×![]()

 All blog posts
All blog postsLabelbox•November 17, 2021
Labelbox November updates

If you tuned in to our annual flagship event, Labelbox Accelerate, you’ll know that Labelbox is a platform designed to improve your ML iteration loop. The ability to annotate data, diagnose model performance, and prioritize data based on your results are key to building a performant model.
As customer use cases become more complex, we recognize the need for more robust annotation capabilities. Over the past few months, we have focused product development in three key areas: supporting more data types, building new annotation tools, and creating improved project workflows. Designed to give you the right annotation tools for every task, here are some key new features coming to Labelbox.
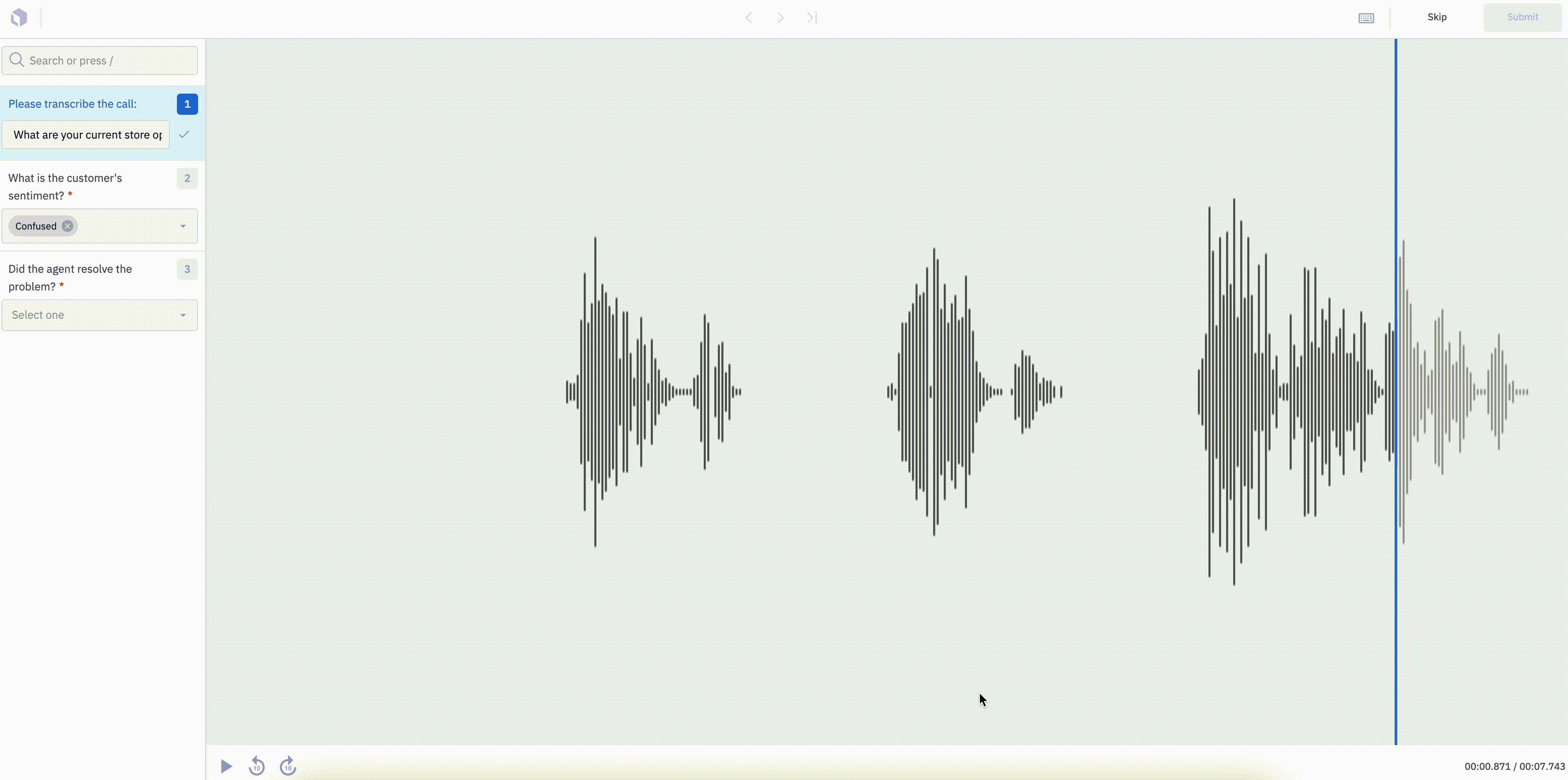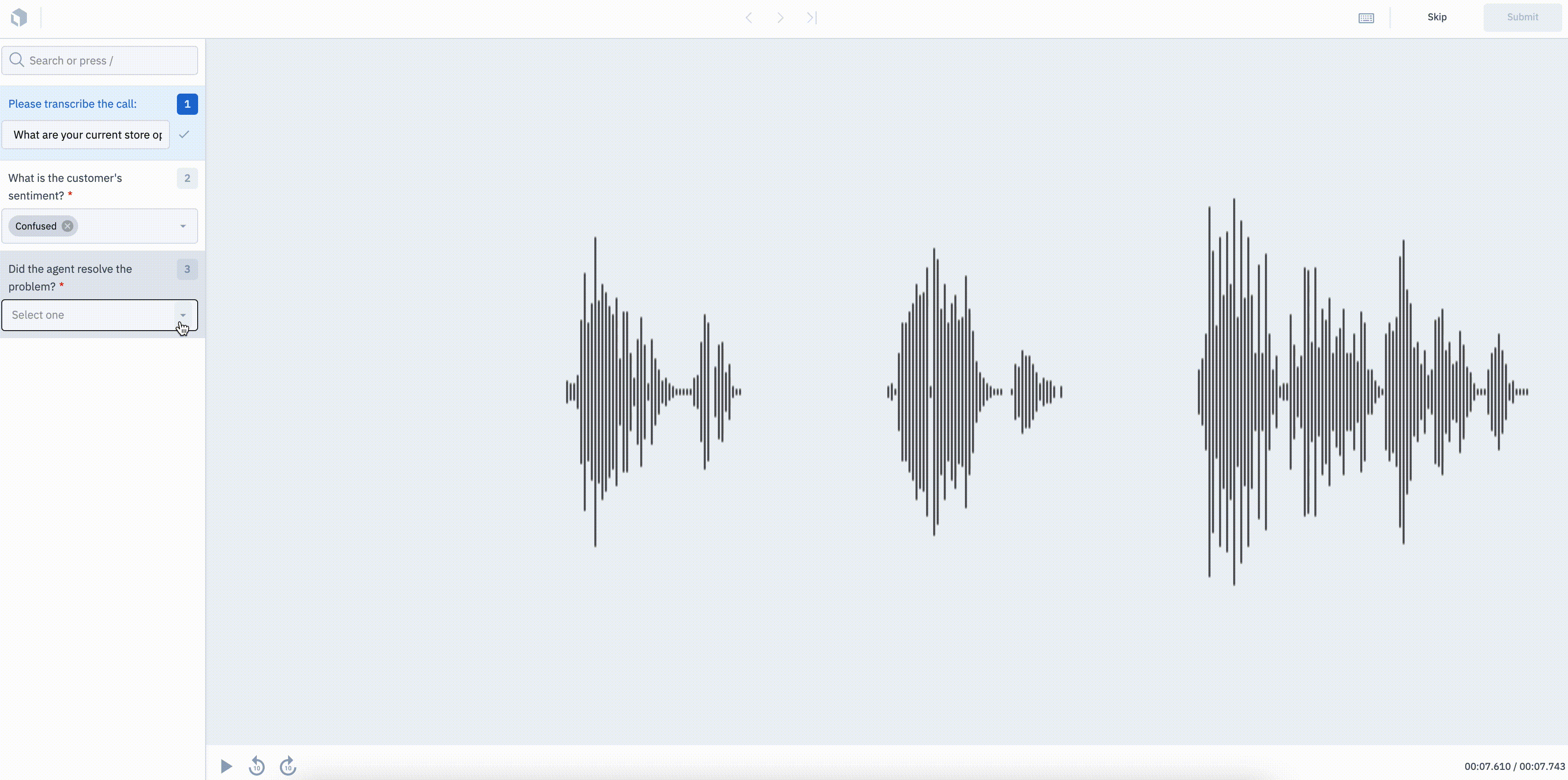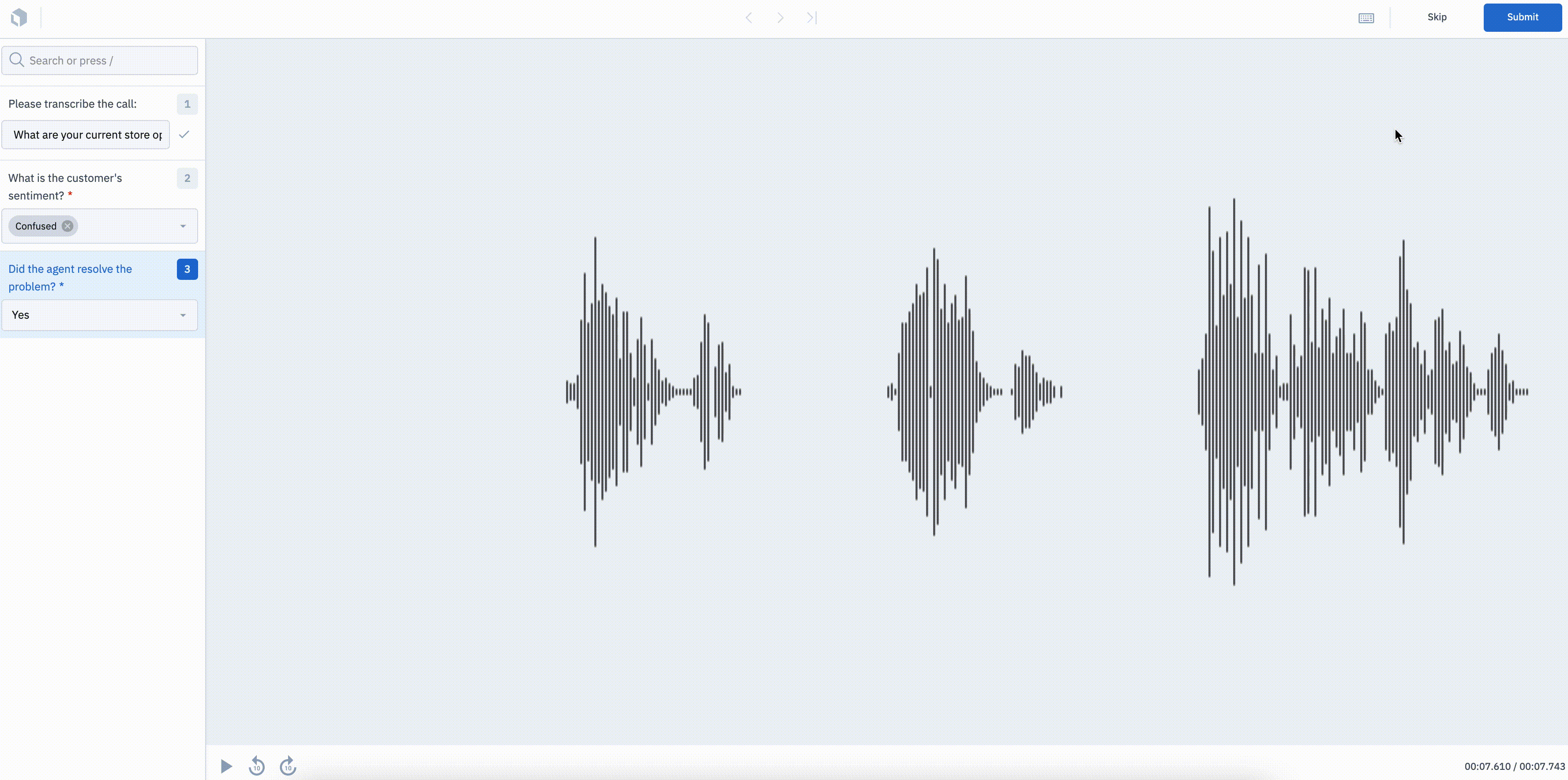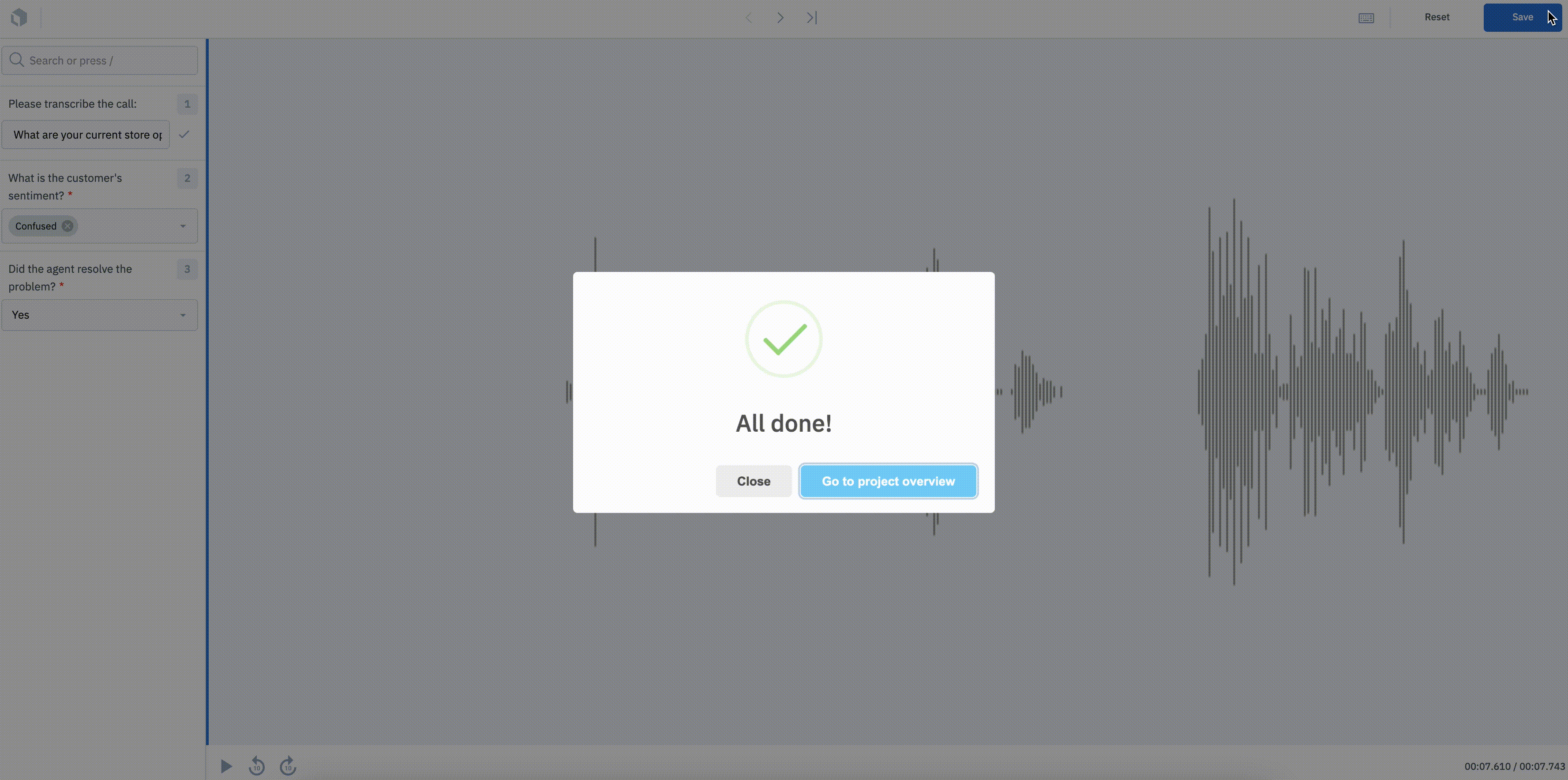
Turn your audio files into insights
We’re excited to announce that you can now classify and transcribe audio files in Labelbox.
You can use our new audio editor to turn raw audio files into structured data. Key use cases include identifying sentiment, transcribing short audio clips, evaluating the quality of audio, and more. The current version of our audio editor supports global classification types for audio files (MP3, WAV, M4A).
Supported annotation types (at the asset level) include:
- Radio classification
- Checklist classification
- Free-form text classification
- Dropdown classification
Learn more about our new audio editor in our documentation.
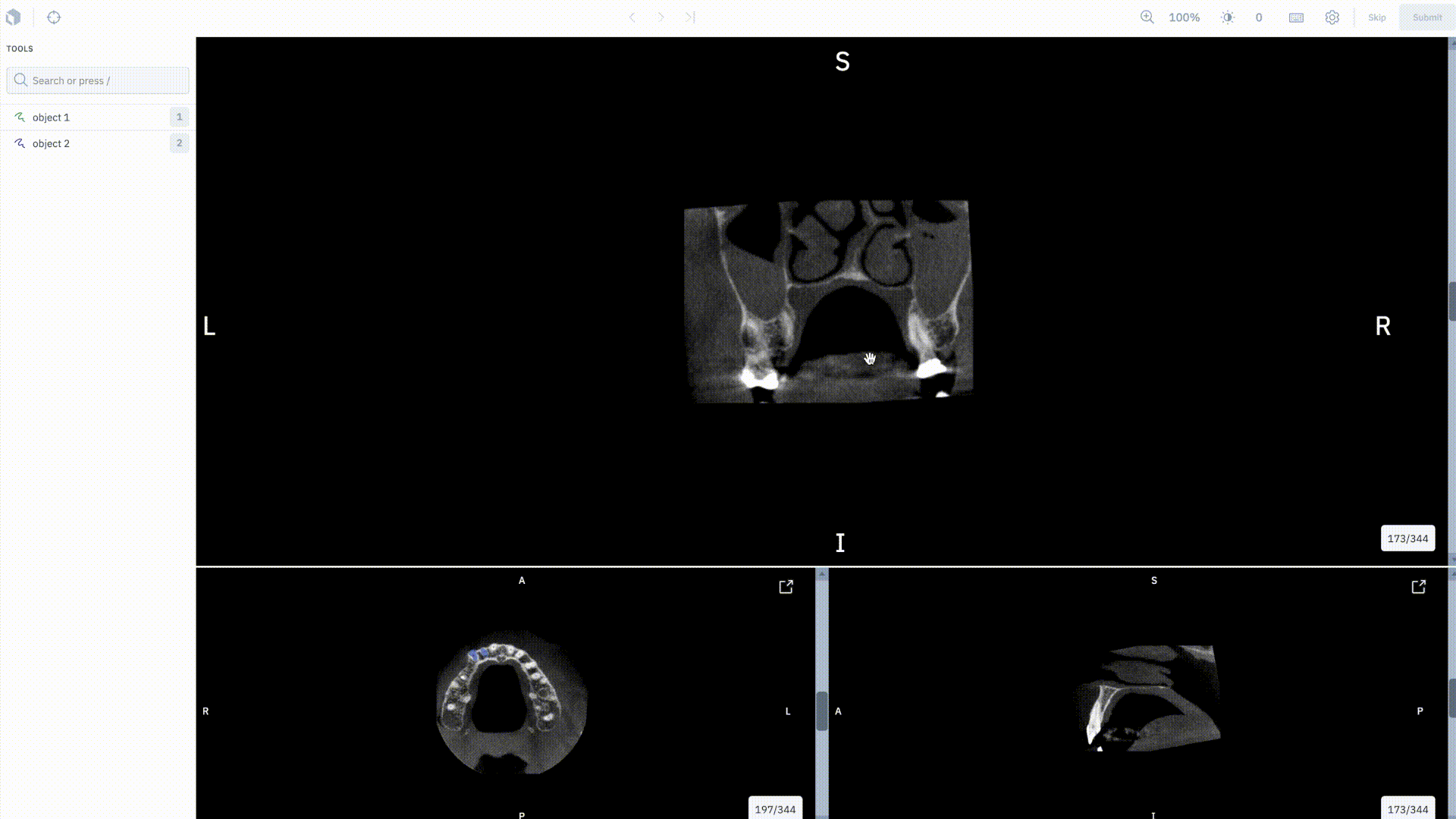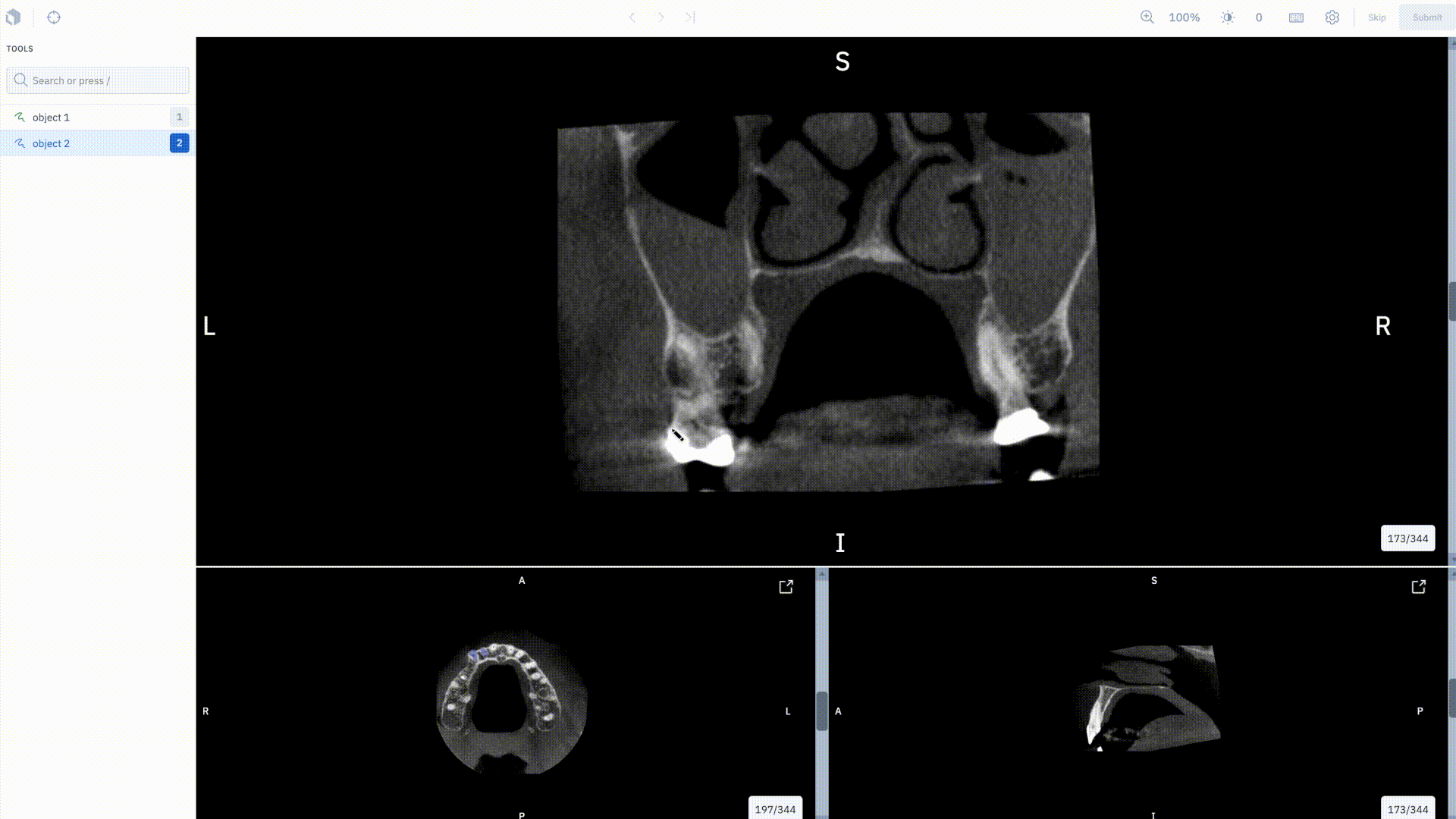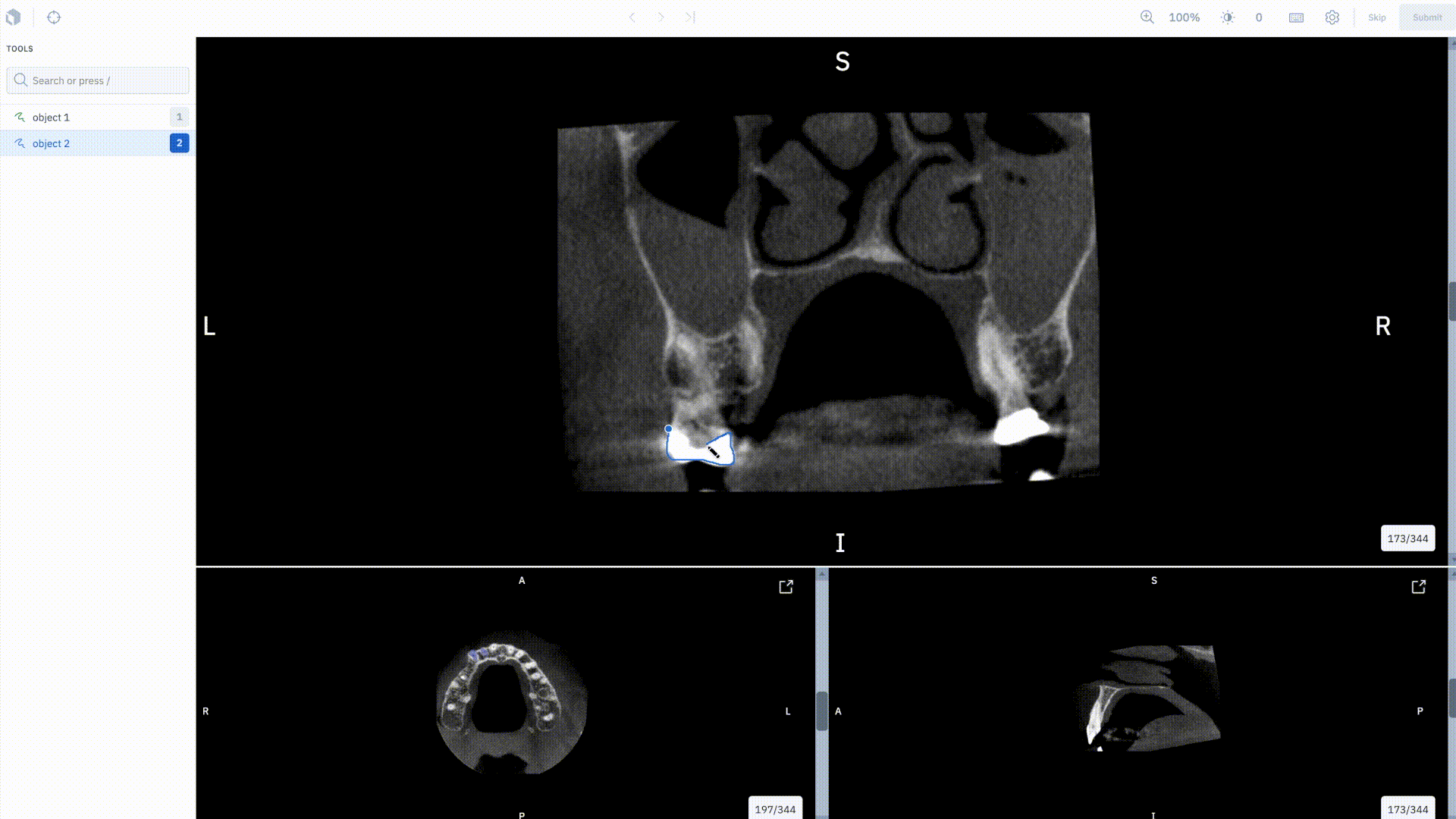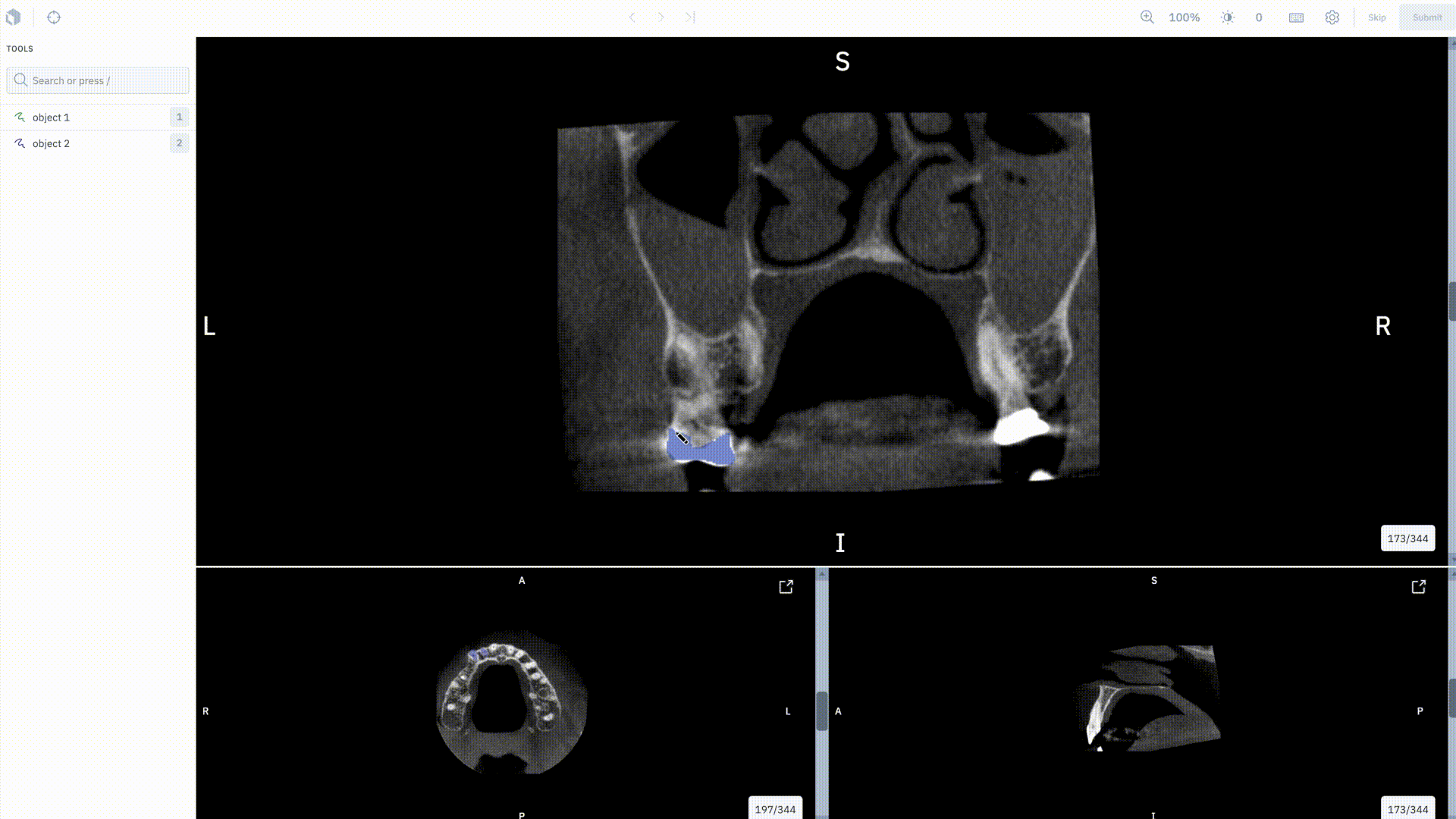
Unlock new use cases in medical imagery
We’re thrilled to be adding support for native medical imagery data types in Labelbox, starting with our upcoming DICOM editor.
With the DICOM editor, users will be able to annotate a study of images together in a single experience using volumetric annotations. Specifically, you can:
• Natively upload DICOM imagery
• Import current DICOM imagery to be corrected or verified by labelers
• Create segmentation masks on DICOM imagery
• Train ML models using the segmentation masks created in the editor
If you’re interested, sign up for our closed beta.

Preserve and label data with native PDF support
While we’ve witnessed huge growth in the number of text annotations in our platform, customers are eager for a way to annotate text within the context of other data. We’re excited to be rolling out the ability to expand your text capabilities by importing PDFs natively from your data buckets and into our new PDF editor.
With this new update, you will be able to turn your data stored as PDFs (research papers, articles, marketing flyers, and other PDF files with images or charts) into useful annotated data for ML applications. You will be able to take advantage of our suite of object annotation tools for data extraction and OCR pattern recognition use cases.
If you’re interested, sign up for our closed beta.
Be more precise with video segmentation
In addition to our three new editors, we’re happy to introduce our upcoming video segmentation tool for use cases that require a finer level of pixel detail annotation.
Prior to this update, users could only track objects of interest in video with bounding boxes, polylines, and key points. However, for those interested in training their model to recognize objects or concepts with an organic shape, users can now use our video segmentation tool to intuitively and accurately segment individual high-value frames, or the best example of an object or concept in a video.
If you’re interested, sign up for our closed beta or read more in our documentation.
Speed up your workflow with our updated Data Row Browser
Labelbox has also made some recent enhancements to our workflow. Our activity table is now data row centric, so users can quickly and easily search for relevant data and labels within their projects.
We’ve also updated our label browser to deliver a more intuitive way to interact with, manage, and review your data. Users can quickly search for a data row to review and navigate through data in a way that works for their team.
Our new Data Row Browser makes it easy for users to review annotations within Labelbox. You can now:
- Update the status of a labeled data row via “approve” or “reject” buttons
- Make intentional changes to annotations with our new “edit” button, preventing unwanted or accidental changes
- For convenience, the new label browser automatically groups Benchmark and Consensus labels together in the browser.
Learn more about the Data Row Browser in our documentation.
Improved support for Active Learning workflows
- Upload custom metadata for more powerful search and filter: You can now store custom metadata related to data rows in Labelbox, enabling you to more powerfully search for and filter data in labeling projects, Catalog, and Model Diagnostics. Create custom metadata fields in the Schema page and upload metadata via the Python SDK.
- Use labeling functions to programmatically tag data rows: Automatically label similar data programmatically based on model embeddings. Find related data rows using Similarity Search and then create a function that will automatically apply a label to all similar data rows so you can search, filter, and add them to a labeling project all from Catalog. In Catalog, you can filter data rows by the similarity score computed by your functions. Scores closer to 1 indicate greater similarity. Learn more in our documentation.
Other improvements
- Manage ontologies and features through the app: We’ve introduced a new UI for creating and managing ontologies and features. You can now create and edit universal ontologies and features through the UI or by uploading an ontology JSON file. When creating a project you can select the appropriate ontology from your ontology library, helping ensure all your data is labeled consistently across projects. Learn more in our documentation or go to the Schema tab.
- Import previously generated ground truth through the API: You can now easily import ground truth annotations into Labelbox for further refinement, reuse, or consolidation. Most teams, whether they’re migrating to Labelbox from another platform or service or have a separate workflow that generates labeled data, want to have all their labeled data in one place. Using the import API makes it easier than ever to use Labelbox as your central repository and source of truth for all labeled data. Learn more in our documentation.


