
 All guides
All guidesHow to get started in Labelbox Model: Train, evaluate, and improve your ML models

The quality of your data will dictate your model’s performance. ML teams have historically had to rely on manual methods of curating data and debugging model errors. For teams who are looking to go through fast, data-centric iterations, this is not an ideal way to quickly scale and reach production AI.
In order to ship performant models, you need to be able to quickly train models with collaborative data-centric tools. Labelbox Model can help you ship better models faster by leveraging collaborative tools to curate, debug, diagnose, and optimize your machine learning data and models.
This guide will walk you through how to get started with Model in the Labelbox platform. We’ll walk through a COCO object detection example and show you how to get onboarded in Model with your first project, model, and model run.
By the end of the tutorial, you will have learned how to:
- Upload and version a dataset in a Labelbox Model run
- Export and train an object detection model from a pre-trained model
- Visualize model predictions against ground truth annotations
- View auto-generated metrics (F1, precision, recall, IOU, confusion matrix, etc.) and the distribution of annotations and predictions
- Evaluate model performance and improve your model and data with error analysis and active learning
Key definitions in Labelbox Model:
- A model is a large language model (LLM) integrated into Labelbox Model or your custom configuration specified by an ontology of data.
- An experiment is a directory where you can create, manage, and compare a set of model runs related to the same machine learning task (e.g object detection on COCO).
- A model run is a model training experiment within a model directory. Each model run provides a versioned data snapshot of the data rows, annotations, and training/validation/test splits for that model run
- You can specify model run configurations to create, version, and track your hyperparameters and any training-related configurations for a model run
Part 1: Seed a COCO dataset and create a project and model run
For this onboarding tutorial, we’ll be working with a COCO dataset example. You can follow along by using the Google Colab Notebook and the accompanying video tutorials, but feel free to also bring your own dataset into Labelbox Model to create a Labelbox project, model and model run for your use case.
Before you begin this tutorial, you’ll need to sign into your Labelbox account or create a free account.
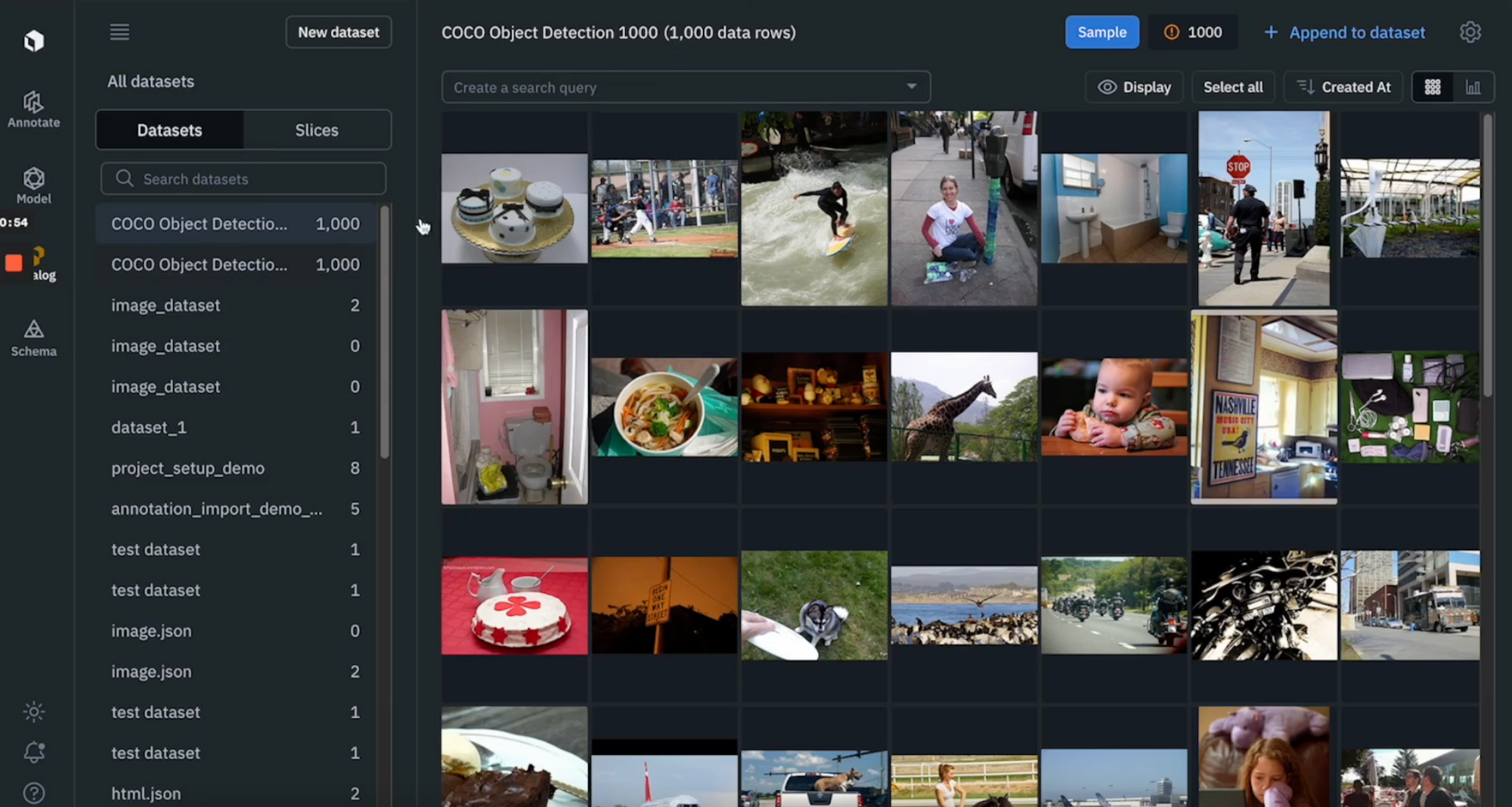
Step 1: Upload the COCO dataset to Labelbox
- Use the provided helper functions in the Colab Notebook to upload the provided COCO dataset to Labelbox
- Once you’ve successfully run the helper function, you should be able to see the COCO dataset appear in Catalog
Step 2: Upload the COCO dataset’s bounding box labels to Labelbox
- While labels are typically created by an internal or external team of labelers, we are going to use an already labeled public dataset for this tutorial
- Use the provided helper function to directly upload the dataset’s labels to Labelbox
- Similarly to the step above, you should be able to see your COCO data rows and the appropriate labels in Catalog
Step 3: Populate a model run: Version model run data and model hyperparameters
- Now, we’re ready to populate the above data (dataset + labels) in a model run
- Follow the steps in the Colab Notebook to configure the ontology (containing classes of objects that we want to detect in the image dataset)
- You can also specify your model run’s hyperparameters
Step 4: View your populated model run in the Model tab
- Once you’ve completed these steps, you should be able to see your versioned data in the Model tab
- You can view your data rows, labels, and inspect your model run configuration (hyperparameters) in the Labelbox app
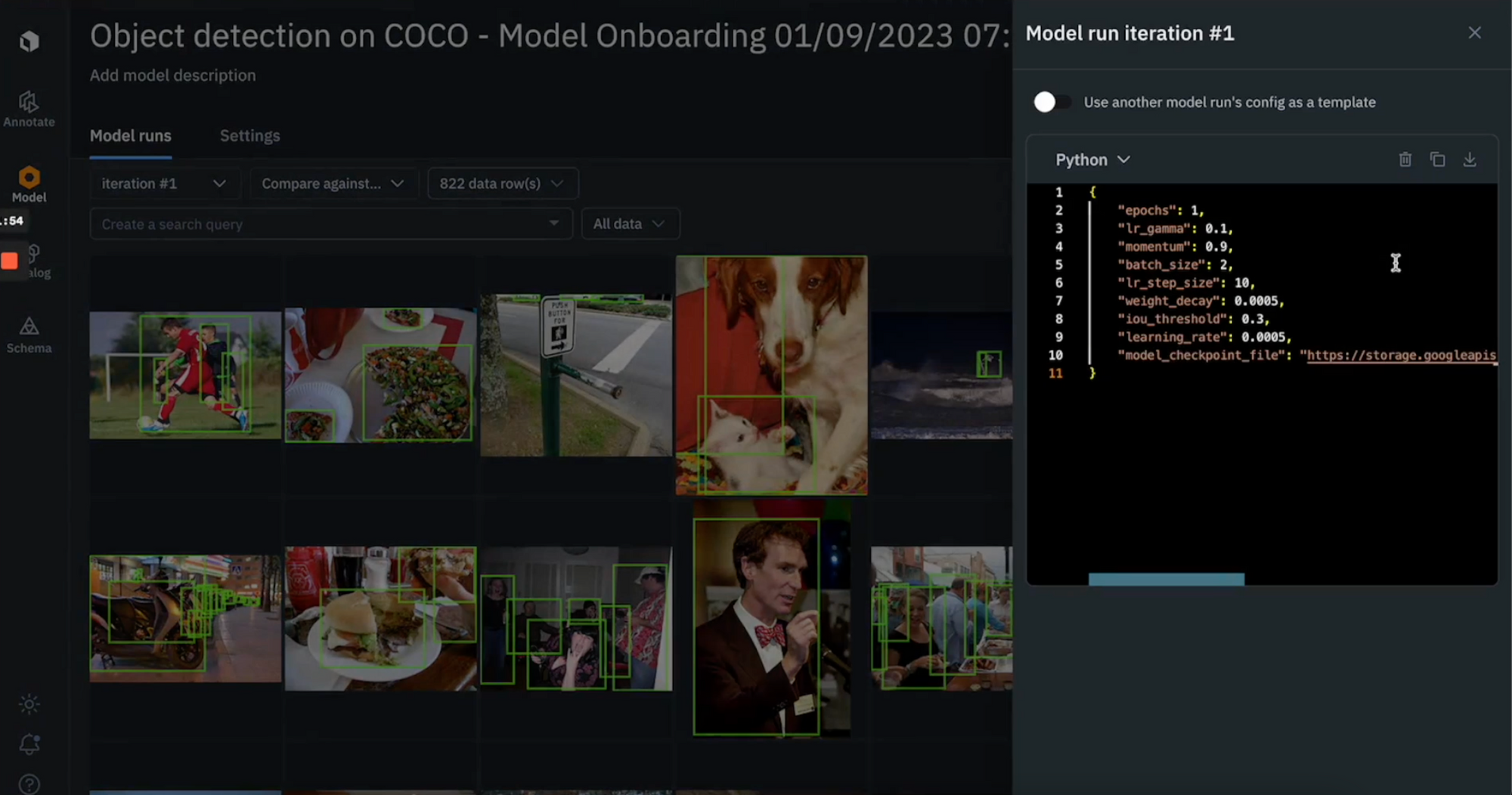
Next, we’re going to use the model run data that we’ve uploaded in Labelbox to train a model.
Part 2: Fine-tune a Faster R-CNN model, upload predictions to Model, and run error analysis
Step 1: Train an object detection model from a pre-trained Faster R-CNN model
- Export the labels from the model run you created – the labels will be versioned by the model run
- Use the provided helper function to transform the labels into a format that the Pytorch model can accept
- We’ve provided a Faster R-CNN model for fine-tuning – this replaces the last box prediction head with a new layer so that it can predict the model ontology and classes that we are concerned with
- Train the Faster R-CNN model for 1 epoch (4 minutes) – after this, you’ll have a model that performs decently well for this use case
Step 2: Generate predictions with the trained model
- Generating predictions will help us visualize model performance in Labelbox Model and can help identify model errors
- Assemble predictions and results of the model into a format that can be ingested back into Labelbox
- Turn predictions into NumPy arrays and create annotation payloads for each object
Want to upload a custom model instead?
At Labelbox, we want to ensure you are able to upload your own models quickly and easily, with no manual onboarding. With just a few clicks, you can seamlessly integrate your own custom models into our platform to enhance prediction, accelerate model evaluation, and improve data enrichment.

Step 3: Upload predictions back into your Labelbox model run
- Upload the model predictions to the Labelbox app in order to visualize how the model is performing
- Other than confidence scores, you don’t have to worry about computing metrics. Labelbox Model will auto-compute model metrics such as F1 scores, precision, IOU, confusion matrix, false positives/false negatives/true positives/true negatives, etc
Step 4: Visualize model predictions and auto-generated metrics in Labelbox Model
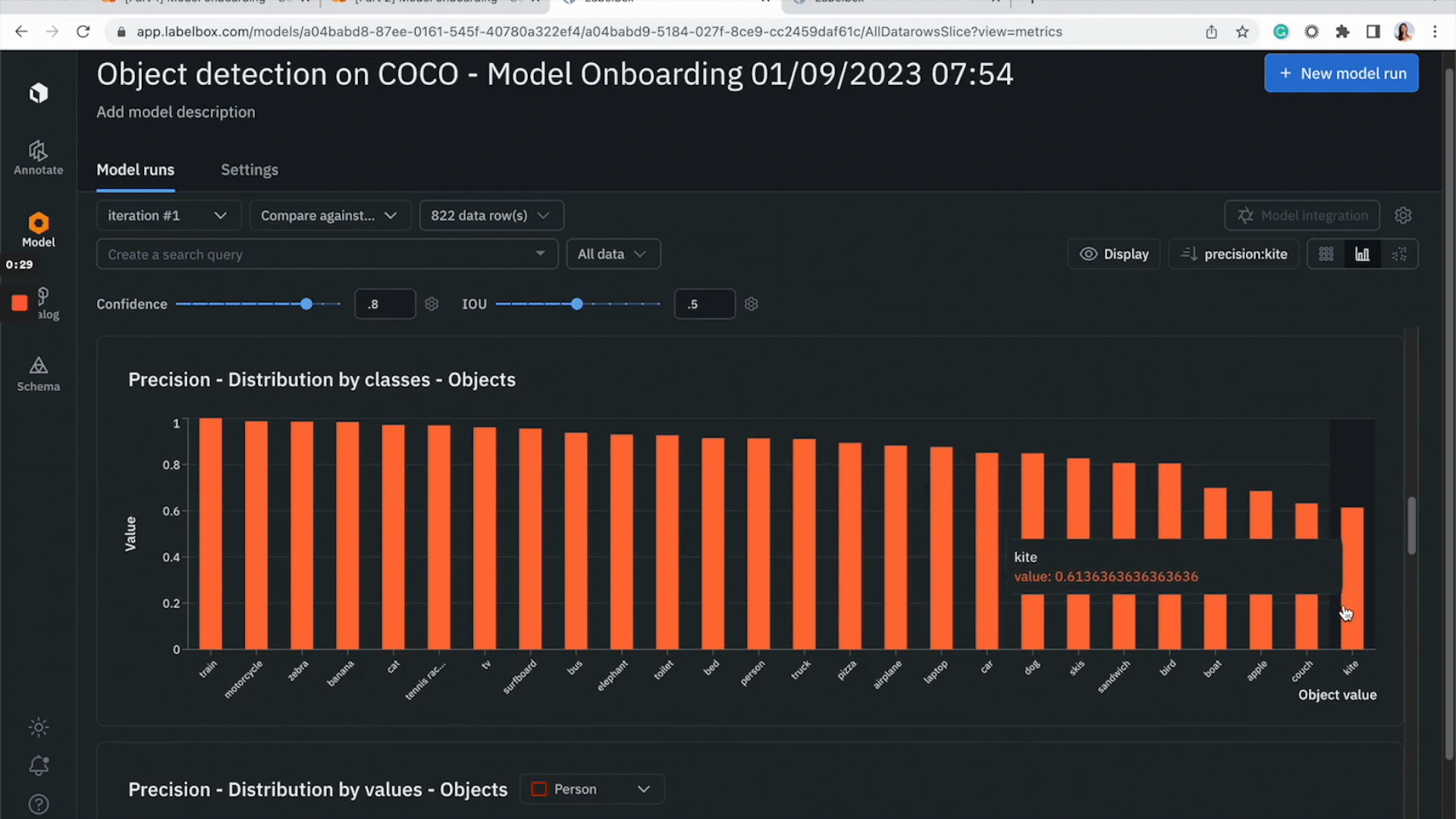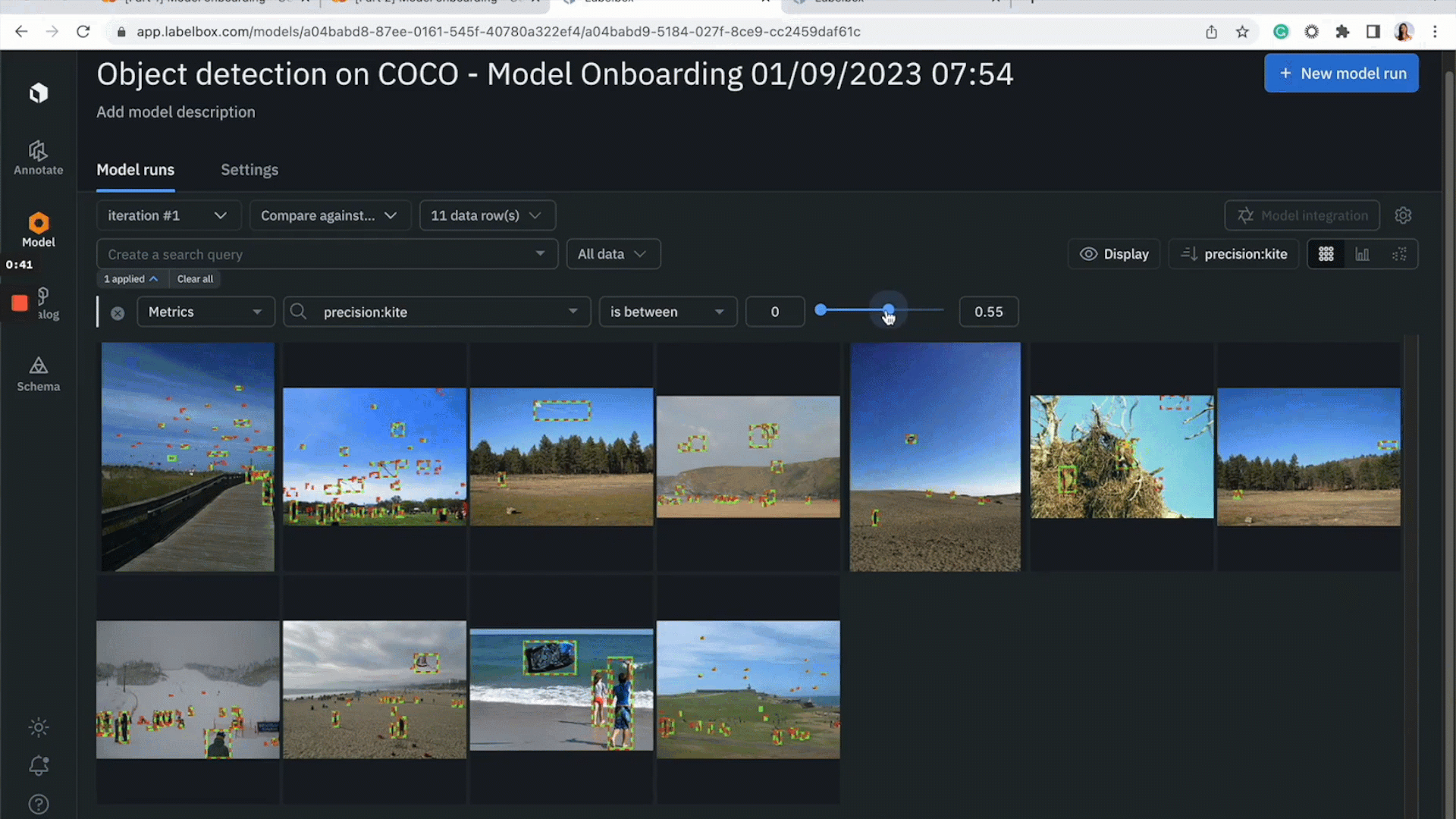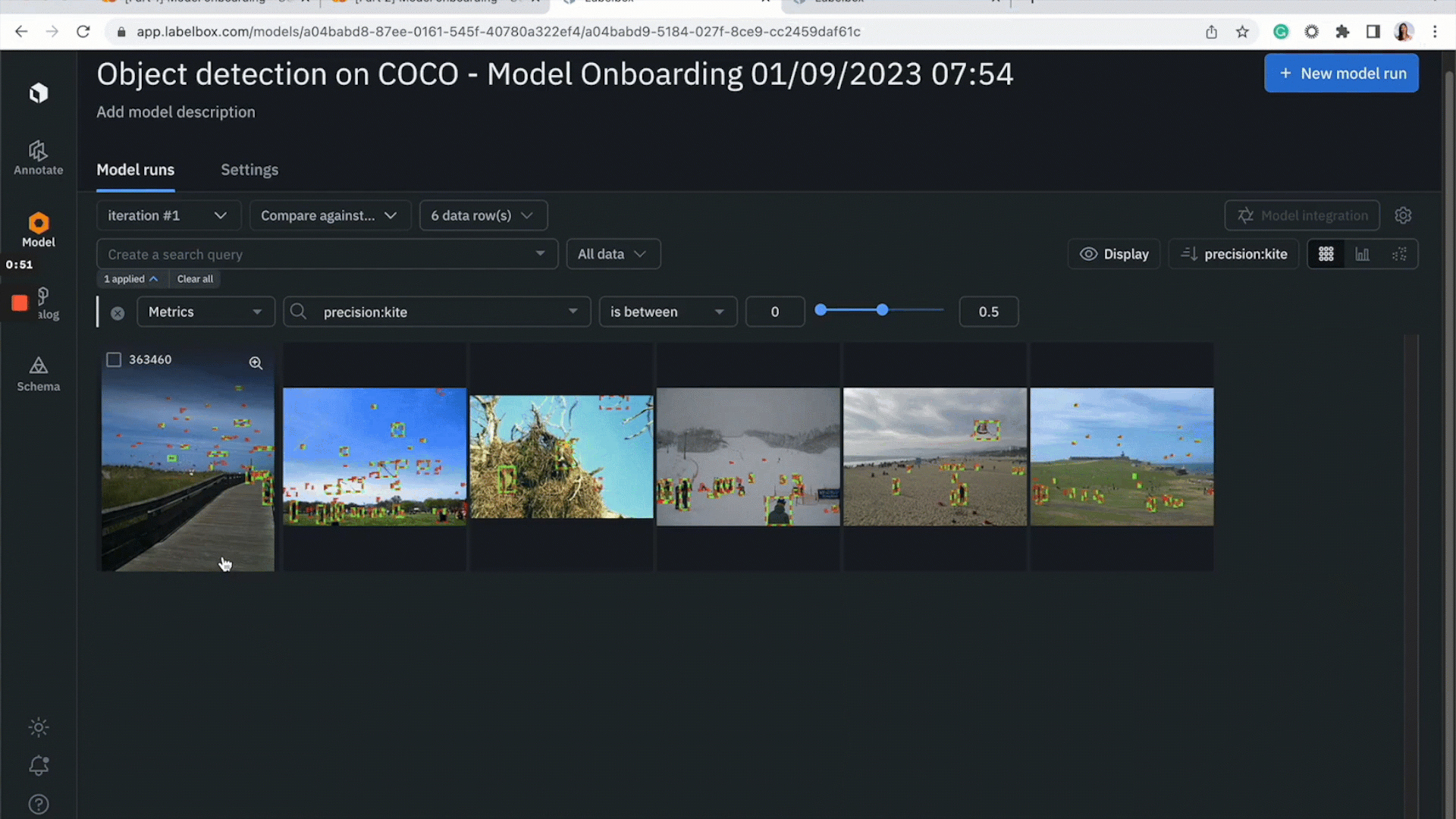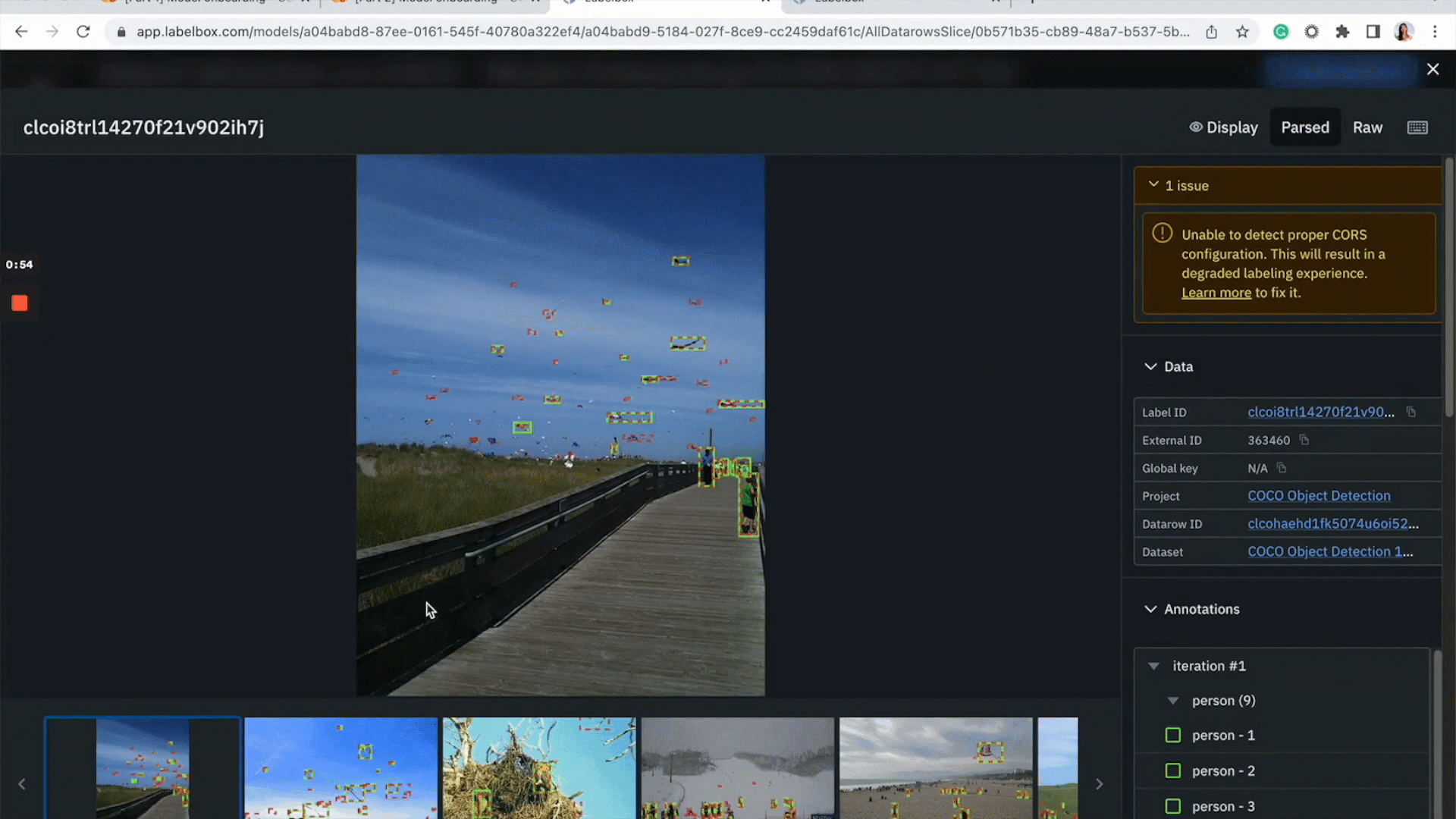
- After you’ve completed the steps above, you should now be able to go to the Models tab to visualize model predictions and model metrics
- Click on “Metrics View” to inspect model metrics and the model’s performance on each class
You can run error analysis on specific classes or data rows of interest:
- Start by inspecting how the model is doing on each class
- If you notice the model is struggling on a specific class, you can click into the histogram to view data rows on which the model is struggling. You can refine the search query to further drill into and inspect model performance
- Leverage “detailed view” to better inspect disagreements and find patterns of model failures on images
- After running error analysis, you can make more informed decisions on how to iterate and improve your model’s performance with corrective action or targeted data selection
Learn More
By following this step-by-step tutorial, you’ve now successfully created a model, a model run, and have uploaded model predictions into Labelbox for further analysis.
You can also refer to the below guides for a more in-depth walkthrough on how to improve data selection and model performance:
- How to search, surface, and prioritize data within a project
- How to prioritize high-value data
- How to find and fix label errors
- How to find and fix model errors
- How to find similar data in one click
We’re happy to help answer any questions. Reach out to us anytime on our contact us page.


