
 All guides
All guidesHow to fine-tune Vertex AI LLMs with Labelbox
In machine learning, fine-tuning pre-trained models is a powerful technique that adapts models to new tasks and datasets. Fine-tuning takes a model that has already learned representations on a large dataset, such as a large language model, and leverages prior knowledge to efficiently “teach” the model a new task.
The key benefit of fine-tuning is that it allows you to take advantage of transfer learning. Rather than training a model from scratch, which requires massive datasets and compute resources, you can start with an existing model and specialize it to your use case with much less data and resources. Fine-tuning allows ML teams to efficiently adapt powerful models to new tasks with limited data and compute. It is essential for applying state-of-the-art models to real-world applications of AI.
Vertex AI provides several base models that can be fine-tuned:
- text-bison@001
- code-bison@001
- codechat-bison@001
- chat-bison@001
In this guide, we’ll cover how to leverage Vertex AI and Labelbox to simplify the fine-tuning process, allowing you to rapidly iterate and refine your models’ performance on specific data.
The goal of model fine-tuning is to improve the model’s performance against a specific task. Over other techniques to optimize model output, such as prompt design, fine-tuning can help achieve:
- Higher quality results: Fine-tuning allows the model to learn from a much larger and more diverse dataset than can fit into a prompt. The model can learn more granular patterns and semantics that are relevant to your use case through extensive fine-tuning training. Prompts are limited in how much task-specific context they can provide, while fine-tuning teaches the model your specific domain.
- Token savings: Fine-tuned models require less prompting to produce quality outputs. With fine-tuning, you can leverage a shorter, more general prompt since the model has learned your domain – saving prompt engineering effort and tokens. Whereas highly-specific prompts can often hit token limits.
- Lower latency: Heavily engineered prompts can increase latency as they require more processing. As fine-tuned models are optimized for your specific task, they allow faster inference and can quickly retrieve knowledge for your domain.
Fine-tuning is especially beneficial for adapting models to your specific use case and business needs. There are several common scenarios where fine-tuning really can help models capture the nuances required for an application:
- Style, tone, or format customization: Fine-tuning allows you to adapt models to match the specific style or tone required for a use case, whether it be a particular brand voice or difference in tone for speaking to various audiences.
- Desired output structure: Fine-tuning can teach models to follow a required structure or schema in outputs. For example, you can fine-tune a summarization model to consistently include key facts in a standardized template.
- Handling edge cases: Real-world data often contains irregularities and edge cases. Fine-tuning allows models to learn from a wider array of examples, including rare cases. You can fine-tune the model on new data samples so that it learns to handle edge cases when deployed to production.
In short, fine-tuning allows teams to efficiently adapt powerful models to new tasks and datasets, allowing ML teams to customize general models to their specific use cases and business needs through extensive training on curated data. High-quality fine-tuning datasets are crucial to improve performance by teaching models the nuances and complexity of the target domain more extensively than possible through prompts alone.
How to use Labelbox for fine-tuning
Labelbox is a data-centric AI platform for building intelligent applications. With a suite of powerful data curation, labeling, and model evaluation tools, the platform is built to help continuously improve and iterate on model performance. We will use the Labelbox platform to create a high-quality fine-tuning dataset.
With Labelbox, you can prepare a dataset of prompts and responses to fine-tune large language models (LLMs). Labelbox supports dataset creation for a variety of fine-tuning tasks including summarization, classification, question-answering, and generation.
Step 1: Evaluate how a model performs against the desired task
Step 2: Create an LLM data generation dataset in Labelbox
When you set up an LLM data generation project in Labelbox, you will be prompted to specify how you will be using the editor. You have three choices for specifying your LLM data generation workflow:
Workflow 1: Humans generate prompts and responses
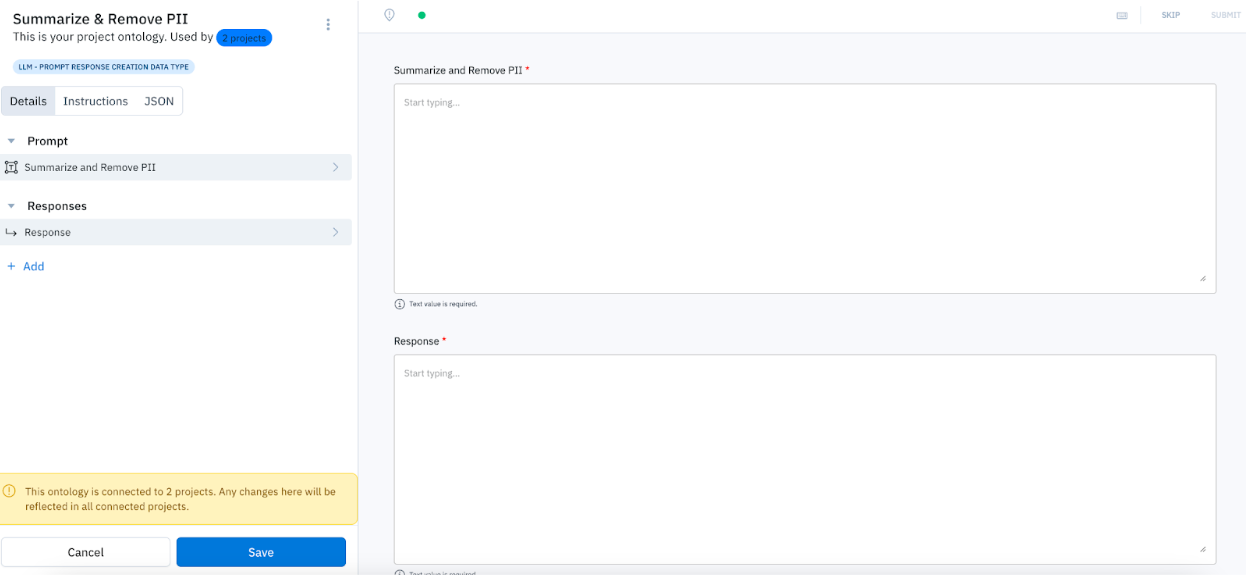
In the editor, the prompt and response fields will be required. This will indicate to your team that they should create a prompt and response from scratch.
Workflow 2: Humans generate prompts
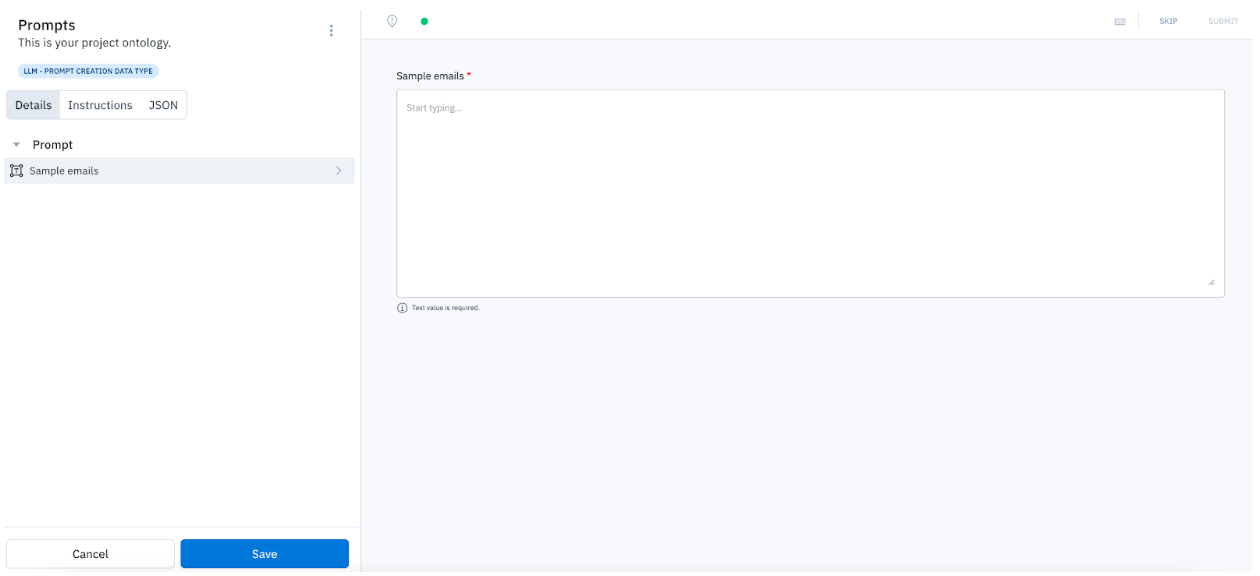
In the editor, only the prompt field will be required. This will indicate to your team that they should create a prompt from scratch.
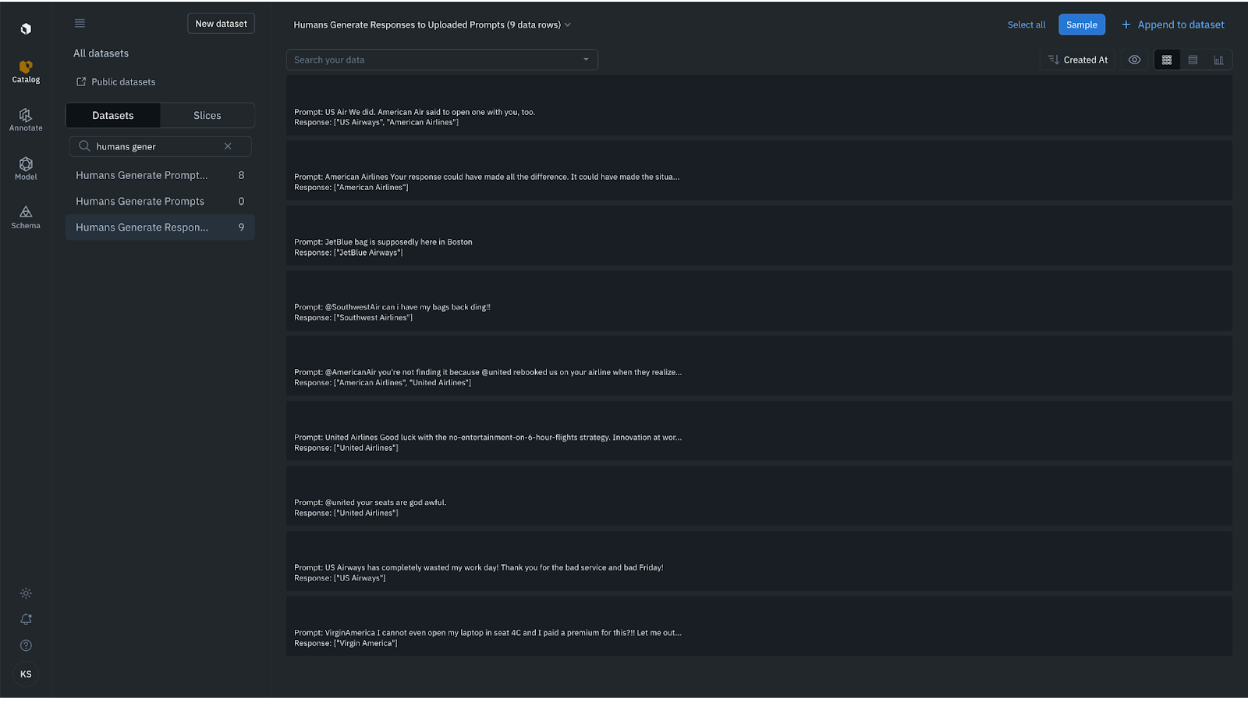
Workflow 3: Humans generate responses to uploaded prompts
In the editor, a previously uploaded prompt will appear. Your team will need to create responses for that prompt.
For our project, we'll want to create a "Humans generate responses to uploaded prompts" project. Namely, we want humans to create responses in the form of a list of airlines.
Step 3: Upload data to Vertex AI
Export the Labelbox fine-tuning dataset
Once you’ve constructed a fine-tuning dataset with Labelbox, you can export it using our Labelbox to Vertex AI conversion script.
Start a model tuning job using Vertex AI & deploy the model
After exporting the fine-tuned dataset, start a model tuning job using Vertex. When a fine-tuning job is run, the model learns additional parameters that help it encode the necessary information to perform the desired behavior or learn the desired behavior.
The output of the tuning job is a new model, which is effectively a combination of the newly learned parameters and the original model. Once the fine-tuning job is complete, you can deploy the model and return to Labelbox for model evaluation.
Step 4: Evaluate and iterate on fine-tuning dataset quality
A well-performing fine-tuned model indicates the effective optimization of model architecture, training data, and hyperparameters. It signifies that the training dataset used for fine-tuning is high-quality and is representative of the real-world use case. This allows for the fine-tuned model to achieve better performance on tasks compared to the base model in less time than it would have to train a model from scratch.
Real-world conditions and data are often dynamic. As the use case evolves, it's crucial to maintain representativeness and relevance in the fine-tuning data. Continuous evaluation of the fine-tuned model’s performance can help detect edge cases or model errors. You can evaluate model performance and debug errors leveraging Labelbox Model. Utilize interactive auto-populated model metrics, such as a confusion matrix, precision, recall, F1 score, and more to surface model errors. Detect and visualize corner-cases where the model is underperforming and generate high-impact data to drastically improve model performance. After running error analysis, you can make more informed decisions on how to iterate and improve your model’s performance with corrective action or targeted data selection.
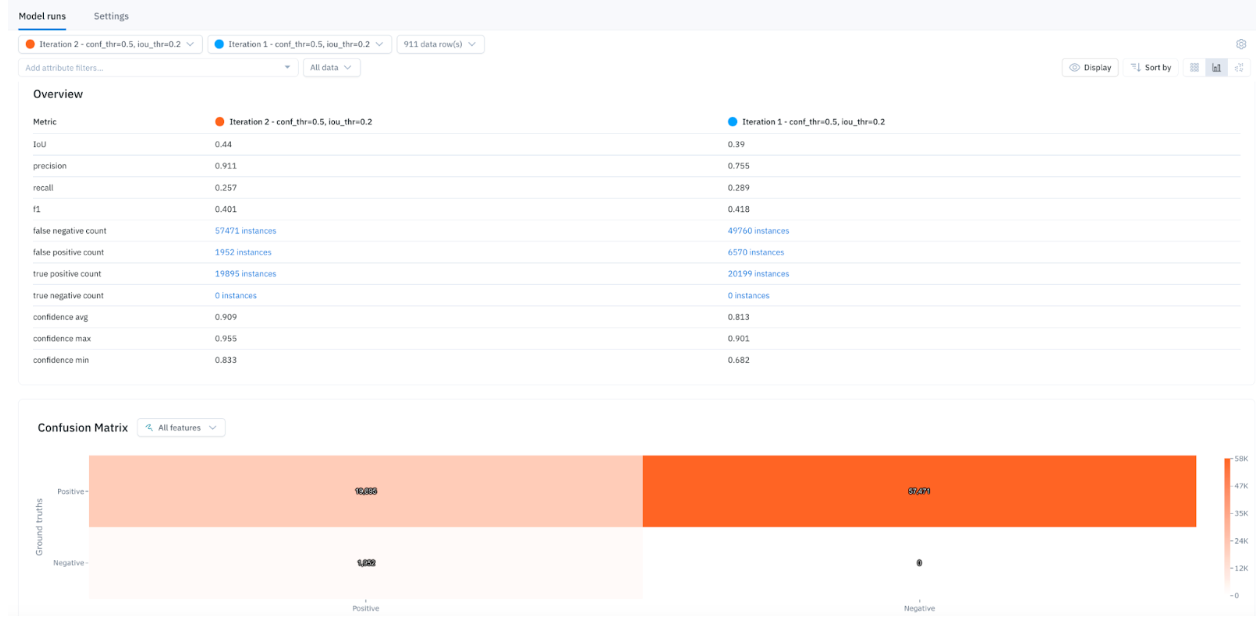
By iteratively identifying gaps and outdated samples in the fine-tuning data, then generating fresh high-quality data, model accuracy can be maintained over time. Updating fine-tuning datasets through this circular feedback process is crucial for adapting to new concepts and keeping models performing at a high level within continuously changing environments.
To improve LLM performance, Labelbox simplifies the process for subject matter experts to generate high-quality datasets for fine-tuning with leading model providers and tools, like Google Vertex AI.
Unlock the full potential of large language models with Labelbox’s end-to-end platform and a new suite of LLM tools to generate high-quality training data and optimize LLMs for your most valuable AI use cases. To get started, sign up for a free Labelbox account or request a demo.


