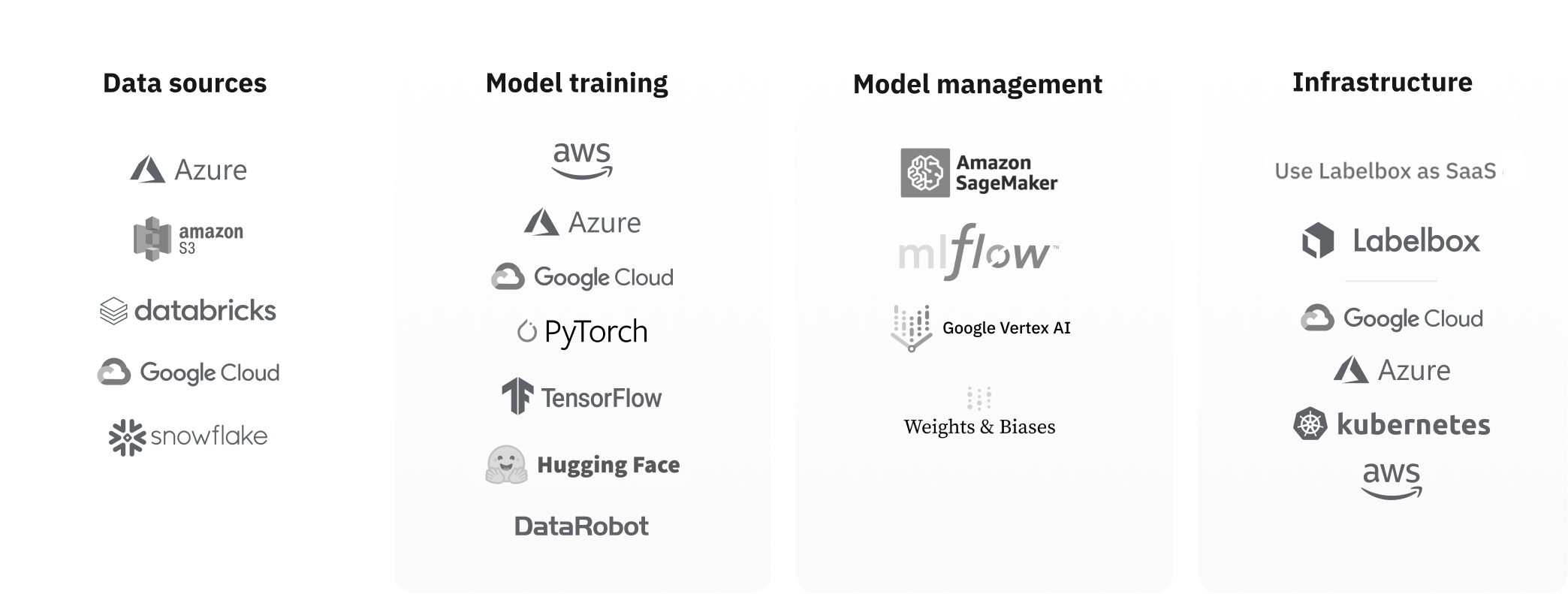
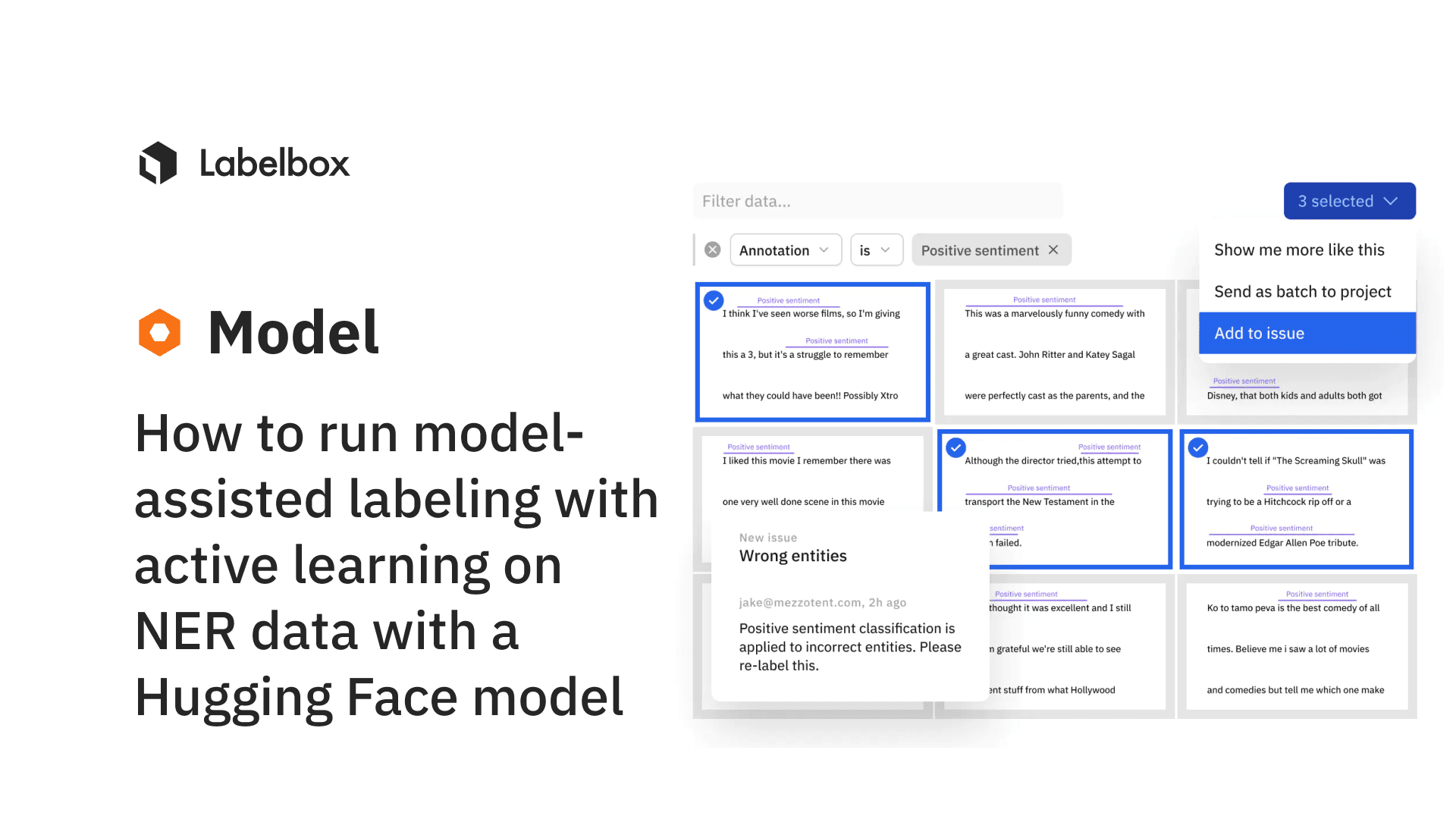
A growing ecosystem of integrations
We believe it is essential to create a technology environment that gives customers the tools needed to seamlessly build AI applications and enable breakthroughs. We strive to work with partners who share this belief and allow our customers to turn their proprietary data into revenue-generating applications with as little friction as possible.