






Let foundation models do the work
We are bringing together the world's best AI models to help you perform data labeling and enrichment tasks across all supported data modalities. Achieve breakthroughs in data generation speed and costs. Re-focus human efforts on quality assurance.

"We love our initial use of Model Foundry. Instead of going into unstructured text datasets blindly, we can now use pre-existing LLMs to pre-label data or pre-tag parts of it. Model Foundry serves as a co-pilot for training data."
- Alexander Booth, Assistant Director of the World Series Champions, Texas Rangers
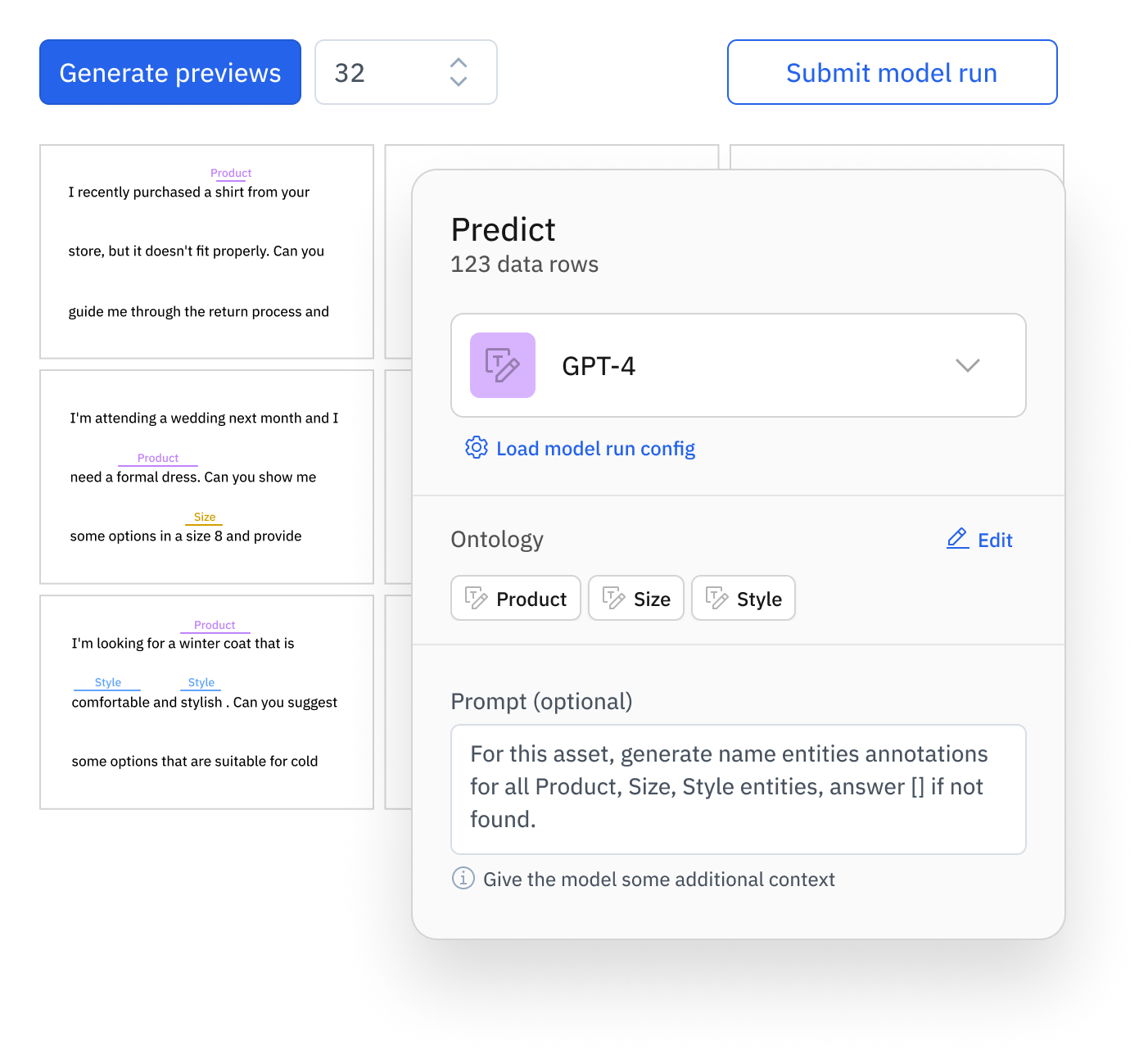
Pre-label data in a few clicks
AI builders can now enrich datasets and pre-label data in minutes without code using foundation models offered by leading providers or open source alternatives. Model-assisted labeling using Foundry accelerates data labeling tasks on images, text, and documents at a fraction of the typical cost and speed.
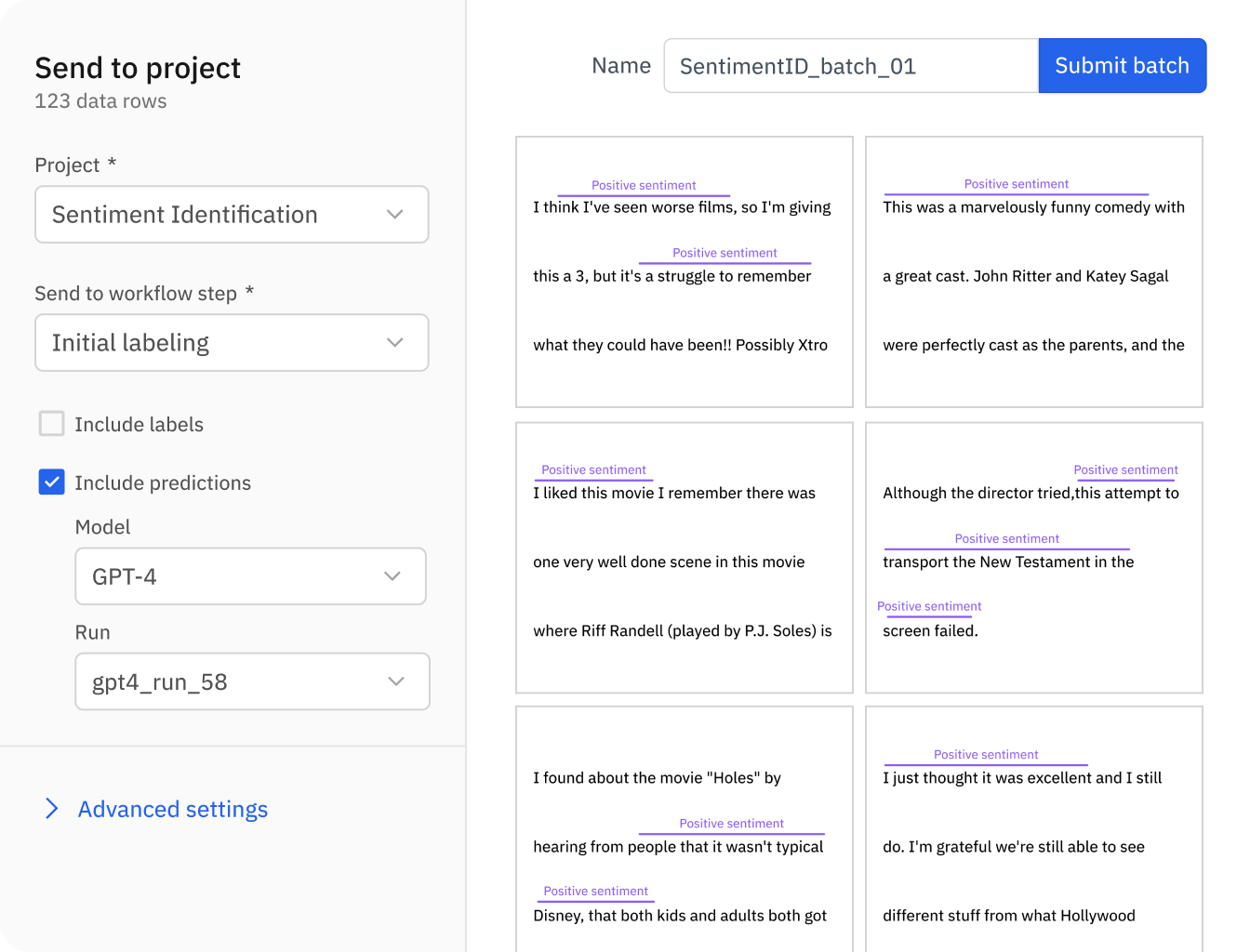
Focus human expertise on where it matters most
The days of manually labeling from scratch are long gone. Foundation models can outperform crowd-sourced labeling on various tasks with high accuracy – allowing you to focus valuable human efforts on critical review. Combine model-assisted labeling using foundation models with human-in-the-loop review to accelerate your labeling operations and build intelligent AI faster than ever.
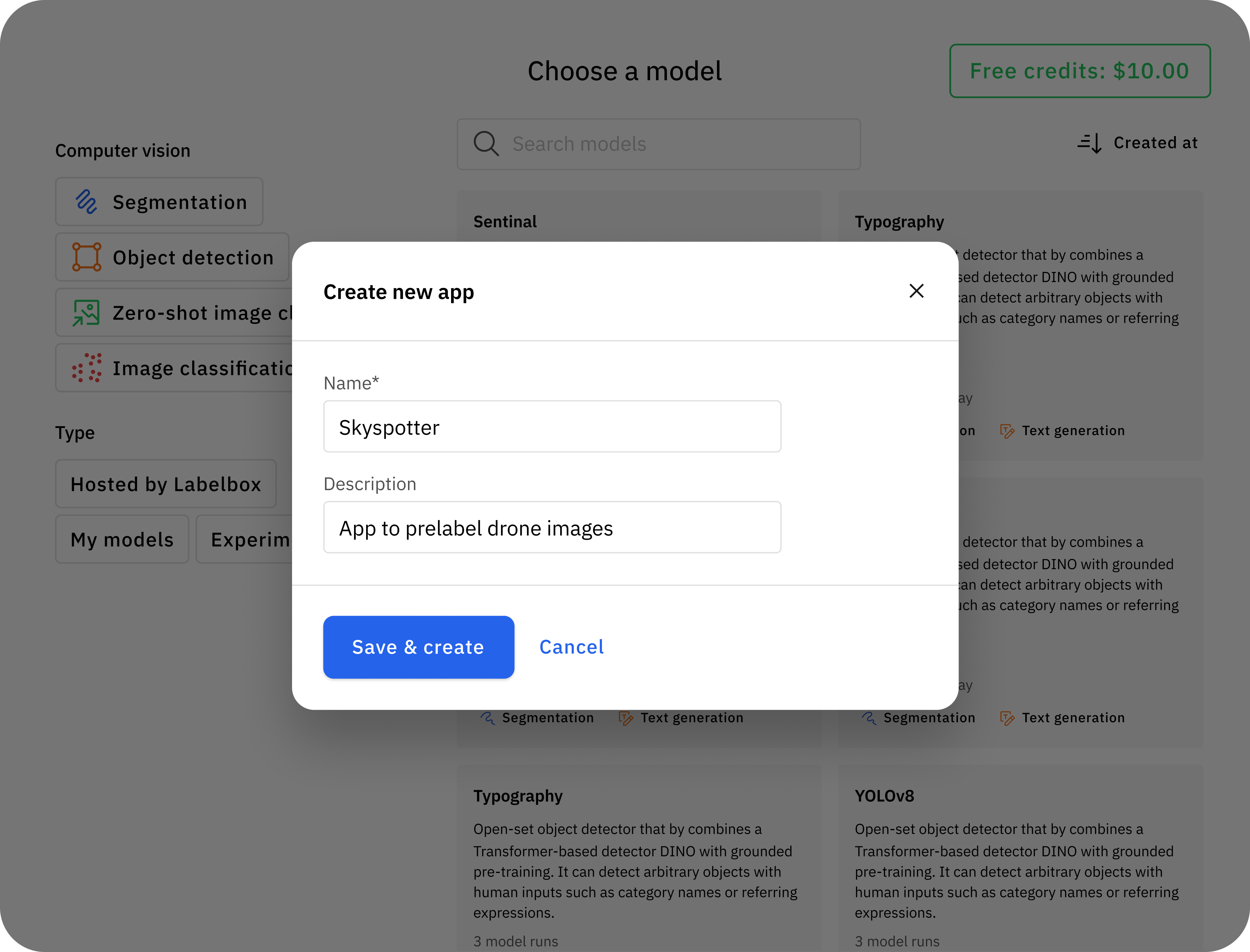
Automate data tasks with Foundry Apps
Create custom Apps with Foundry based on your team’s needs. Deploy a model configuration from Foundry to an App for automated data management or to build custom intelligent applications.
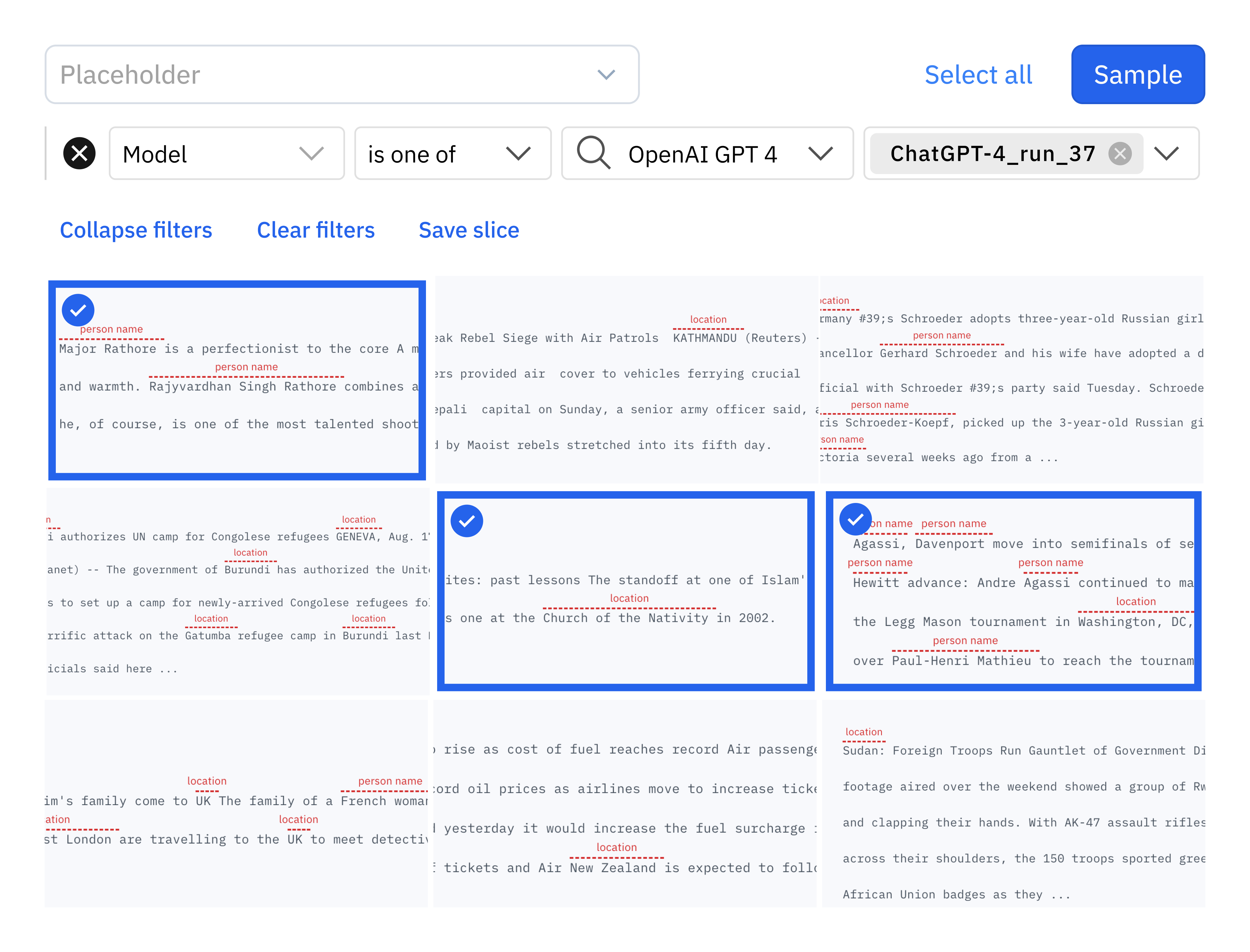
Explore datasets using AI insights
Curate and explore datasets faster than ever. Query your data using predictions generated from the latest and greatest foundation models. Supercharge your data enrichment process and accelerate curation efforts across image and text data modalities.

Accelerate custom model development
Data enriched by Foundry can be used to tailor foundation models to your specific use cases:
Fine-tune leading foundation models: Optimize foundation models for your most valuable AI use cases. Enhance performance for specialized tasks in just days instead of months.
Distill knowledge into smaller models: Elaborate foundation models into lightweight models purpose-built for your applications.
Frequently asked questions
Who gets access to the Model Foundry?
To use Labelbox Foundry, you will need to be a part of our Starter or Enterprise plans. You will be billed monthly for the pass-through compute costs associated with foundation models run on your data in Labelbox.
Learn more about how to upgrade to a pay-as-you-go Starter plan or about our Labelbox Unit pricing.
Contact us to receive more detailed instructions on how to create a Labelbox Starter or Enterprise account or upgrade to our Starter tier.
How is Foundry priced?
Only pay for the models that you want to pre-label or enrich your data with. Foundry pricing will be calculated and billed monthly based on the following:
Inference cost – Labelbox will charge customers for inference costs for all models hosted by Labelbox. Inference costs will be bespoke to each model available in Foundry. The inference price is determined based on vendors or our compute costs – these are published publicly on our website as well as inside the product.
Labelbox's platform cost – each asset with predictions generated by Foundry will accrue LBUs.
Learn more about the pricing of the Foundry add-on for Labelbox Model on our pricing page.
What kind of foundation models are available?
Labelbox Foundry currently supports a variety of tasks for computer vision and natural language processing. This includes powerful open-source and third-party models across text generation, object detection, translation, text classification, image segmentation, and more. For a full list of available models, please visit this page.
How do I get started with Foundry?
If you aren’t currently a Labelbox user or are on our Free plan, you’ll need to:
Create a Labelbox account
Upgrade your account to our Starter plan:
In the Billing tab, locate “Starter” in the All Plans list and select “Switch to Plan.” The credit card on file will only be charged when you exceed your existing free 10,000 LBU.
Upgrades take effect immediately so you'll have access to Foundry right away on the Starter plan. After upgrading, you’ll see the option to activate Foundry for your organization.
Follow the steps below on how to get started generating model predictions with Foundry.
If you are currently a Labelbox customer on our Starter or Enterprise plans, you automatically have the ability to opt-in to using Foundry:
After selecting data in Catalog and hitting “Predict with Foundry,” you’ll be able to select a foundation model and submit a model run to generate predictions. You can learn more about the Foundry workflow and see it in-action in this guide.
When submitting a model run, you’ll see the option to activate Foundry for your organization’s Admins. You’ll need to agree to Labelbox’s Model Foundry add-on service terms and confirm you understand the associated compute fees.
Does Labelbox sell or use customer data via Foundry?
Labelbox does not sell or use customer data in a way other than to provide you the services.
Do the third-party model providers use customer data to train their models?
Labelbox's third-party model providers will not use your data to train their models, as governed by specific 'opt-out' terms between Labelbox and our third-party model providers.
Can I use the closed source models available through Foundry for pre-labeling?
OpenAI: Labelbox believes that you have the right to use OpenAI’s closed-source models (e.g, GPT-4, GPT3.5, etc) for pre-labeling through Foundry if you comply with applicable laws and otherwise follow OpenAI’s usage policies. If you wish to use your own instance of OpenAI, you can do so by setting up a custom model on Foundry.
Anthropic: Labelbox believes that you have the right to use Anthropic’s Claude for pre-labeling through Foundry if you comply with applicable laws and otherwise follow Anthropic’s Acceptable Use Policy. If you wish to use your own instance of Anthropic, you can do so by setting up a custom model on Foundry.
Google: Labelbox believes that you have the right to use Google’s Gemini (or other closed-source models such as Imagen, PalLM, etc.) for pre-labeling through Foundry if you comply with applicable laws and otherwise follow the Gemini API Additional Terms of Service, including without limitation the Generative AI Prohibited Use Policy. If you wish to use your own instance of Google, you can do so by setting up a custom model on Foundry.