Covering everything you need to know in order to build AI products faster.
Labelbox•May 5, 2022
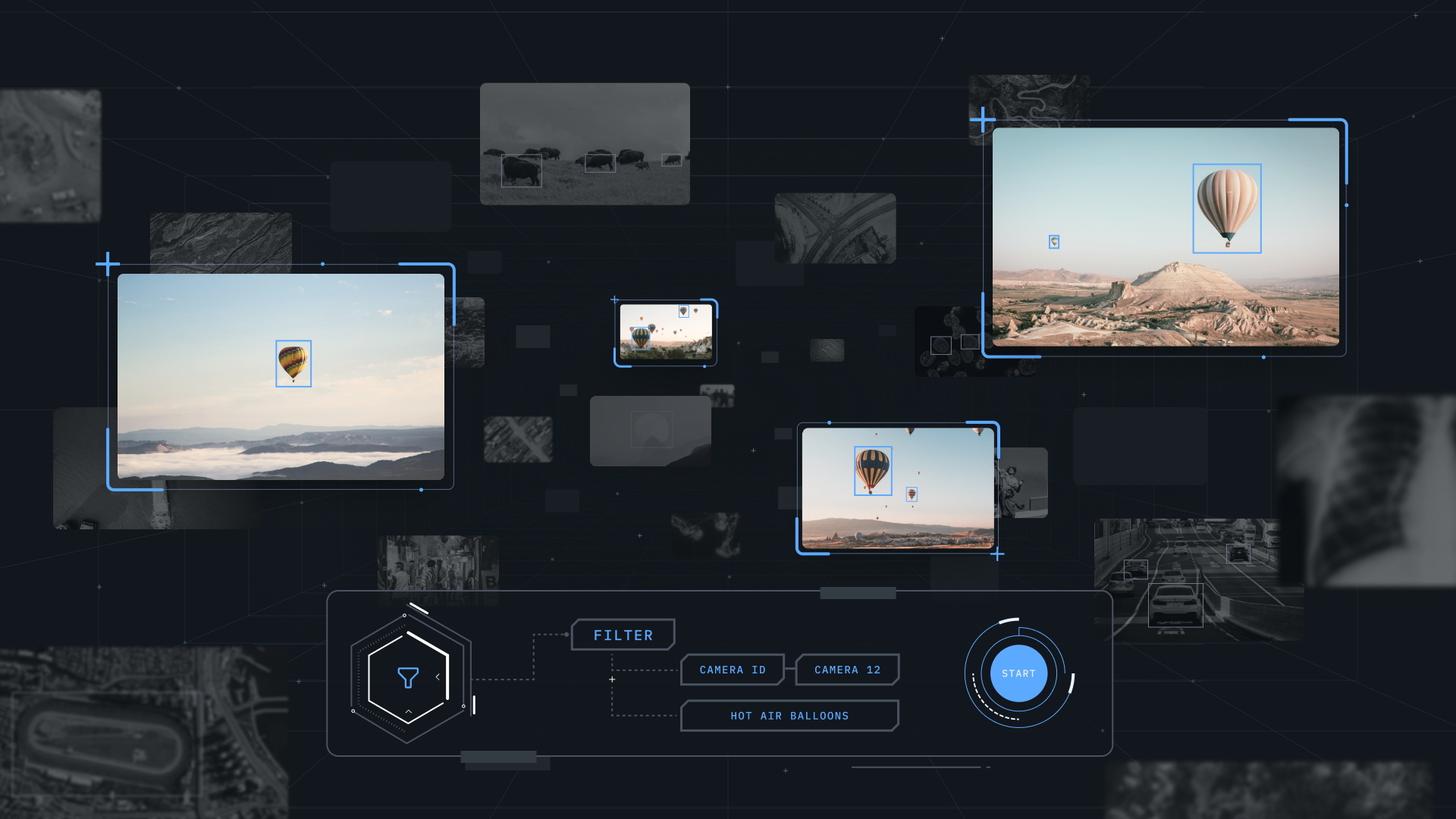
Catalog: The launchpad for unstructured data management
Labelbox built Catalog, a unifying layer across your ML data, to tackle managing massive unstructured datasets, visualizing and exploring data, and curating efficient batches of high-value data.
Labelbox•April 26, 2022
6 fundamental sessions on improving your AI data
Join us at Labelbox Blueprint on May 18th - A virtual event covering six fundamental sessions to improve your AI data
Labelbox•April 21, 2022
Streamlined data management and key editor improvements
We've focused recent product development on streamlining essential data management workflows and are introducing new collaboration tools for labeling operations and labeling teams. We’ve also made some key updates to our Editors that enable more complex ML use cases and improve usability.
Labelbox•March 24, 2022
March updates
We’ve focused recent product development on improvements to Catalog, the ability to filter data rows by status, updates to our account usage page, and more.
Labelbox•March 11, 2022
How to use vector embeddings to create high-quality training data
Functions and embeddings are a powerful way to quickly search and explore your unlabeled and labeled data. Using them can help you break down silos across datasets so you can focus on curating and labeling the data that will most significantly improve model performance.
Labelbox•January 20, 2022
How to improve model performance with less data
This data-centric ML method can reduce the required amount of training data by 10% to 50%.
Labelbox•November 10, 2021
Stop labeling data blindly
ML teams need to know "what data will improve model performance fastest?" These best practices will help teams identify model errors and prioritize better data.
Labelbox•October 29, 2021
You’re probably doing data discovery wrong
Learn best practices for storing, evaluating, and visualizing labeled and unlabeled data so you can accelerate your model iteration cycles and simplify your training data pipeline.