×![]()

 All blog posts
All blog postsLabelbox•June 23, 2022
Optimize the efficiency and quality of your training data with our newest features

We’ve focused recent product development on updates to help users better optimize the throughput, efficiency, and quality of their training data production. You can now more powerfully search for data rows within a project, visualize ground truth and predictions within Catalog, and easily import pre-labeled NER text datasets through our SDK. To help you cut labeling costs and get started faster, we’ve launched our new image auto-segmentation tool that generates quality segmentation masks in a fraction of the time.
Data Row tab update
Our continued work on the Data Rows tab experience is part of our broader push toward data row centricity, which is designed to give you more freedom, more control, and additional ways to automate elements of your labeling operations.
We've started to roll out several major updates to the Data Row tab experience. You can expect to see the following updates by early July:
- A powerful new search experience that lets you filter and search by specific attributes. If you’ve used the search function in Catalog, this new feature will feel very familiar.
- Overall performance improvements, including better performance on longer running queries.
- Flexible querying that allows for combinations of logical operations in searching such as AND or OR.
- Coming soon: integration of data row status with multi-step reviews.
Visualize ground truths and predictions in Catalog
You can now quickly make sense of your data’s annotations and predictions, and easily spot discrepancies between ground truth and prediction overlays in Catalog.
Ground truth predictions are annotations generated by a human labeler or that are imported to a project using the SDK, whereas predictions are uploaded via a Model Run, through our SDK. We’ve made data exploration and model error identification even easier and more powerful in Catalog. At a glance, you can now visualize ground truth and prediction overlays in both our thumbnail and detailed view.
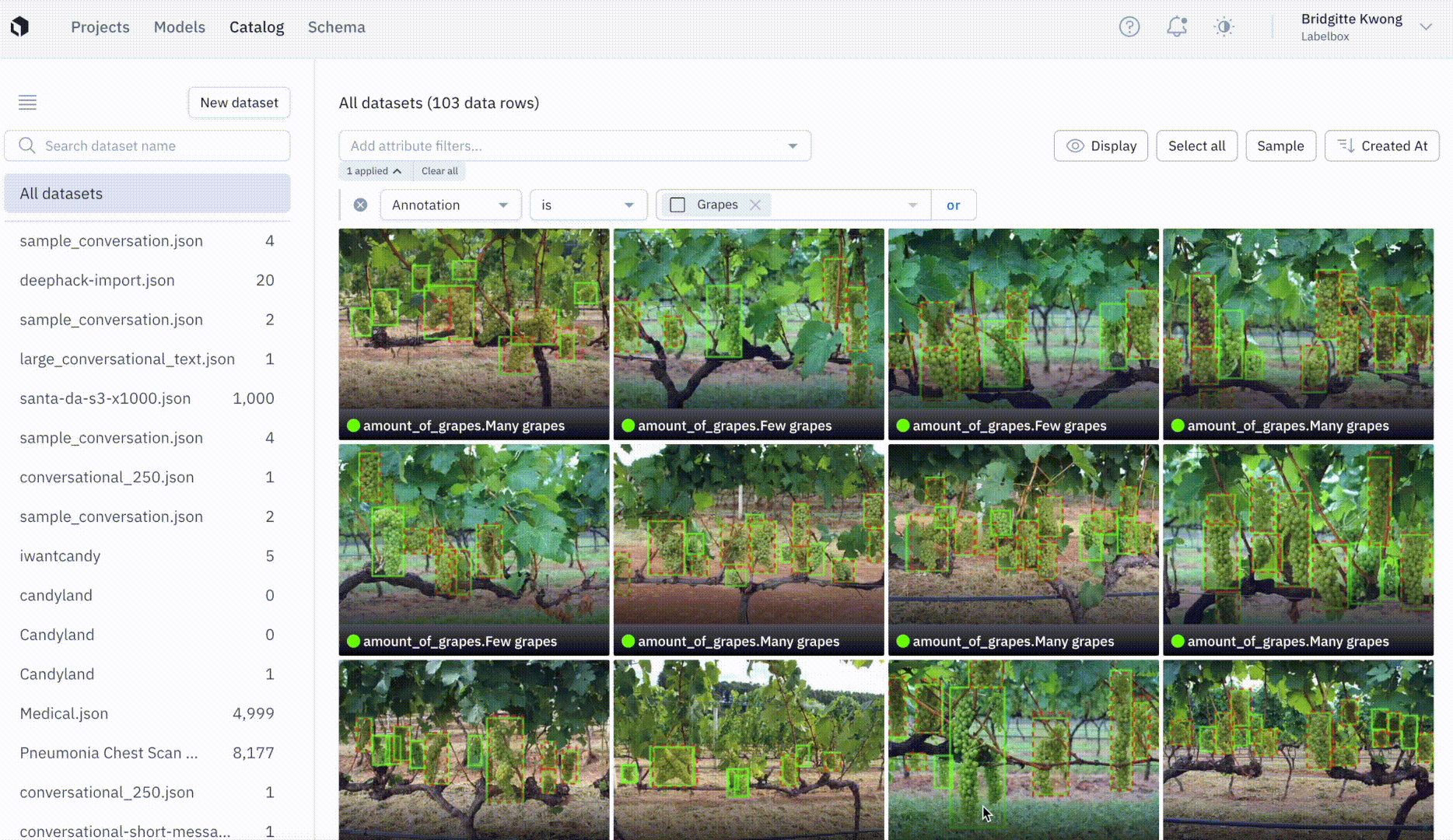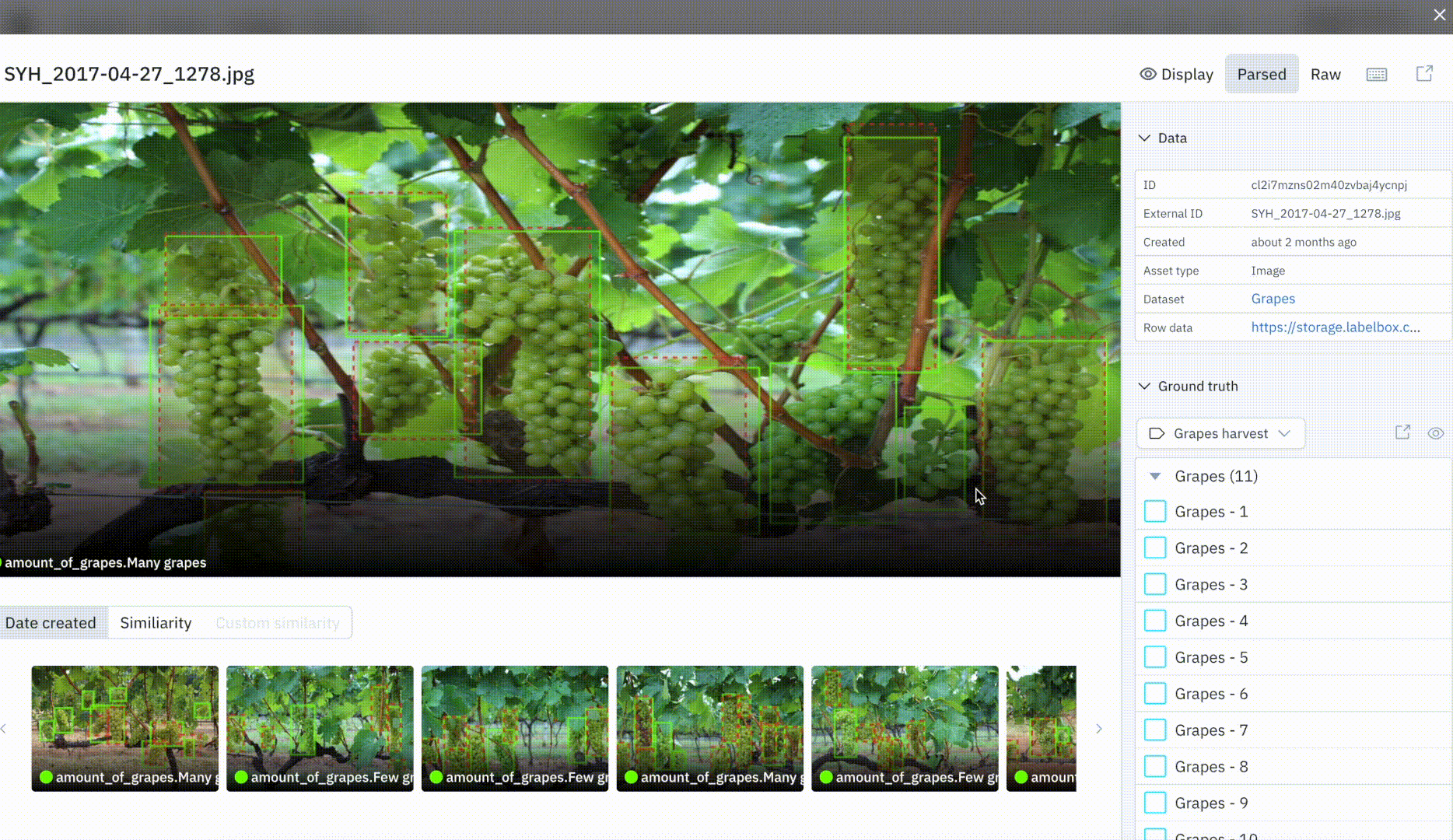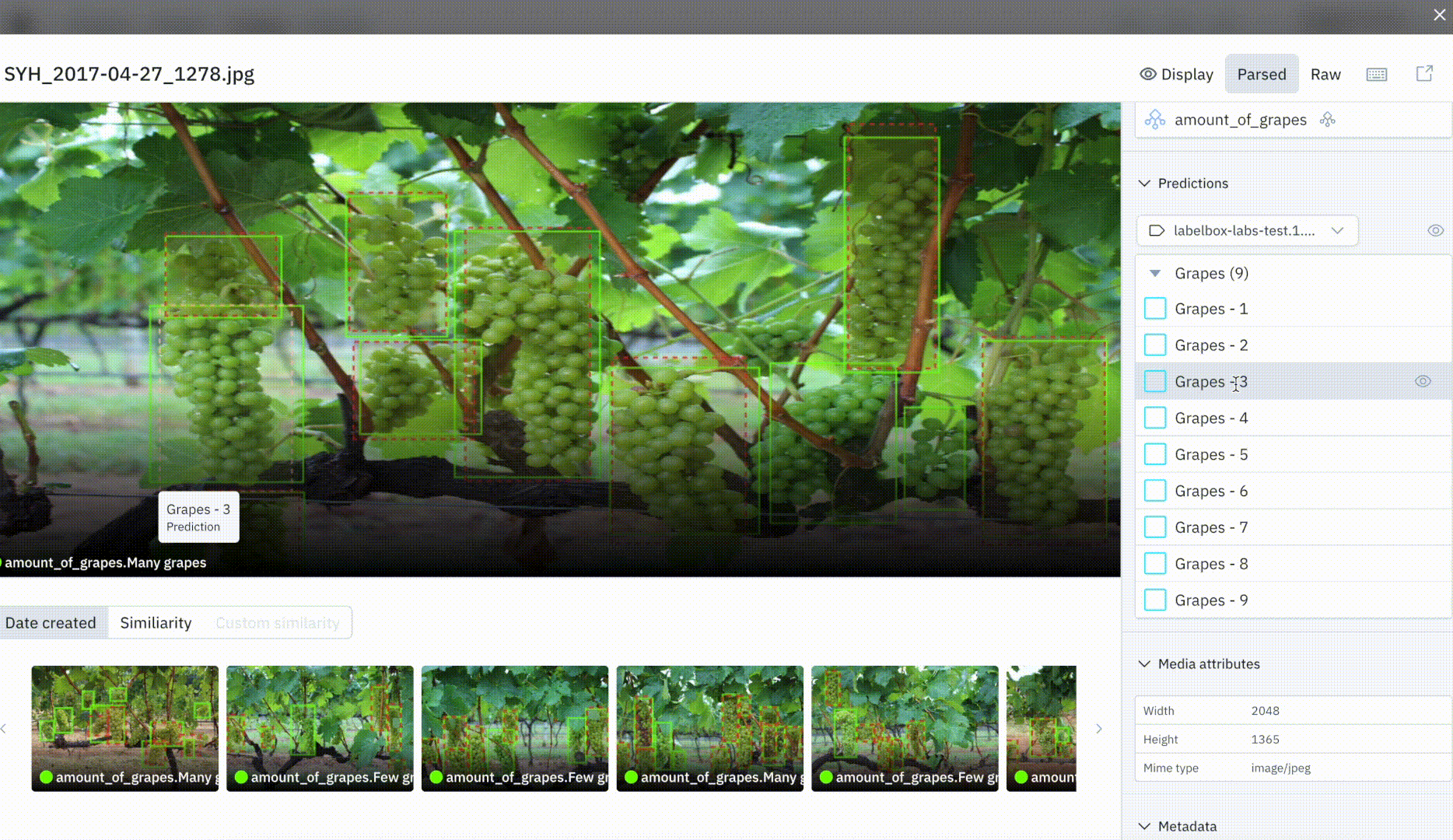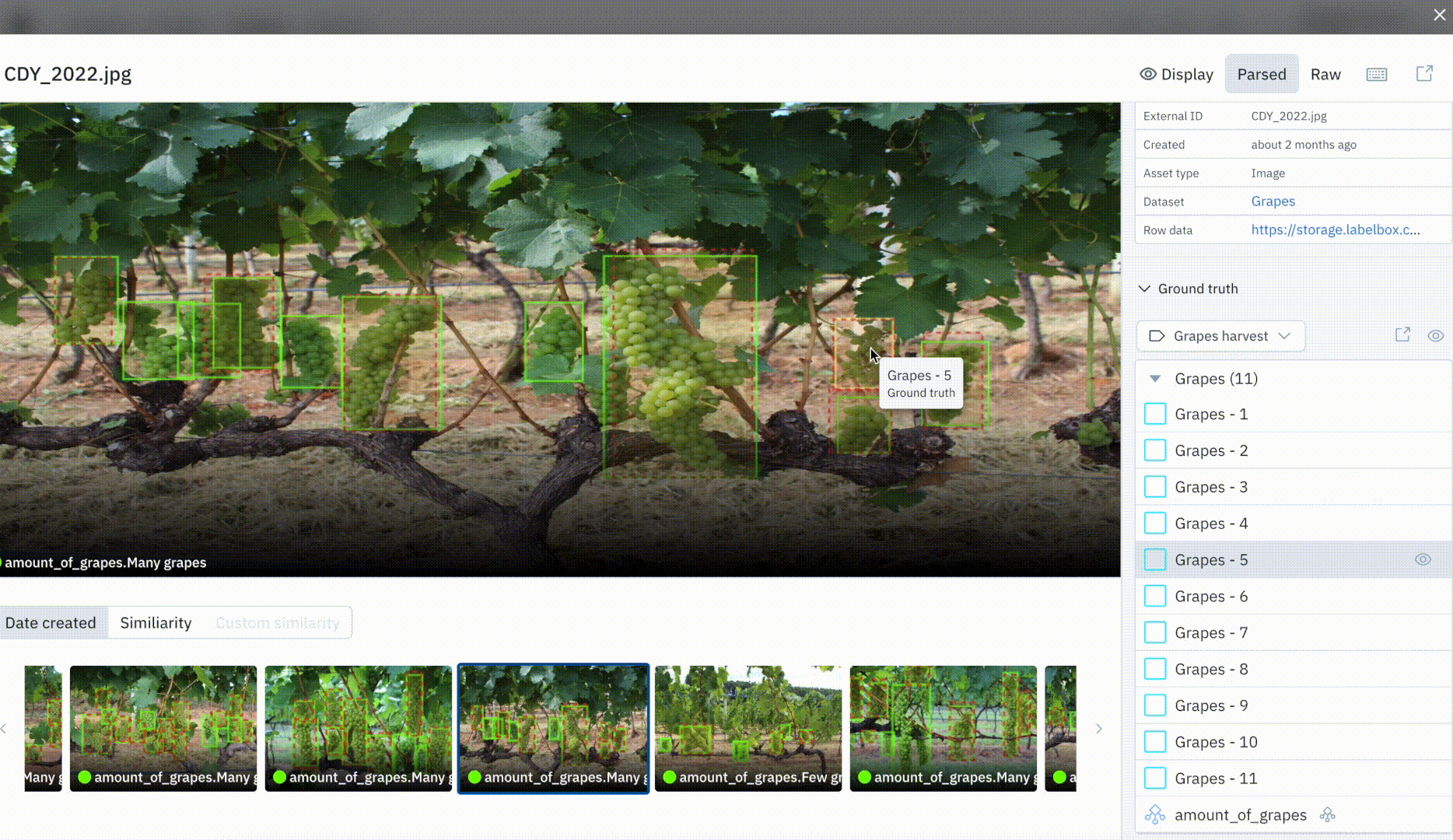
We now show ground truth and prediction overlays for the following data and annotation types:
Images and Tiled Imagery
Global Classification
- Radio input
- Checklist input
Objects
- Bounding Boxes
- Polygons
- Polylines
- Points
Text
Global classification
- Radio input
- Checklist input
Along with being able to easily visualize data in Catalog, you can customize your view in Catalog to quickly sort and find your data. You can now control:
- Thumbnail sizes in Catalog
- Whether or not to show ground truth
- Whether or not to show predictions
- The color scheme of ground truth & predictions
- The grayscale of images
Easily import a labeled text dataset through our Python SDK
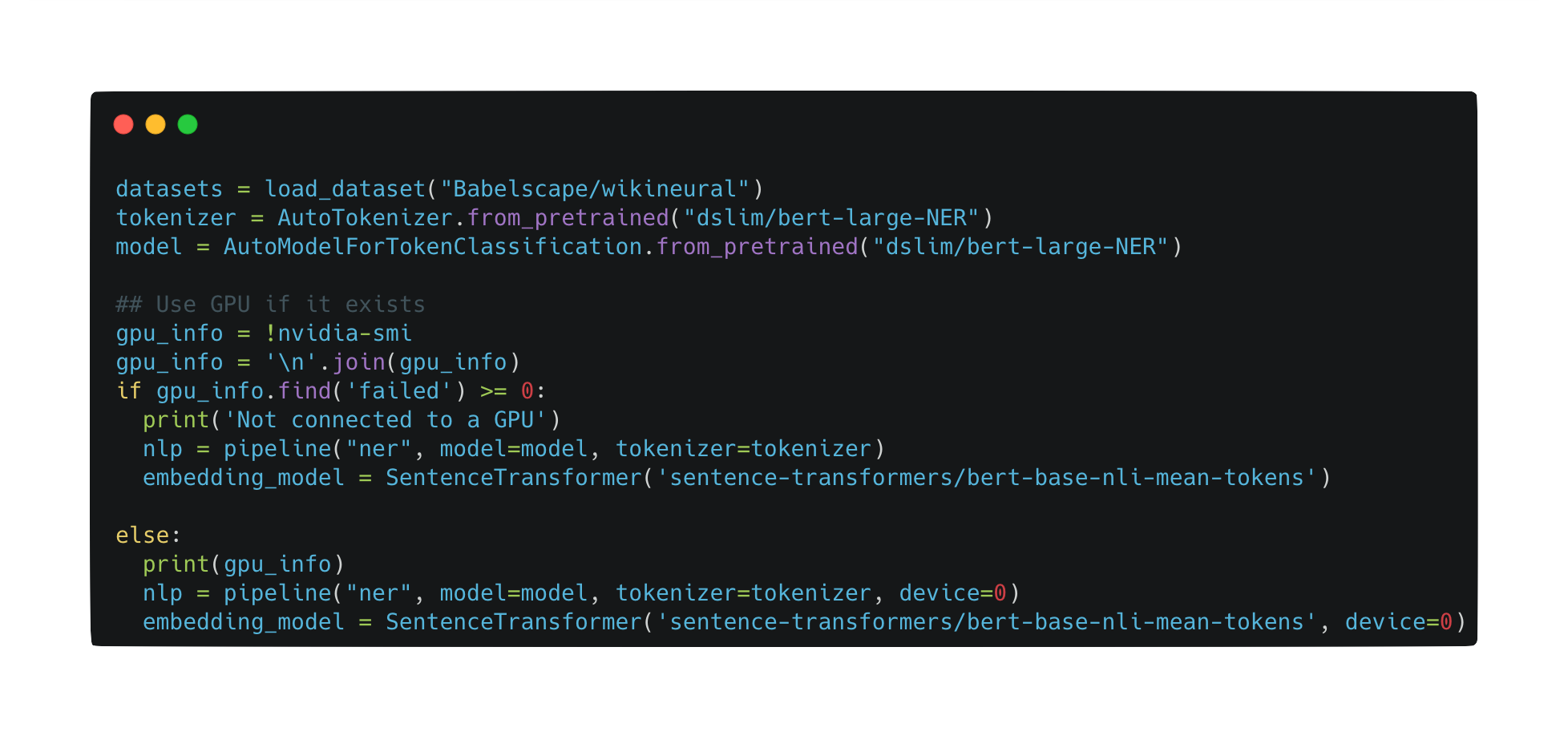
Rather than having to label from scratch, we’ve made it easy for users to import a labeled text dataset through our Python SDK. Follow our end-to-end code tutorial to import a pre-labeled NER text dataset using the Hugging Face BERT transformer model.
With our tutorial, you can use the Hugging Face BERT model to:
- Generate NER predictions
- Generate sentence embeddings
- Create a dataset in Labelbox
- Import model predictions, custom metadata, and model predictions as ground truth
Learn more about importing a labeled text dataset via Hugging Face in our documentation. If you’re interested in learning how to import a labeled image dataset, feel free to refer to this tutorial.
Editor Updates
Reduce labeling time and cost with our image auto-segmentation tool

Automating parts of your labeling workflow is a key component to getting better data, faster. Teams may look for labeling automation strategies to help reduce labeling time and effort, including editor-assisted ML powered tools. You can now use our auto-segmentation tool to quickly generate quality segmentation masks in a fraction of the time.
While all teams can use our auto-segmentation tool to jump-start their labeling and reduce labeling time and cost, ML teams that import predictions from their own model or an open-source model make labeling easier, more accurate, and faster as they iterate. Using your own model or a model of your choice to pre-label your data can be helpful in cases where our auto-segmentation tool might not work as well, such as with rare datasets.
Watch the demo below to see our auto-segmentation tool in action!
The image auto-segmentation tool will be available for all users in the near future. To make our tool even better, we welcome your feedback and input on any areas of low performance.


