial for the iterative nature of AI development and is particularly potent when fed into various RL process, such as RLHF (Reinforcement Learning from Human Feedback) or RLVR (Reinforcement Learning from Verifiable Rewards).
Next steps for improving your frontier models
The move from simple golden dataset comparisons to nuanced, multi-dimensional rubric evaluations marks a significant maturation in how we develop and refine AI systems, especially in the domain of reinforcement learning. Rubrics provide the structured, detailed, and actionable feedback required to train AI on complex tasks where shades of quality matter more than a binary notion of correctness.
Interested in implementing robust rubric-based evaluations for your AI projects? Contact us to explore how Labelbox can help operate a powerful evaluation of your models.


