
 All guides
All guidesWhat is Human-in-the-Loop?
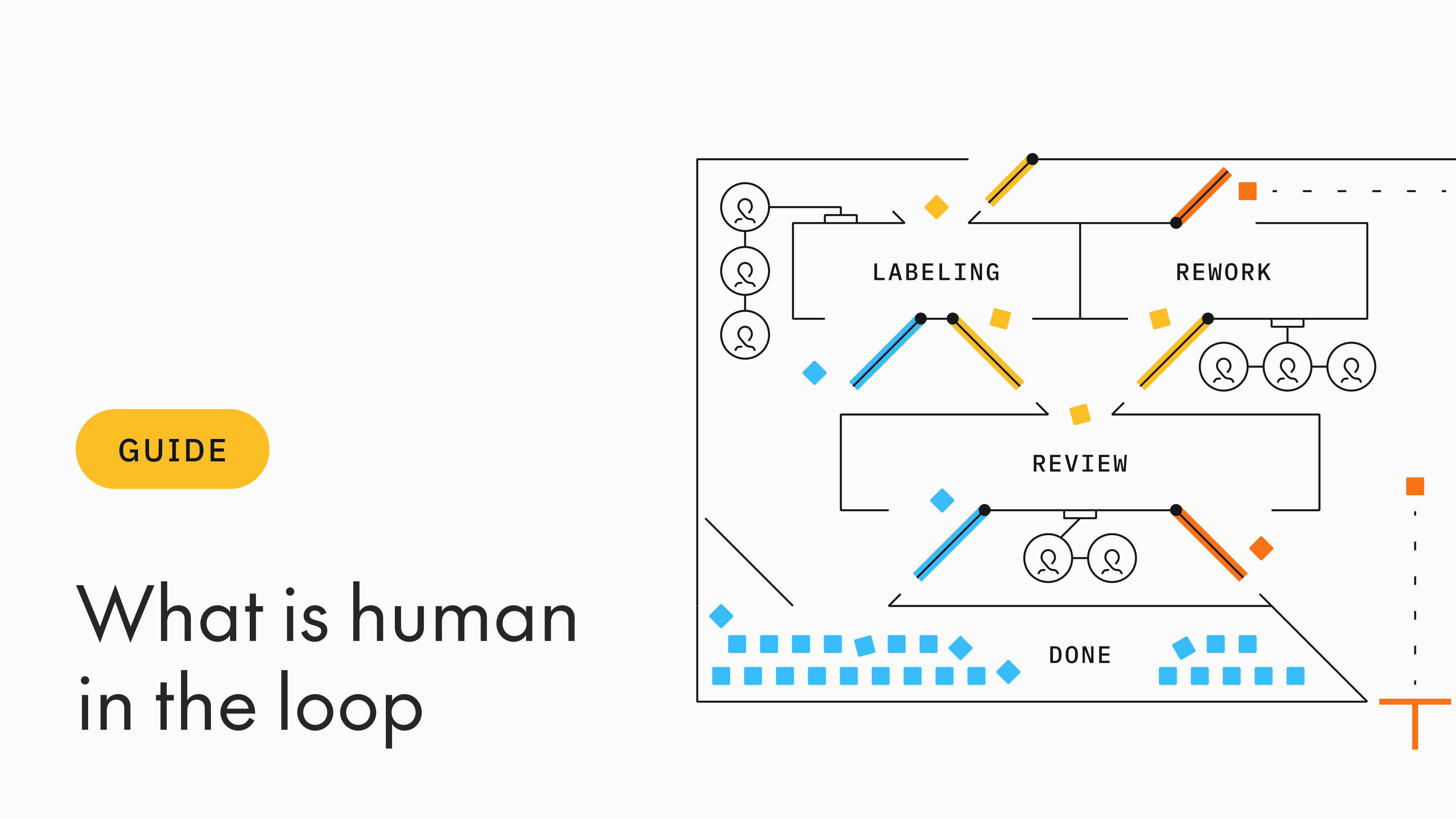
Every time a new AI tool is rolled out, the topic ultimately shifts to: Will AI replace humans? A satisfying answer to this question is given by the title of a report by Harvard Business Review: “AI Won’t Replace Humans — But Humans With AI Will Replace Humans Without AI”. It summarizes how AI is nothing without the intervention of humans.
In one way or another, humans are involved in developing AI models, integrating natural human intelligence at various points of the machine-learning loop, resulting in more human-like AI systems that exhibit helpfulness, empathy, ethics, and reason.
Human-in-the-loop is a fundamental concept in reinforcement learning in the RLHF process. Human evaluators and annotators are introduced into the model training cycle to prepare datasets (preference pairs), monitor performance, and annotate feedback. Although that is just a single use case; human-in-the-loop goes beyond dataset preparation.
In this article, we break down human-in-the-loop as an AI model training concept, explaining what it entails, its bottlenecks, and how we can overcome such challenges.
Understanding the concept of humans-in-the-loop

In the context of AI and machine learning (ML) models, human-in-the-loop is an autonomous system that allows humans to give direct feedback to the model, refining it further. Human-in-the-loop is a system of continuous processes where various “humans,” such as data annotators and evaluators, data scientists, QAs, and engineers, interact with the model differently to guide it. In this context, a human refers to any person participating in the algorithmic decision-making and steering the model toward human-like performance.
Unlike monolithic model training approaches, where AI systems are built, tested, and rolled out without further modifications, human-in-the-loop ensures we keep a close eye on the model and guide it appropriately. In doing so, we beat the risk of obsolescence, scaling constraints, and model degradation, which are common challenges in fully automated model training workflows. Introducing human agents rather than end-to-end automation of the machine learning process guarantees accurate, fast, and human-like AI systems.
Human-in-the-loop combines human interventions with machine learning algorithms, the goal being to achieve what these two cannot achieve by themselves. In most cases, human-in-the-loop is implemented using either supervised or unsupervised learning methodologies.
- In supervised learning, human agents prepare input objects and desired output values to train the model.
- Conversely, the unlabelled dataset is fed into the algorithm in unsupervised learning, leaving the model to learn independently.
Human-in-the-loop also blends different machine learning approaches, such as active learning, interactive learning, and machine teaching. During training, humans and machines take turns controlling the learning process. Depending on who is in control at a particular time, the machine learning approaches mentioned above come into play differently in the light of HITL.
Active learning
In active learning, the system is in control. It interactively queries humans to label the data points used in training. Therefore, humans are merely introduced into the training loops as annotators of the unlabeled data, and their interaction with the model is limited to that.
Interactive machine learning
In this approach, the role of human-in-the-loop transcends just data labeling. As its name suggests, interactive machine learning involves a closer interaction between the learning system and the human agents (trainers, annotators, and evaluators). These human agents interact with the models in natural language that the model can observe and imitate. In this case, the human agents supply the model with information that supports learning in a more focused, frequent, and incremental manner.
Machine teaching
Machine teaching is the opposite of active learning. In this context, the human agent, usually a domain expert, controls the learning process. Through transfer learning, this knowledge expert guides the model in a contextually specific manner. This way, the model learns better and faster than on labeled training data.
The underlying working principle of human-in-the-loop is that humans should intervene when a machine can't solve a problem, telling them what to do and how to do it. Also, automatable training episodes should be left for the machine but under human supervision to ensure faster and more accurate learning. Combining ML algorithms with human intervention creates a continuous feedback loop that iteratively helps the AI models learn better and faster each time.
What are the benefits of human-in-the-loop?
Most foundational models trained on large-scale data lack context-specificity, accuracy, and human preferences. These shortcomings are easily remedied by adding human-in-the-loop to the process. Other human-in-the-loop benefits in training performant AI models include:
Improving dataset quality and model accuracy
Introducing human agents in various model training instances, especially in dataset preparation, creates a ripple effect on the quality of the model attained at the end of the ML pipeline, as each instance of human intervention is considered additional training.
Human-in-the-loop helps generate accurate custom datasets that can be used to improve the quality of the model's output incrementally. For instance, when building a sentimental analysis AI solution, the algorithm might not understand non-direct language elements like context, cultural lingo, and multilingual texts. Humans, therefore, step in to guide the model in learning some of these elements that cannot be captured in the dataset. In helping improve the utility and accuracy of the datasets, human-in-the-loop guarantees accurate models that align with human values and preferences.
Reducing errors and biases
Errors and biases will always happen in the model training process, whether in the training data or the model’s output. Thus, the goal is to reduce the frequency of such errors and biases. Human agents can always spot the mistakes, skewness, and blank spots in the training data that the algorithm cannot uncover. When the model makes assumptions and generates misleading outputs, in the case of AI hallucination, human agents are always on standby to troubleshoot and rectify such errors.
During training, the data preprocessing phase focuses more on data qualities like size and relevance, ignoring possible biases. Besides, historical data used in model training will likely contain hidden biases that the algorithm might ignore. Adding humans into the loop helps identify such biases as soon as they manifest and eliminate them as early as possible to avoid misleading the model.
Challenges when implementing human-in-the-loop
While there are many benefits in introducing humans into the model training process, there are also challenges that come with it. For example, scalability and cost emerge as the two most profound challenges confronting humans-in-the-loop systems.
Scalability
Combining humans with automatable systems usually slows down the model training process. A notable setback of most human-in-the-loop systems is that they are often not scalable. Human resources constraints and performance limitations are some of the factors reducing human-in-the-loop systems' scalability. These systems require more and more human resources as the task complexity and the training data volume increase. The need for human agents like annotators, trainers, and QA often becomes a bottleneck to scalability efforts.
Also, as the number of humans involved in the model training increases, coordinating their efforts efficiently becomes challenging. Having many people interact differently with the model during training increases the chances of errors and generally slows the training process.
However, there are ways to eliminate the scalability challenges in human-in-the-loop systems. One way to do so is by enhancing machine learning algorithms used in model training. A common technique involves using an interpretable machine learning algorithm that provides a high-level training data summary.
Such algorithms handle more tasks independently, reducing the frequency of human intervention. Routine tasks performed by human agents can be automated to overcome scalability issues. An example of such a solution is reinforcement learning from AI feedback (RLAIF), which involves training LLMs using rewards provided by a preference model as guided by an AI feedback agent.
Cost
Additional cost is incurred whenever there is a need to increase resource input in the training process. Cost implications as challenges of human-in-the-loop systems often impede the training process. The more humans are in the training loop, the more we have to spend on wages and costs accrued from longer training.
Any workaround eliminating the frequency of human agents in the training lifecycle saves on cost. Algorithm enhancement and automation of routine tasks already mentioned also come in handy in eliminating the cost-related challenges of human-in-the-loop.
Final thoughts on human-in-the-loop
Human-in-the-loop emerges as the additive of human touch and feel to AI. Most AI solutions we appreciate today were trained and tested by humans at some point. As the panic of 'AI is taking over' grows, it is important to note that human expertise remains indispensable in AI. Despite increased automation, data annotation and feedback modeling still require human-in-the-loop systems, making it an indispensable element in the AI model training lifecycle.
Labelbox facilitates human-in-the-loop workflows for machine learning by providing tools for data annotation, quality control, active learning, iterative improvement, and integration with automation. Try it for free today.