
 All blog posts
All blog postsManu Sharma•March 21, 2023
Make your videos queryable using foundation models
In this tutorial, I'll demonstrate how easy it is to enrich all of your video content with foundation models to perform tasks such as:
- Searching a wide range video content for specific types of videos
- Understand the nature of video content within your data lake
- Explore videos that contain specific keywords, or talk about a topic, or appear similar to some other videos
- Select data that will improve your ML models, because it is rare or shown as an edge-case scenario
- Apply zero/few shot learning and weak supervision to label your data
For this post, I utilized the most recent foundation models provided by OpenAI, Meta and Hugging Face to analyze and enrich a series of videos. Labelbox Catalog is used as the data platform to store all the metadata, search across metadata and embedding space, as well as perform zero shot classification.
Easily search videos by combining foundation models with Labelbox Catalog
Videos are complex data structures that consist of a sequence of frames that are composed of many pixels. This complexity makes it challenging to develop efficient search algorithms that can quickly and accurately locate specific content within a video.
Additionally, due to variability in content, videos can vary significantly in terms of their content, making it challenging to develop search algorithms that work across different types of videos. For example, searching for a specific object or event within a sports highlight video may require a different approach than searching for the same object or event within a security camera footage. For object or scene detection, one obvious approach is to chunk the video into smaller pieces, downsample the video, generate and index inferences at frame level. However, various use cases just require global video level understanding (e.g. Instagram or Youtube shorts).
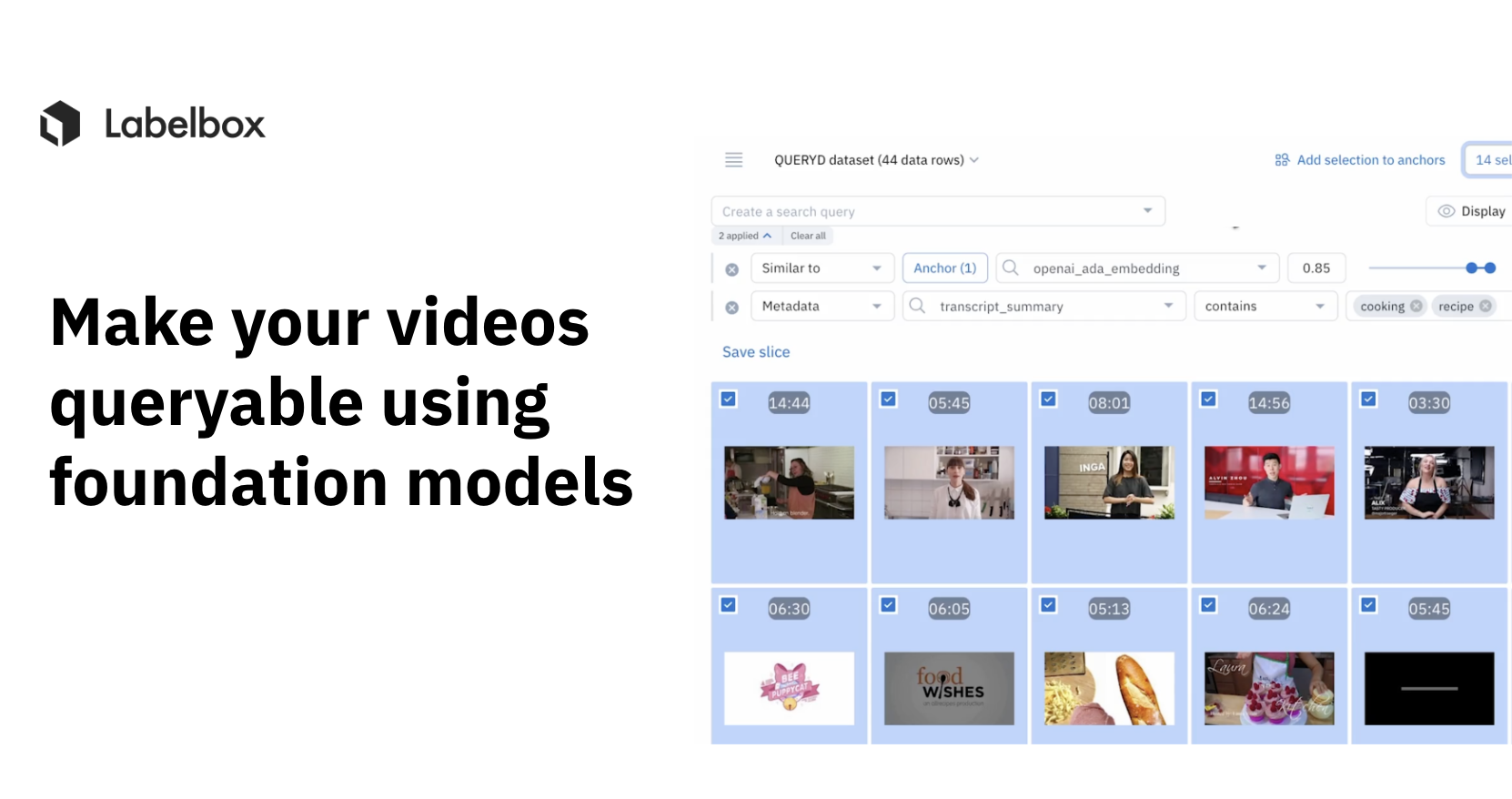
Let’s get started and take a look at how it works on a few real-world examples. For starters, I'll walk through how you can find cooking videos quickly by searching for text related to cooking or recipe in the transcript summary and combining this with foundation models.
1) Prepare and understand data
I found the QUERYD dataset that contains a curated list of youtube videos. To understand what kind of videos they were, I downloaded the these videos and imported them into Labelbox Catalog.
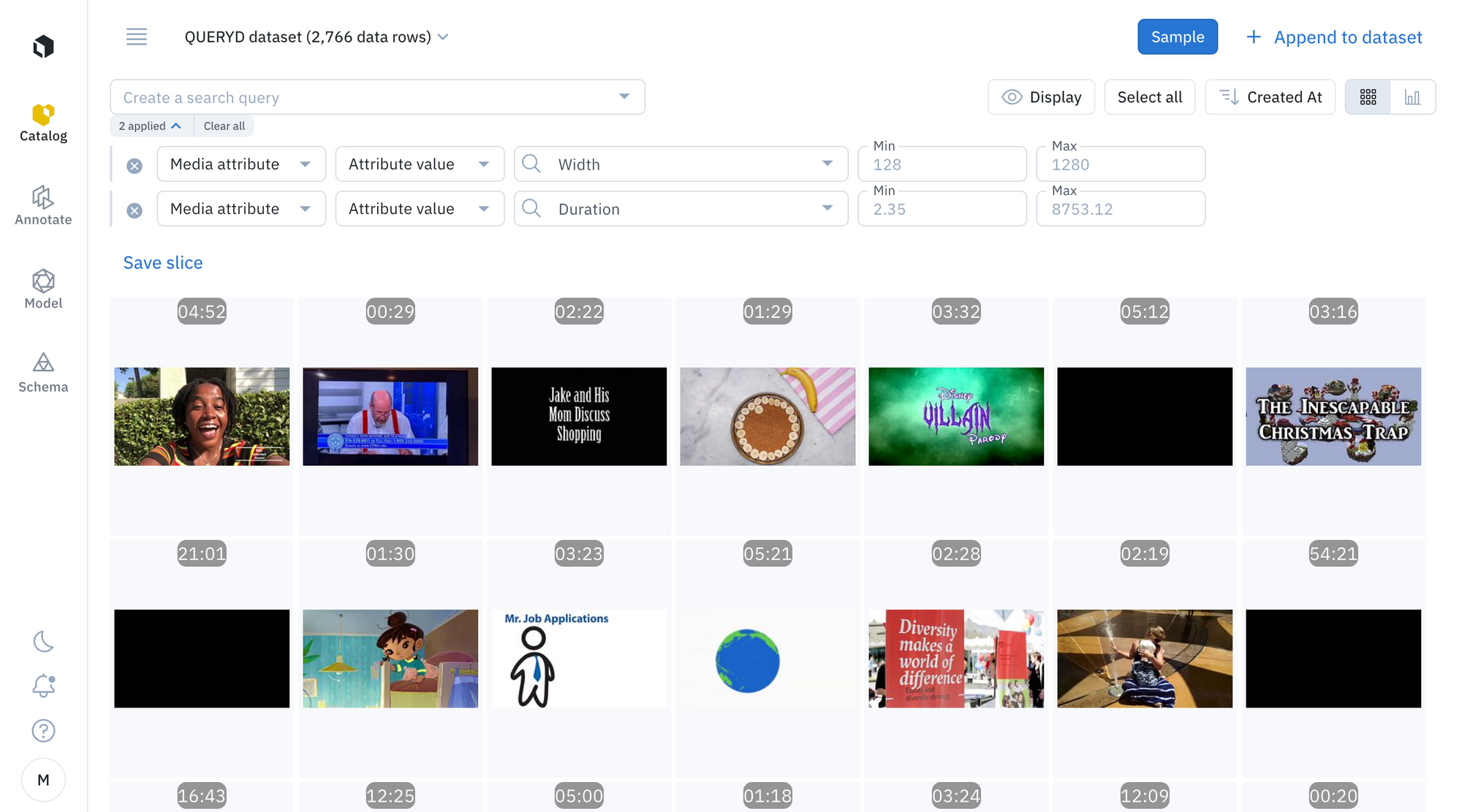
A few initial observations from my dataset:
- Most videos are less than 900 seconds in duration.
- The video content has a high degree of variation from podcasts, sports to cooking. Although these are common topics, widely available over internet.
- Most videos have both audio and voice.
2) Select AI models to generate insights
Based on the preliminary understanding of the data, I chose the following foundation models to generate metadata in order to make the videos queryable.
- OpenAI Whisper for video transcription
Whisper is an automatic speech recognition (ASR) system trained on 680,000 hours of multilingual and multitask supervised data collected from the web. It enables transcription in multiple languages, as well as translation from those languages into English
- OpenAI GPT 3.5 for summarizing transcription
OpenAI's GPT-3.5 model is a language model that can perform a wide range of natural language processing tasks including summarization, language generation, translation, question-answering, text completion and more.
- OpenAI Generation 2 embeddings for similarity search
Released in December 2022, the latest generation of embedding model by OpenAI, text-embedding-ada-002, replaces five separate models for text search, text similarity, and code search, and outperforms the previous most capable model, Davinci, at most tasks, while being priced 99.8% lower.
- TimeSformer by Facebook for zero shot video classification
TimeSformer is a video processing model developed by Facebook AI Research (FAIR) and Meta (formerly Facebook Reality Labs) that can analyze and understand video data. TimeSformer model pre-trained on Kinetics-400. It was introduced in the paper TimeSformer: Is Space-Time Attention All You Need for Video Understanding? by Tong et al. and first released in this repository.
- Sentence-transformers/All-mpnet-base-v2 for text similarity search
This is a sentence-transformers model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
3) Generate metadata and embeddings
Below are the python functions to call OpenAI APIs to transcribe audio, summarize text and generate embeddings.
@retry(wait=wait_random(min=1, max=5), stop=stop_after_attempt(3))
def ask_gpt(prompt):
try:
response = openai.Completion.create(
model="text-davinci-003",
prompt="Summarize this in a short paragraph:\n {}".format(prompt),
temperature=0.7,
max_tokens=64,
top_p=1.0,
frequency_penalty=0.0,
presence_penalty=0.0
)
transcript_summary = response.choices[0].text
return transcript_summary
except Exception as e:
print(e)
raise(e)
@retry(wait=wait_random(min=1, max=5), stop=stop_after_attempt(5))
def ask_whisper(mp3_file):
try:
audio_file = open(mp3_file, "rb")
transcript = openai.Audio.transcribe("whisper-1", audio_file)
transcript_text = transcript.text
return transcript_text
except Exception as e:
print(e)
raise(e)
@retry(wait=wait_random(min=1, max=5), stop=stop_after_attempt(5))
def embed_text(text):
try:
e = openai.Embedding.create(
model = "text-embedding-ada-002",
input = text
)
embeddings = []
for item in e.data:
embeddings.append(item.embedding)
return embeddings
except Exception as e:
print(e)
raise(e)Here’s a code snippet to generate inferences using Timesformer model on a local machine with a GPU using HuggingFace.
def predict_video_action(video_file):
try:
container = av.open(video_file, "rb")
indices = sample_frame_indices(clip_len=60, frame_sample_rate=1, seg_len=container.streams.video[0].frames)
video = read_video_pyav(container, indices)
inputs = video_processor(list(video), return_tensors="pt").to("cuda:0")
with torch.no_grad():
outputs = video_model(**inputs)
logits = outputs.logits
predicted_class_idx = logits.argmax(-1).item()
video_classification = video_model.config.id2label[predicted_class_idx]
except Exception as e:
print(e)
device = "cuda:0" if torch.cuda.is_available() else "cpu"
video_processor = AutoImageProcessor.from_pretrained("facebook/timesformer-base-finetuned-k400")
video_model = TimesformerForVideoClassification.from_pretrained("facebook/timesformer-base-finetuned-k400")
video_model = video_model.to(device)Now we process all of the videos and call the functions above to generate metadata.
for datarow in dataset:
try:
### Transcribe the audio
transcript_text = ask_whisper(mp3_file)
### Ask GPT to summarize the transcription
transcript_summary = ask_gpt(transcript_text)
### Generate embedding on raw transcription
embedding = embed_text(transcript_text)
### Timesformer video action recognition
video_action = predict_video_action(video_file)
data_rows.append({
"row_data": video_url,
"global_key": global_key,
"metadata_fields": [
{"name": transcript_schema.name, "value": transcript_text},
{"name": transcript_summary_schema.name, "value": transcript_summary},
{"name": video_classification_schema.name, "value": video_action}
],
"attachments": [{
"type": "TEXT",
"value": transcript_text
}]
})
text_embeddings.append({"id": global_key, "vector": embedding})
except Exception as e:
print(e)
return None
Now we create a new dataset and import metadata generated above.
dataset = client.create_dataset(name = "QUERYD dataset")
task = dataset.create_data_rows(data_rows)
task.wait_till_done()
print(task.errors)Now we import embeddings using the code snippet below. (P.S. Python SDK support will be released soon)
openai_embedding_ndjson = list()
for i in tqdm(text_embeddings):
global_key = i["id"]
vector = i["vector"]
datarow_id = client.get_data_row_ids_for_global_keys(global_key)["results"][0]
openai_embedding_ndjson.append({"id": datarow_id, "vector": vector})
with open('openai_embedding.ndjson', 'w') as f:
ndjson.dump(openai_embedding_ndjson, f)
!advtool embeddings import cea4f70f-1d4a-4315-a4f7-0f1d4a131563 openai_embedding.ndjson
4) Explore your results
By leveraging foundation models, I am been able to take an initial video dataset and find a lot of potential interesting use cases, with a few examples included below for inspiration.
Finding cooking videos using metadata and embeddings
I can discover cooking videos from this dataset quickly by searching for cooking or recipe in the transcript summary. I found better results than just searching in the raw transcript text. The reason for this is because the raw transcript is summarized using GPT 3.5 model which is then subsequently used in its summary.
Fine tuning search query to generate better results
Finding videos about people associated with playing, games sports
Let’s try similarity search by embedding Timesformer outputs with all-mpnet-base-v2 transformer model.
Next, I'll demonstrate searching for text metadata generated by the Timesformer model.
Text search has one major limitation. The user has to imagine things to look for in words. It is surprisingly hard to come up with a comprehensive list of words that may describe a thing. Semantic search powered by embeddings provide an elegant solution. Here’s a demonstration of just this. Use text search to find positive examples and then use similarity search to find more stuff like the anchors.
Zero shot classification in Catalog
Zero-shot classification is a type of machine learning approach that allows a model to recognize and classify objects or concepts that it has never seen before. Labelbox provides an intuitive and effective way to perform zero shot classification with an integrated human in the loop workflow to ensure high data quality.
In the video below, I'll demonstrate classifying the results of a complex query (metadata + cosine distance based similarity) manually. This can be automated programmatically using slices.
Try it out
I hope this walkthrough was informative and inspired a few potential video use cases. By utilizing these techniques, you'll be able to accelerate downstream workflows such as classifying high-volumes of videos for further labeling, or enriching your videos with additional metadata to derive faster insights. As a next step, you can check out this dataset and give it a try for yourself in Labelbox Catalog.


