
 All blog posts
All blog postsManu Sharma•May 3, 2023
Using reinforcement learning from human feedback to fine-tune large language models
Reinforcement learning from human feedback (RLHF) is a powerful way to align foundation models to human preferences. This fine-tuning technique has been critical to a number of recent AI breakthroughs, including OpenAI’s ChatGPT model and Anthropic’s Claude model.
The highly nuanced improvements enabled by RLHF have significant impacts on the usability and performance to a model. This can include subtle improvements in tone, reductions in bias and toxicity, and domain specific content generation. The focus of this post will be on how to leverage RLHF to fine-tune large language models (LLMs).
What is reinforcement learning from human feedback?
As stated in "Deep reinforcement learning from human preferences," RLHF emerged from a core problem in reinforcement learning: the fact that “many [reinforcement learning] tasks involve goals that are complex, poorly-defined, or hard to specify." The difficulty of specifying a reward function creates a “misalignment between our values and the objectives of our RL systems.”
Some of the most significant business applications of AI today have goals that are hard to specify. One example is content moderation, where the nuance and context of a moderation policy might be at odds with an algorithm’s ultimate enforcement decisions. Another example is content generation — say in the form of an automated support agent. While generative AI enables content creation at a fraction of previous costs, concerns over quality have hindered broader adoption. How might a team specify a reward function that follows brand style and tone guidelines in all circumstances? When faced with the brand risks associated AI-generated content, a deterministic chatbot or human support agent might be well worth the cost.
In traditional reinforcement learning, a clearly specified reward function nudges an algorithm in the right direction. For more nuanced tasks, however, a reward function might be difficult to determine. In these cases, human preferences can guide an AI system to the right decision. This is because people (even non-experts) can intuitively understand how to navigate nuanced and contextual tasks. Given example brand marketing copy, for instance, people can easily determine how well AI generated copy aligns with brand tone. The problem, however, is the time and cost required to provide human preferences in the reinforcement learning training process. “Using human feedback directly as a reward function is prohibitively expensive for RL systems that require hundreds or thousands of hours of experience,” state the authors of “Deep reinforcement learning from human preferences.”
As a result, researchers came up with reinforcement learning from human feedback (RLHF), in which a reward predictor, also referred to as a preference model, is trained to estimate human preferences. Using a reward predictor makes the process much more economical and scalable than directly supplying human feedback to an RL algorithm.
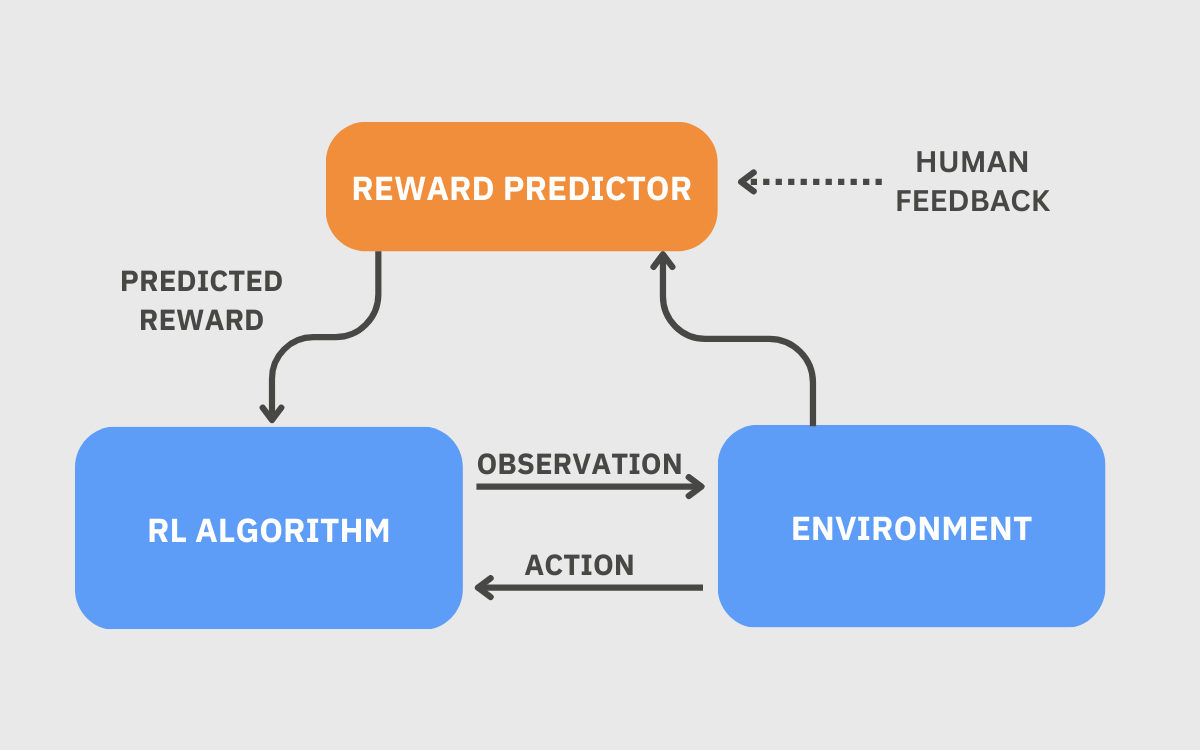
Using RLHF to fine-tune large language models
RLHF is a powerful tool to improve helpfulness and accuracy, as well as reduce harmful biases in large language models. In a comparison between GPT-3 and InstructGPT (a model fine-tuned with RLHF), OpenAI researchers found that labelers “significantly prefer” outputs from InstructGPT. On truthfulness and toxicity benchmarks, InstructGPT showed improvements over GPT-3 as well. A 2022 paper by researchers at Anthropic documented similar benefits. Researchers found that “RLHF improves helpfulness and harmlessness by a huge margin when compared to simply scaling models up.” These studies offer a compelling case for leveraging RLHF to achieve a variety of business outcomes with large language models.
Let's walk through how to set up and customize an RLHF workflow.
Step 1: Collect demonstration data and train a supervised policy
The dataset you need to collect, comprising text prompts and outputs, should be a gold standard that is used to initially fine-tune an LLM, and represents the ideal behavior of a fine-tuned model. Typically, it is structured in the form of a prompt and completion. In the case of an email summarization task, the prompt might consist of a full email, with the completion being a two sentence summary. For a chat task, the prompt could be a single question or a number of conversation turns. The completion would be the ideal response to the prompt.
This demonstration data can come from a number of sources: data already on hand, a labeling team, or from a model (as shown in Self-Instruct: Aligning Language Model with Self Generated Instructions). According to OpenAI’s fine-tuning guidelines, at least a few hundred high-quality examples are necessary to fine-tune successfully. OpenAI reports that performance tends to linearly increase with every doubling of dataset size. Their researchers strongly encourage AI builders to manually review demonstration datasets for inaccurate, toxic, biased, or unhelpful content.
Methods of generating demonstration data can vary widely. Some teams might have data on-hand and only require labelers to generate completions. Other use-cases might involve web browsing, where labelers might need to collect data online and link a source for verification purposes. With Labelbox, you can create three types of data generation tasks:
1. Prompt and response creation
2. Response creation based on uploaded prompts
3. Prompt creation
Each of workflow supports optional text entry and classification tools.
Once demonstration data is generated, it’s time to fine-tune a large language model with supervised learning. Organizations like OpenAI and Cohere offer easy to follow guides on the technical steps required.
Step 2: Collect comparison data and train a reward model
After a large language model is fine-tuned with supervised learning, it will be able to generate task-specific completions of its own. The next step in the RLHF process is to collect human feedback on these completions, specifically in the form of comparisons. This comparison data is then used to train a reward model. The reward model will then be used to optimize the fine-tuned supervised learning model through reinforcement learning (see step 3).
To generate comparison data, present a labeling team with multiple model completions to the same prompt, and have labelers rank completions from best to worst. The number of completions can range from a side-by-side comparison (one prompt and two completions) to the ranking of three or more completions. To fine-tune InstructGPT, for instance, OpenAI found it efficient to present labelers with a range of four to nine completions to rank at a time.
To conduct comparison tasks in Labelbox, you can directly upload model completions or connect via a model endpoint to generate them in real time. Labelbox also offers additional tools to conduct the evaluation of fine-tuned LLMs, such as Likert scores, multiple choice evaluation, and text fields to re-write model completions.
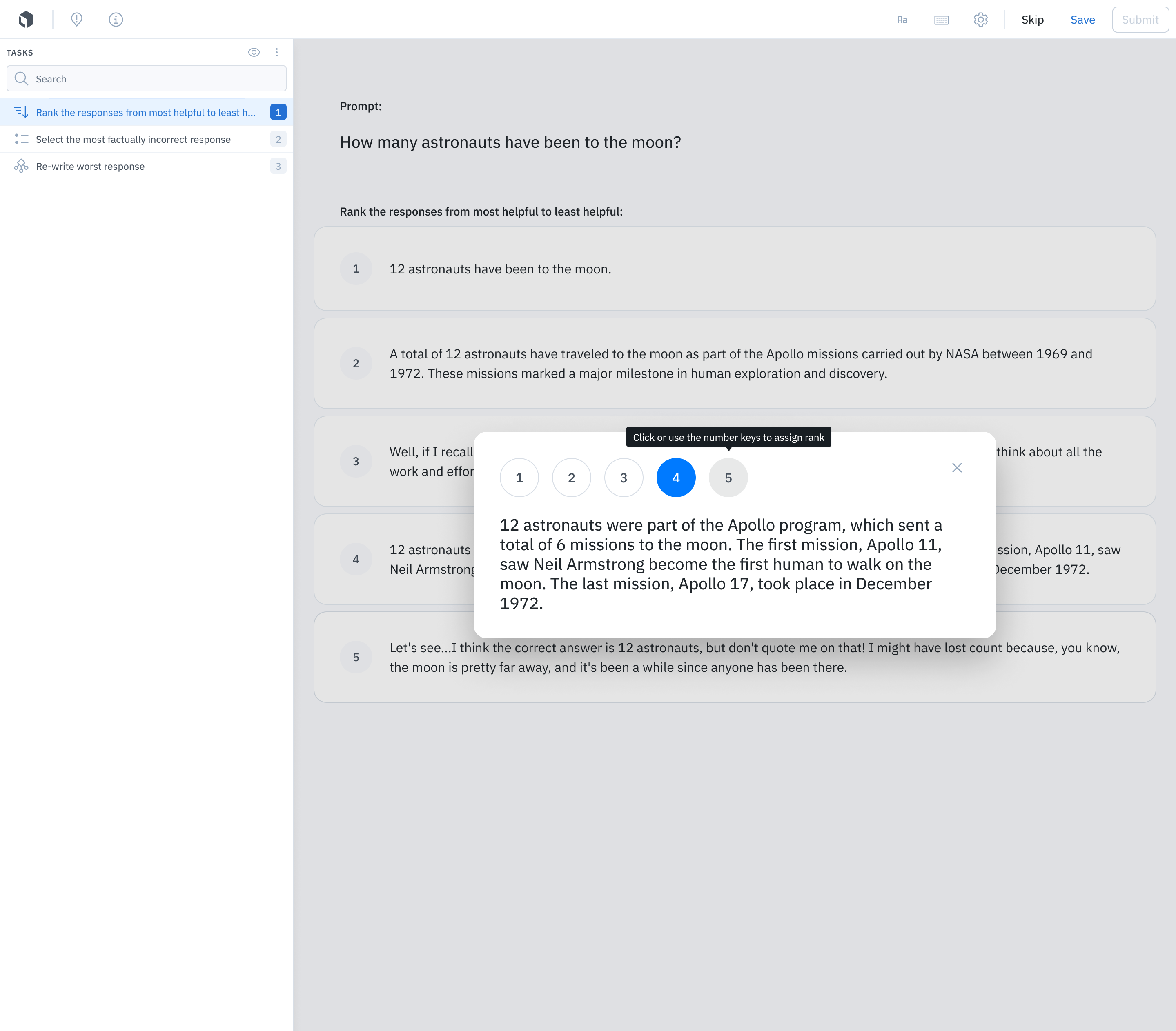
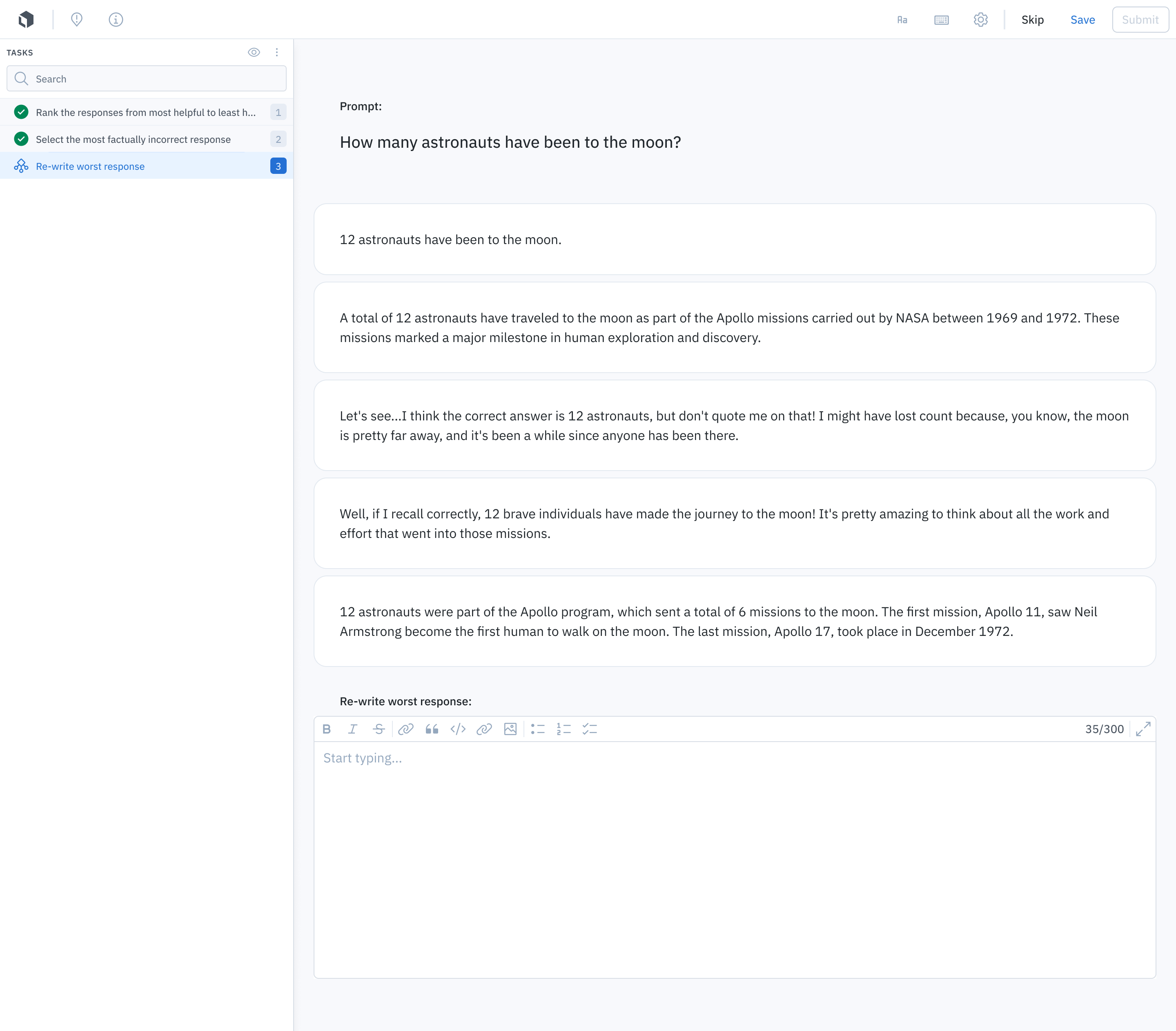
Before deploying a fine-tuned LLM, you should also test against baselines for honesty, helpfulness, bias, and toxicity. Common LLM benchmarks include TruthfulQA for honesty, the Bias Benchmark for Question Answering for bias, and RealToxicityPrompts for toxicity.
Step 3: Optimize the supervised policy against the reward model using reinforcement learning
The supervised learning baseline is fine-tuned to maximize the reward using a reinforcement learning (RL) algorithm. Proximal Policy Optimization (PPO) is an industry-leading class of RL algorithms developed by OpenAI. More details on PPO algorithms can be found on OpenAI’s website.
The reinforcement learning process aligns the behavior of the supervised policy (in this case, the baseline fine-tuned LLM) to the preferences of labelers. Further iterations on steps 2 and 3 will continue to improve model performance.
Final thoughts on using RLHF to fine-tune large language models
Reinforcement learning from human feedback is a powerful tool to improve model performance, particularly in cases where an objective is hard to explicitly specify as a reward function. RLHF unlocks a wide variety of performance enhancements from foundation models, the impacts of which have already sent ripples through the tech industry and mainstream culture.
With large language models, RLHF offers a number of powerful business applications including support agents fine-tuned on company-specific documentation, content generation systems, code generation, and sentiment detection tools.
Stay tuned in the coming weeks for more updates on how data and ML teams can utilize the latest advances in RLHF with Labelbox.
Sources
Christiano, Paul F., et al. "Deep reinforcement learning from human preferences." Advances in neural information processing systems 30 (2017). https://arxiv.org/abs/1706.03741
Ouyang, Long, et al. "Training language models to follow instructions with human feedback." Advances in Neural Information Processing Systems 35 (2022): 27730-27744. https://arxiv.org/abs/2203.02155
Bai, Yuntao, et al. "Training a helpful and harmless assistant with reinforcement learning from human feedback." arXiv preprint https://arxiv.org/abs/2204.05862 (2022).
Wang, Yizhong, et al. "Self-Instruct: Aligning Language Model with Self Generated Instructions." arXiv preprint https://arxiv.org/abs/2212.10560 (2022).
OpenAI. https://platform.openai.com/docs/guides/fine-tuning/preparing-your-dataset


