
 All blog posts
All blog postsLabelbox•April 17, 2024
Seamless LLM human evaluation with LangSmith and Labelbox
As businesses increasingly integrate large language models (LLMs) and generative AI applications into their workflows, maintaining customer trust and safety has become a significant challenge due to unexpected and inappropriate behaviors from chatbots and virtual agents.
While automated benchmarks offer a starting point for evaluating LLM performance, they often struggle to capture the intricacies of real-world scenarios, particularly in specialized domains. Human evaluation and feedback, while an essential source of data for supervised fine-tuning, can be difficult to get started and operationalize.
To guarantee effective evaluation, it is crucial to utilize a combination of human evaluation and automated techniques, ensuring a customer’s experience booking their next airplane ticket or requesting a refund for an incorrect meal delivery (or reporting fraudulent credit card activity) doesn’t devolve to toxic conversation or product hallucinations. This is becoming increasingly important as chatbots and conversational agents become the primary interface between users and companies.
Consequently, hybrid evaluation systems are gaining recognition for their reliability in ground-truth analysis as well as robustness in assessing an LLM's capabilities in production environments.
How can companies face the challenge of efficiently scaling their human evaluation processes to uphold the quality and safety of their AI-powered interactions without straining their operations teams?
LangSmith and Labelbox are tackling this growing problem by offering enterprise-grade LLM monitoring, human evaluation, labeling, and workforce services.
Production-grade LLM monitoring, human evaluation, labeling, and workforce services together
LangSmith & LangChain
LangSmith is a unified developer platform for building, testing, and monitoring LLM applications. With LangSmith, companies can harness the power of LLMs to build context-aware reasoning applications, ready for the enterprise. LangSmith users enjoy the revenue acceleration and productivity savings LLM applications promise without suffering the risks, costs, and team inefficiencies that working with non-deterministic models can bring.
LangSmith offers teams the ability to:
- Develop and Debug: Get visibility into what your agent or chain is doing and what context is being provided to the prompts.
- Manage Datasets: Centralize management of datasets for testing and fine-tuning.
- Evaluate and Test: Layer in human feedback on runs or use automatic evaluation.
- Discover and Collaborate: Explore, adapt, and version prompts with your team.
- Monitor: See what’s happening in production and take action when needed.
- Experiment: Test different prompts and models in a playground until you’re happy with your results.
LangSmith works seamlessly with LangChain, the most popular framework for building LLM-powered applications, but also helps you accelerate your development lifecycle whether you’re building with LangChain or not.
Labelbox
Labelbox offers a data-centric AI platform for optimizing data labeling and supervision to enhance model performance. The labeling, curation, human evaluation and orchestration of workflows is crucial to the development of high-performing, reliable generative generative AI applications in two key ways:
- Unlocking new, multimodal unstructured data (such as text, images, video, audio, etc) for model distillation, fine-tuning (and even pre-training) of generative models (LLMs, Large Vision Models, Large Multimodal Models). The invaluable data isn’t the same, web crawled Wikipedia data everyone has access to (including your competitors). The first-party, curated, domain specific data in your BigQuery data warehouse simply needs a label to become machine learning data.
- Enhancing the quality and performance of generative AI models through an iterative process of auto-eval, human review, and incorporating both forms of feedback into model optimization for RLHF. Reviewing the output of a chat log as part of a hybrid, continuous monitoring and evaluation system, for example, can pinpoint potential quality issues as they arise, create additional data for future fine-tuning (both of labeling and end-application models) as well as enrich data fed and chunked into RAG systems.
Labelbox addresses these core capabilities of performant, generative AI data engineers with a customizable native labeling editor, built-in workflows for both model-assisted labeling and human-labeling workflows, as well as a human labeling & evaluation workforce of subject matter experts.
The Labelbox platform includes:
- Annotate: Use the same platform for human and AI-assisted labeling and evaluation, for data modalities including text, documents, audio, as well as images and video.
- Catalog: Explore your raw data (text, image, video, etc), metadata, embeddings, and ground truth labels stored in the same place. Offering vector & traditional search, data exploration, and curation.
- Model: Batch and pre-label your data using foundation models. Preview generated labels and fine-tune models to optimize labeling and evaluation operations.
- Boost: Outsource, expand, and scale human-evaluation through our workforce services.
Improving LLM quality through robust monitoring, evaluation and data enrichment services
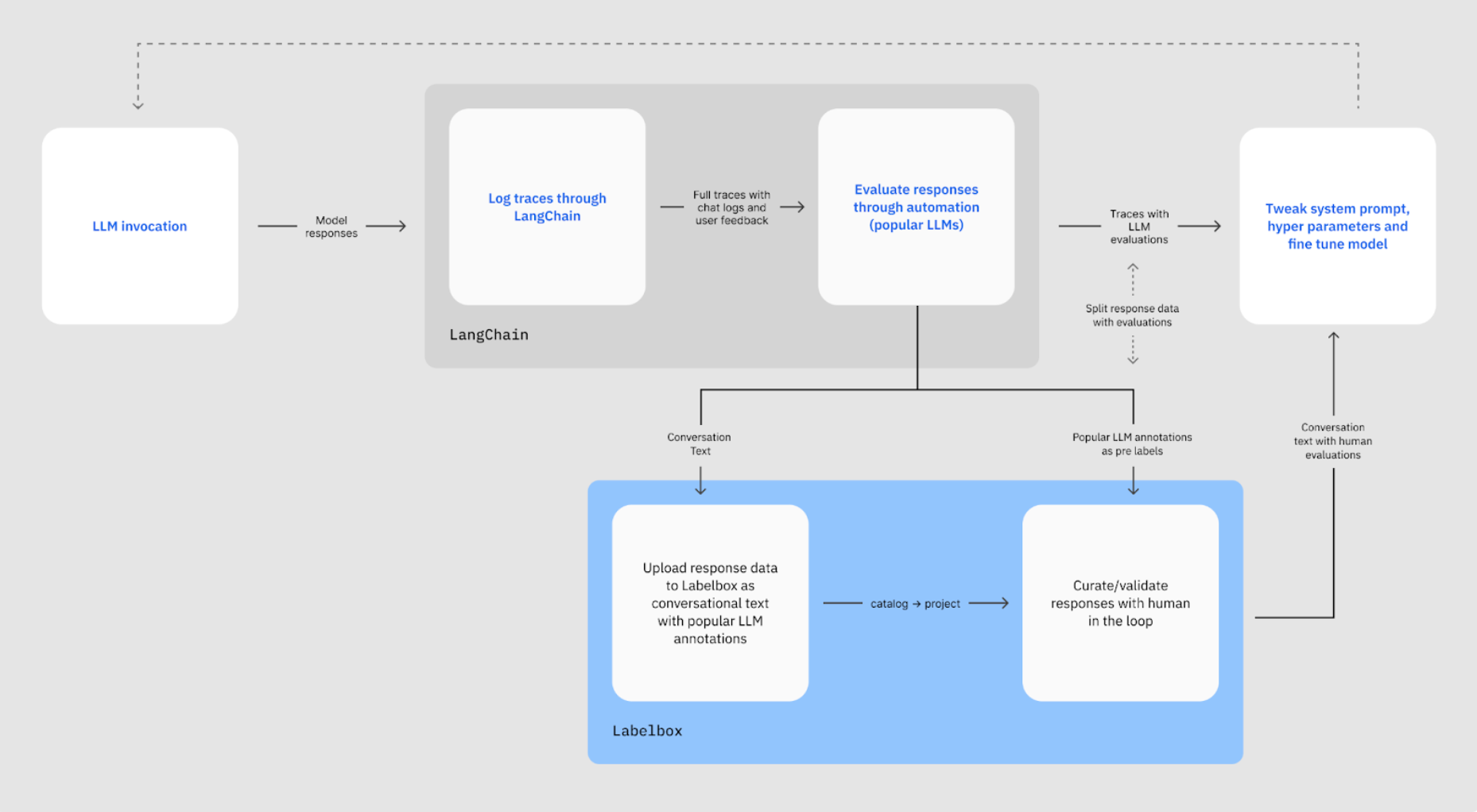
Event logging is a prerequisite for conducting human and model-based evaluation. LangSmith logs event sequences, presenting them in a user-friendly manner with an interactive playground for prompt iteration. Labelbox provides a labeling and review interface, as well as an SDK to automate the process, eliminating obstacles in data viewing and labeling.
While automated evaluation using LLMs shows promise, it is essential to ensure the model aligns with human evaluators. Gathering feedback from labelers and refining the evaluator model through prompt engineering or fine-tuning can help achieve this alignment. Regular checks to monitor the agreement between the model and human evaluators are also necessary.
LLMs can be employed to expedite the development of an evaluation system by generating test cases, synthetic data, and critiquing and labeling data. The evaluation infrastructure can then be repurposed for debugging and fine-tuning.
Common production use cases for LangSmith and Labelbox include:
1. Creating safe & responsible chatbots: Enhance chatbot development, concentrate on categorizing conversation intents for subsequent fine-tuning of LLMs, and ensure chatbot performance aligns with human preferences through high-quality, relevant training data.
2. Improving RAG agent performance: Boost the performance of RAG-based agents by refining reranking models and preprocessing documents for increased relevance, leveraging human-in-the-loop and semi-supervised techniques.
3. Accelerated multimodal workflows: Develop and refine agents capable of handling complex multimodal interactions, processing and understanding various data types—text, images, and more—to perform nuanced analysis.
How to get started
Interested in learning more about how to start implementing a hybrid evaluation system for your production generative AI applications?
Check out our guide on how to turn LangChain logs into conversational data with Labelbox.
Reach out to the Labelbox sales team and join our community to stay informed about upcoming tutorials and resources.


