
 All guides
All guidesHow to fine-tune large language models (LLMs) with Labelbox

What are large language models (LLMs)?
Large language models leverage deep learning techniques to recognize, classify, analyze, generate and even predict text. Critical in natural language processing (NLP) applications like AI voice assistants, chatbots, translation, and sentiment analysis — large language models rely upon large volumes of data to consistently comprehend, capture and convey the nuances of human language.
Why should you consider using one?
Recent advancements and accessibility of large language models can serve as a powerful starting point for your machine learning team. Although you’ll still need to retrain these base models on data that is contextually-relevant to your use case, leveraging a foundational model saves significant times and costs. Large language models significantly improve with Reinforcement Learning from Human Preferences (RLHP). This guide provides a framework for using Labelbox to fine-tune OpenAI 's popular GPT-3 large language model for your use case.
Getting Started
This guide and Colab notebook will walk you through how to:
- Select your own relevant classification ontology to use with foundational large language models like GPT-3.
- Create a Project in Labelbox Annotate to generate labeled training data.
- Leverage iterative model runs to rapidly tune OpenAI large language models.
- Use Labelbox Model to diagnose performance, find high impact data, get the data labeled, and create another model run for the next iteration of fine tuning.
1. Import Colab notebook packages
To help you get started, for this workflow, we’ve created a Colab notebook which has installed Open AI and Labelbox packages within the same python notebook. Import all of the packages and use the corresponding Open AI and Labelbox API keys to connect to your instances.
!pip install labelbox[data] --upgrade -q !pip install openai -q
2. Create a Project based on your desired data ontology
Next, create a Project in the platform that matches the defined ontology for the data you want to classify using Open AI’s GPT-3 model. Add this ontology to a Project. Our Colab notebook example focuses on classifying e-commerce assets into the following four categories that comprise 80% of all e-commerce assets sold:
- “Electronics”
- “Household”
- “Books”
- “Clothing & Accessories” up common e-commerce use case.
``import os
import openai
from labelbox.schema.ontology import OntologyBuilder, Tool, Classification, Option
from labelbox import Client, LabelingFrontend, LabelImport, MALPredictionImport``
``from labelbox.data.annotation_types import (
Label, ImageData, ObjectAnnotation, MaskData,
Rectangle, Point, Line, Mask, Polygon,
Radio, Checklist, Text,
ClassificationAnnotation, ClassificationAnswer
)``
``from labelbox.data.serialization import NDJsonConverter
import pandas as pd
import shutil
import labelbox.data
import json
import uuid ``3. Generate training data
Once you’ve determined the ontology and added it to your Labelbox Project, you can begin curating the training data that supports your requirements. This will ultimately play a critical role towards adapting GPT-3 to support your use case. Once you add your ontology to a project, you have multiple options for creating training data, including:
- Using Labelbox Annotate to label the data yourself
- Importing existing annotations you have in your data lake
- Leveraging our experts from data labeling services for support rapidly curating training-quality data
4. Push the batch of training data labels to model runs
Once you've created the training data, select the appropriate, corresponding data rows and export them to Labelbox Model for model training. Note that you'll need to implement model training settings that connect your model training environment and cloud service provider (CSP) to Labelbox. Our Colab Notebook demo uses Google Cloud Platform (GCP) but this same workflow and Labelbox’s cloud-agnostic platform works well with any model training environment.
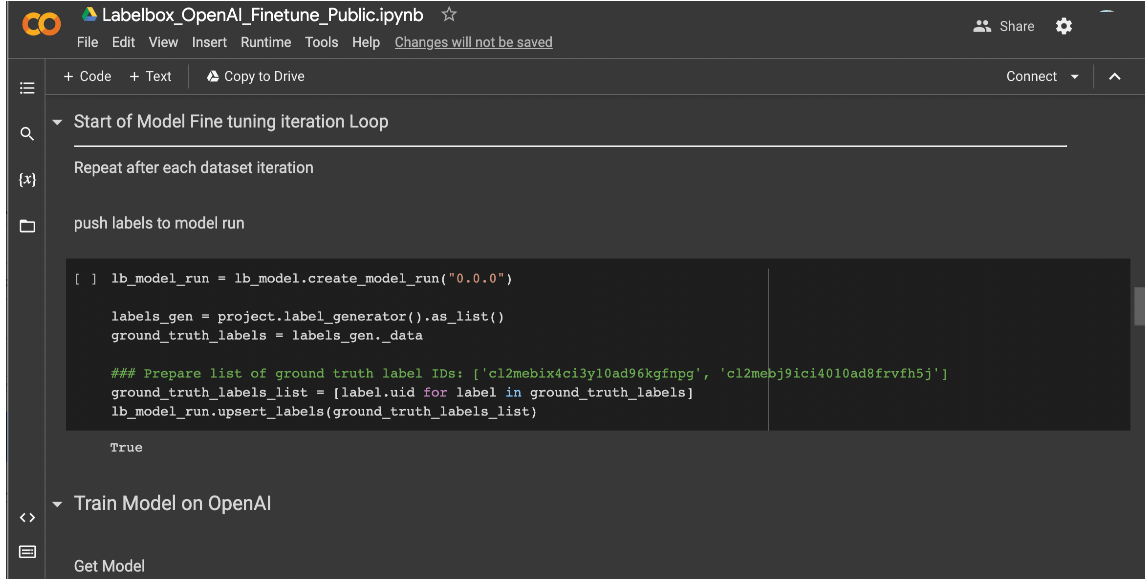
5. Iteratively improve and fine-tune the model
Next the Colab notebook features a list of prompts to iteratively train the Open AI GPT-3 model based on the annotations that fit your unique use case. As you review the model predictions in Labelbox Model, the platform will help you easily identify mis-predictions and target areas where the model consistently performs poorly.
In Labelbox Catalog, you can leverage embeddings and similarity search features to find training data samples that exhibit similar characteristics to data where your model is consistently performing poorly – then queue that data for labeling so it can be incorporated during your next retraining iteration. You'll do this by iteratively submitting a batch – featuring these newly-curated Data Rows – to the same Project you created earlier (in step two) for fine-tuning your LLM. Ultimately, this iterative loop of exposing the model to new prompts will allow you to continuously fine-tune the GPT-3 model to perform based on your own data priorities.
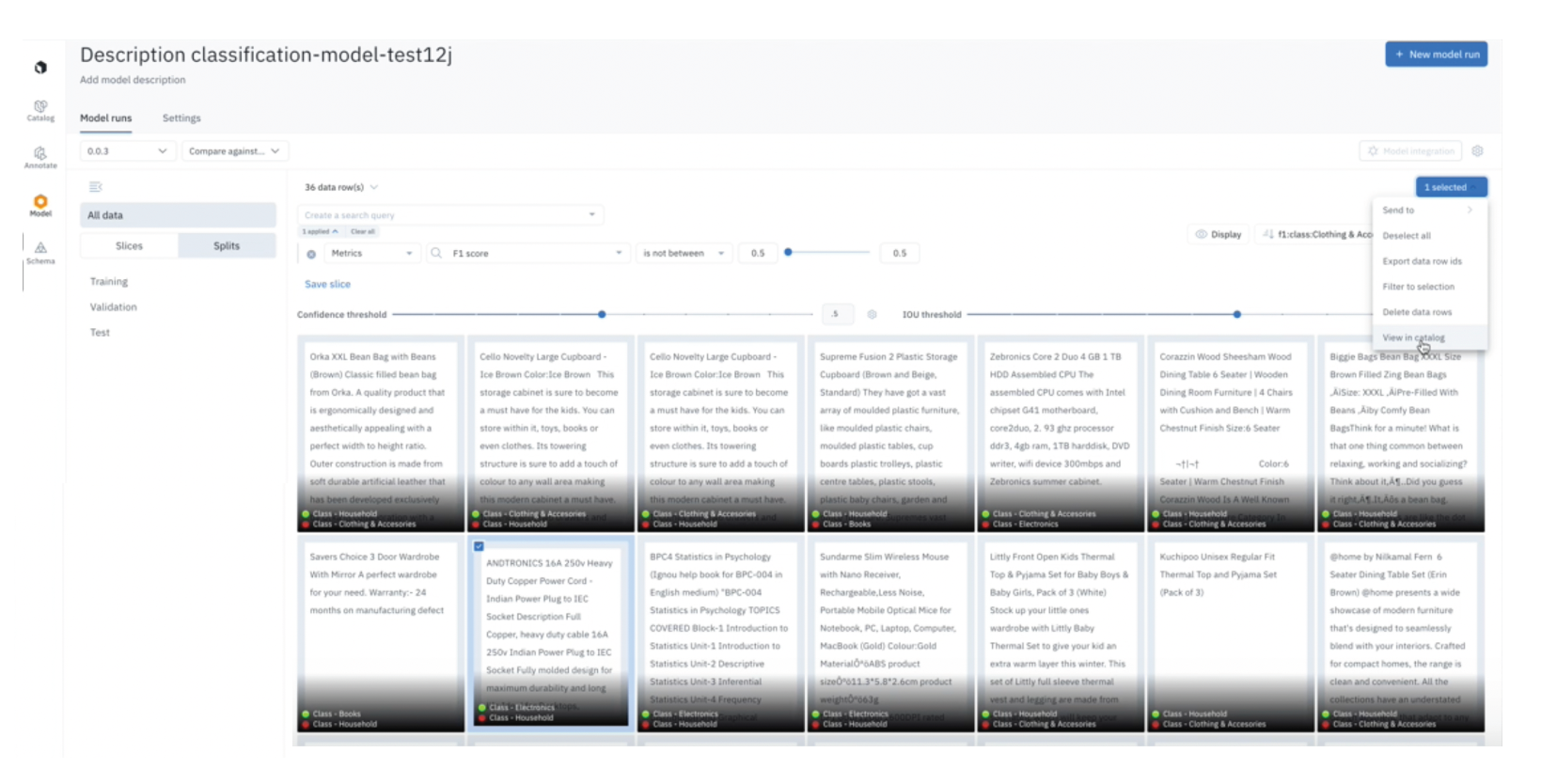
The notebook feeds the output results from Open AI back into the Labelbox Model tab. This iterative back and forth workflow empowers you to:
- Leverage Labelbox Model to measure model performance
- Evaluate model output predictions and identify areas where the model performs poorly
- Leverage Catalog to prioritize data from your Catalog that will have the most maximal impact towards addressing your edge cases
- Fine-tune the Open AI large language model by iteratively feeding it relevant data addressing your ontology, finding erroneous model predictions and fixing areas where the model performs poorly.
Get started today by following the prompts in this Colab notebook. To learn more about Labelbox Model, check out the following guides below:


