×![]()

 All blog posts
All blog postsLabelbox•August 25, 2022
Accelerate AI development and search for more granular data with new features

We’ve focused recent product development on a host of improvements to help drive greater insight and productivity across annotation, data curation, and model training workflows. You can now improve the quality of annotations with updates such as message-based classification and pixel-level coordinate support, search for data faster than ever with custom metadata and powerful new queries, configure and track model hyperparameters, and more.
Annotate
Classify or tag specific messages within a conversation
Our conversational text editor now supports message-based classifications for training conversational AI to power more tailored experiences.
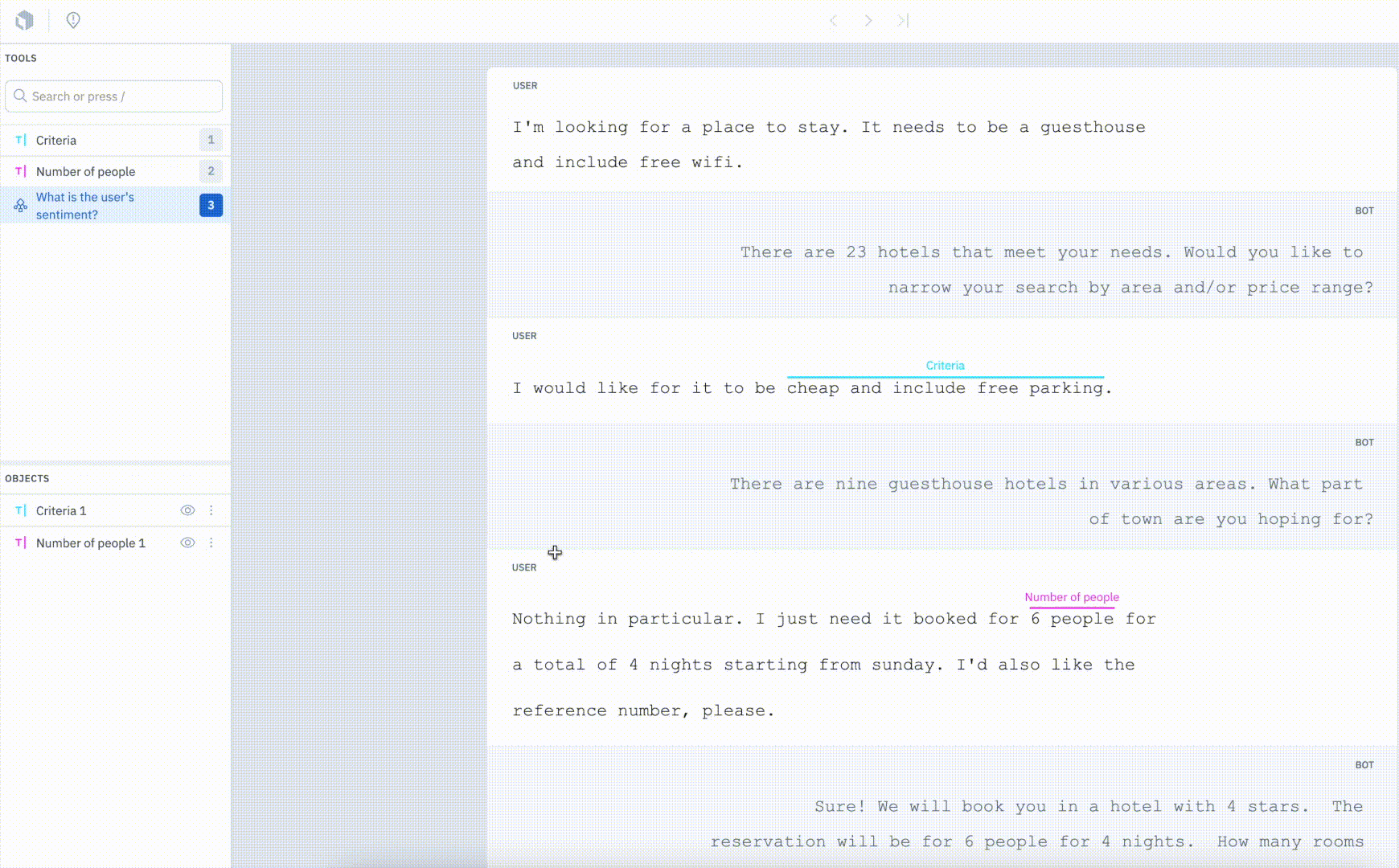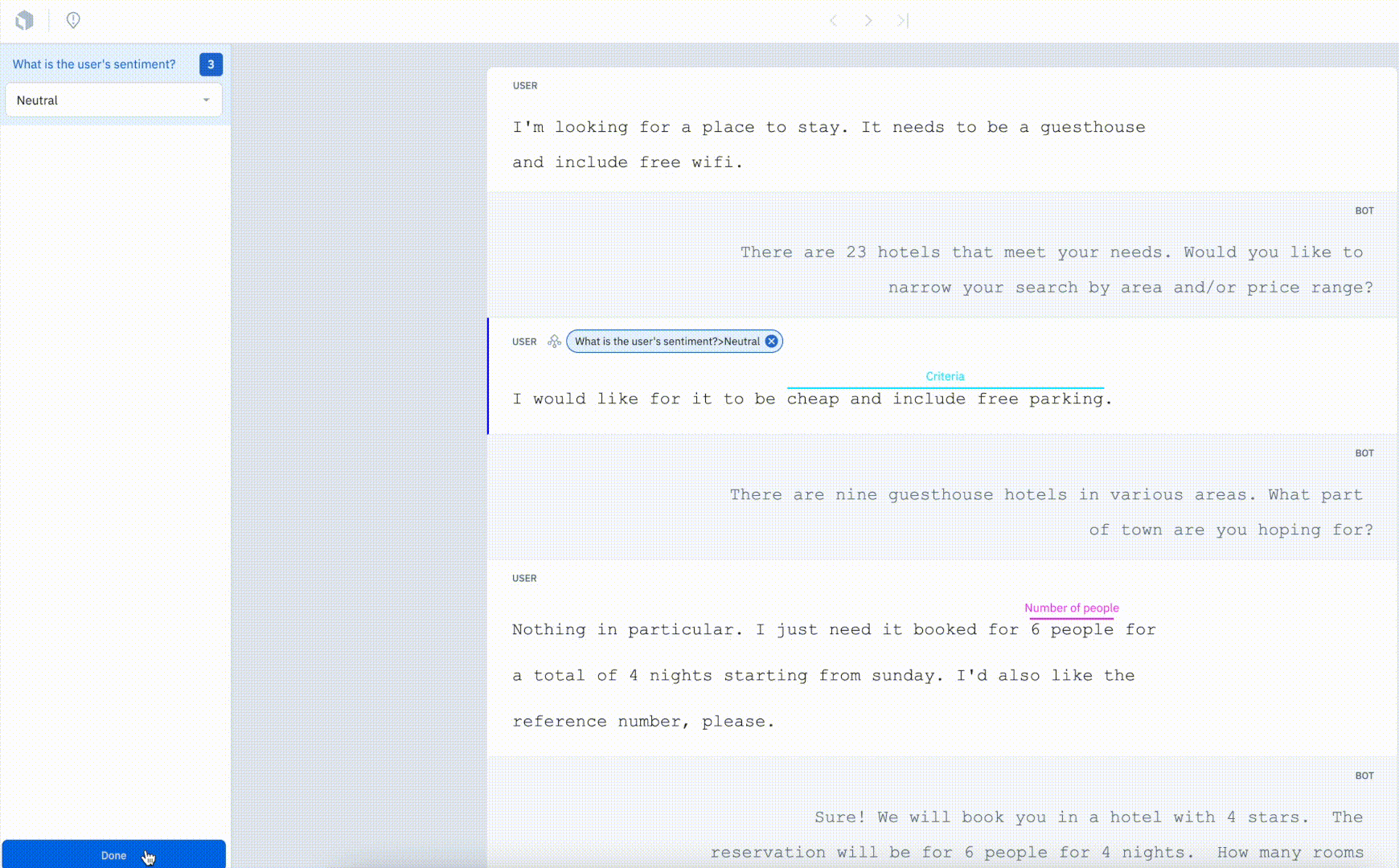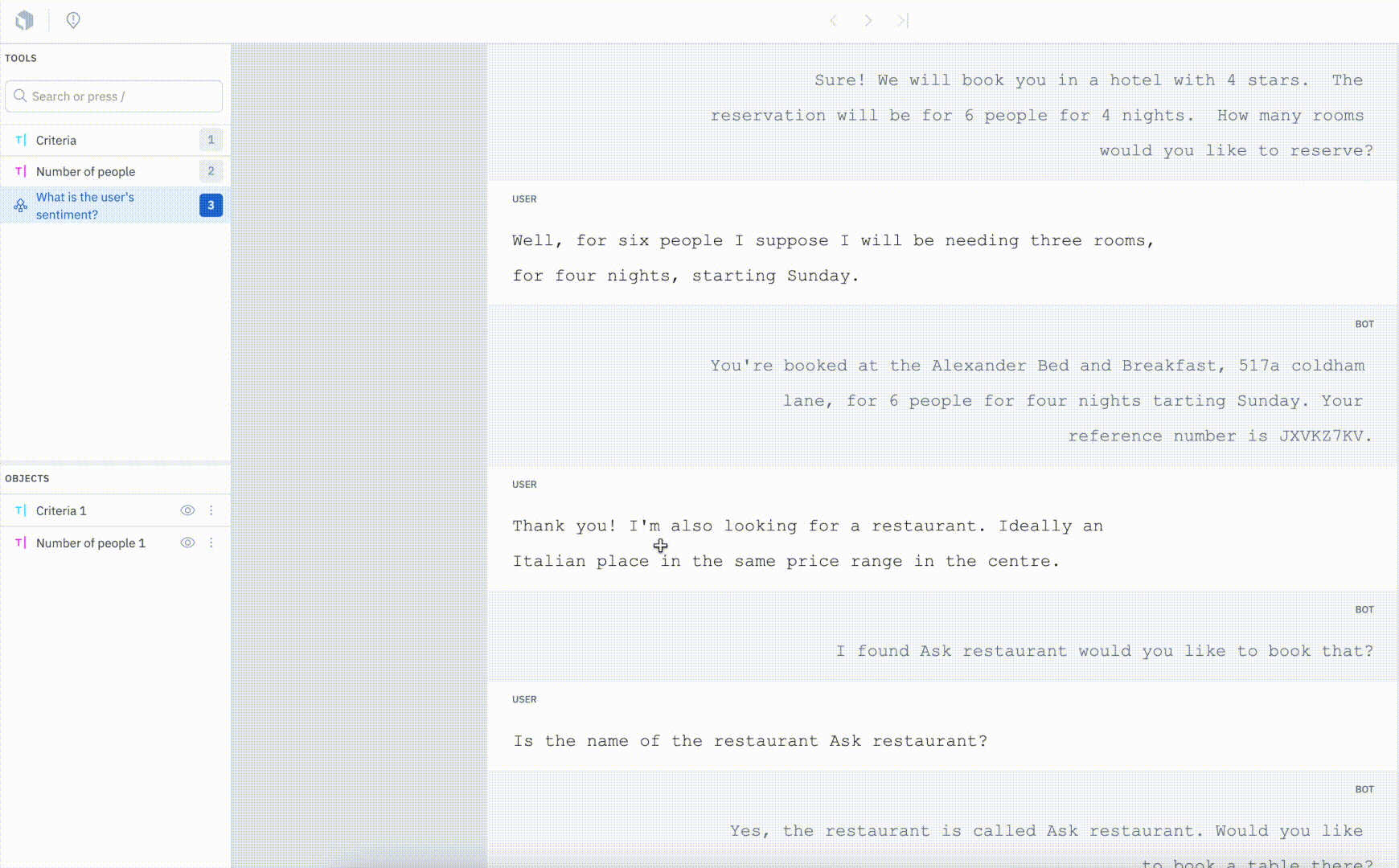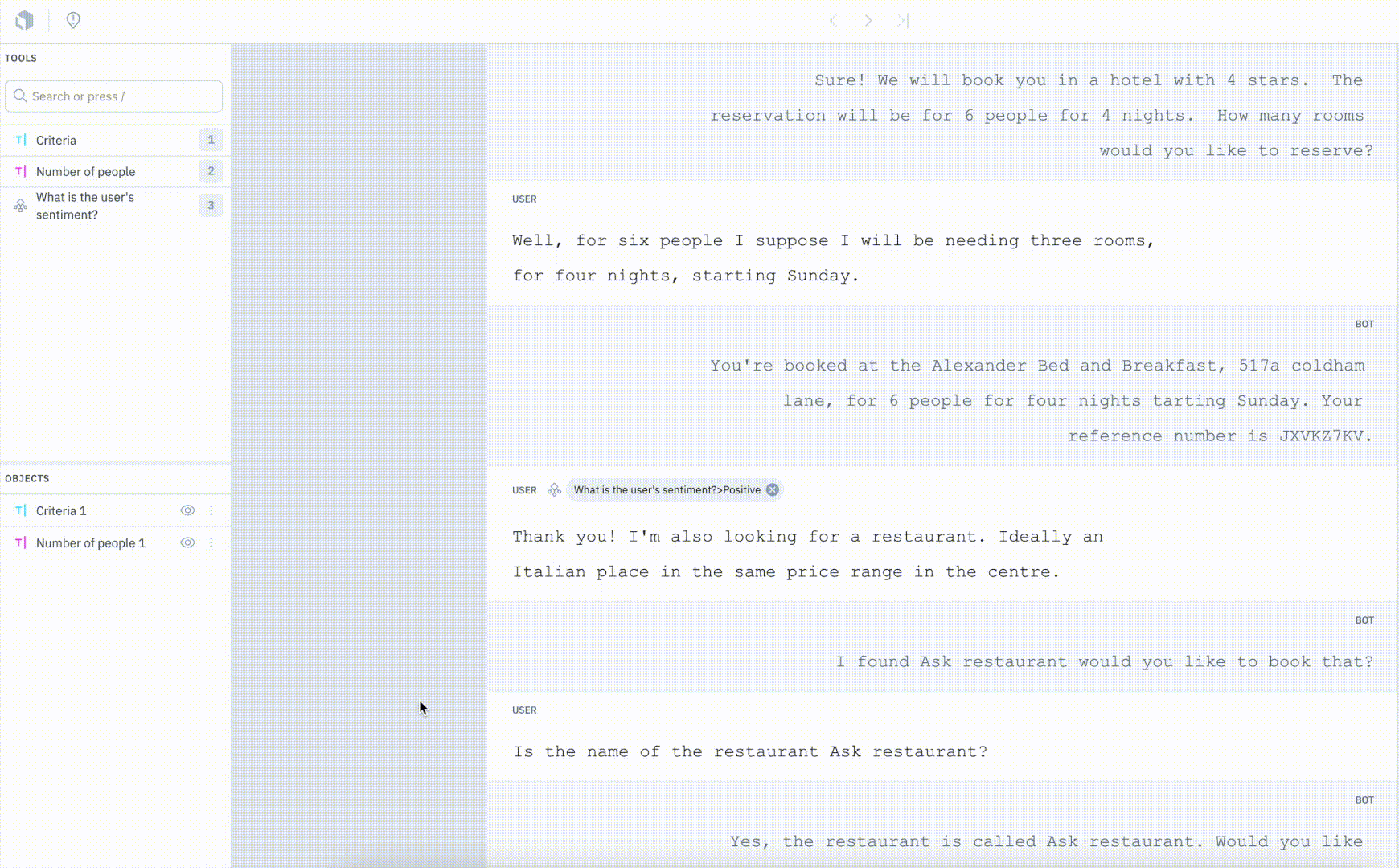
In addition to being able to create entities and annotation relationships, users can now tag a message within the context of a conversation to classify intent or sentiment. The ability to classify specific messages within the context of a conversation can help unlock granularity and provide greater insight. Message-based classification can be advantageous for use cases such as sentiment analysis or intent mapping for chat bots.
Our conversational text editor is currently available in beta. Learn more about message-based classifications and our conversational text editor in our documentation.
Go easy on the eyes with dark mode
We’re excited to announce that dark mode is now available for all users.

As a highly requested feature, dark mode will allow teams to label for longer with less eye strain and fatigue. When selected, dark mode will persist across the entire platform, including all of our editors.
Zoom in on the details with pixel-level coordinate support
We recently added Cartesian coordinate support for our tiled imagery editor. This feature will enable teams to work with larger images for greater detail and context.
Cartesian coordinate support relies on x and y pixel coordinates, rather than geographic longitude and latitude coordinates. Teams working with geospatial data can now receive pixel coordinates of their tiled imagery, independent of a coordinate system. Teams who are annotating non-geospatial tiled imagery, such as pathology or other large-scale images, can now receive annotations on the source image pixels of the full image.
Learn more about Cartesian coordinate support in our documentation.
Better performance and improved support for up to 1K annotations
We’ve increased the performance of our editors, enabling greater interactivity and responsiveness. Our image editor now supports up to 1,000 annotations per asset. This allows teams to annotate and gain greater insight from their data with little to no delays.
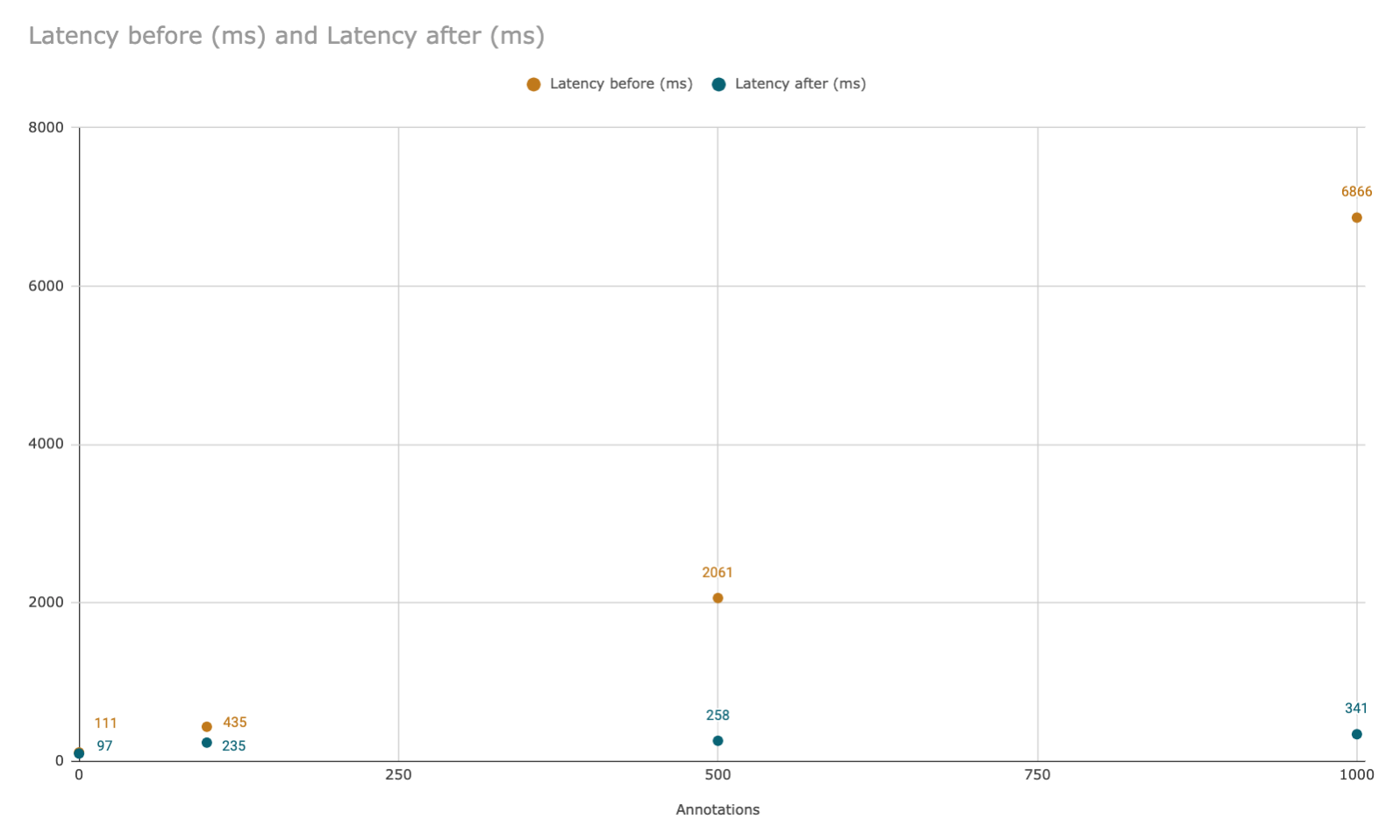
Enterprise teams, who historically rely on high annotation volumes to draw insights, can now create, manage, and uncover more insights from their data with ease.
Model
Configure, track, and compare model hyperparameters
Being able to understand and visualize how different models compare to each other is a crucial aspect of a successful data engine.

Users can now configure, track, and compare essential model training hyperparameters alongside training data and data splits in a single place. This update allows users to easily track and reproduce model experiments, and enables them to share best practices with their team.

We’ve also made it easy for users to compare the difference of model hyperparameters through our model metrics comparison view. Teams can use this view to understand the cause for different model results. Rather than flying blind, teams easily understand what is causing differences in model runs by comparing model run configurations and observing the differences in hyperparameters between two runs.
Learn more about adding a model run configuration to track hyperparameters in our documentation.
Preview model-assisted labeling (MAL) in a model run and easily send pre-labels to a project
Teams can upload predictions through MAL to a model run before sending them as pre-labels to a project.

Prior to this update, pre-labels would be submitted to a project directly when using the MAL feature. There was no real way of pre-determining whether a model prediction was useful or a particularly strong pre-label. Now, teams can upload predictions to a model run and view those pre-labels to determine whether or not to submit those model predictions as a batch.
With this workflow, users can now create a batch, select the model predictions they want to include, and send those data rows with predictions directly to a project from Labelbox Model rather than assembling everything through the SDK.
Use our improved search filters for a more unified experience
We’ve updated our search filters to enable a more intuitive and unified search experience. The search filters in Labelbox Model enable workflows such as uncertainty sampling, MAL visualizations, and error analysis.

Users can search by the following filters:
- Prediction (features)
- Ground truth (features)
- Dataset
- Project
- Metrics
- Data row (including data row ID and label ID)
Catalog
Assign custom metadata in bulk to auto-label data
Users can now apply metadata to bulk data rows in Catalog to make finding and searching for data rows easier than ever across our platform.

To assign custom metadata, users can first select a few data rows of interest in Catalog and conduct a similarity search to pull in more similar data rows. From there, users can create a labeling function that can be used in Catalog to automatically search for all other similar data rows.
Once users have narrowed in on a specific subset of data, they can use metadata to tag selected data rows. This will automatically write metadata on all of the selected data rows, allowing users to seamlessly access these data rows with both the metadata search field in Catalog and across the Annotate and Model solutions.
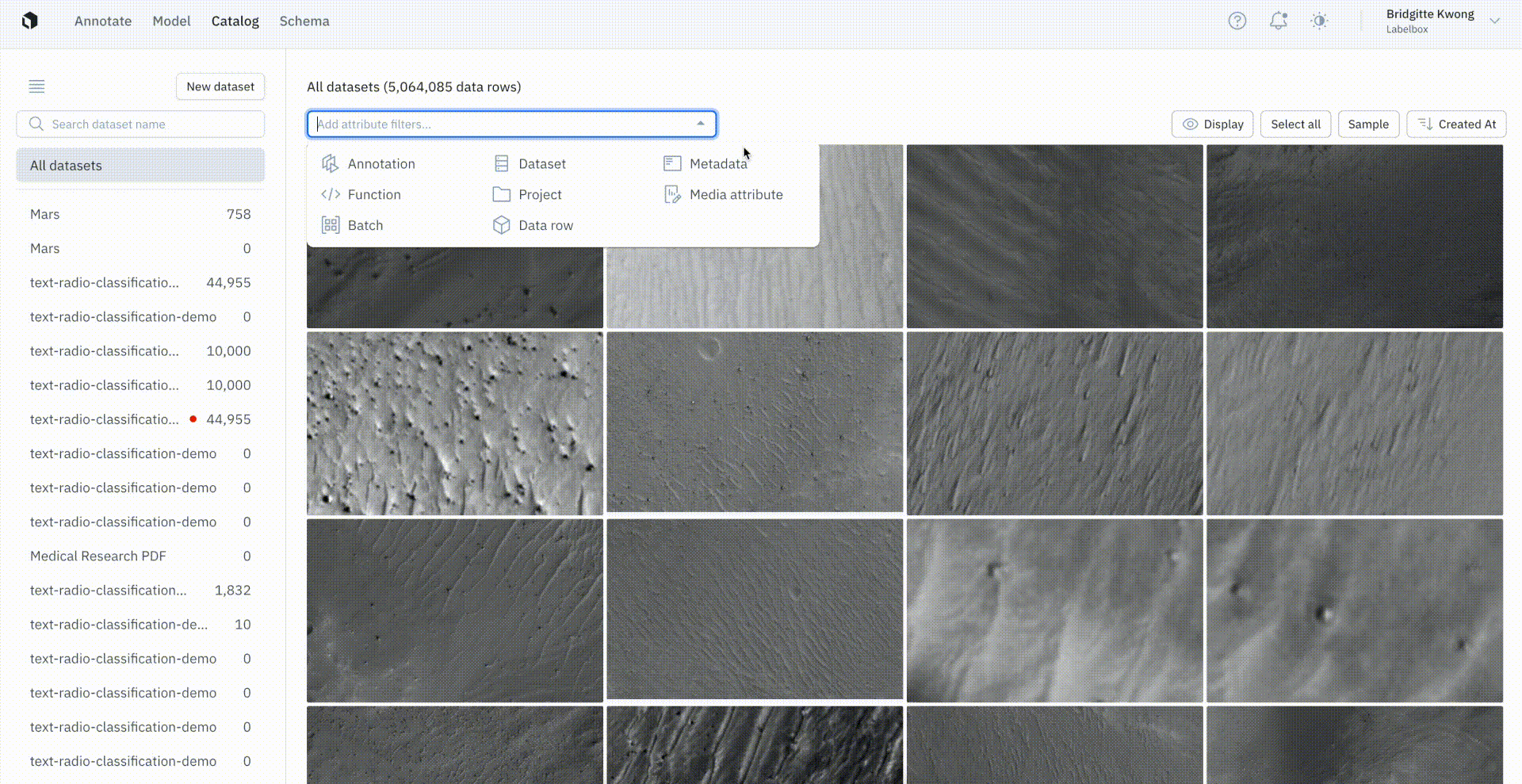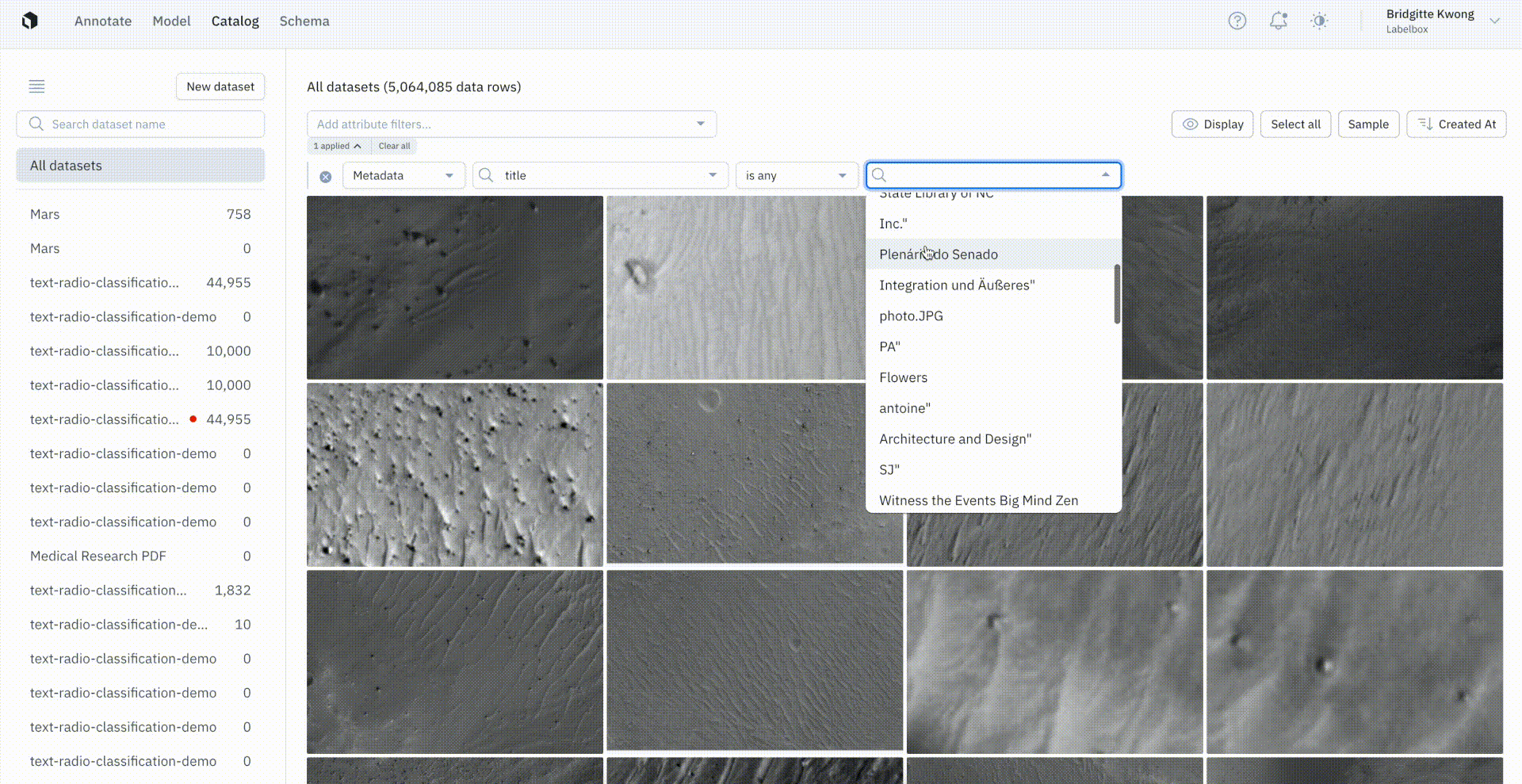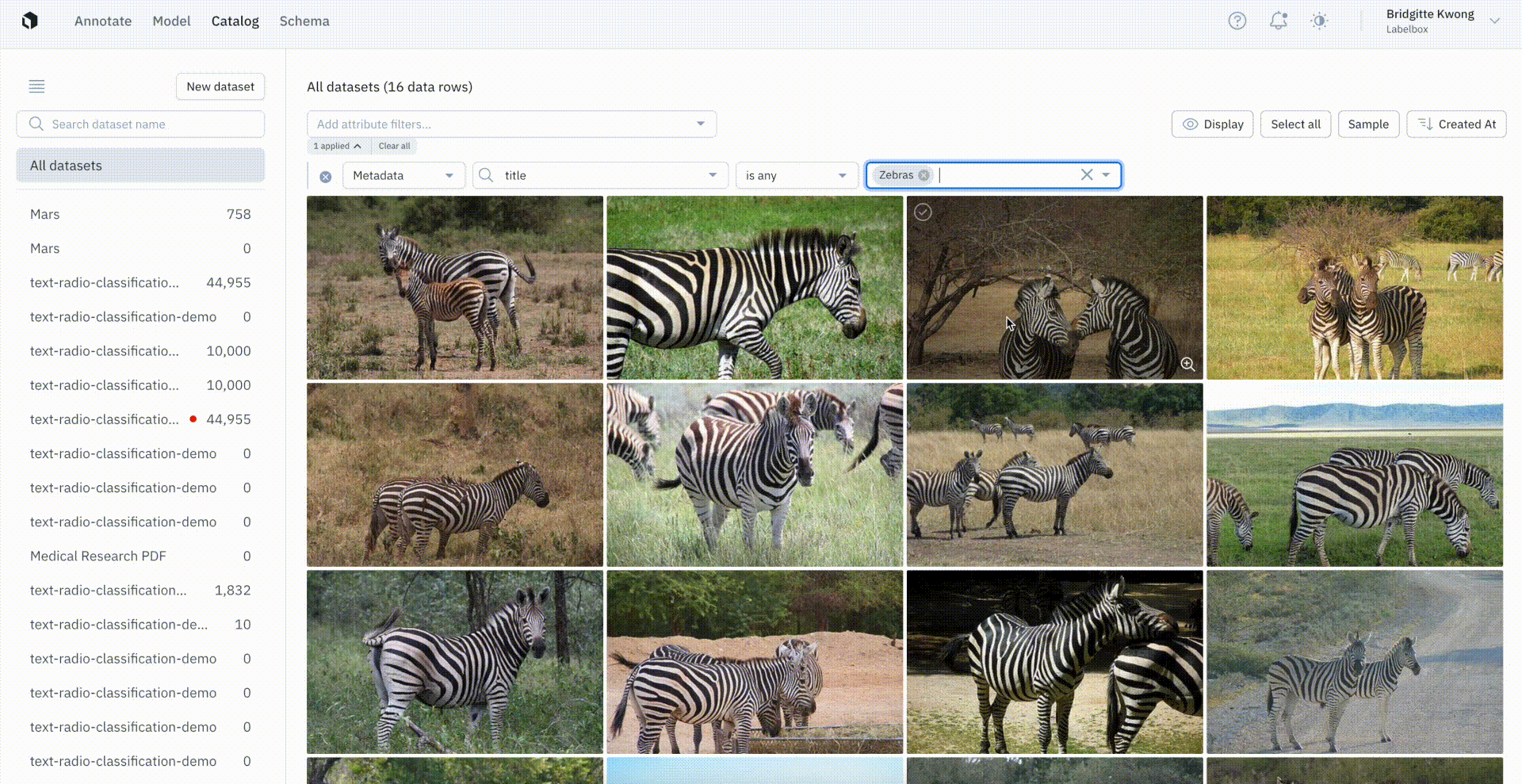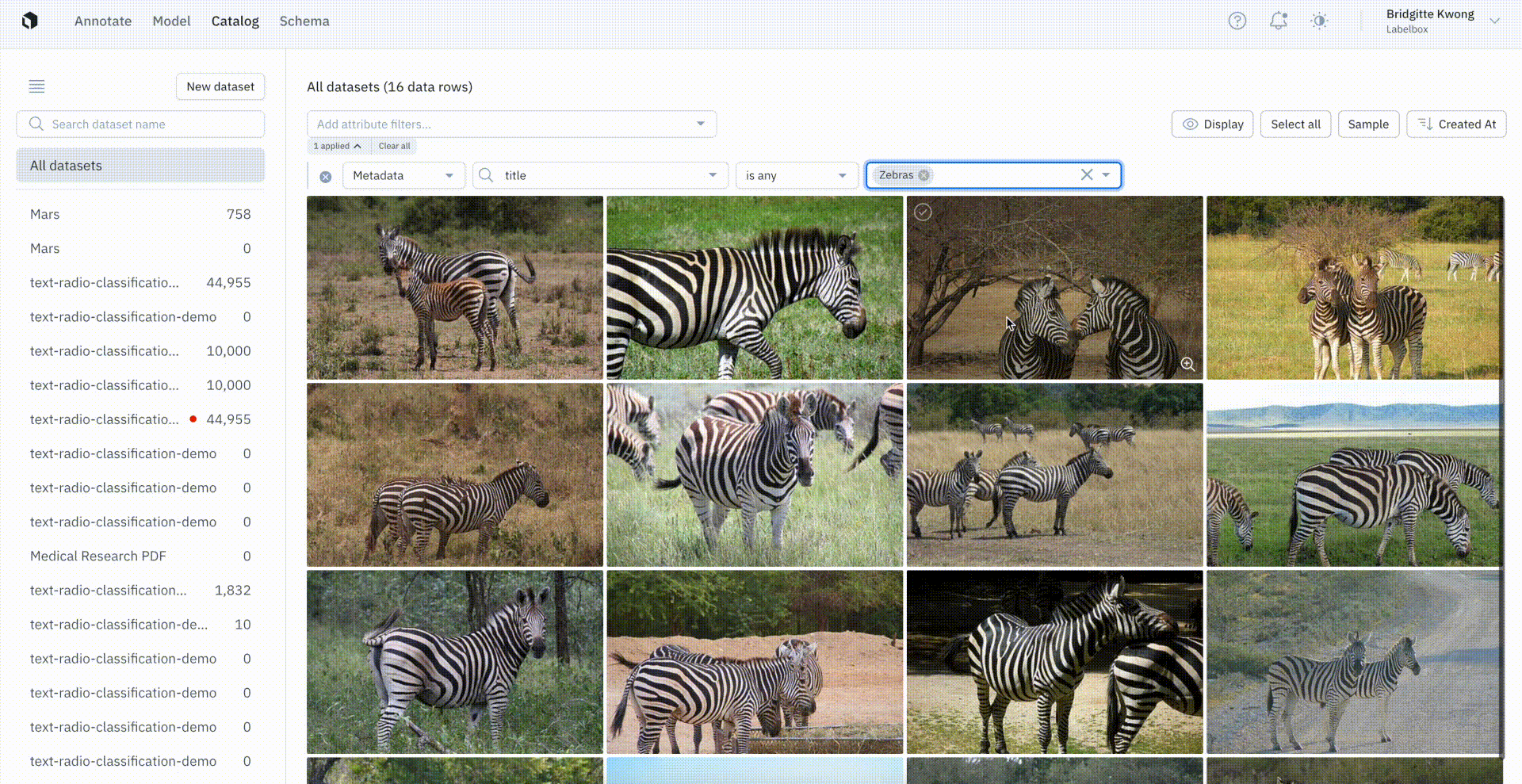
Using the SDK, users can export these data rows from a dataset and can also export and access the metadata.
Get smarter on your data with in-depth analytics
Catalog provides top level data analytics for teams to understand their data in order to mitigate model error and biases.

We’ve introduced metrics view in Catalog — allowing teams to understand annotation distribution at a global level. From there, teams can easily filter down to specific annotations for review. Users can also view metadata distribution for a holistic understanding of their data.
Search for data faster than ever with powerful new queries
We’re excited to introduce powerful new queries within Catalog that will help teams find specific data faster. With these improvements, users will have access to more advanced search capabilities to help identify and narrow in on specific subsets of their data.
Annotation count filter
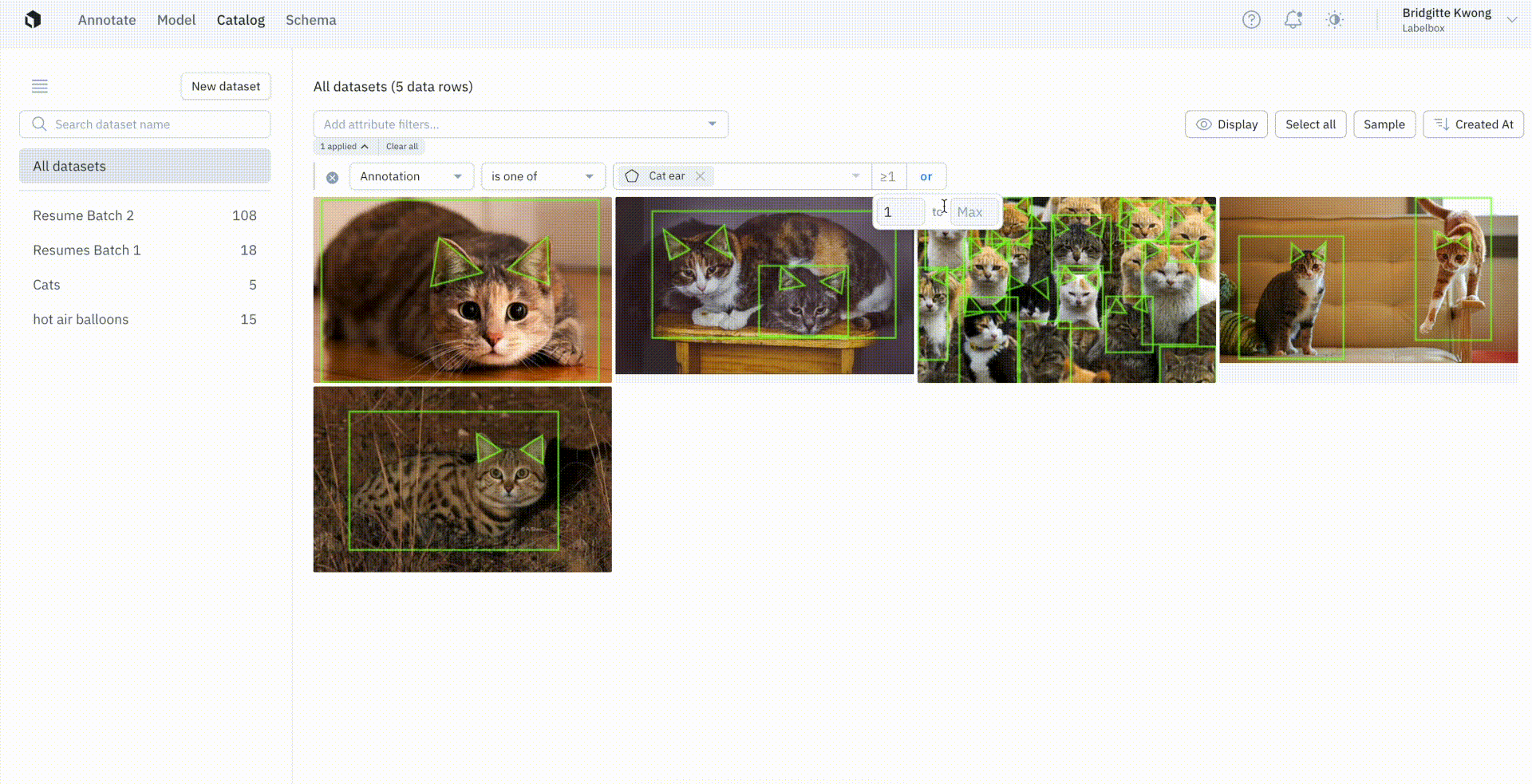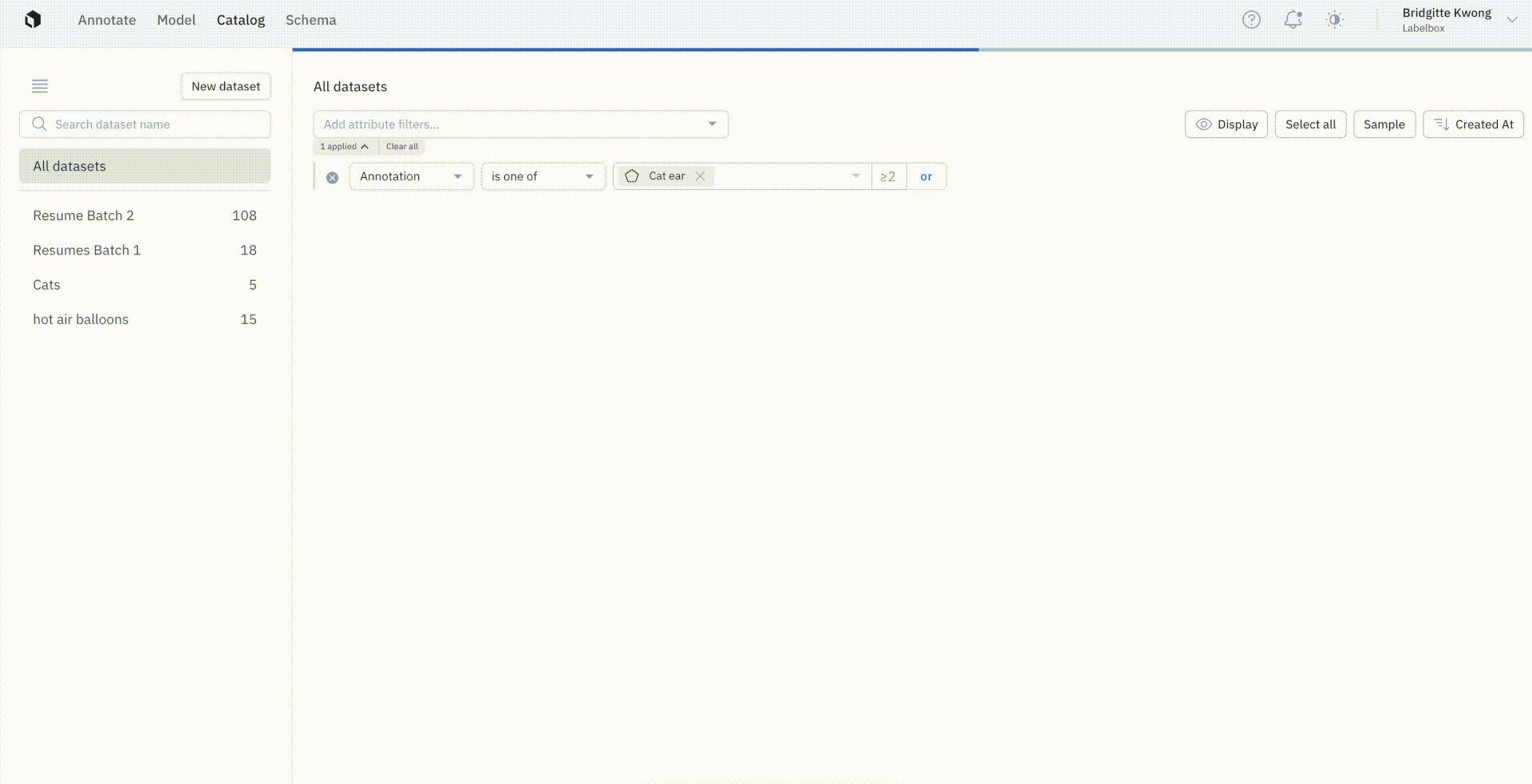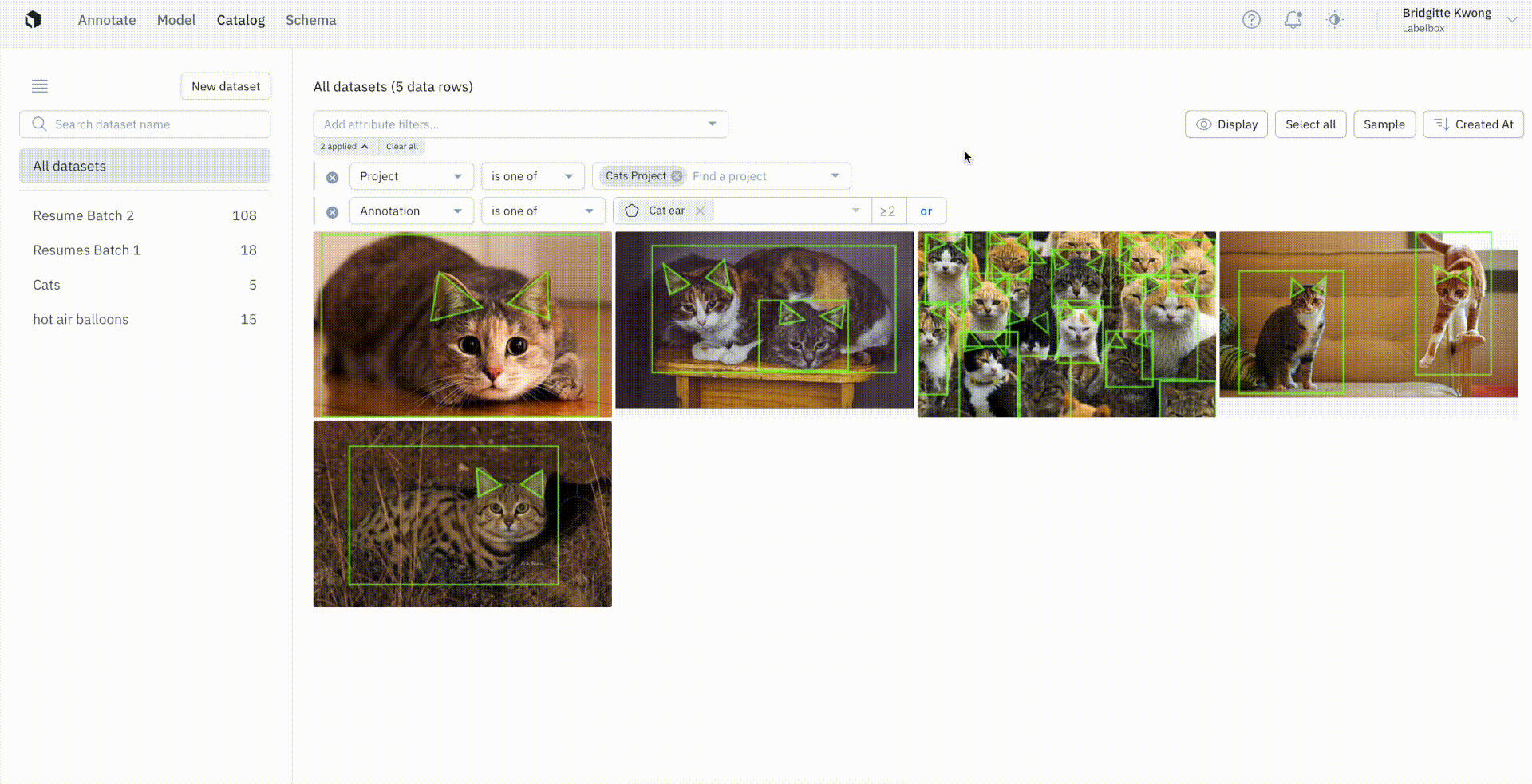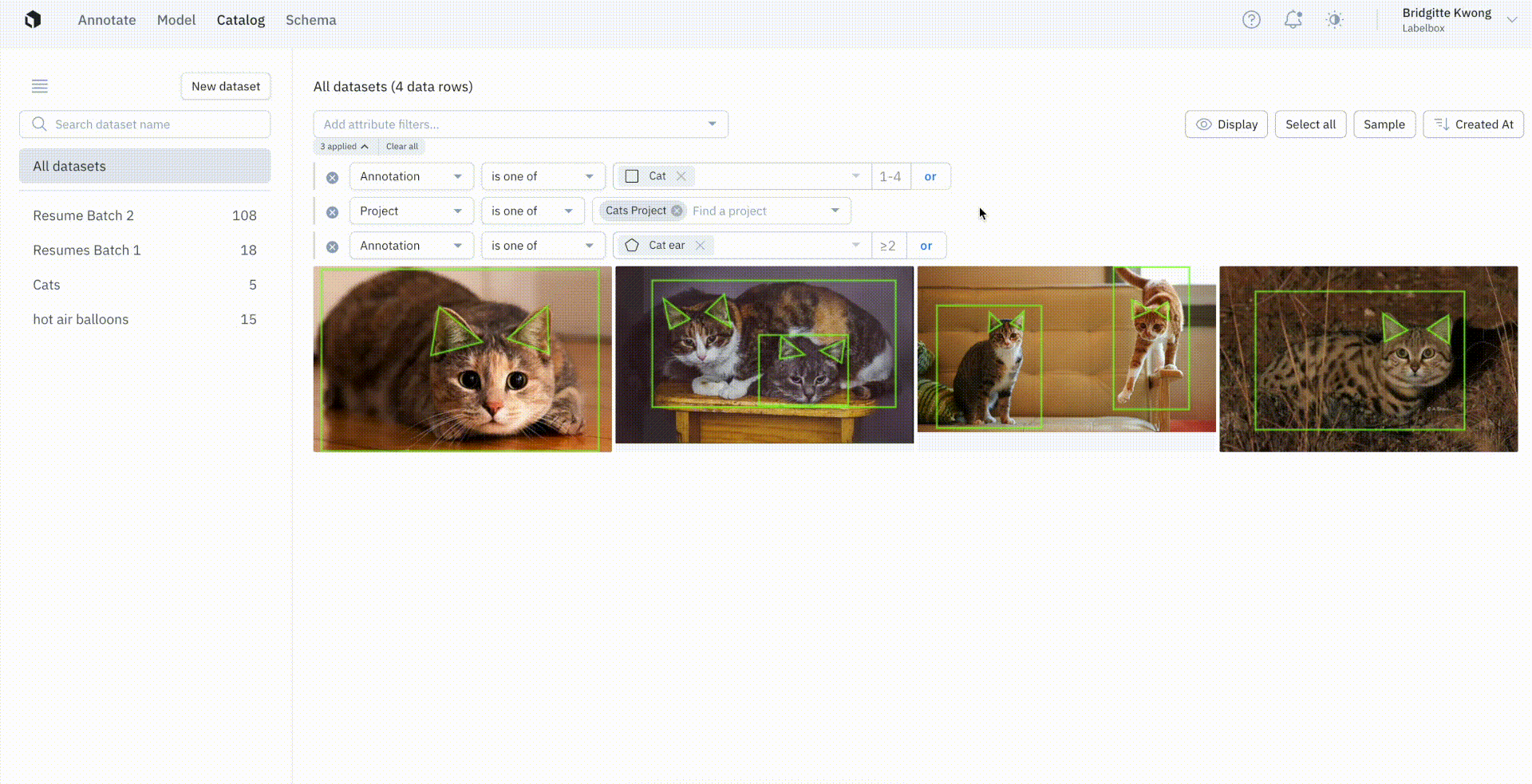
Instead of searching only by the presence or absence of an annotation, users now have the option to conduct more granular searches.
You can now specify the exact number of annotations on a data row — including searching for a specific value, more than a specific value, or specify a range of values. You can couple this powerful new search feature with other search criteria, such as the project or other annotation specifications.
The above example, in which we’re only interested in filtering for data rows where there are two or more cat ears present, is part of the Cat Project, and contains one to four cats in each image.
Reworked metadata filter
We’ve moved away from OR button logic filters and are introducing more powerful search capabilities on text metadata.
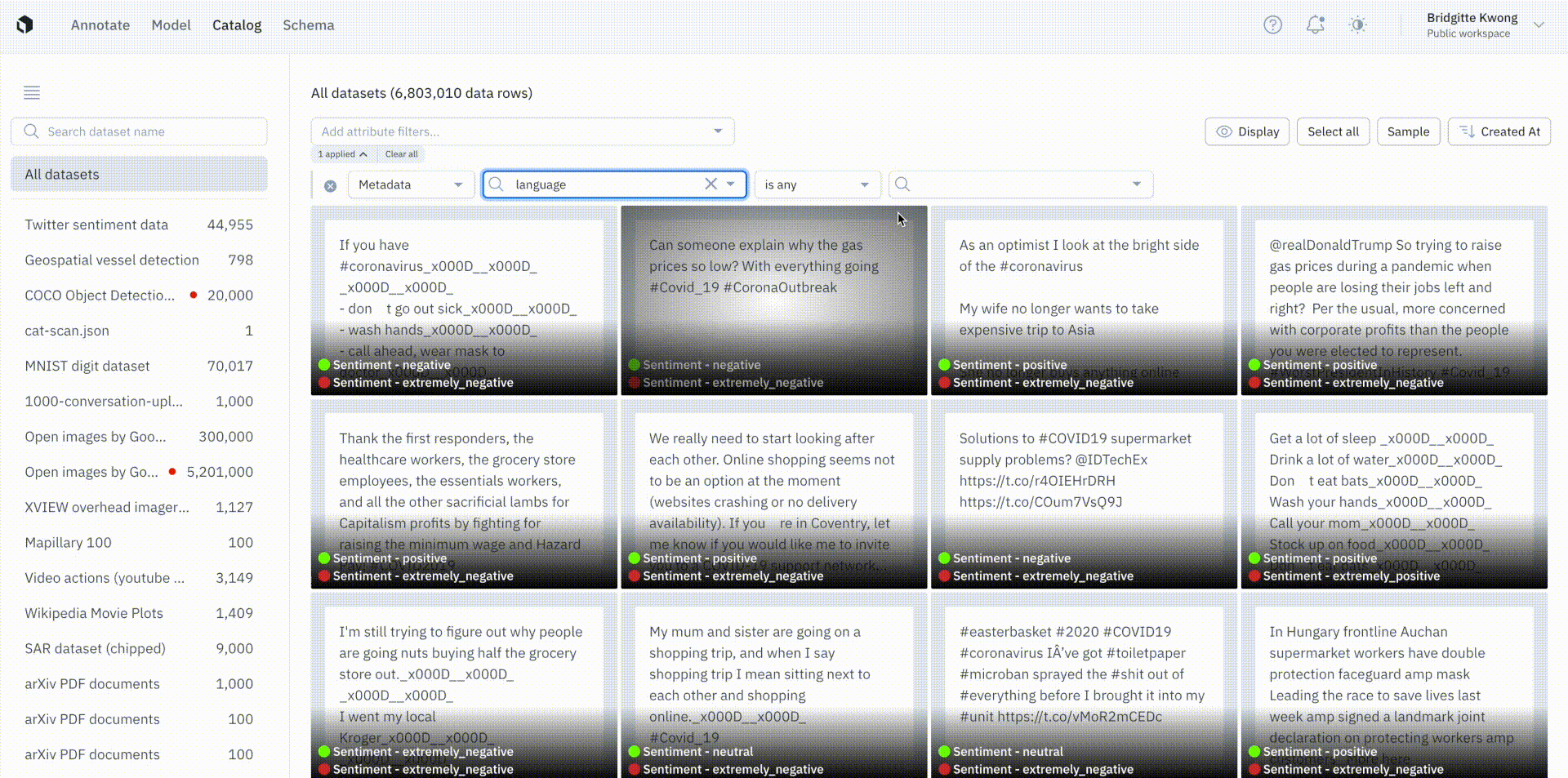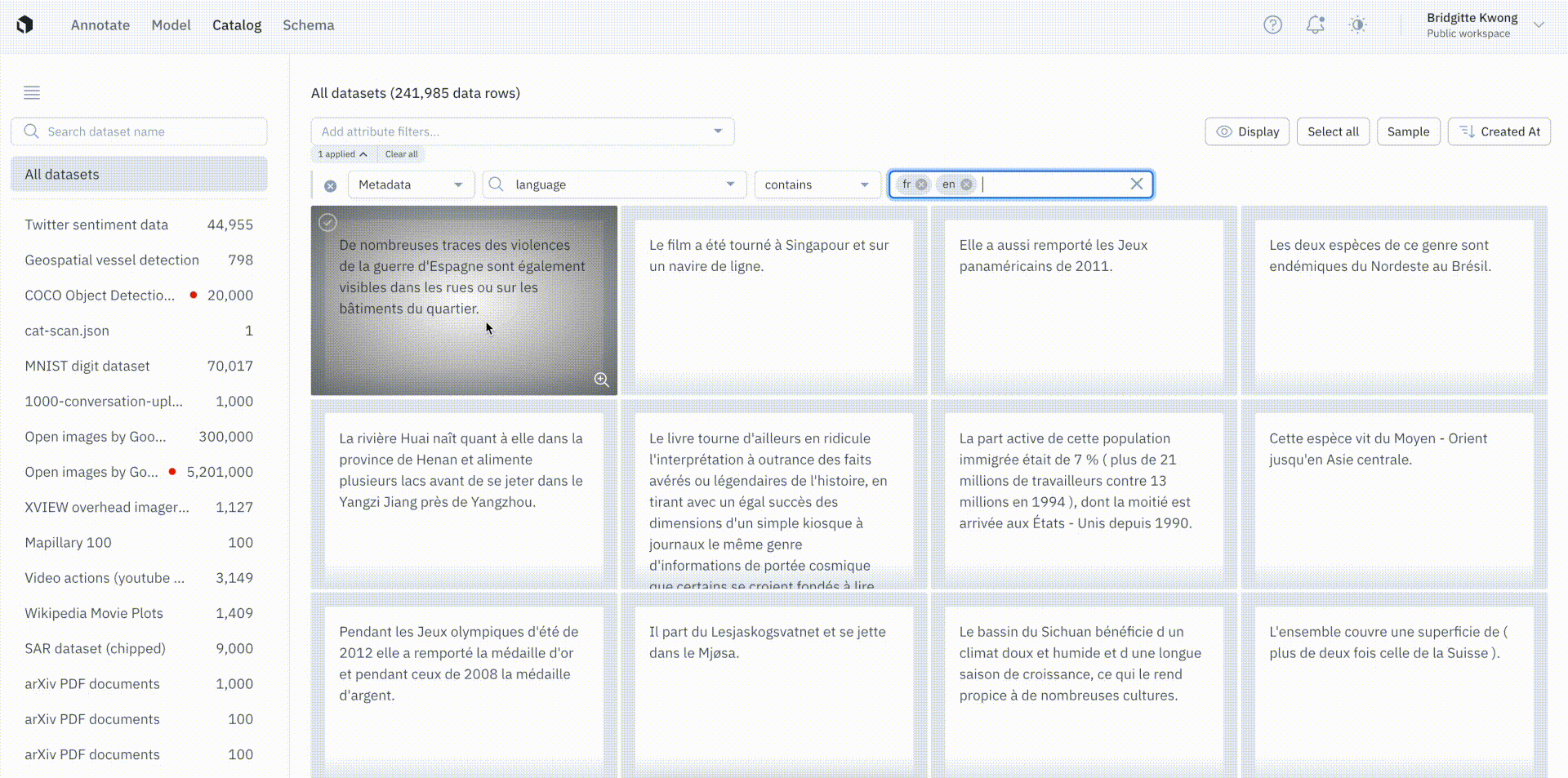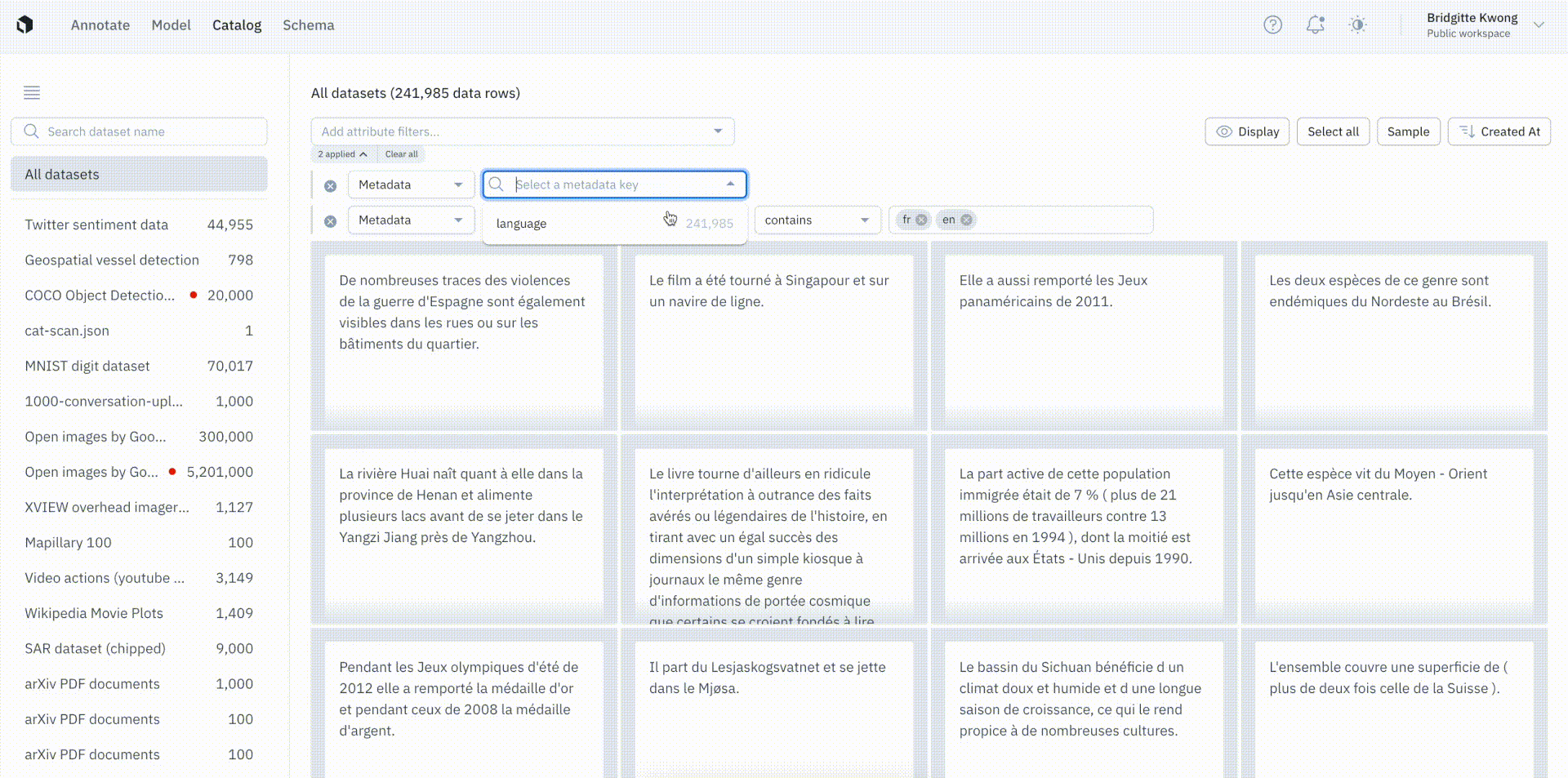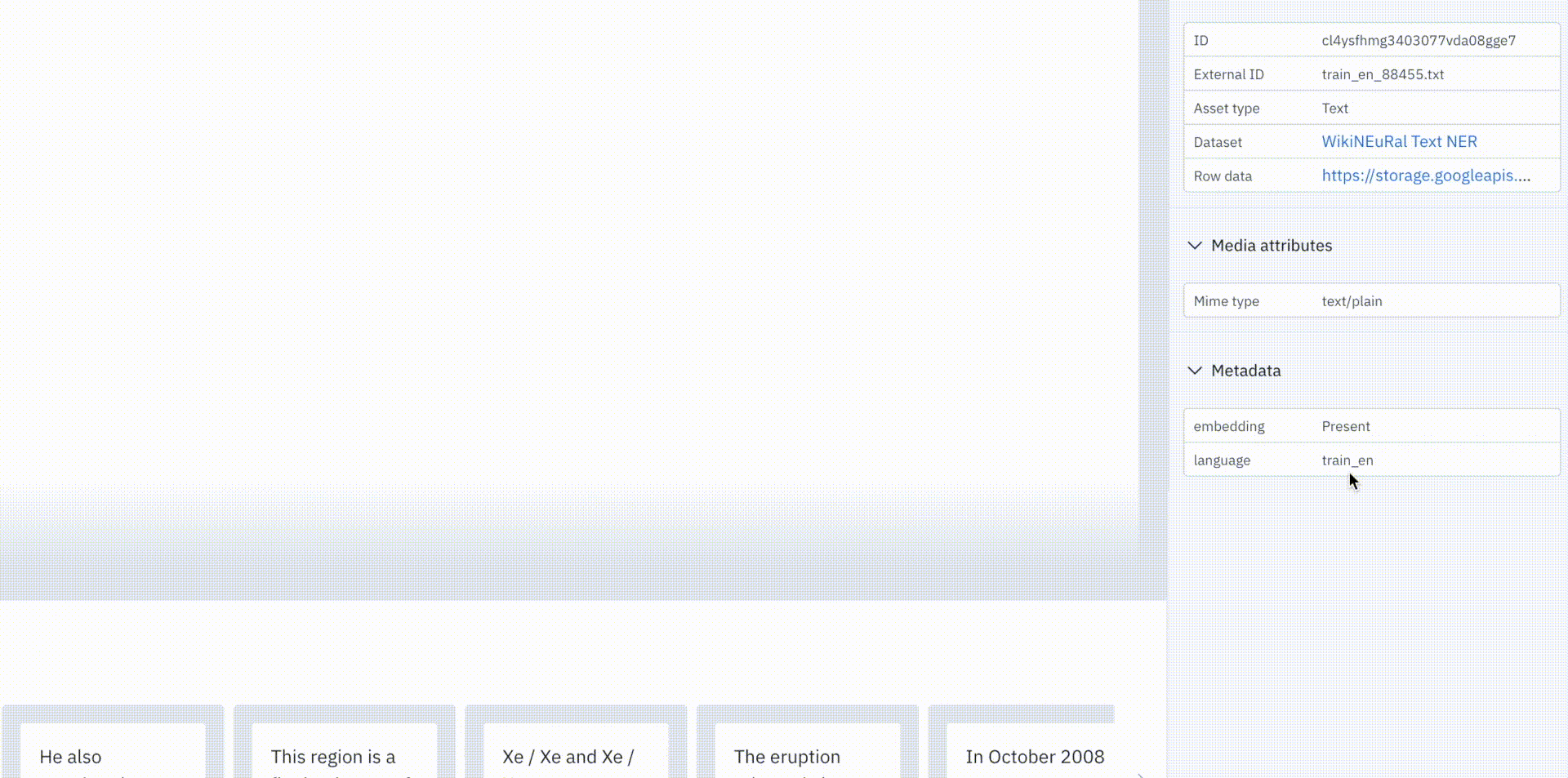
Users will now see a dropdown of operators and can now multi-select within a search. Any values selected in the dropdown are considered OR expression arguments.
Datetime filter improvements
With this update, users can filter by a specific time in addition to the date. Prior to this, there was no way for users to filter for data before, after, or within a specific time period.
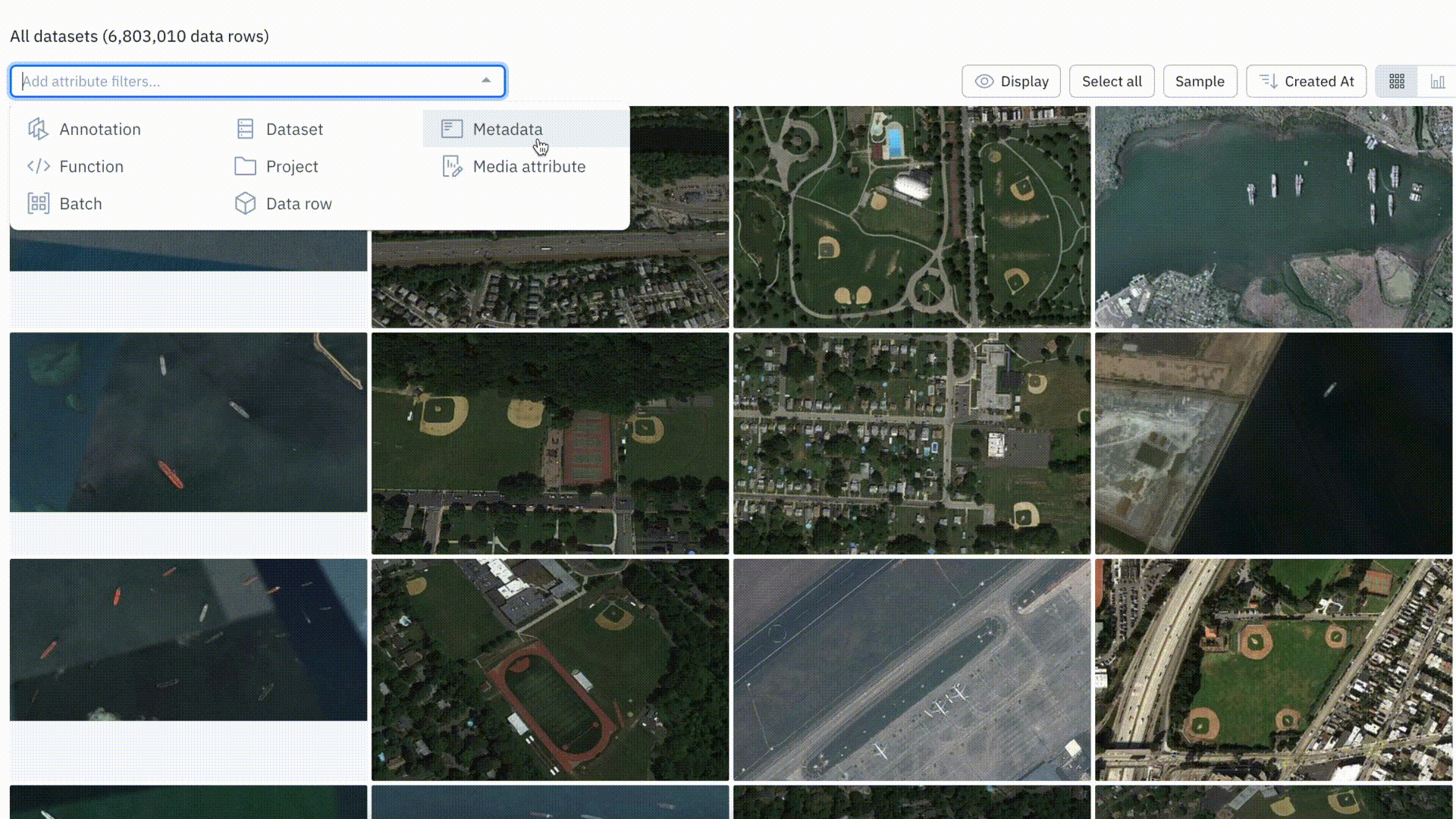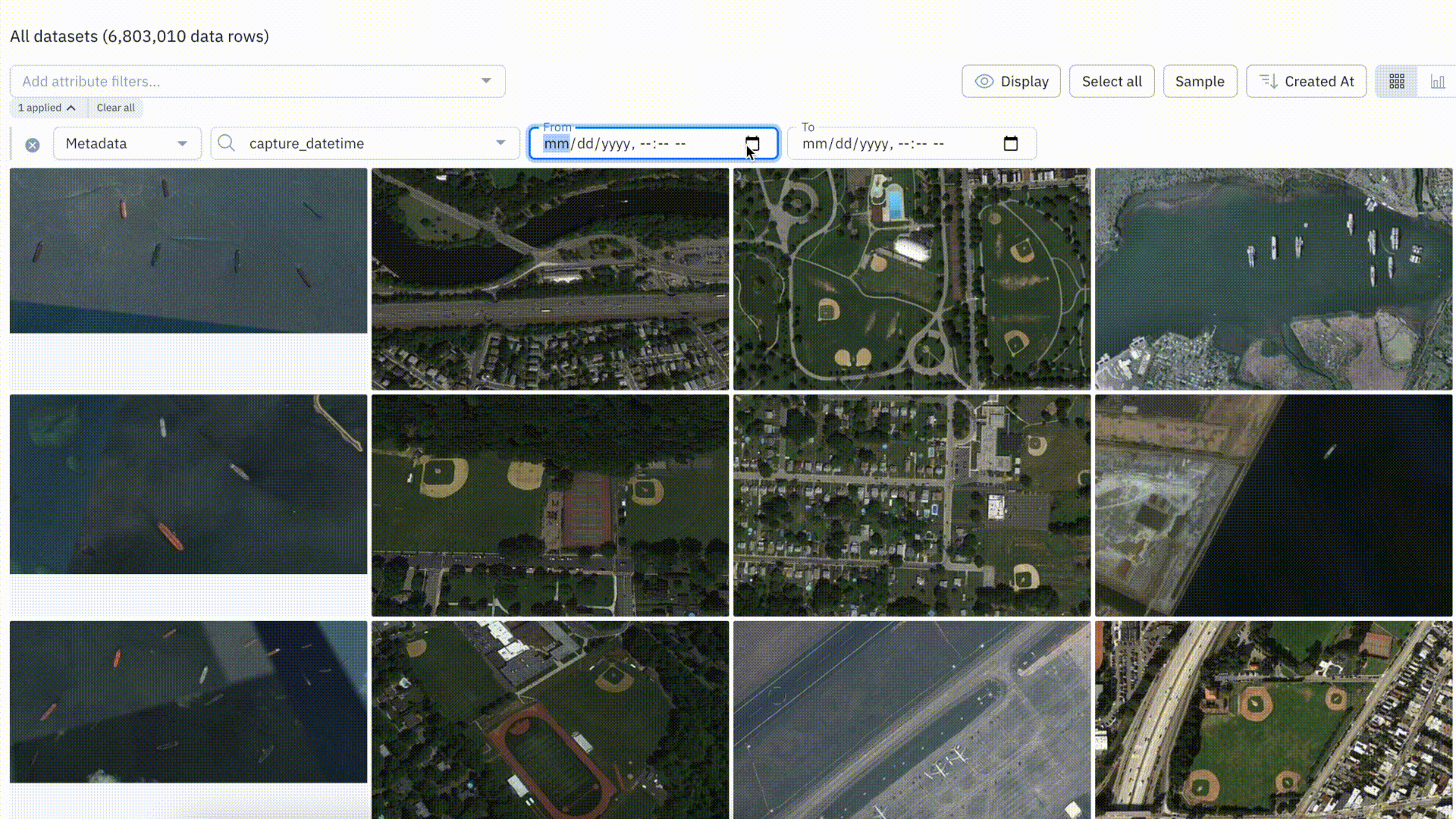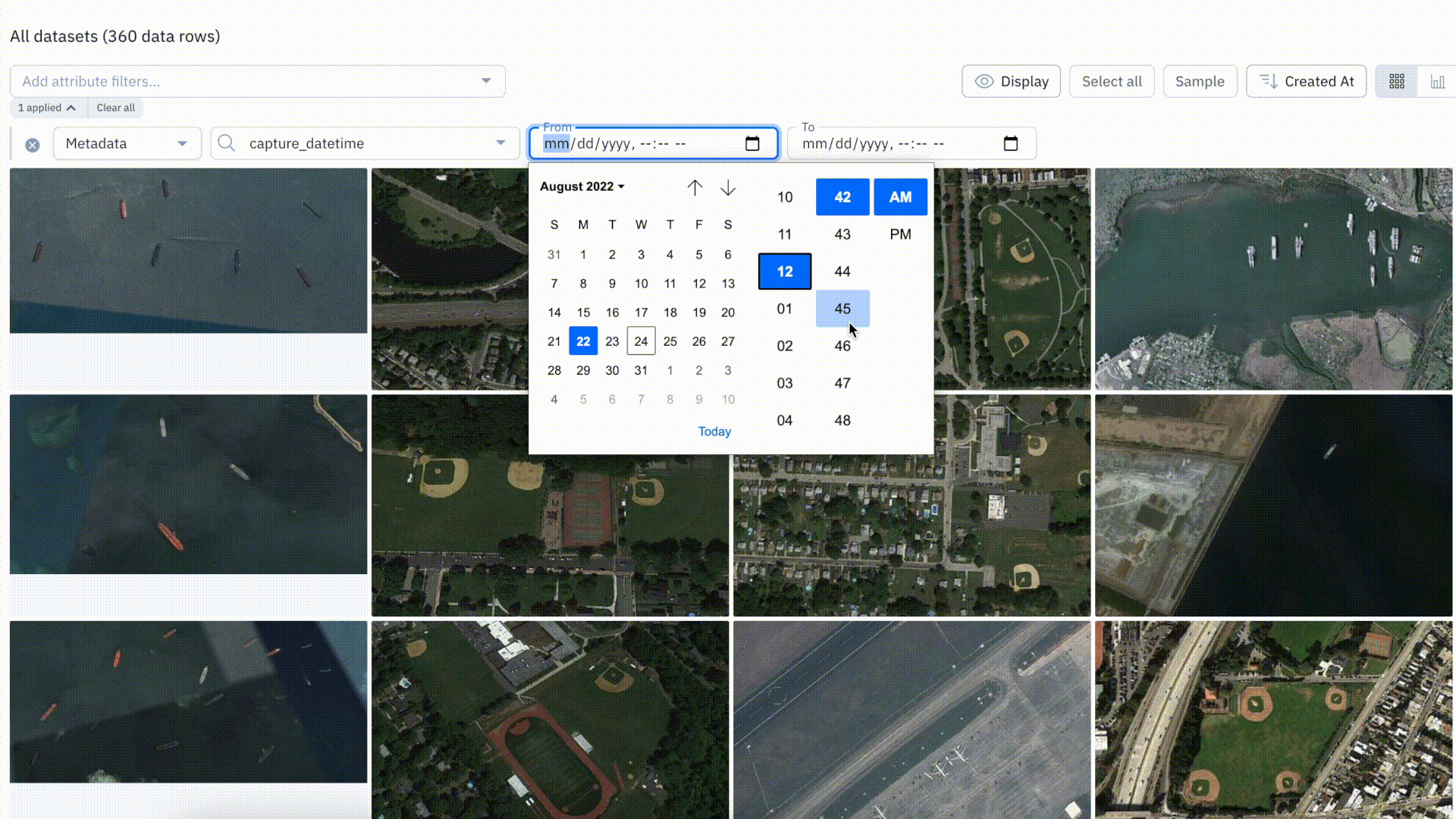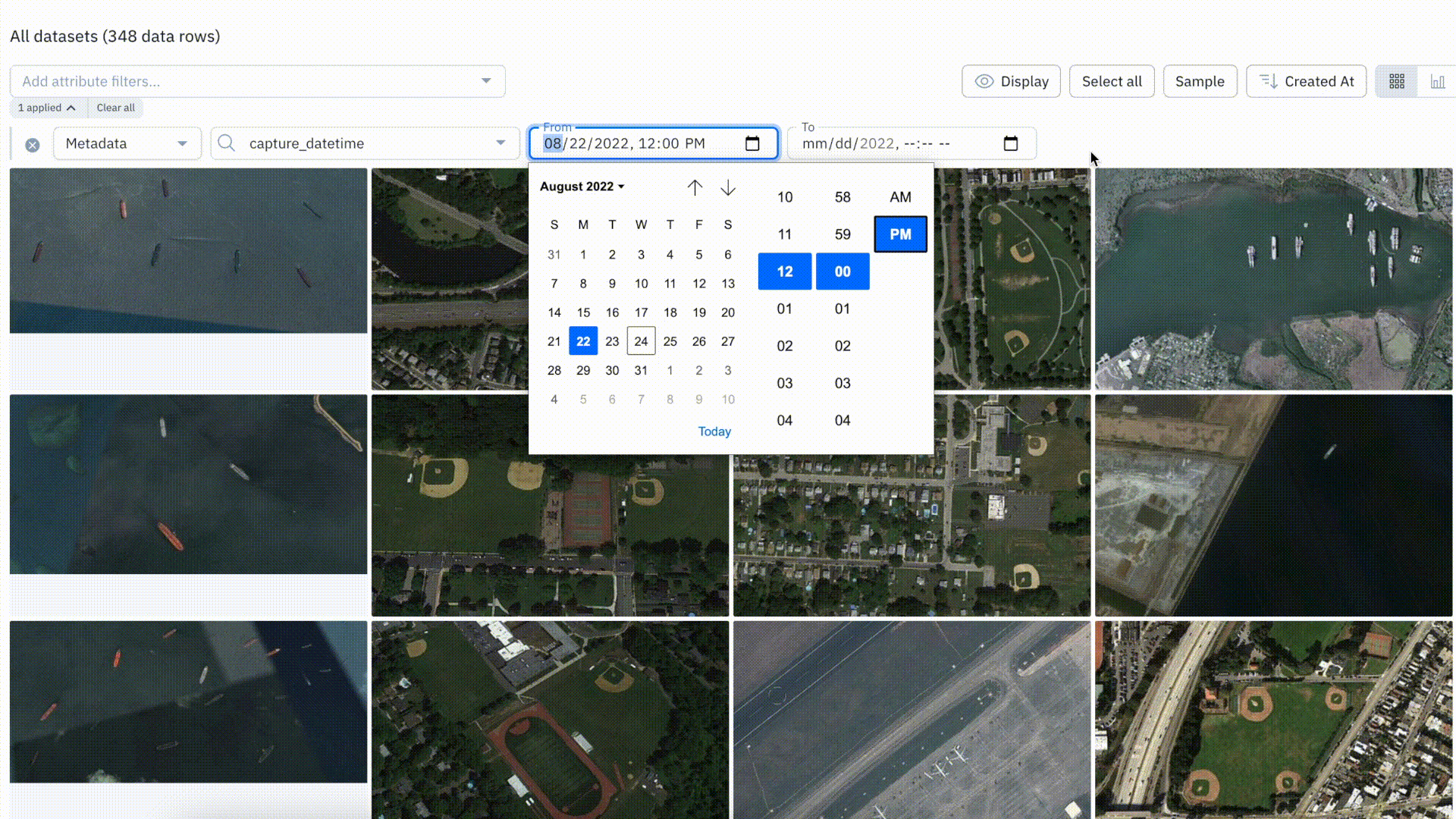
Datetime filters can be extremely helpful in not only surfacing relevant data, but for use cases where time of day (morning or evening) can impact the type of data or imply scenarios or edge cases.
Keep only unlabeled data in Catalog
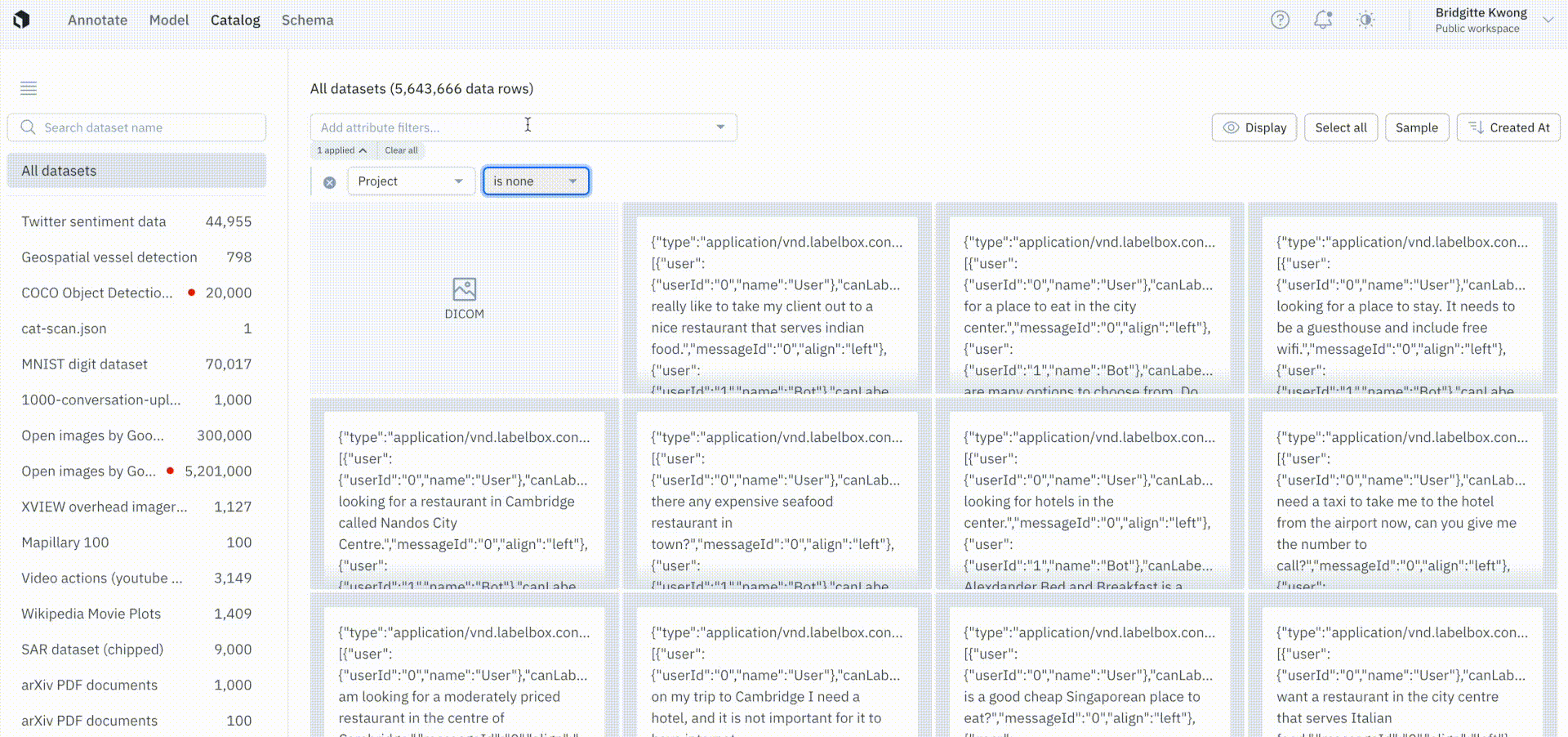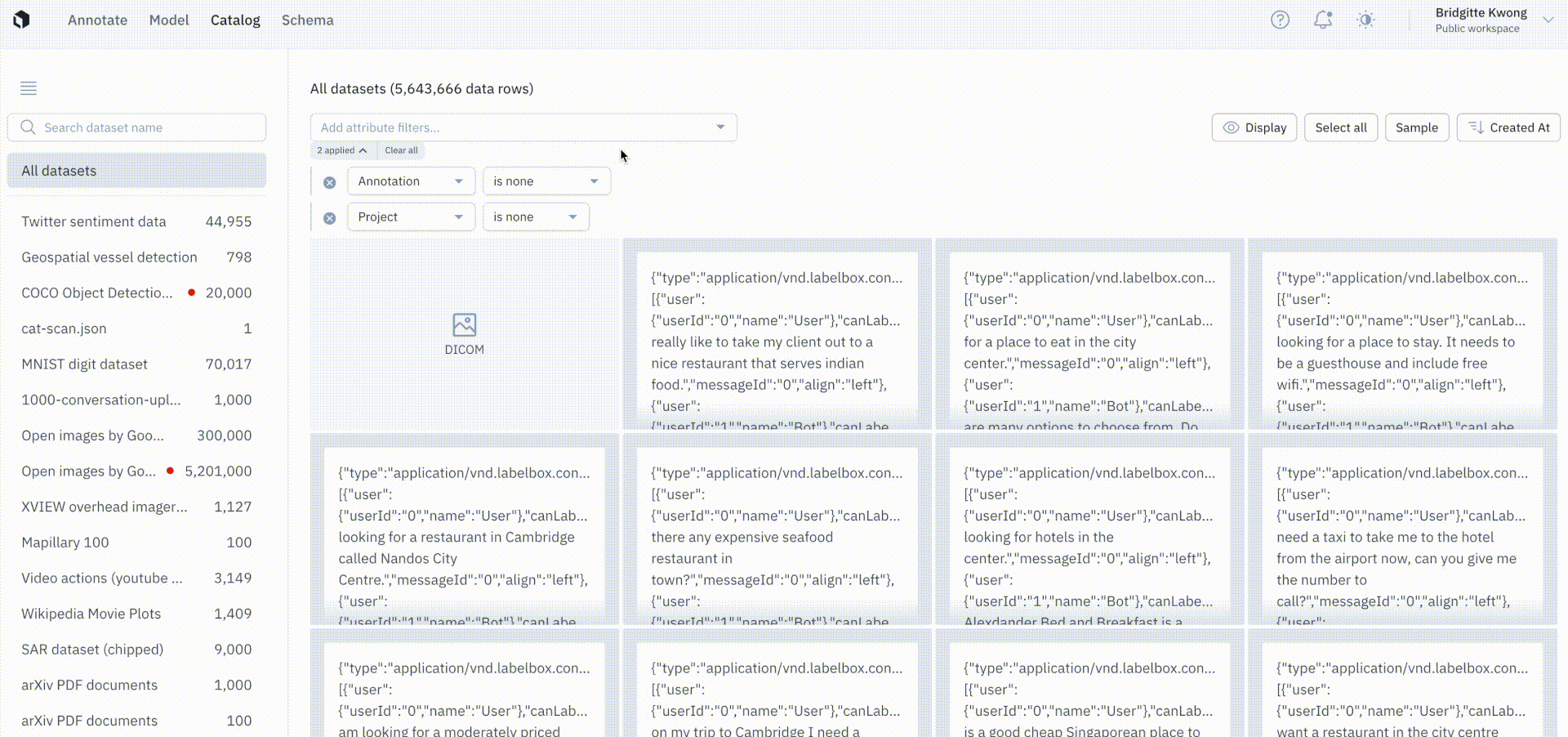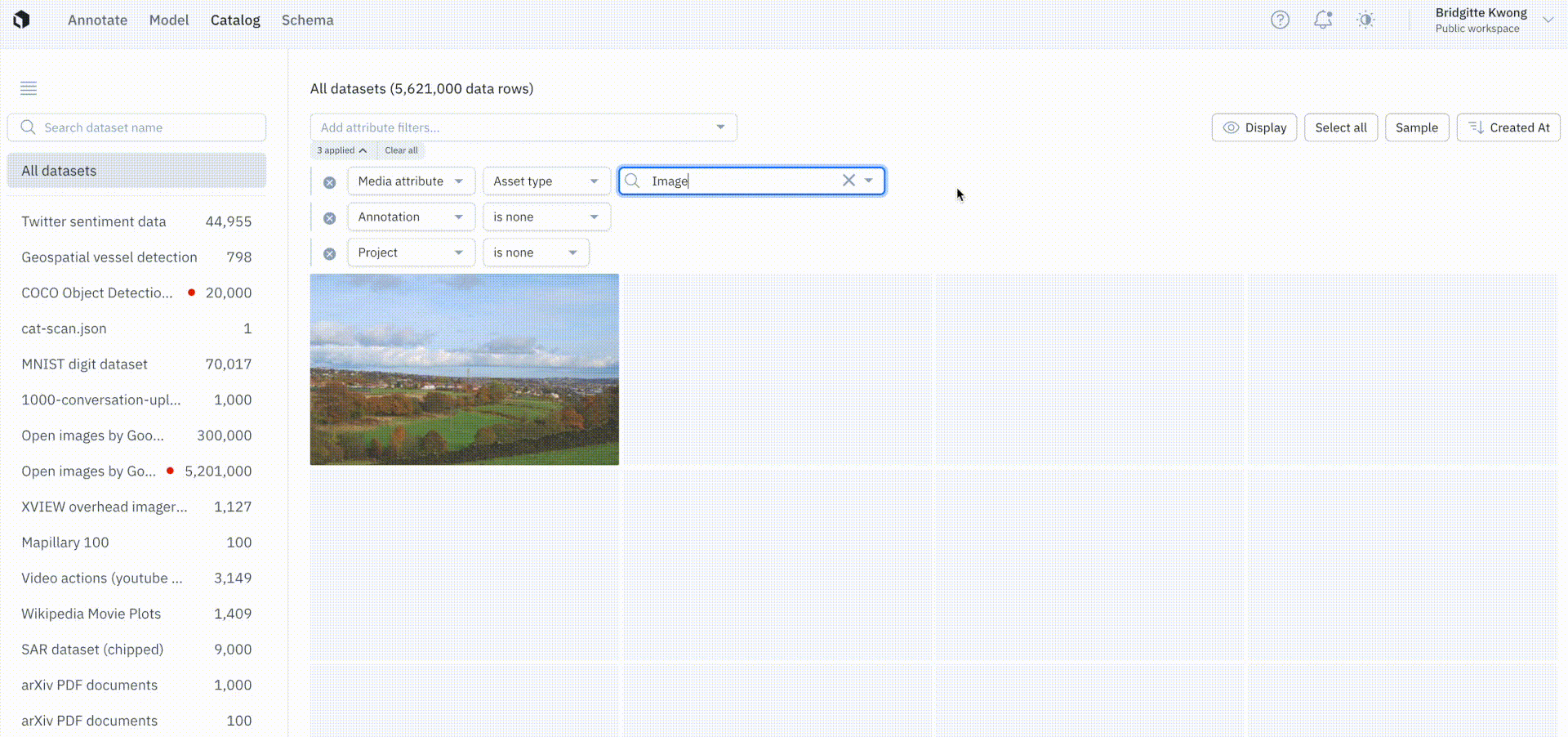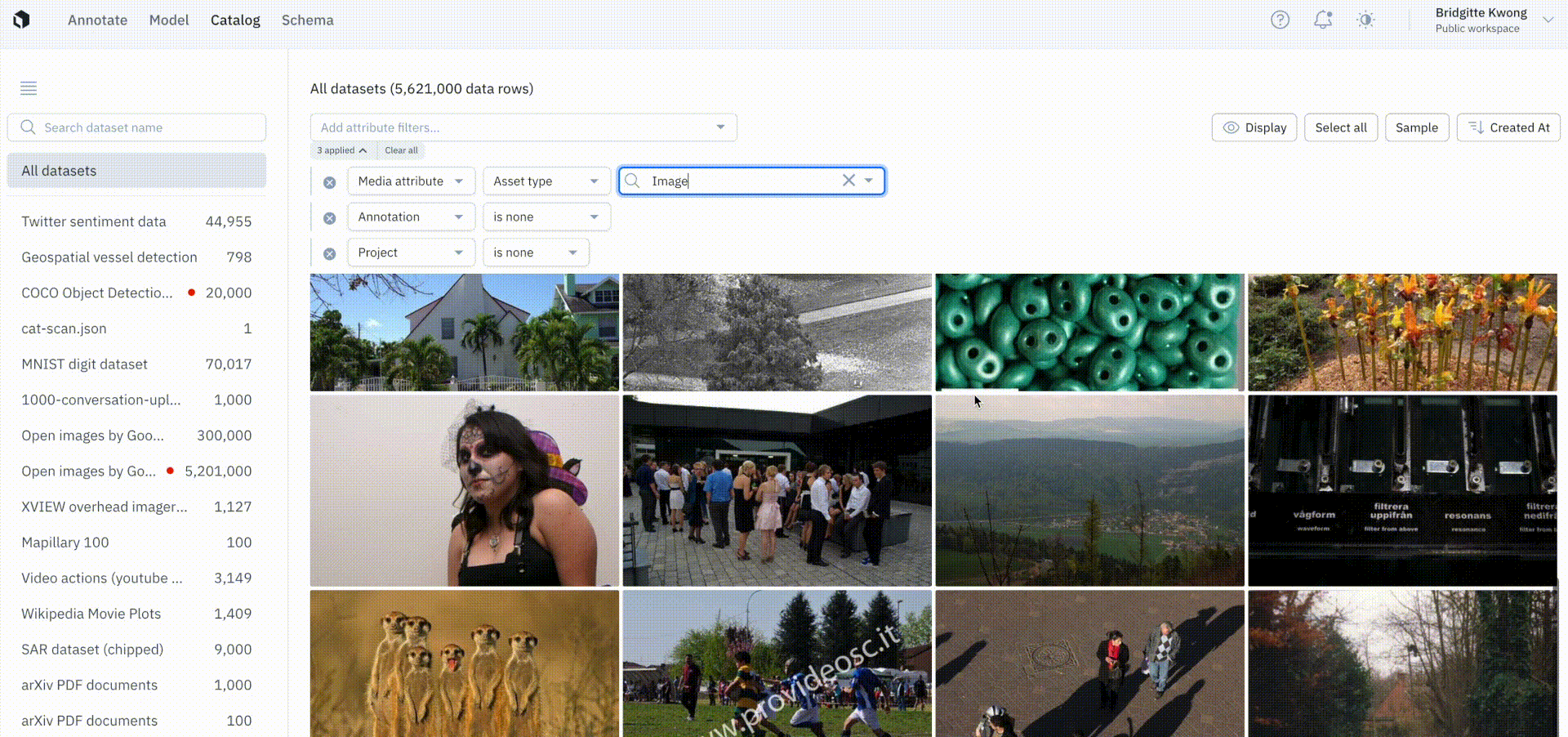
We’ve introduced a project filter with an operator, is none, that will only show data rows that are not in any batch. This allows teams to safely send data rows that are not already in an existing batch to a project. Prior to this update, there was no easy way to distinguish between data rows that were already queued for labeling.
Keep only unlabeled data in Labelbox Model
To distinguish training data (labeled) from unlabeled inference or production data in a model run, users can now filter by the presence of annotations.
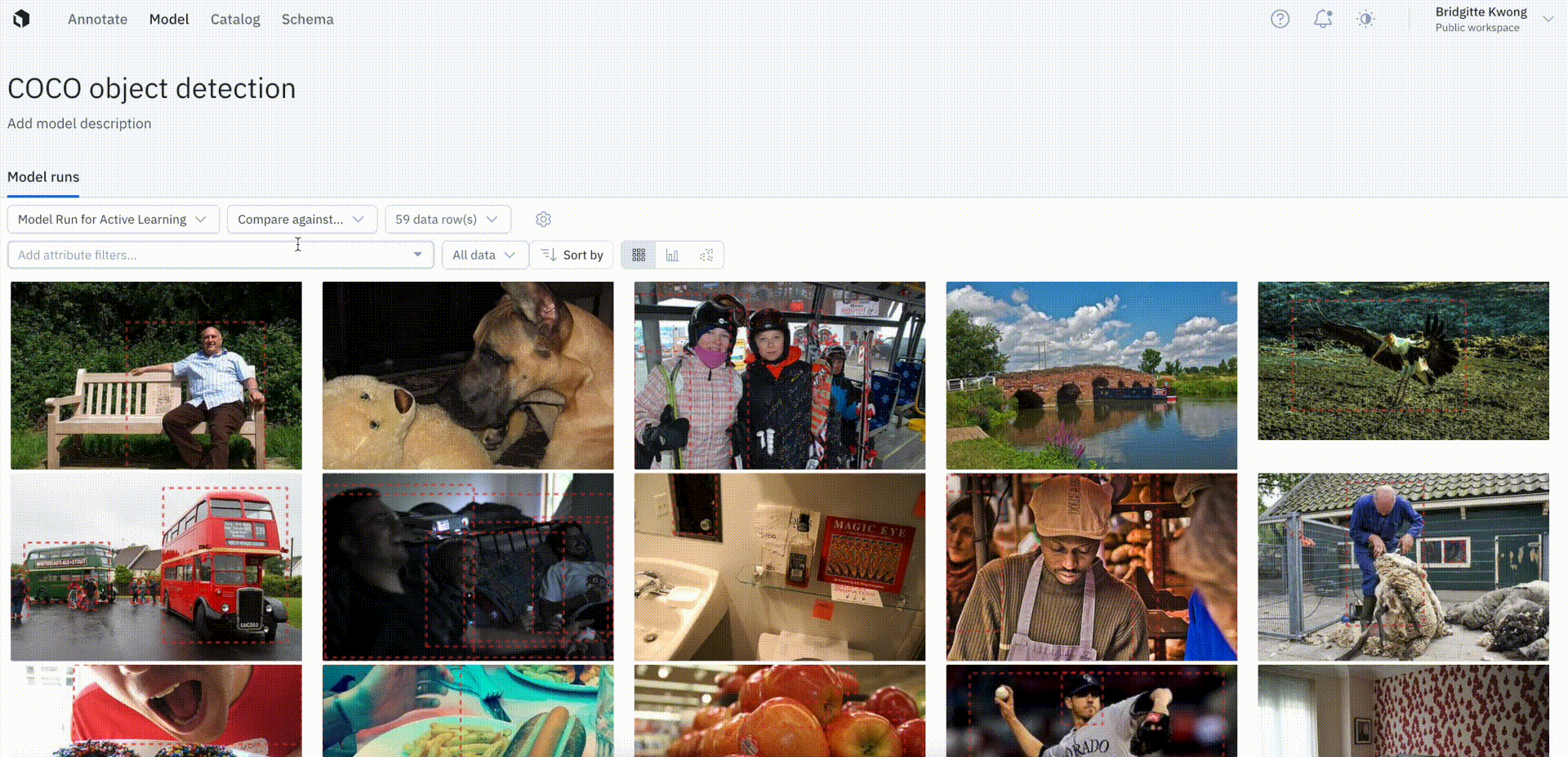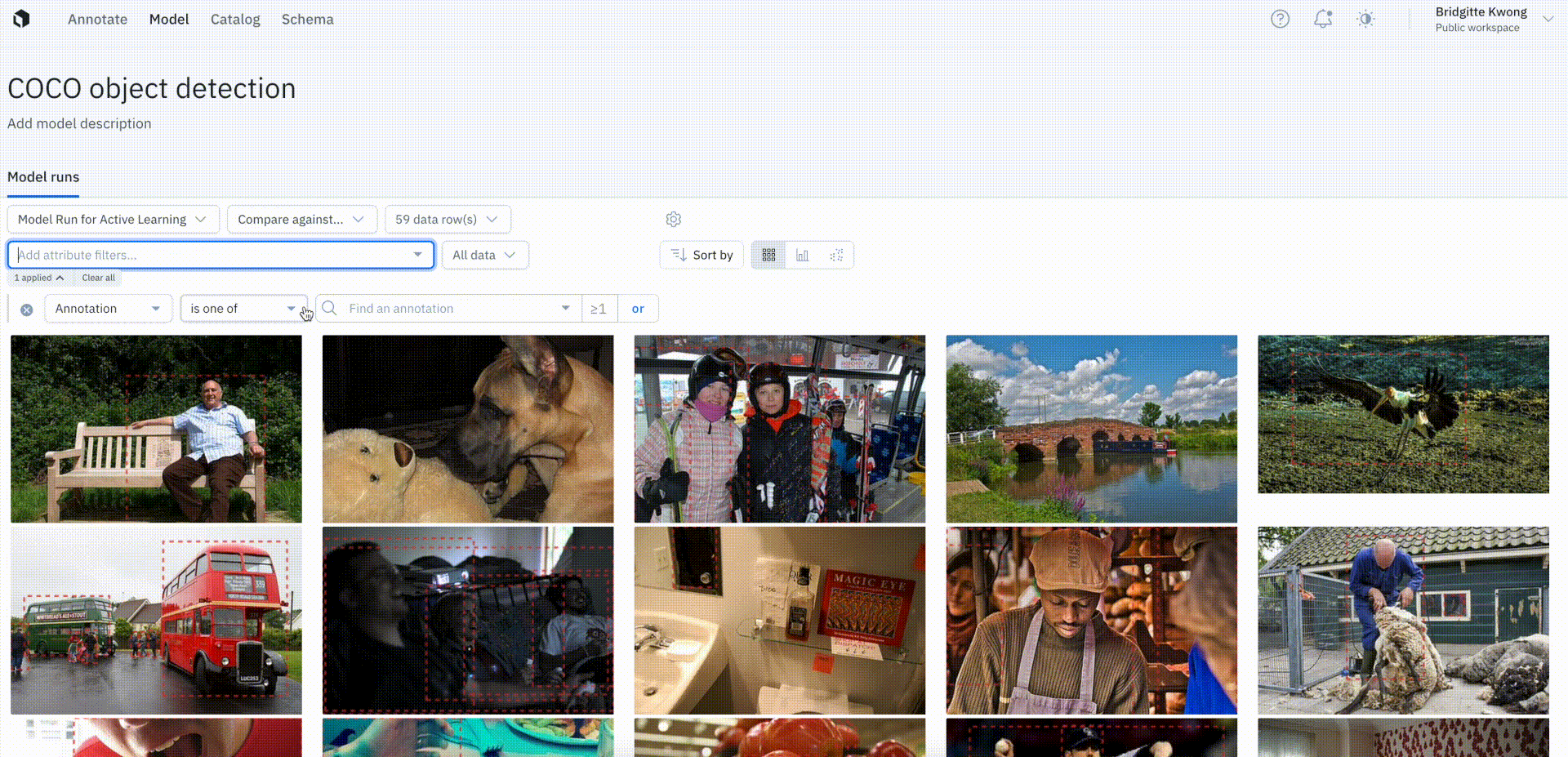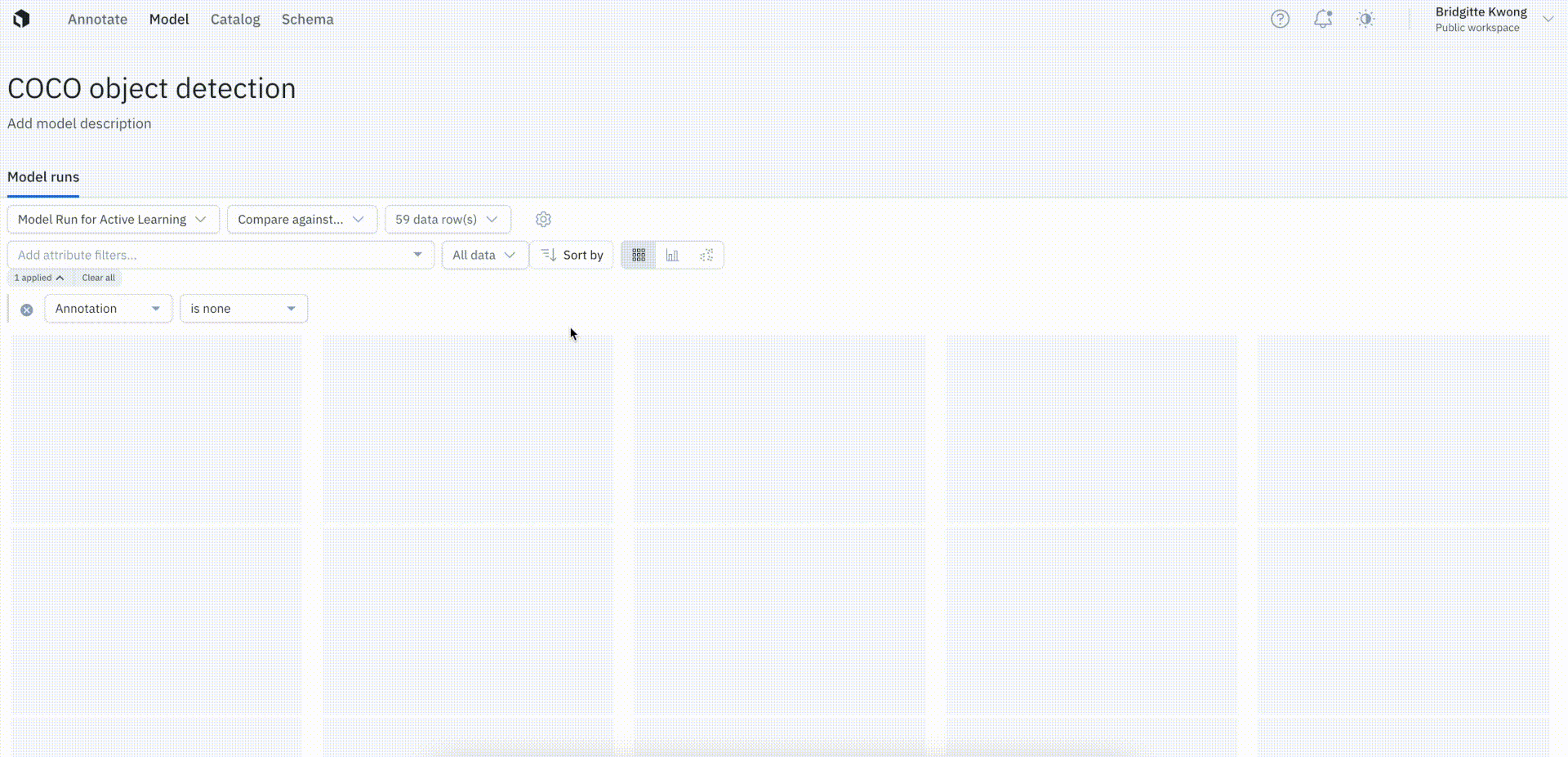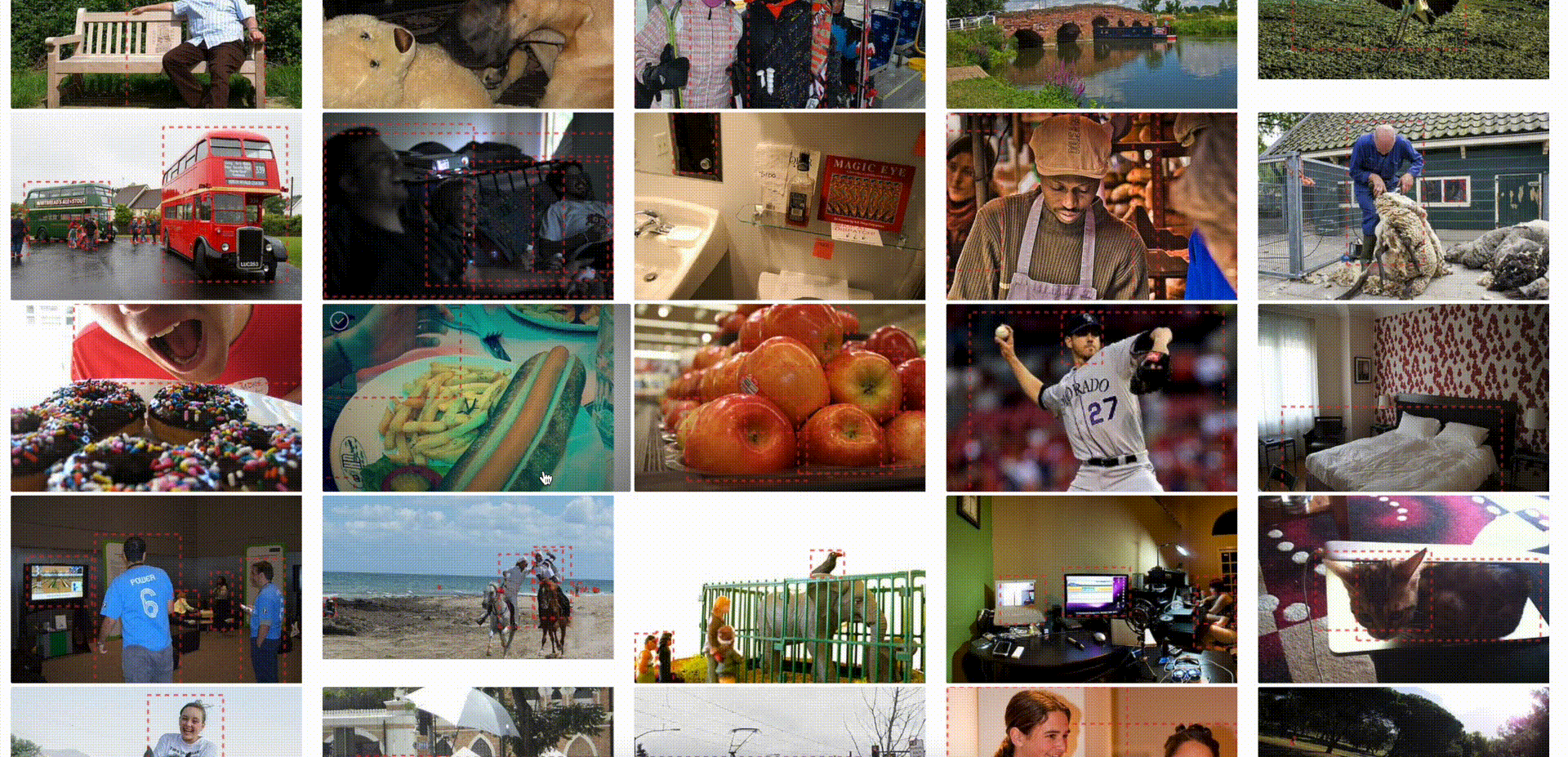
The annotation is none filter will show all data rows with zero annotations in the model run, whereas filtering by annotation is any will show all data rows with at least one annotation in the model run. This filter will help teams keep track of their unlabeled and labeled data in the model run.
SDK
New SDK reference page
We’ve redesigned our SDK reference page to make it easier for developers and teams to find SDK-related information.
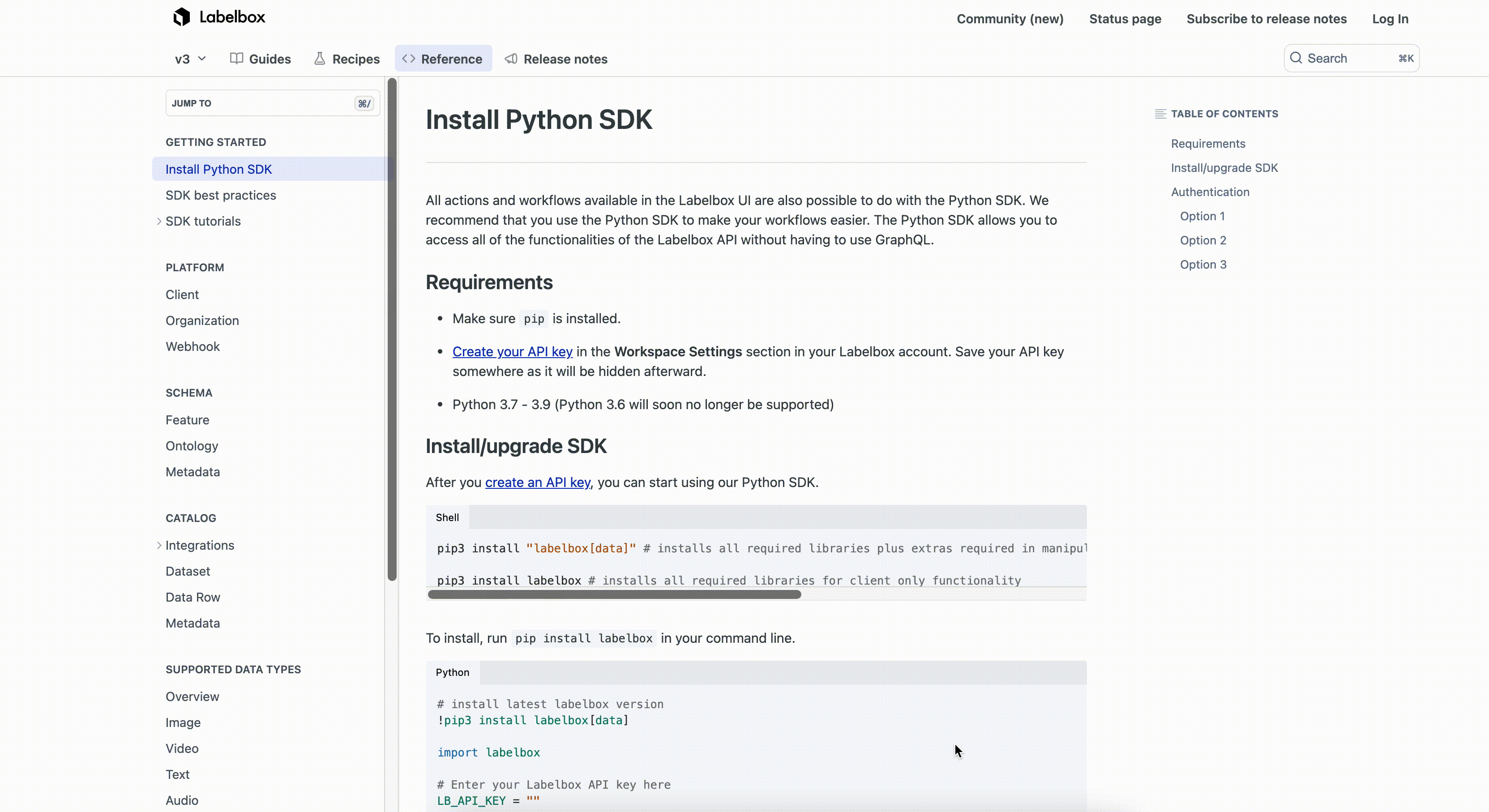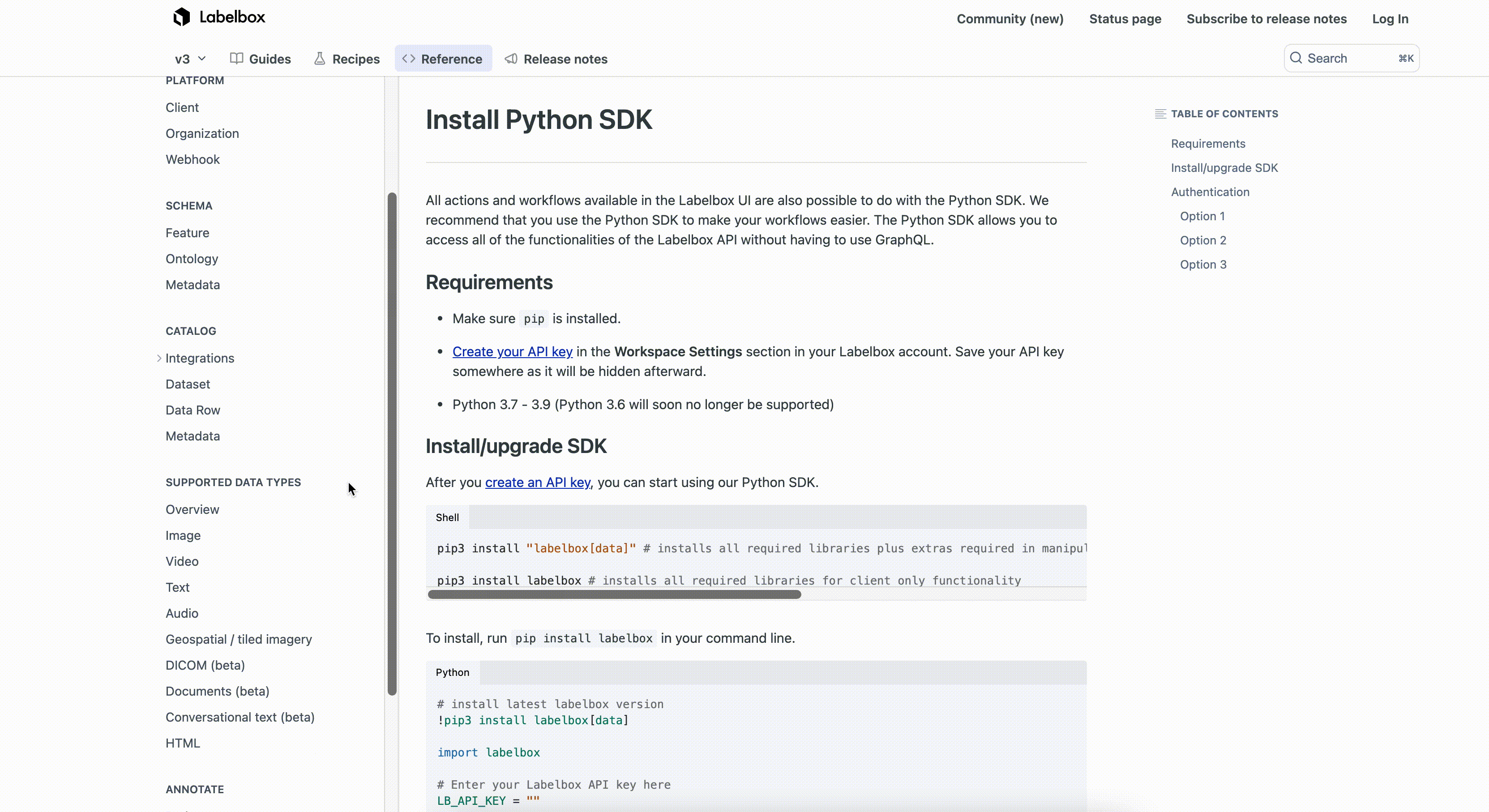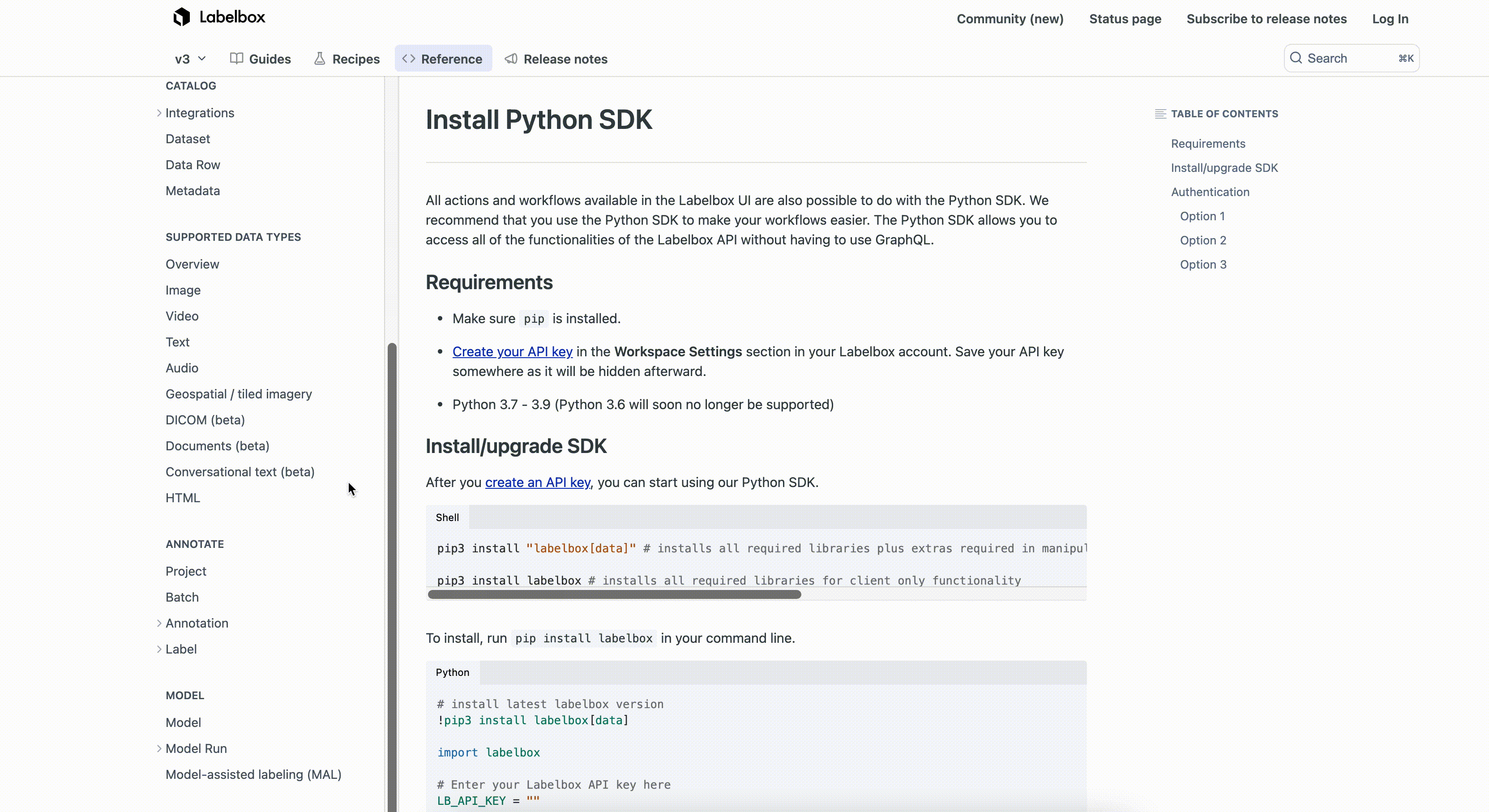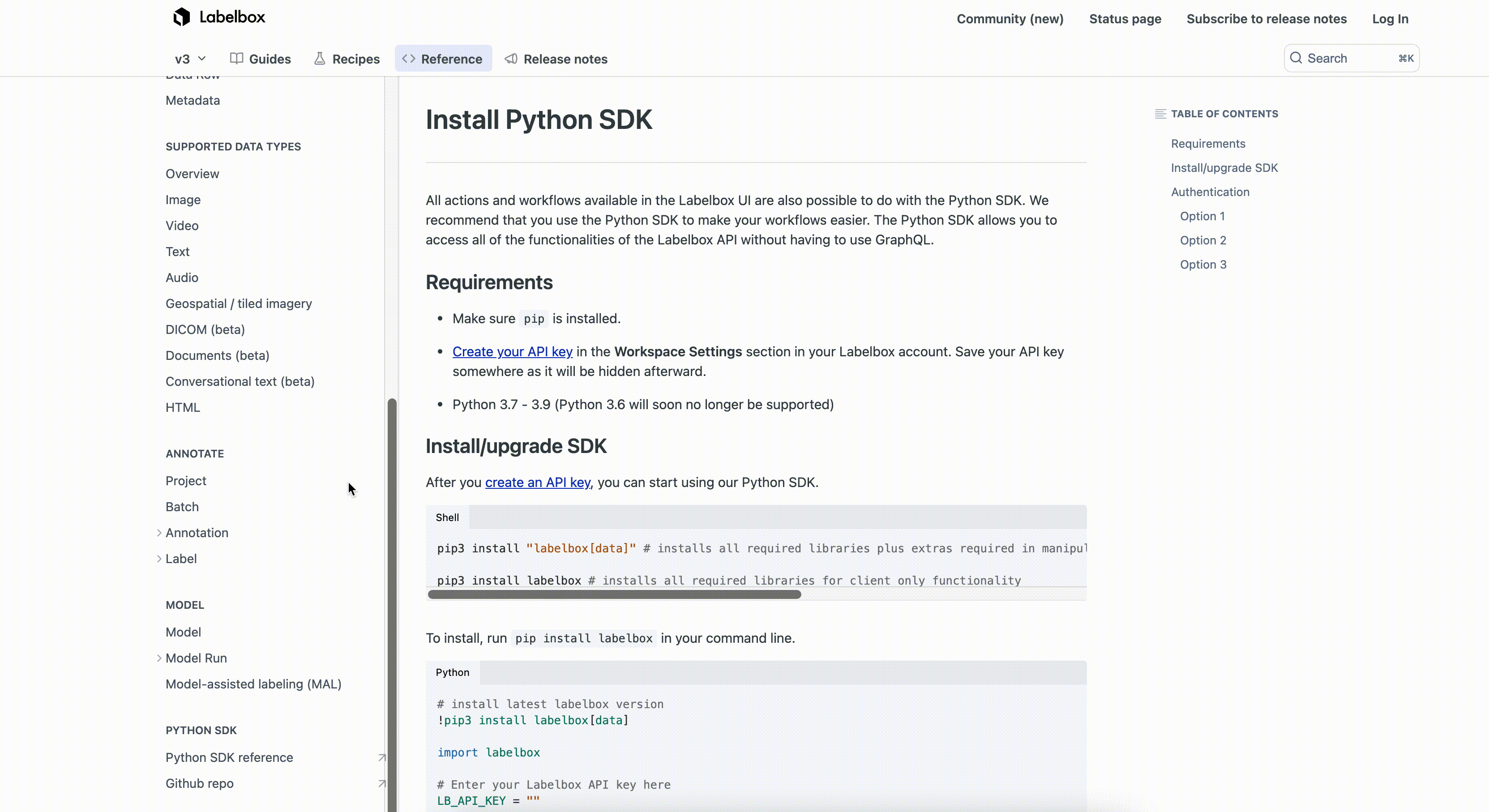
The new reference page is organized by product areas, key concepts, and modules in our API (such as Project, Webhook, Data row, MAL, etc.). Teams can now access code examples and major workflows across all Labelbox solutions, including Annotate, Model, Catalog, Python SDK, and more.
If you have any questions on workflows or want to learn more about Labelbox best practices, be sure to check out our Labelbox Community page.
Product Spotlight
Learn about how teams are using our products to achieve breakthroughs.
Our model-assisted labeling workflow imports model output (from either an off the shelf algorithm, a previous version of the model in training, or another model built by the ML team, depending on the use case) into the platform as pre-labeled data, which labelers can easily correct and edit rather than label from scratch.
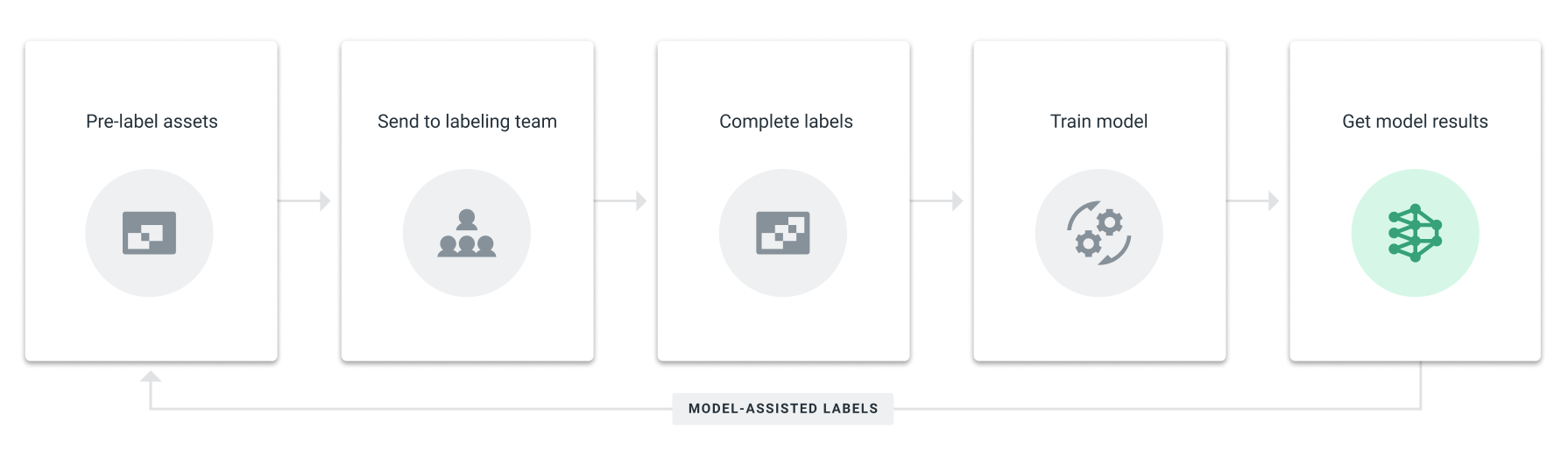
One of our customers, VirtuSense, uses pre-labeling as a key component of their data engine to increase the amount of labels created by 5x. Their data is pre-labeled by a purpose-built model and programmatically imported into Labelbox through the Python SDK.
“Out of all the platforms we explored, Labelbox is the easiest to use and the best for managing labelers, workflows and monitoring performance...From a thousand-foot view, it looks like an AI labeling engine, which feeds into the deep learning system and spits out trained networks.” - Deepak Gaddipati, Founder & CTO of VirtuSense
Learn more about VirtuSense’s use case and how they use automation in our case study.


