
 All guides
All guidesGet started with active learning
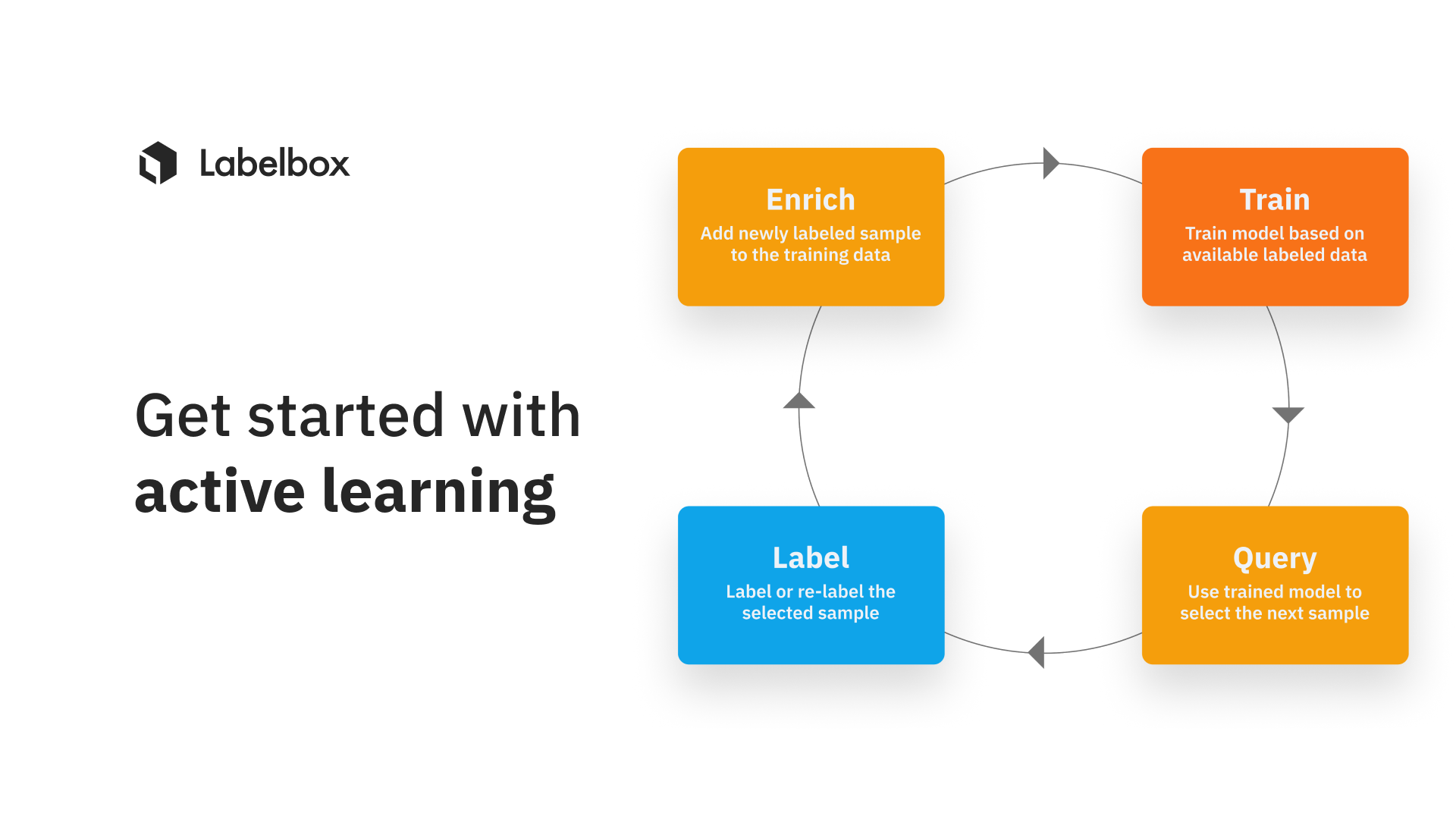
What is active learning?
Machine learning (ML) teams working with large volumes of unstructured data in order to generate high-quality training data typically encounter a critical question: If not all my data is created equal, among all of my unlabeled data, what should I label in priority? Active learning in machine learning is the process of answering this very question, by identifying what data will most dramatically improve model performance and feeding these insights into the prioritization of data for labeling.
Why is active learning important in machine learning?
#1: Avoid overspending
Your goal should be to label as little data as possible by focusing your data labeling and data debugging efforts on the data that will most dramatically improve model performance. By doing so, you'll be able to save significant time and resources upfront. Active learning in machine learning helps with this prioritization.
#2: Better prioritization
When ML teams possess a wealth of unlabeled data and cannot label everything at once, the best option is to select a fraction of your assets to label, and choose from the highest impact assets first.
#3: Boost model performance
It turns out that being very intentional about what to label next is one of the best ways to improve the performance of your machine learning models. This is evidenced by other leading AI companies such as Tesla, who have stated that, “in academia, we often see that people keep data constant, but at Tesla it’s very much the opposite. We see time and again that data is one of the best, if not the most deterministic levers to solving these [challenging cases].” - Source: Tesla AI Day 2022
In addition, leading AGI research organizations such as OpenAI have also utilized active learning to better train, deploy, and maintain popular models such as GPT-3 and DALL-E 2. To train DALL-E 2, they utilized two different active learning techniques to iterate on the image classifiers: one to find and fix false positives, and another to find and fix false negatives. The organization has published a blog post about the active learning techniques used to modify and process the data used to train DALL-E 2 to ensure that no violent or lewd images are included in the training dataset. Their active learning process used classifiers to select a handful of unlabeled images that are likely to improve classifier performance. Finally, humans produced labels for these images, adding them to the labeled dataset. The process was repeated to iteratively improve the classifier’s performance.
The ML engineering team at Doordash also shared how they utilized active learning techniques to select low-confidence samples and then built a human-in-the-loop workflow for better menu item labeling. By leveraging active learning based on low confidence predictions, they were able to utilize similarity search and fix model performance on low performing slices of data.
Building off these examples, the goal of your AI team and your labeling team should be to identify the unique assets that will boost model performance the most, and to focus all of your labeling time, efforts and budget on these high impact assets. The benefits of this data-centric approach yields higher model performance – allowing teams to rapidly ship models to production, continuously improve models once in production, and effortlessly accumulate competitive advantages faster than ever before.

How active learning unlocks value for all ML teams
Within the model development lifecycle, there are generally two phases of iterative and data-centric performance improvements. Although both encounter a set of different challenges, active learning is highly relevant for both stages:
Models in development: these models are not yet deployed into production or accepting live / new ingested data. However, ML teams continuously evaluate and improve these models, trying to reach the performance metrics required to get them into production as quickly and as confidently as possible. Active learning will help you select the right data to include in your training sets so you can reach desired model performance.
Models deployed in production: These models have either met or exceeded the initial minimum viable performance levels required for them to be deployed into production. At this point, they are generally accepting live / newly-ingested data in the “real world.”
Even after a model has been deployed to production, ML teams still need to keep improving their models for two key reasons:
1. Improving their product/service relies upon continuously improving their model
2. The data from production changes over time; hence model performance tends to decrease over time if no steps are taken to tune the model based on these changes.
Active learning will help you select what to label, among all this production data, in order to keep improving model performance.
Key challenges to overcome when leveraging active learning
Even with an organized data lake, selecting the most useful data can be a complex challenge. To improve model performance, you don’t need volumes of just any data – you need the most relevant data. Filtering out the value from the noise becomes even more challenging and time consuming when deployed models confront the continuously evolving landscape of real data.
However, implementing this data-centric strategy poses a challenge as it requires ML teams to have purpose-built tools with the ability to:
- Visualize assets, model predictions, and ground truths alongside each other. Identify model predictions.
- Understand where models are performing well and struggling. Evaluate the performance of a model on the training data splits, on incoming production data, and on any data slice.
- Understand the distribution of your data.
- Analyze model confidence scores.
- Ensure that every ML experiment is reproducible.
- Compare models against each other, as you go through data-centric iterations. The goal is to track whether models are actually making progress with each successive iteration.
- Track model performance over time as performance requirements and real ground truth conditions change.
The complexity compounds because the workflows typically need to be continuously repeated in order to meet the demands of surging capacity to address real world changes or data conditions that suddenly and significantly reduce model performance. Fortunately, dedicated tooling now exists to support these critical active learning workflows as we will introduce later in this post.
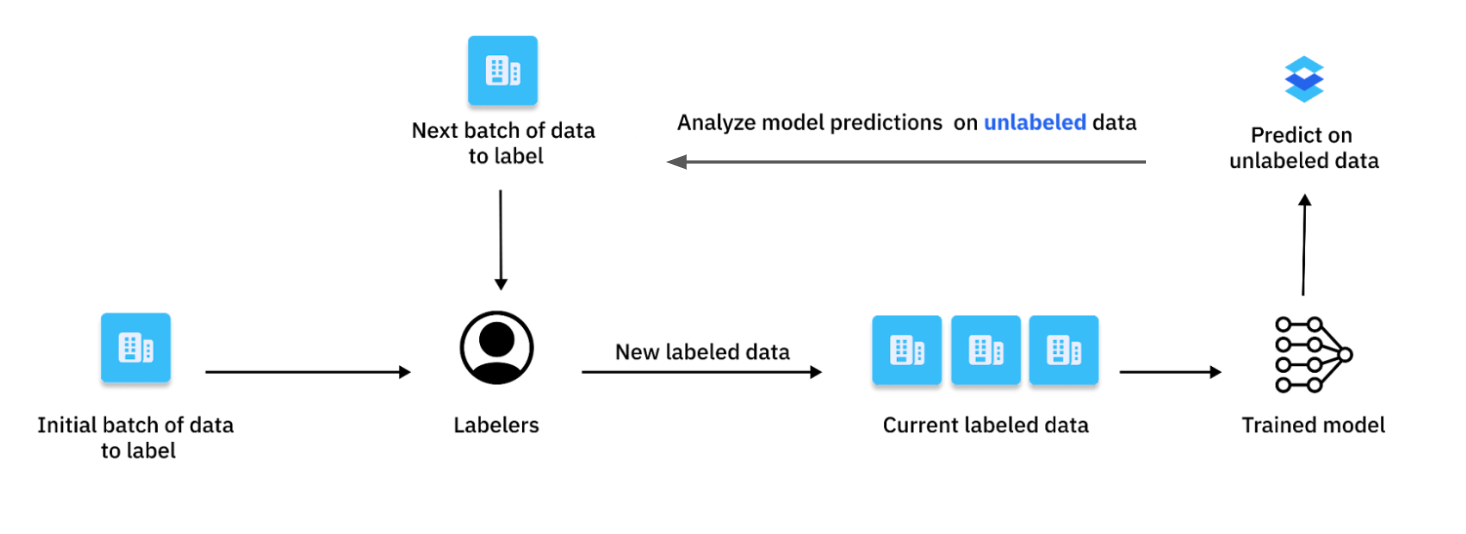
Current active learning strategies
The three dominant active learning strategies we’ve encountered in the field can be grouped into broad categories:
- Active learning that leverages your data distribution
- Active learning that leverages your model predictions
- Active learning that leverages model error analysis
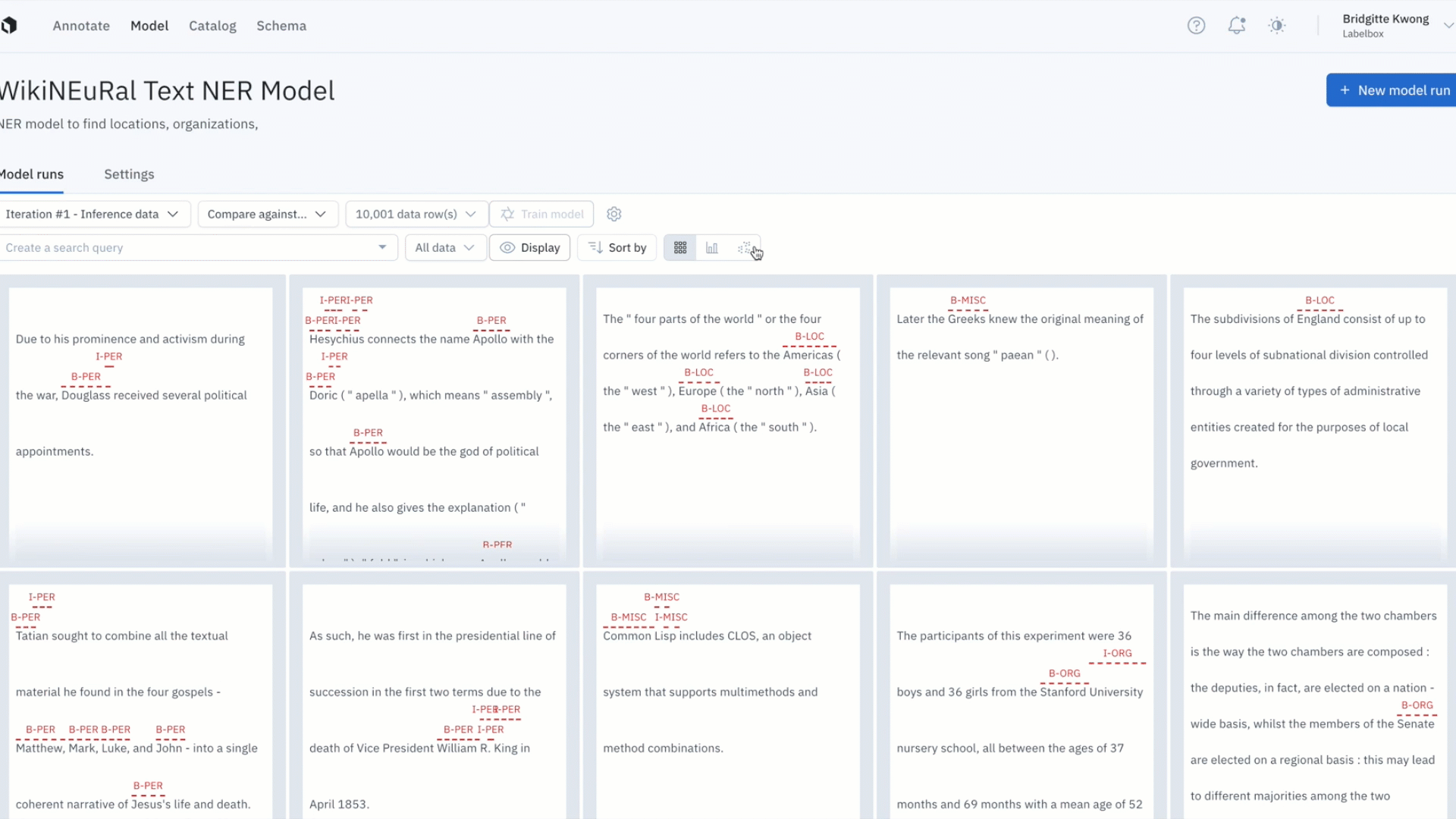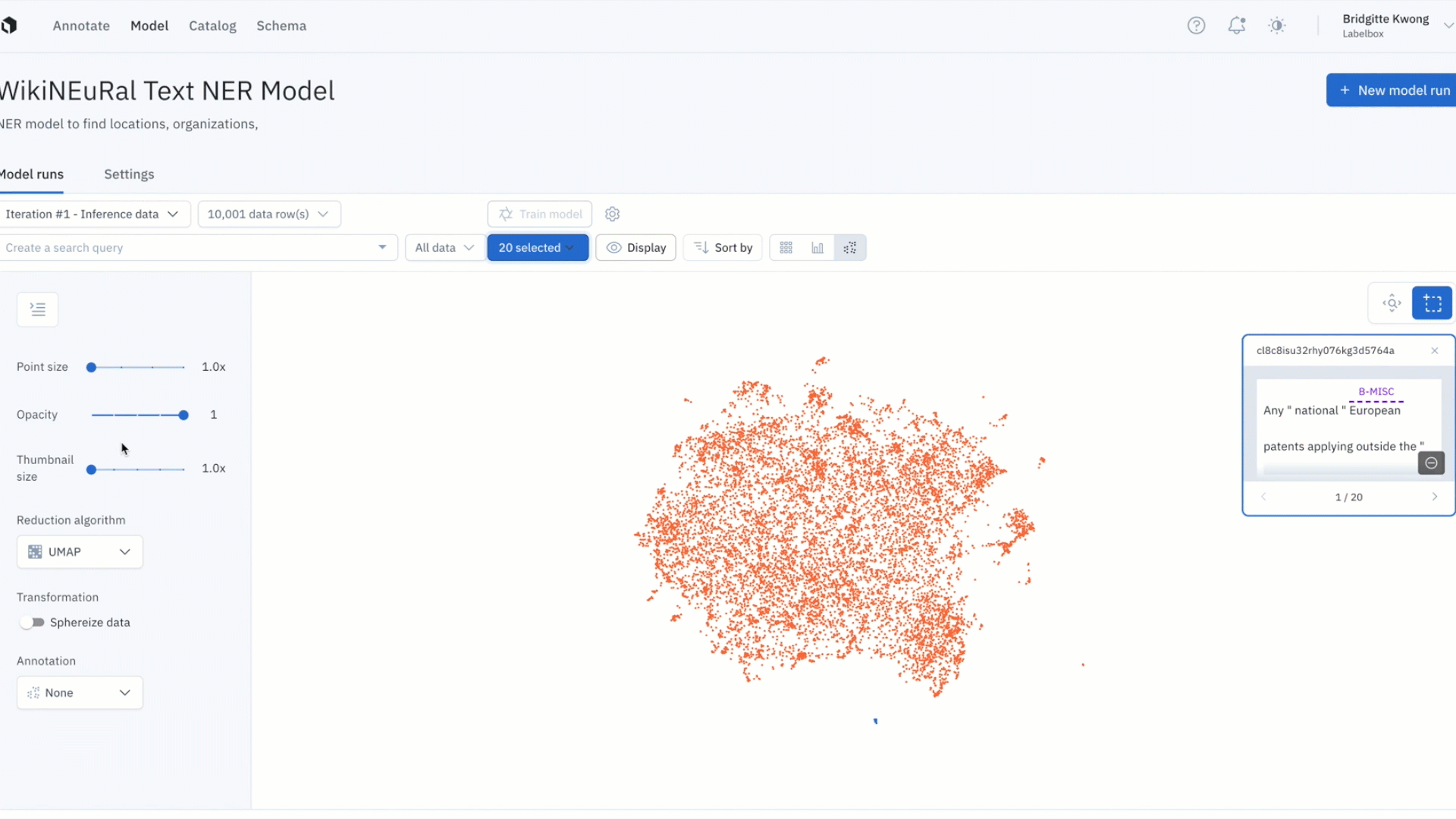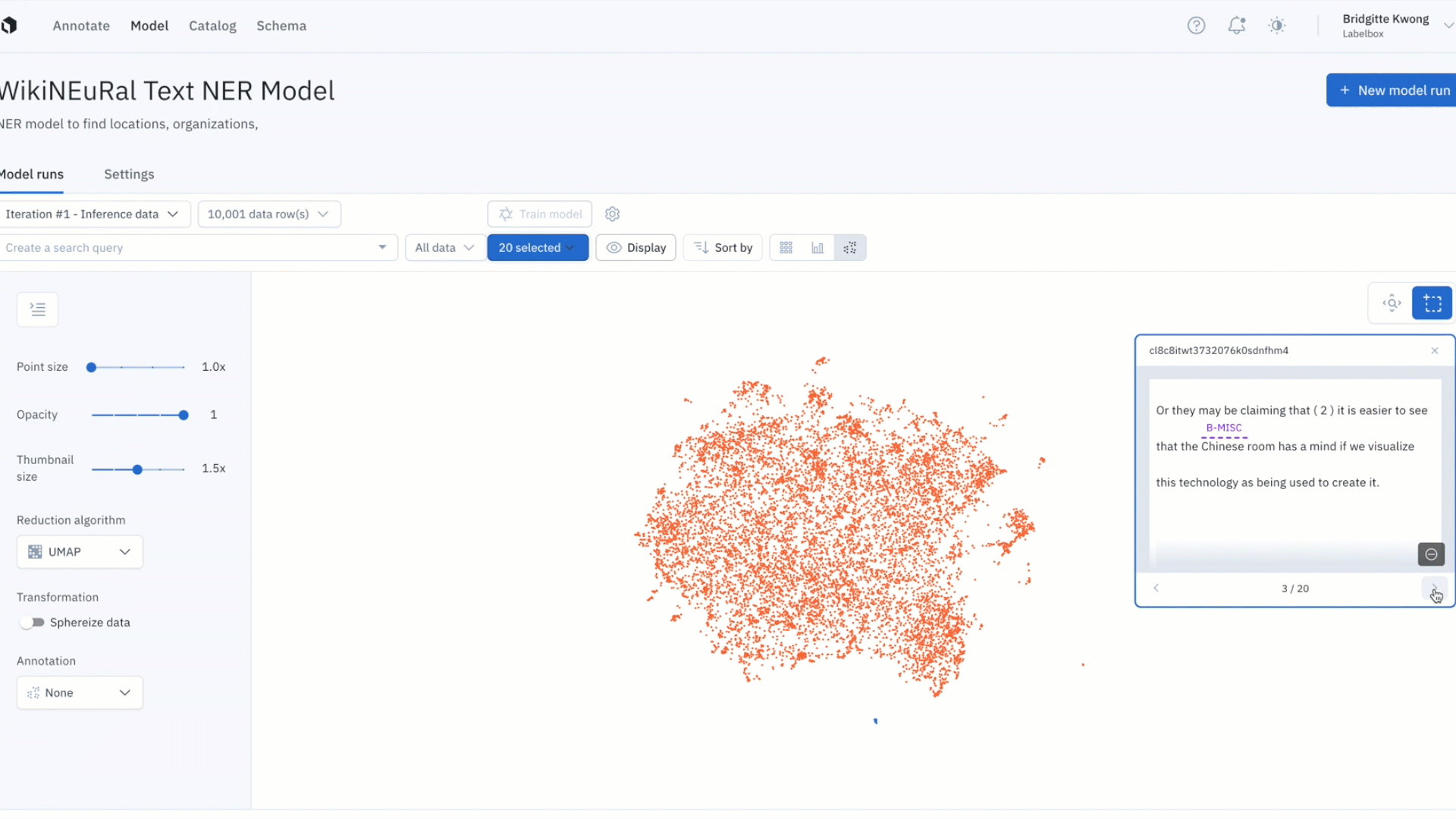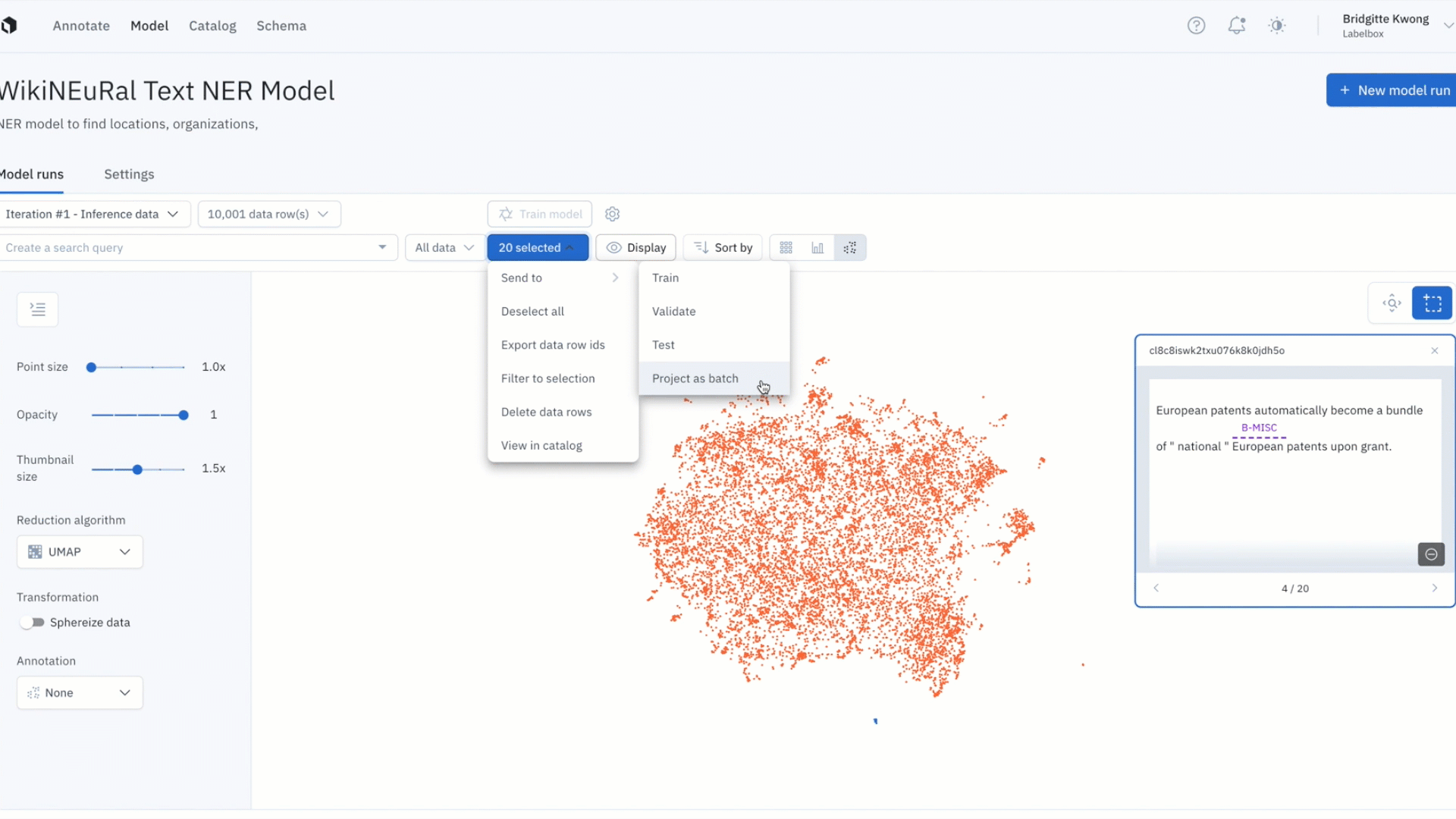
Active learning strategies that leverage your data distribution
Active learning techniques of this type can be applied even before you have labeled data or a trained a ML model, as the primary focus of these techniques is to analyze your data distribution.
- Prioritize diverse data
Selecting diverse data is one of the critical steps to follow before you begin training your model. The process focuses on picking a small, diverse subset of data, e.g. by using random sampling, or e.g. by clustering your unlabeled data and sampling from each cluster.
2. Prioritize out-of-distribution data
Based on the nature of continuous change in the real world, once models are delivered and deployed, they are often exposed to data samples they were not trained on. As a function of time and volume, the model will make predictions on data with increasingly more varied characteristics that often outpace the data diversity of the initial training data set.
In essence, once deployed, the model becomes stale and outdated quickly –— posing inherent challenges for improving, let alone maintaining machine learning models.
Active learning workflows alert ML teams to indications of change or differences in what’s happening lately compared to what had been happening before.
For example, using image segmentation to identify geographic features after a natural disaster may be a much more nuanced challenge to the model than it was pre-disaster. As a natural language processing (NLP) example, the model can report that it is seeing many more instances of deceptive fake news articles than it has previously encountered during past model runs on real / live data.
A model reporting a sharp change in sentiment analysis can alert end users to new service disruptions experienced by customers. Active learning helps not only to identify these changes, but also expedite retraining on areas that are outside the training distribution.
ML Teams will have to confront this data drift – when the underlying data distribution changes over time. If the model was engaged within an Active Learning workflow, the model would:
- Alert the ML team that it is encountering data with new qualities than previously observed.
- Triage and identify data that is outside the training distribution and cue labeling for data samples that exhibit similar characteristics.
Active learning strategies that leverage your model predictions
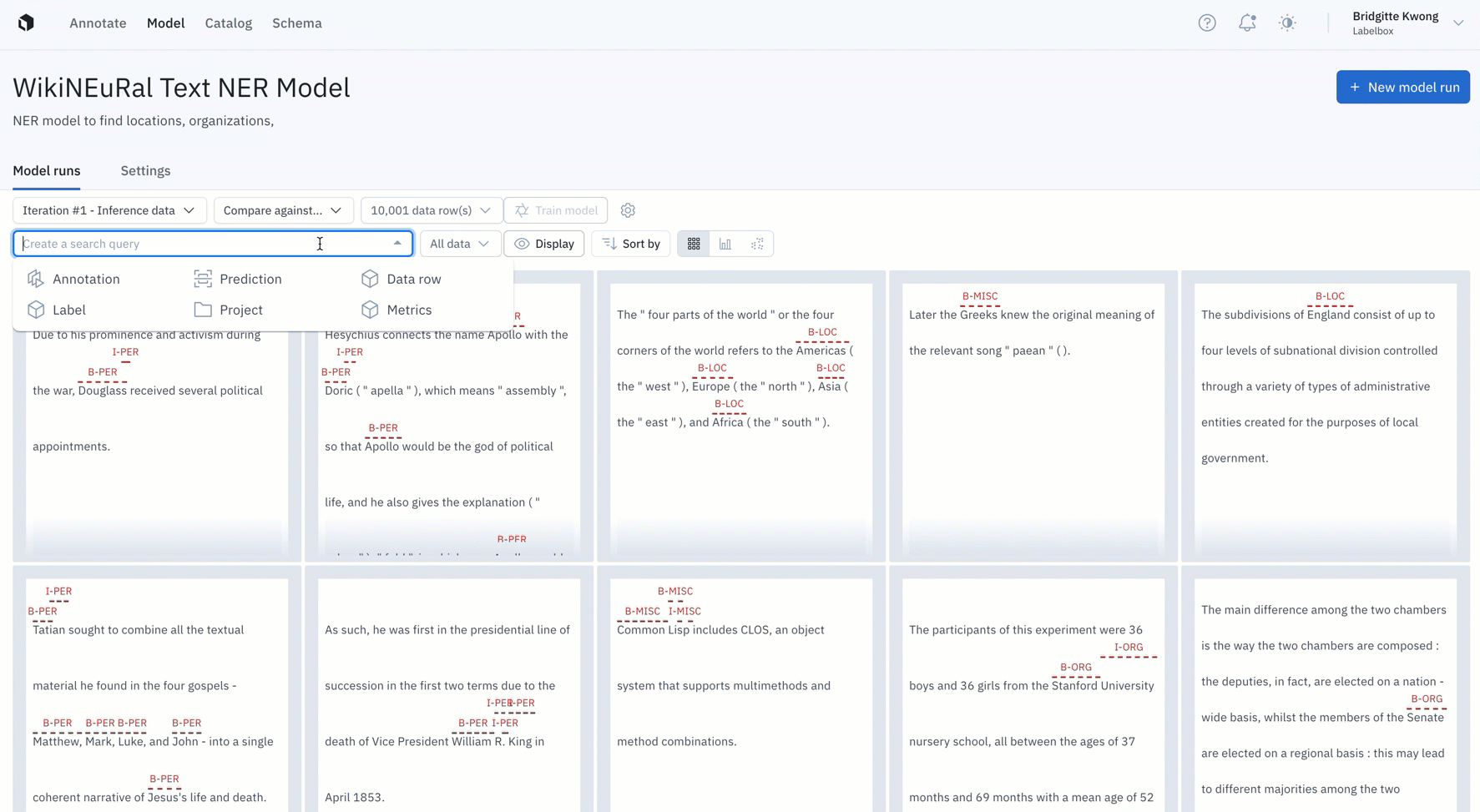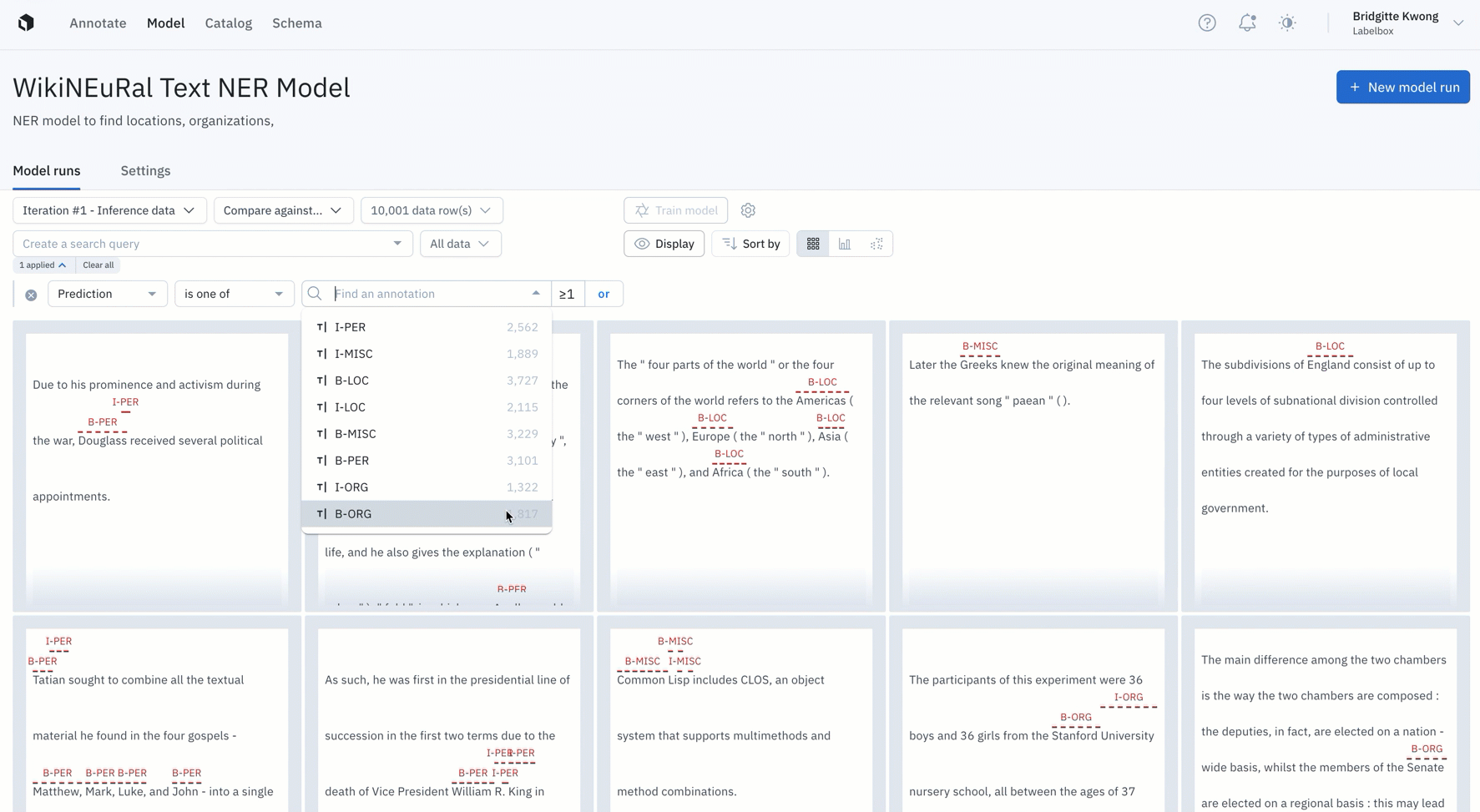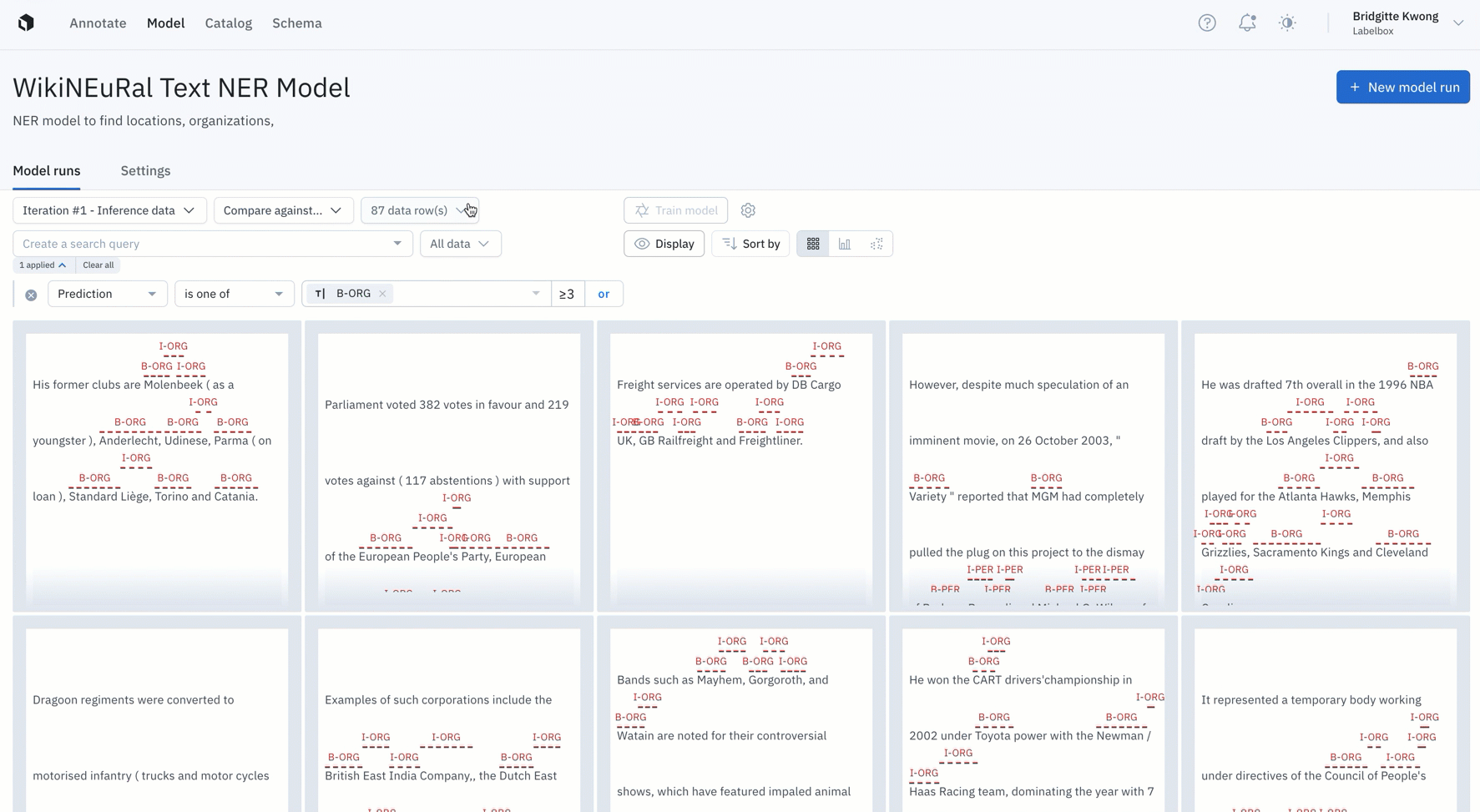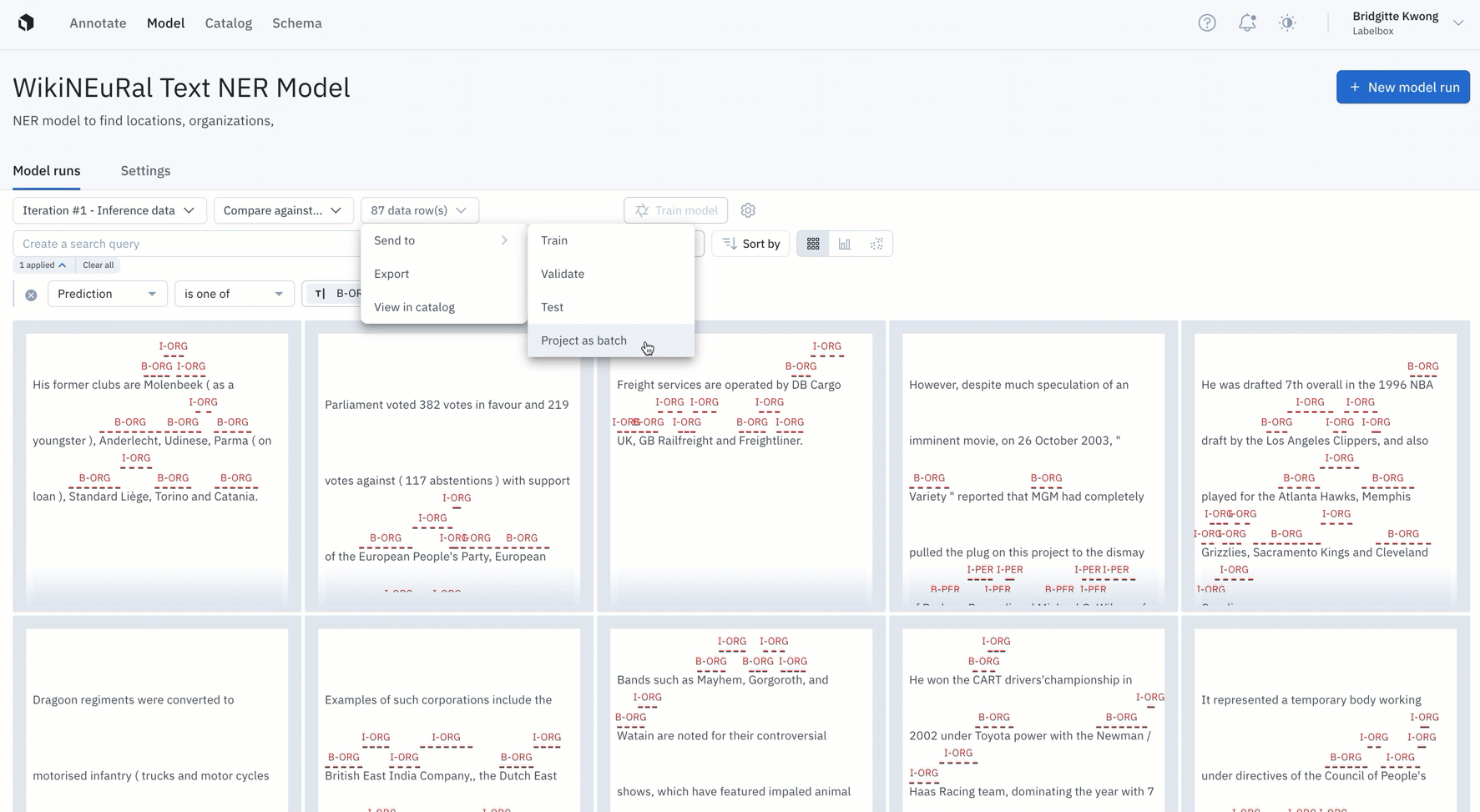
Once you have a trained model, you can use it as a guide to select high impact data that will boost model performance. The following active learning techniques can be applied to your unlabeled data, as long as you generate model predictions on them. This is a typical setting during model development (with your unlabeled data that sits unused in a data bucket) and once your model is in production (with real data that your model is being confronted with in production).
- Prioritize low confidence predictions (uncertainty sampling)
Active learning workflows of this type quickly identify and triage areas where model confidence is low. For models that have already been deployed and spent time confronting real world data, active learning identifies areas where model confidence has declined based on a variety of factors, such as shifts in the data itself.
Active learning workflows select the data necessary to boost model performance among these areas of uncertainty as well as track the impact of each retraining on model performance, across all data splits, data slices and model classes.

2. Prioritize rare predictions
We've observed that active learning workflows become even more critical and valuable for teams that work with rare data — defined as data where there are minimal observable or found samples to use for training even the initial model. These use cases demand that ML teams bring to bear every bit of data they have, at any given time, in order to attain any sort of reliable model performance.
Active learning workflows select the data necessary to improve performance in the prioritized model prediction classes or metadata tags, as well as track the impact of each retraining on model performance, across all data splits, data slices and model classes.
Improvement cycles for rare predictions and rare metadata tags can happen at the moment that new real and rare data becomes available, rather than waiting a longer period of time until a larger quantity batch has become available.
Active learning strategies that leverage model error analysis
Some advanced active learning techniques may require both model predictions and ground truth data. While training data typically is labeled, it is rarely the case for production data. The solution is to label a subset of your production data and then to apply the following active learning techniques on this subset of labeled data.
Prioritize data on which your model is struggling
Active learning techniques help find and fix model errors by:
- Identifying and surfacing areas of disagreement that occur between the model predictions.
- Bucketing model errors into patterns of model failures.
- Mining all of your unlabeled data, looking for similar challenging assets, and sending them to labeling.
- Tracking the impact of each retraining on model performance, across all of the data splits, model classes and data slices.
Learn more about how to find and fix model errors in our “Find and Fix Model Errors” Guide.
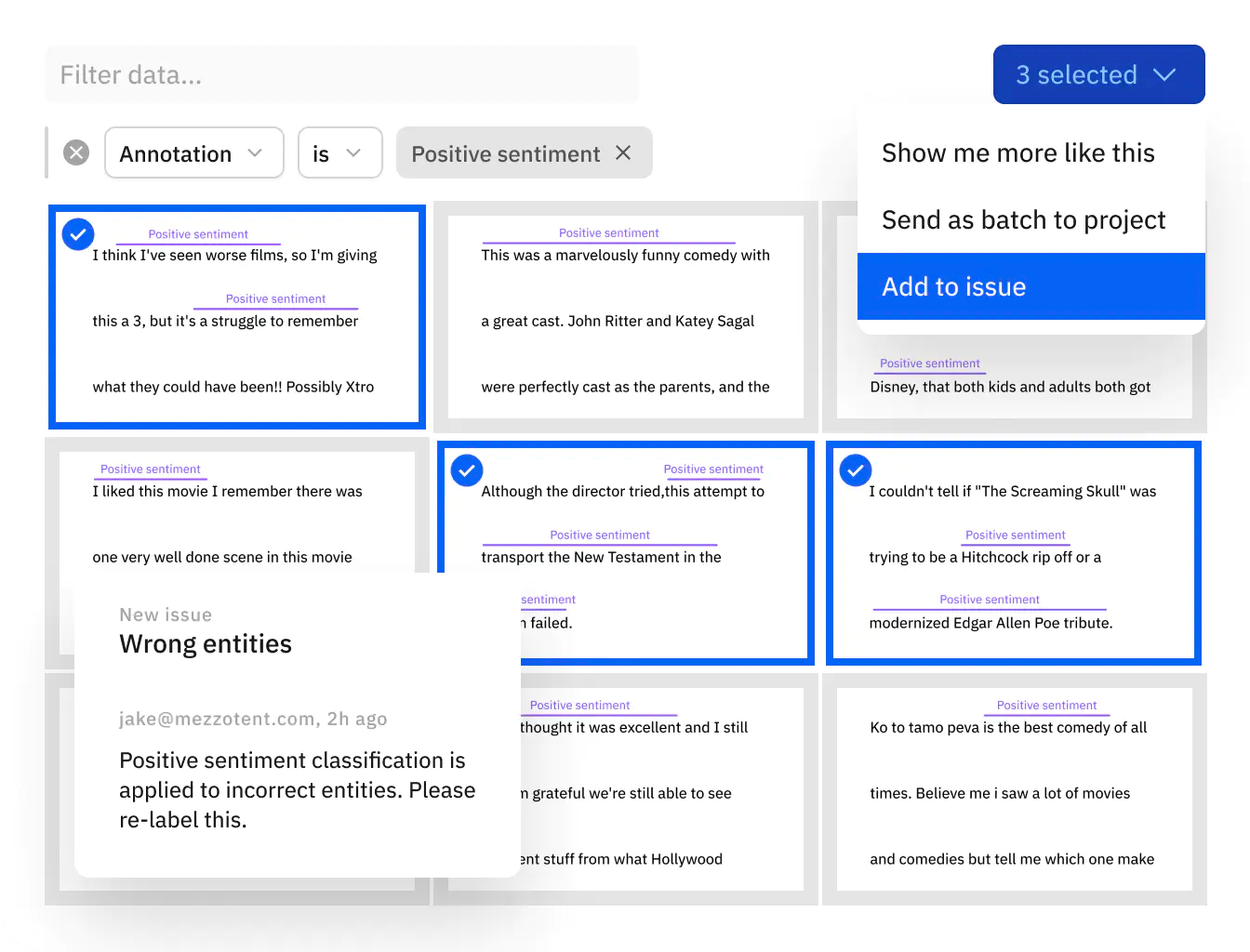
Prioritize labeling mistakes that undermine your model training
Active learning techniques help find and fix label errors by:
- Identifying and surfacing areas of disagreement that occur between the model and labels, but where the model also shows high confidence.
- Visualizing these candidate label errors.
- Mining all of your labeled data, looking for similar annotation mistakes, and sending them to re-labeling.
- Tracking the impact of each retraining on model performance, across all of the data splits, model classes and data slices.
Learn more about how to find and fix label errors in our “Find and Fix Label Errors” Guide.
Combining active learning techniques to compound your gains
Having shared some of the multiple techniques to implement active learning, we recommend evaluating these techniques based on your use case and seeing these building blocks as tools in your team’s ML workbench to solve different model performance challenges. We have seen that ML teams that mix together the core building blocks for active learning techniques are able to compound the value of these techniques to deliver further model improvements. By setting up the infrastructure and workflows that allow you to do this easily – and even automatically – apply all of these active learning techniques, ML teams can unlock compounding and exponential value, especially compared to doing just one active learning technique (or not doing any active learning at all).
Leverage Labelbox for active learning
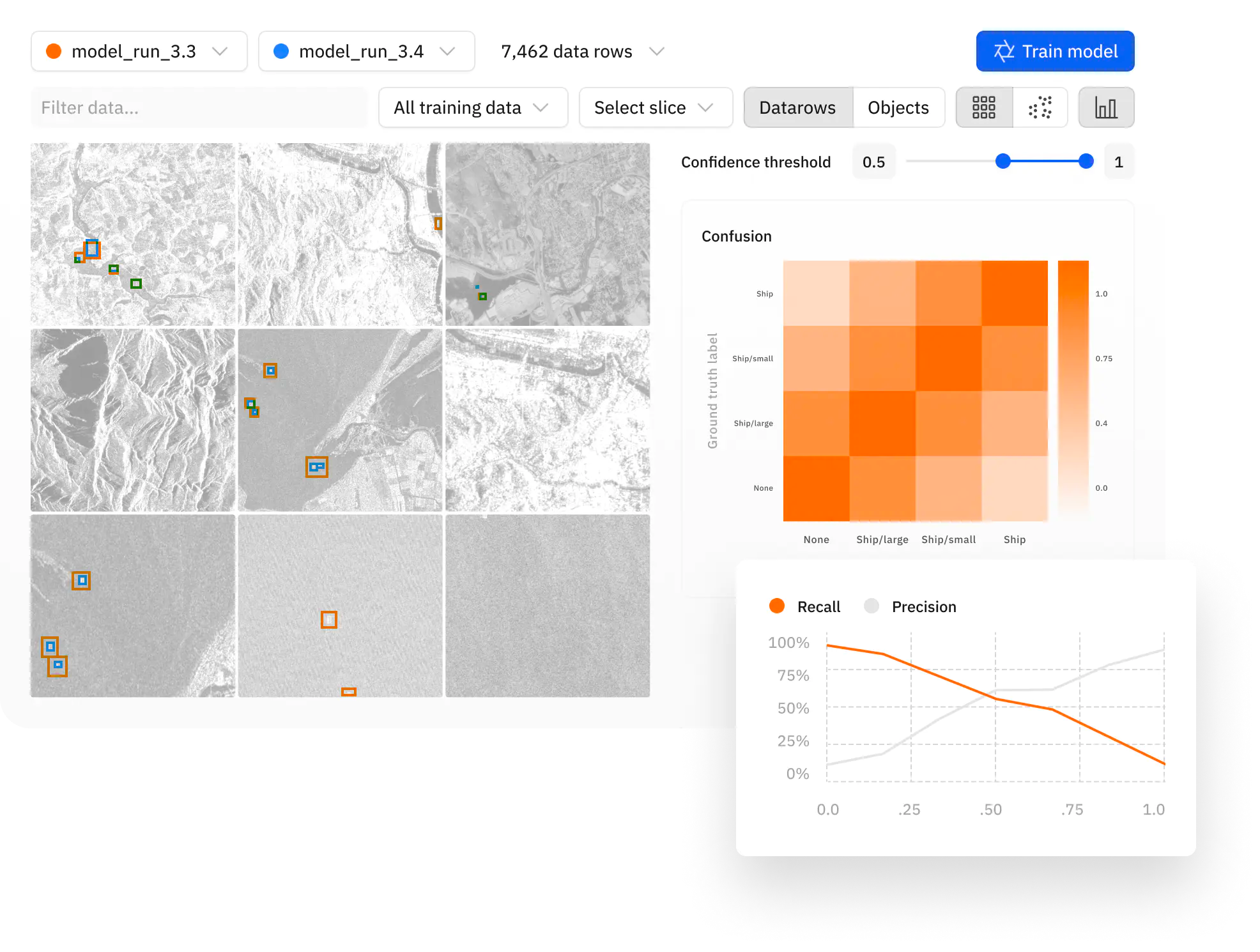
Labelbox introduces a convenient way to work with your data and models to help you get started faster with your active learning workflows. Whether the most relevant strategy calls for retraining on edge cases and outliers; updating human labeling queues; adopting model-assisted labeling; or refining data splits, Labelbox empowers your team with a diverse workbench of active learning tools necessary to accelerate, streamline, and scale implementation of these model improvement techniques above.
- Amplify impact by going through many active learning iterations, as frequently as possible.
- Interact with data visually; compare model predictions to ground truth; identify edge cases and identify trends in model behavior.
- Curate high-quality, balanced training data. Split labeled data into training, validation, and test datasets, including adjusting the configuration of these datasets across versions.
- Cluster visually similar data to understand trends in real data distribution and how those trends impact model performance.
- Comprehend the nuances of a model's performance and add crucial context to key decision-making metrics like Intersection over Union (IoU); Precision and Recall, and more.
- Version your model experiments and model metrics. Easily track each data version to reproduce model results, by preserving the original datasets used to train the model.
ML teams can leverage Labelbox's data engine to deliver targeted improvements to your training data, so that your team can save crucial time and achieve better and faster model performance.

Active Learning customer spotlight: Cape Analytics
Cape Analytics enables insurers and other property stakeholders to access valuable property attributes during underwriting, by using computer vision algorithms to extract information from geospatial imagery. The power of this solution lies in combining the accuracy and detail of property information traditionally relegated to in-person inspections, with the lightning speed of a living database covering the entire property base of the US, and delivering this information in a matter of seconds.
Cape Analytics currently uses active learning loops to study the uncertainty of their models. They first select data where the model is uncertain and feed it into Labelbox, and then back into their model and execute this loop as many times as needed in order to hit their model performance goals. The aggregate time saved from utilizing Labelbox’s active learning workflows represented an estimated 30%+ increase in total time savings, as well as months of custom development work in engineering hours.
According to their principal data scientist, Giacomo Vianello, "we've found that some active learning techniques are more successful than others depending on the project at hand. Also, it’s not just always about performance, but also robustness. Active learning finds corner cases that may not move the needle for model performance, but improve robustness. This is important to our customers because we're making our models more reliable."

Active learning customer spotlight: Deque
Deque is a leader in digital accessibility which is the practice of making digital documents, web and mobile apps accessible to everyone, including people with disabilities. Using the power of machine learning, the Deque team is now focused on the next generation of accessibility testing. Building out the components of their ML program, Deque leverages a sophisticated data engine using model diagnostics and active learning that’s capable of prioritizing the most performant classes of data, discovering model errors quickly, and fueling their iterations with high-quality data.
The ML team at Deque were able to make considerable improvements to model performance by seeing the ability to evaluate and visualize model performance. According to Noe Barrell, Deque's machine learning engineer, “we detected some noise issues in our dataset and thanks to model diagnostics, we were able to filter out about one-third of data points we considered less trustworthy. By doing so, model performance went up 5%. We re-labeled some data and we saw the performance went up again after we added the re-labeled points. It was challenging data for humans to label and for the model to understand. Being able to target the data we already had in Labelbox and make changes and fixes to it was really helpful to us as a team to save time and target where we knew it would make a difference in our model’s performance.”
The Deque team made huge leaps in several areas via model diagnostics and were able to target their data collection in a way that addresses model failures more quickly. For instance, they boosted performance on classes of data such as improving detection of checkboxes from 47% accuracy to 75% accuracy, presentational tables from 66% accuracy to 79% accuracy, and radio buttons from 37.9% accuracy to 74% accuracy.
Try Labelbox and its active learning features yourself for free, or request a demo to learn how it works.


