
 All guides
All guidesAI foundations: Understanding embeddings
Introduction
Embeddings transform complex data into meaningful vector representations, enabling powerful applications across various domains.
This post covers the theoretical foundations, practical examples, and demonstrates how embeddings enhance key use cases at Labelbox.
Whether you’re new to the concept or looking to deepen your understanding, this guide will provide valuable insights into the world of embeddings and their practical uses.
What is an embedding?
At its core, an embedding is a vector representation of information. This information can be of any modality—video, audio, text, and more.
The process of generating embeddings involves a deep learning model trained on specific data.
Each index in a vector represents a numerical value, often a floating-point value between 0 and 1.
The relationship between dimensions and detail
The dimensions of a vector describe the level of detail it can capture. Higher dimensionality means higher detail and accuracy in the similarity score.
For example, a vector with only two dimensions is unlikely to store all relevant information, leading to simpler but less accurate representations.
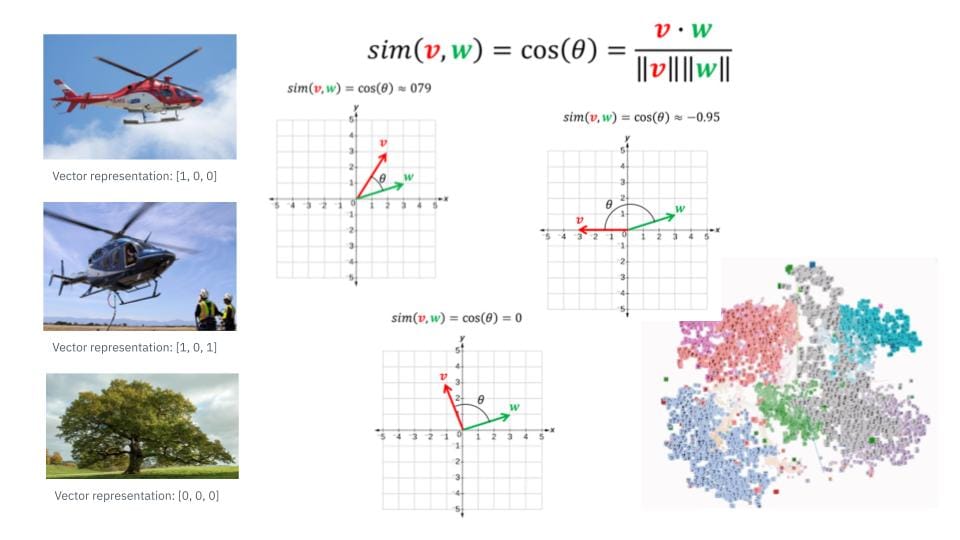
Vector representations of images
For instance, consider an image. The underlying compression algorithm converts this image into a vector representation, preserving all relevant information. These embeddings can then be used to determine the similarity between different pieces of data. For example, images of a cat and a dog would have different embeddings, resulting in a low similarity score.
Another example: Let's consider a model trained on images of helicopters, planes, and humans. If we input an image of a helicopter, the model generates a vector representation reflecting this. If the image contains both a helicopter and humans, the representation changes accordingly. This process helps in understanding how embeddings are generated and used.

Importance and applications of embeddings
Why embeddings matter
As we’ve described in the prior sections, understanding what embeddings are and how they work is crucial for several reasons:
- Capturing Semantic Relationships: Embeddings help capture complex relationships within data, enabling more accurate predictions and recommendations.
- Improved Search Capabilities: Embeddings facilitate efficient and accurate similarity searches, essential in applications like search engines and recommendation systems.
Applications of embeddings
Embeddings are extremely useful in search problems, especially within recommender systems.
Here are a few examples:
- Image Similarity: Finding images similar to an input image, like searching for all images of dogs based on a sample image.
- Text-to-Image Search: Using a textual query, such as "image of a dog," to find relevant images.
- Content Recommendations: Identifying articles or movies similar to ones you've enjoyed, enhancing search engines and recommendation systems.
How embeddings are generated
Deep learning models, trained on either generalized or specific datasets, learn patterns from data to generate embeddings. Models trained on specific datasets, like cat images, are good at identifying different breeds of cats but not dogs. Generalized models, trained on diverse data, can identify various entities.
Modern models produce embeddings of over 1024 dimensions, increasing accuracy and detail. However, this also raises challenges related to the cost of embedding generation, storage, and computational resources.
Some of the earliest work with creating embedding models included word2vec for NLP and convolutional neural networks for computer vision.
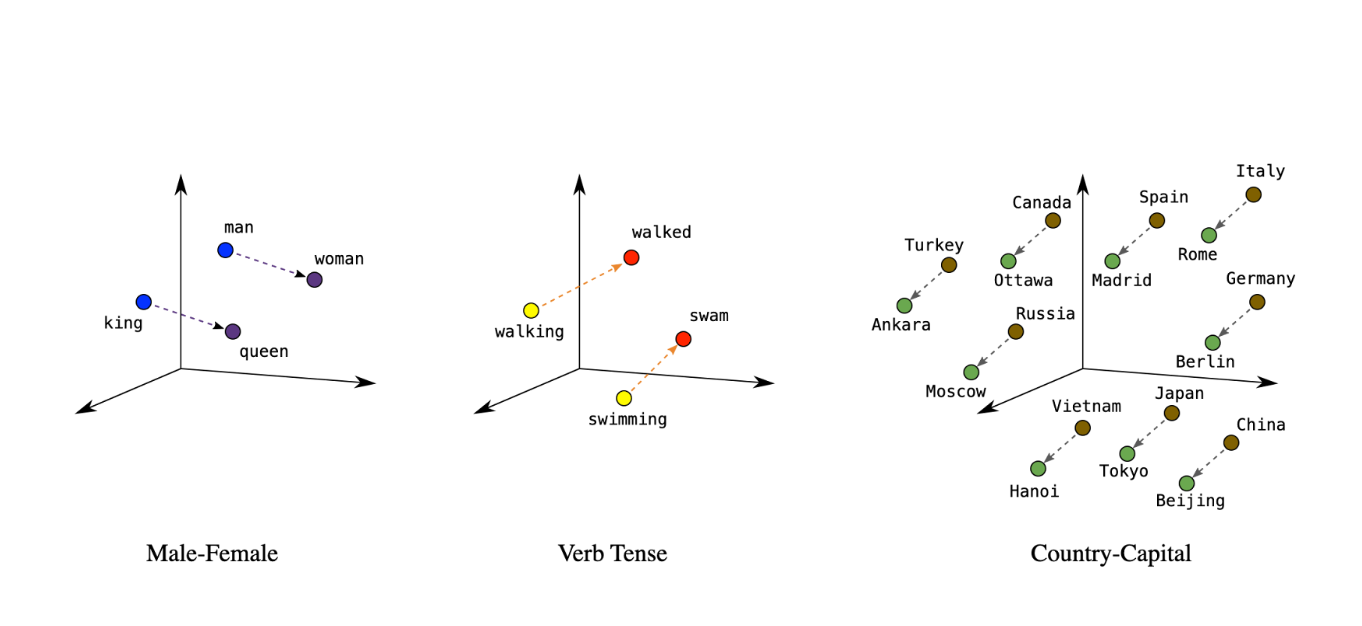
The significance of word2vec
The introduction of word2vec by Mikolov et al. in 2013 marked a significant milestone in creating word embeddings. Word2vec enabled the capture of semantic relationships between words, such as the famous king-queen and man-woman analogy, demonstrating how vectors can represent complex relationships.
This breakthrough revolutionized natural language processing (NLP), enhancing tasks like machine translation, sentiment analysis, and information retrieval.
Word2vec laid the foundation for subsequent embedding techniques and deep learning models in NLP.
Equivalent of word2vec for Images
For images, convolutional neural networks (CNNs) serve as the equivalent of word2vec. Models like AlexNet, VGG, and ResNet revolutionized image processing by creating effective image embeddings.
These models convert images into high-dimensional vectors, preserving spatial hierarchies and semantic information.
Just as word2vec transformed text data into meaningful vectors, CNNs transform images into embeddings that capture essential features, enabling tasks like object detection, image classification, and visual similarity search.
Uploading custom embeddings to Labelbox
Labelbox now supports importing and exporting custom embeddings seamlessly, allowing for better integration into workflows. This new feature provides flexibility in how embeddings are utilized, making it easier to leverage embeddings for various applications.
import labelbox as lb
import transformers
import torch
import torch.nn.functional as F
from PIL import Image
import requests
import numpy as np
# Add your API key
API_KEY = "your_api_key_here"
client = lb.Client(API_KEY)
# Get images from a Labelbox dataset
DATASET_ID = "your_dataset_id_here"
dataset = client.get_dataset(DATASET_ID)
export_task = dataset.export_v2()
export_task.wait_till_done()
data_row_urls = [dr_url['data_row']['row_data'] for dr_url in export_task.result]
# Get ResNet-50 from HuggingFace
image_processor = transformers.AutoImageProcessor.from_pretrained("microsoft/resnet-50")
model = transformers.ResNetModel.from_pretrained("microsoft/resnet-50")
img_emb = []
for url in data_row_urls:
response = requests.get(url, stream=True)
image = Image.open(response.raw).convert('RGB').resize((224, 224))
img_hf = image_processor(image, return_tensors="pt")
with torch.no_grad():
last_layer = model(**img_hf, output_hidden_states=True).last_hidden_state
resnet_embeddings = F.adaptive_avg_pool2d(last_layer, (1, 1))
resnet_embeddings = torch.flatten(resnet_embeddings, start_dim=1, end_dim=3)
img_emb.append(resnet_embeddings.cpu().numpy())
data_rows = []
for url, embedding in zip(data_row_urls, img_emb):
data_rows.append({
"row_data": url,
"embeddings": [{"embedding_id": new_custom_embedding_id, "vector": embedding[0].tolist()}]
})
dataset = client.create_dataset(name='image_custom_embedding_resnet', iam_integration=None)
task = dataset.create_data_rows(data_rows)
print(task.errors)
To compute your ow embeddings and send them to Labelbox, you can use models from Hugging Face. Here’s a brief example using ResNet-50:
This code snippet demonstrates how to create and upload custom embeddings, which can then be used for similarity searches within Labelbox.
Why you should care about custom embeddings
Custom embeddings provide several advantages:
- Tailored Representations: Custom embeddings can be tailored to your specific dataset, improving accuracy in domain-specific tasks.
- Enhanced Performance: They allow for more precise similarity searches and recommendations by capturing nuances specific to your data.
- Flexibility: Custom embeddings offer flexibility in handling various types of data and use cases, making them a versatile tool in machine learning workflows.
Using embeddings for better search
Earlier we mentioned that search (a core activity of search engines, recommendation systems, data curation, etc) is a common and important application of embeddings. How? By comparing how similar two (or many more) items are to each other.
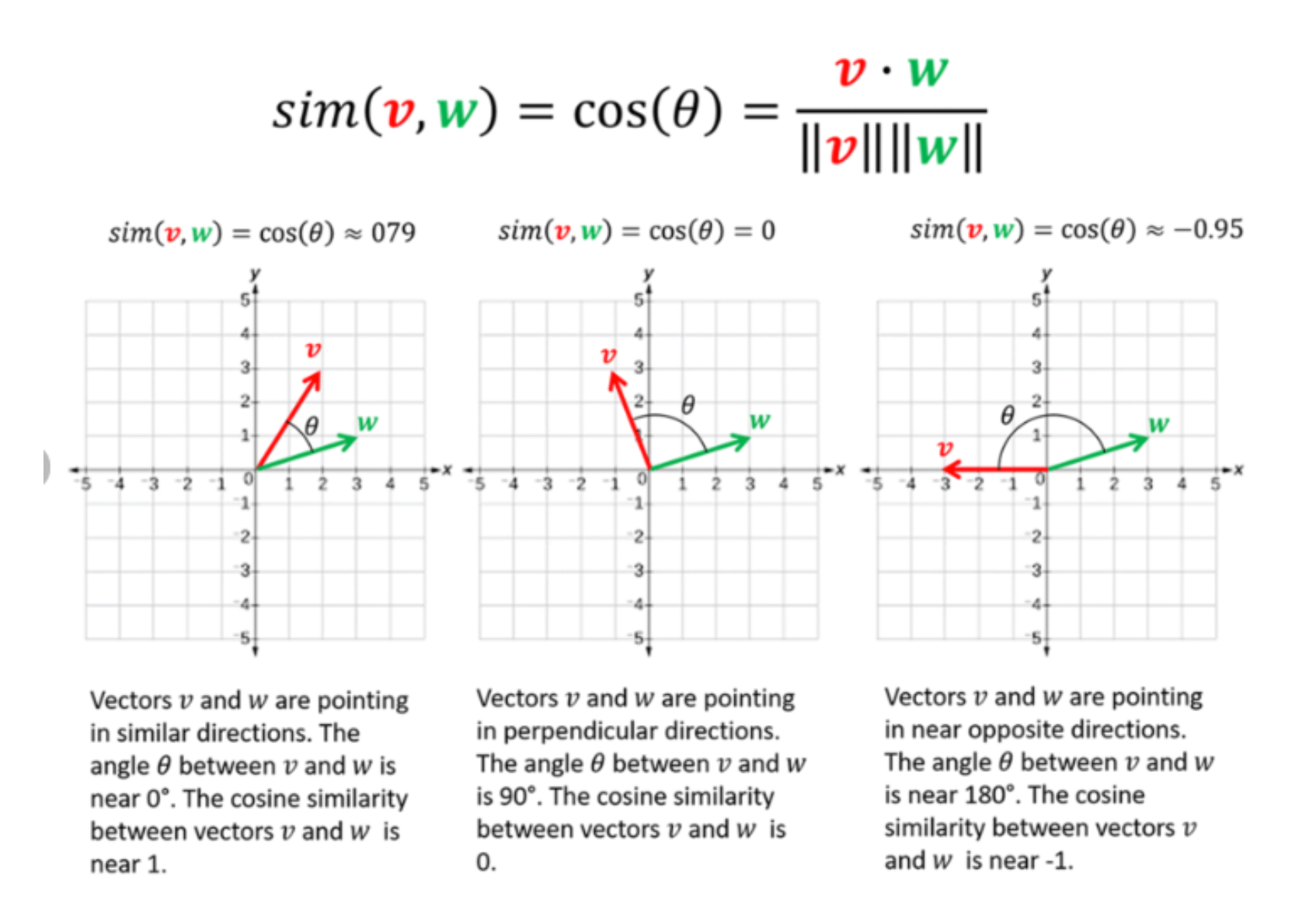
Measuring similarity
The most popular algorithm for measuring similarity between two vectors is cosine similarity. It calculates the angle between two vectors: the smaller the angle, the more similar they are. Cosine similarity scores range from 0 to 1, or -1 to 1 for dissimilarity.
For example, if vectors W and V are close, their cosine similarity might be 0.79. If they are opposite, the similarity is lower, indicating dissimilarity. This method helps in visually and computationally understanding the similarity between different assets.

Because embeddings are essentially vectors, we can apply many of the same operations used to analyze vectors to embeddings.
Strategies for similarity computation
Additional strategies for performing similarity computation include:
- Brute Force Search: Comparing one asset against every other asset. This provides the highest accuracy but requires significant computational resources and time. For instance, running brute force searches on a dataset with millions of entries can lead to significant delays and high computational costs.
- Approximate Nearest Neighbors (ANN): Comparing one asset against a subset of assets. This method reduces computational resources and latency while maintaining high accuracy. ANN algorithms like locality-sensitive hashing (LSH) and KD-trees provide faster search times, making them suitable for real-time applications, although they may sacrifice some accuracy.
- Hashing Methods: Techniques like MinHash and SimHash provide efficient similarity searches by hashing data into compact representations, allowing quick comparison of hash values to estimate similarity. These methods are particularly useful for text and document similarity.
Tree-based methods (KD-trees, R-trees, and VP-trees) and graph-based methods (like Hierarchical Navigable Small World, also known as HNSW) are also options.
Leveraging embeddings for data curation, management, and analysis in Labelbox
Through search, embeddings improve the efficiency and accuracy of data curation, management, and analysis in several ways:
- Automated Data Organization: Embeddings help group similar data points together, making it easier to organize and manage large datasets.
- Enhanced Search and Retrieval: By transforming data into embeddings, search and retrieval operations become faster and more accurate, enabling quick access to relevant information.
- Improved Data Analysis: Embeddings capture underlying patterns and relationships within data, facilitating more effective analysis and insights extraction.
And these are exactly the ways we use embeddings in our products at Labelbox to improve search for data.
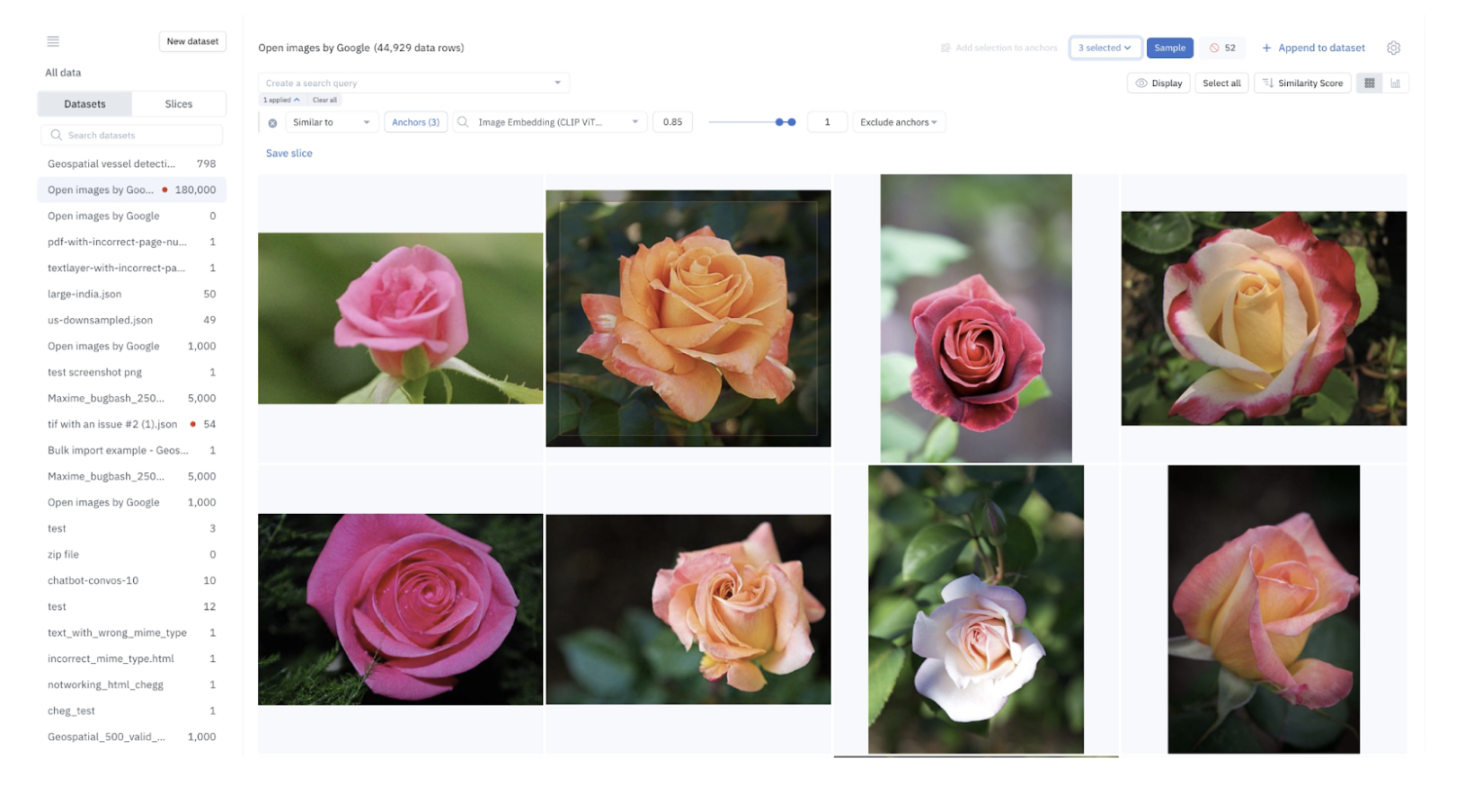
For example, in Catalog, users can find images similar to an input image, such as searching for basketball players on a court. Our natural language search allows users to input a textual query, like "dog," and find relevant images.
Labelbox offers several features to streamline embedding workflows, including:
Data curation and management
- Custom Embeddings in Catalog: Surfaces high-impact data, with automatic computation for various data types.
- Smart Select in Catalog: Curates data using random, ordered, and cluster-based methods.
- Cluster View: Discovers similar data rows and identifies labeling or model mistakes.
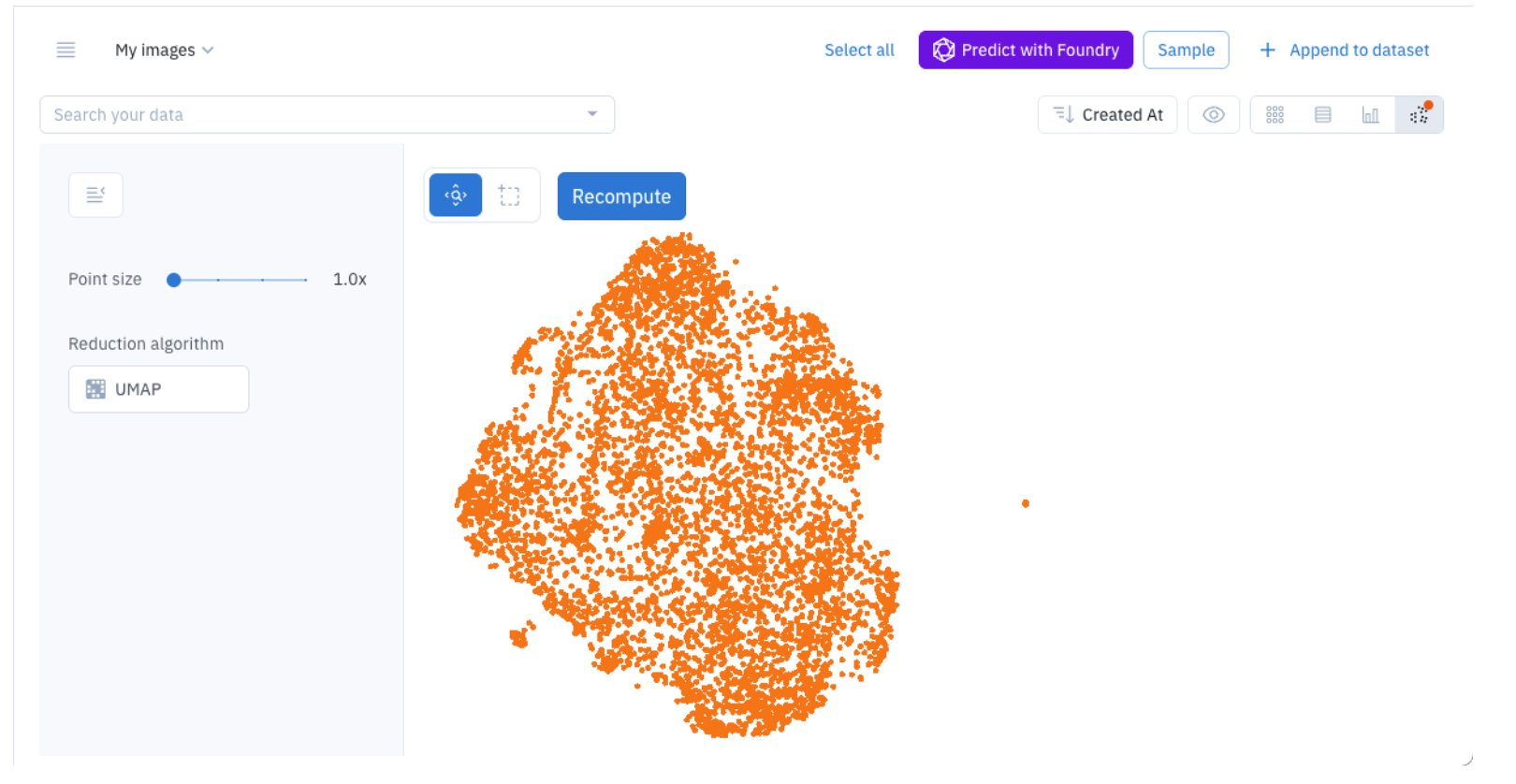
- Natural Language and Similarity Search: Supports video and audio assets.
- Prediction-level Custom Metrics: Filters and sorts by custom metrics, enhancing model error analysis.
- Pre-label Generation from Foundry Models: Streamlines project workflows.
- Enhanced Video Player: Aids in curating, evaluating, and visualizing video data.
Embeddings schema
- Schema Tab: Includes an Embeddings subtab for viewing and creating custom embeddings.
API and inferencing
- Inferencing Endpoints: Generate predictions via REST API without creating data rows or datasets.
Additional workflow enhancements
- Boost Express: Request additional labelers for data projects.
- Export v2 Workflows and Improved SDK: Streamlines data management.
These features ensure that embeddings are utilized effectively, making your workflows more efficient and your models more accurate.
Conclusion
Embeddings are a powerful tool in machine learning, enabling efficient and accurate similarity searches and recommendations. We hope this post has clarified what embeddings are and how they can be utilized.
For more on uploading custom embeddings, check out our documentation and developer guides.
Additional resources on embeddings can be found here:
- Watch the video: Understanding embeddings in machine learning.
- Learn more in our community about: How to upload custom embeddings and why you should care.
Thanks to our contributors Tomislav Peharda, Paul Tancre, and Mikiko Bazeley!


