
Model
Improve performance using foundation models
Introducing the Foundry
Foundry enables teams to use world-class foundation models to enrich datasets and automate tasks. In a few clicks, use this AI copilot to explore, test, and integrate powerful models into your workflow.



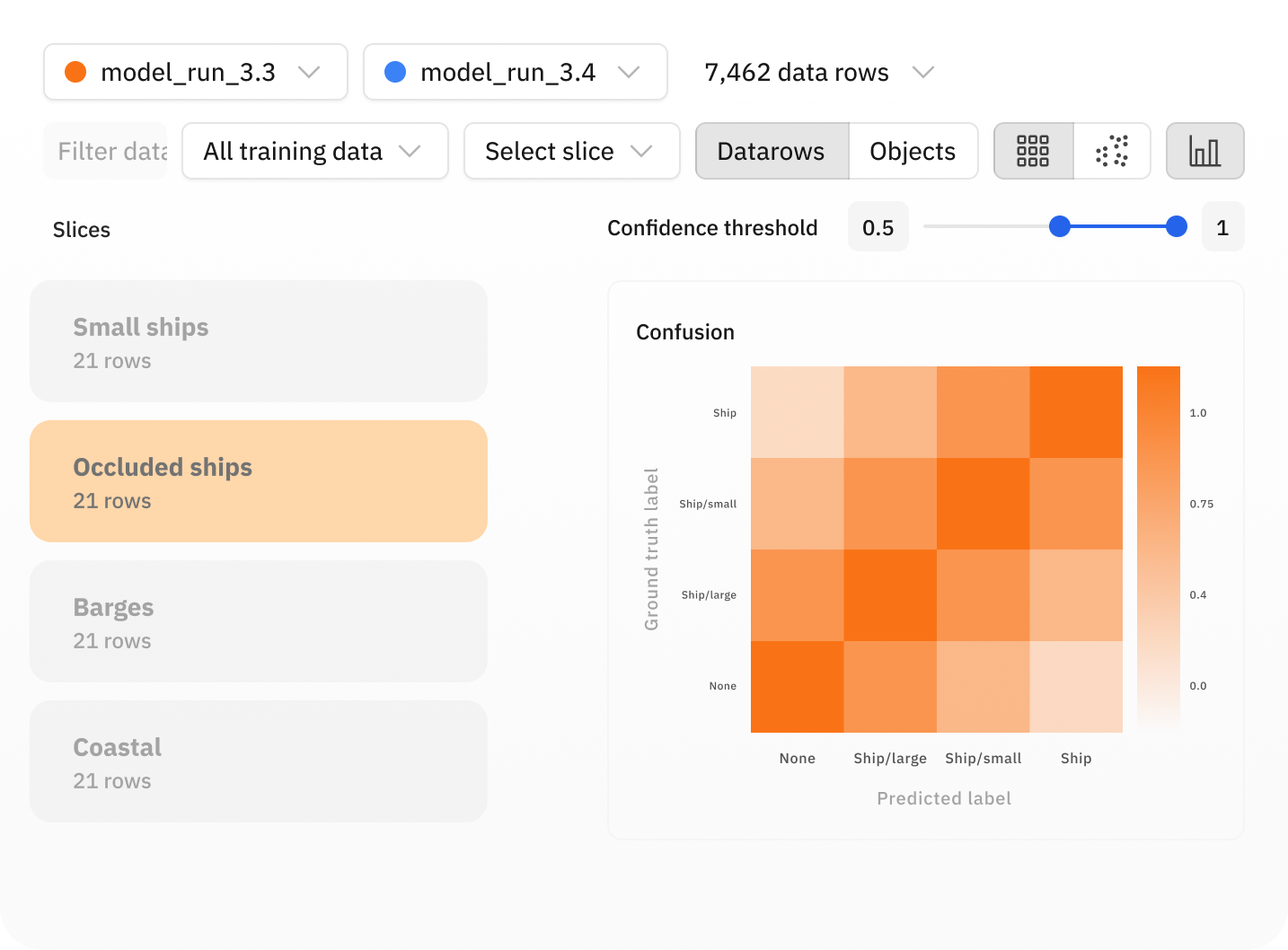
Build robust models with powerful error analysis
Identifying and fixing model errors with improved training data is the key to building high-performing models. Conduct powerful error analysis to surface model errors, diagnose root causes, and fix them with targeted improvements to your training data. Collaboratively version, evaluate, and compare training data, hyperparameters, and models across iterations in a single place.
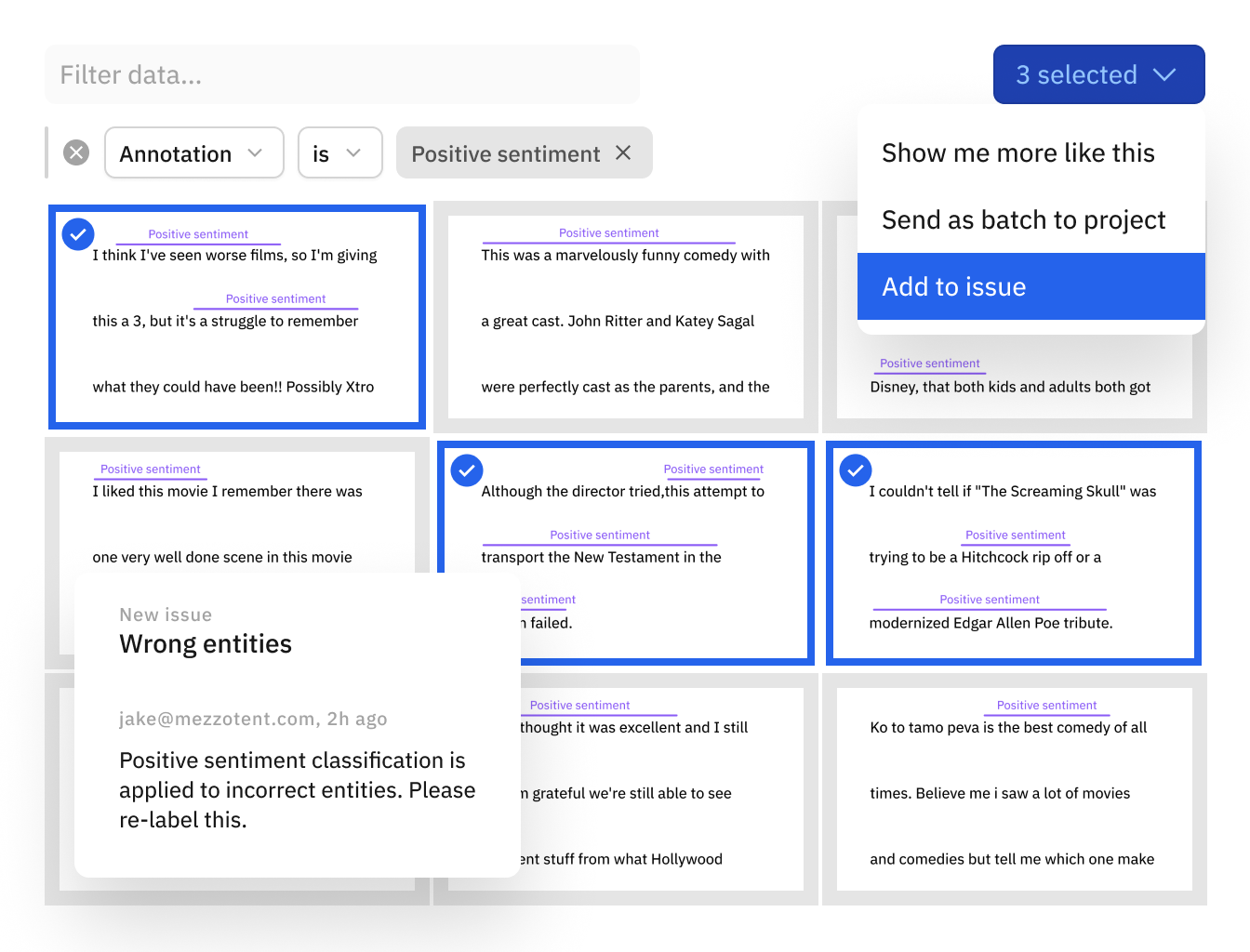
Leverage your model to find and fix data quality issues
Data quality issues can severely undermine your model’s performance. Use your model as a guide to find and fix labeling mistakes, unbalanced data classes, and poorly crafted data splits that can affect model performance.
Optimize labeling budget
Not all data impacts model performance equally. Leverage your data distribution, model predictions, model confidence scores, and similarity search to curate high-impact unlabeled data that will boost your model performance.



Plug into powerful data-centric workflows
Simplify your data-to-model pipeline without friction. Seamlessly integrate Labelbox with your existing machine learning tech stack using our Python SDK. Labelbox Model works with any model training and inference framework, major cloud providers (AWS, Azure, GCS), and any data lake (Databricks, Snowflake).
Supported annotations
 Bounding box
Bounding box Segmentation
Segmentation Polygon
Polygon Polyline
Polyline Point
Point Classification
Classification
- Classification
- Bounding box
- Polygon
- Polyline
- Classification
 Named-entity recognition
Named-entity recognition - Classification
- Classification
- Classification



