×![]()

 All blog posts
All blog postsLabelbox•May 26, 2022
Increase labeling velocity and optimize workflows with our newest features

This month, we’ve continued to focus product development to help teams increase labeling velocity and optimize their data management workflows. Users can now import their metadata with a few lines of code and easily search and manage their datasets within Catalog. We’ve also made key improvements to our editors to better support text and documents.
Jump start your labeling with our image auto-segmentation beta

A big challenge that many ML teams face is getting to model production faster. Manual labeling can be a significant portion of an ML team’s budget, with segmentation masks being the most time-consuming annotation type.
We’re introducing our upcoming image auto-segmentation tool to help teams reduce labeling time and cost.
With our upcoming auto-segmentation tool, you can:
- Generate quality masks with one simple action
- Create segmentation masks in a fraction of the time
- Easily edit the mask prediction with our pen tool
For the most dramatic gains, you can integrate your own model to pre-label your assets. This makes labeling faster and more accurate as your model improves with every iteration. Read more about our model-assisted labeling workflow and how one of our customers increased their labeling efficiency by 160%.
While the most mature and efficient ML teams tend to use model-assisted labeling to accelerate labeling by importing model predictions, many teams just getting started with a new project will be able to dramatically increase their labeling speed for segmentation masks.
Sign up to get early access!
Import your data rows and metadata in one operation
We’ve updated our SDK to make metadata imports easier than ever. You can now quickly import your data and attach your metadata with a much quicker operation and then start filtering based on metadata in Catalog.
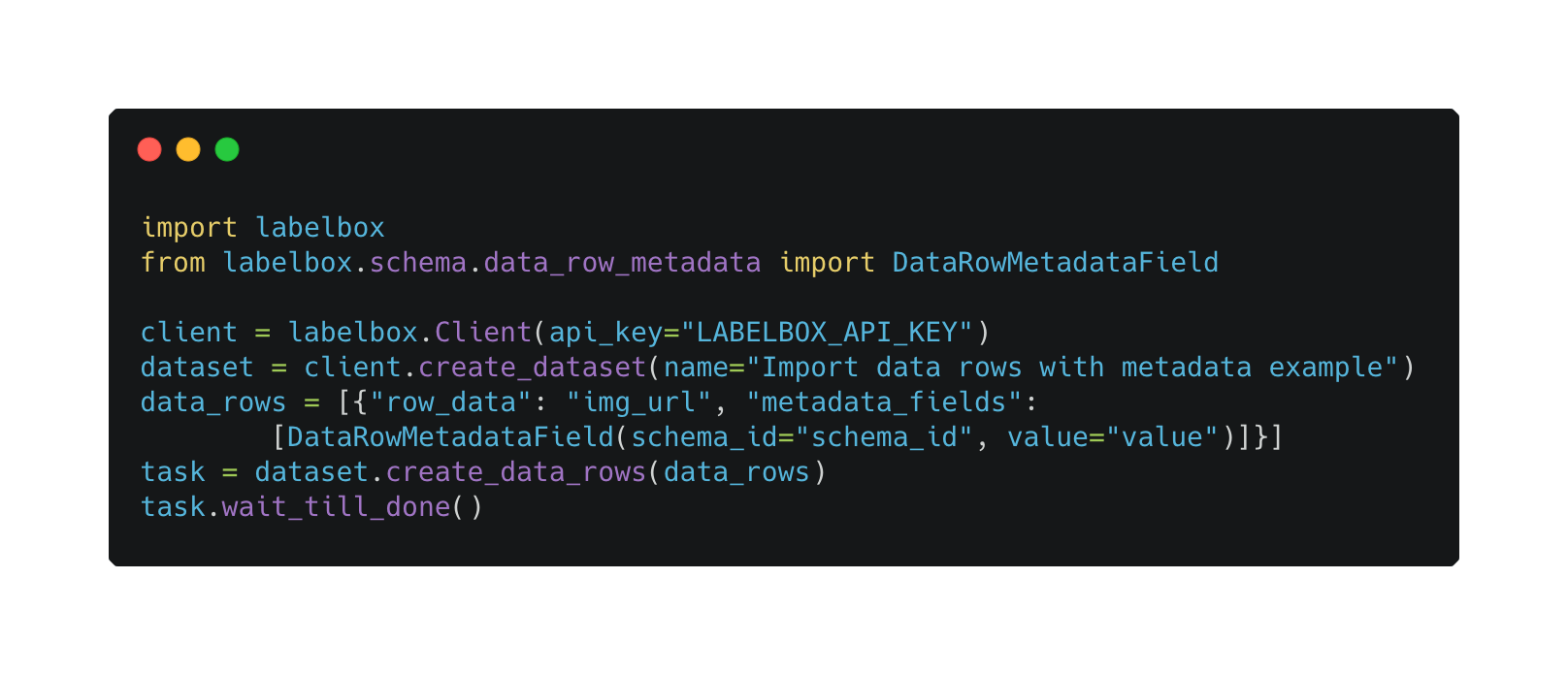
We'll be updating our SDK to make metadata exports a more seamless experience in the coming weeks.
Manage, search, and curate your data with Catalog
We recently updated Catalog to make it easier than ever to explore unstructured data and curate data for labeling projects. You can read more about how Catalog’s centralized data workflows can help you increase your iteration velocity in a recent blog post.
In addition to the key updates highlighted in our blog post, we’re excited to announce upcoming improvements to increase visibility and productivity in Catalog.
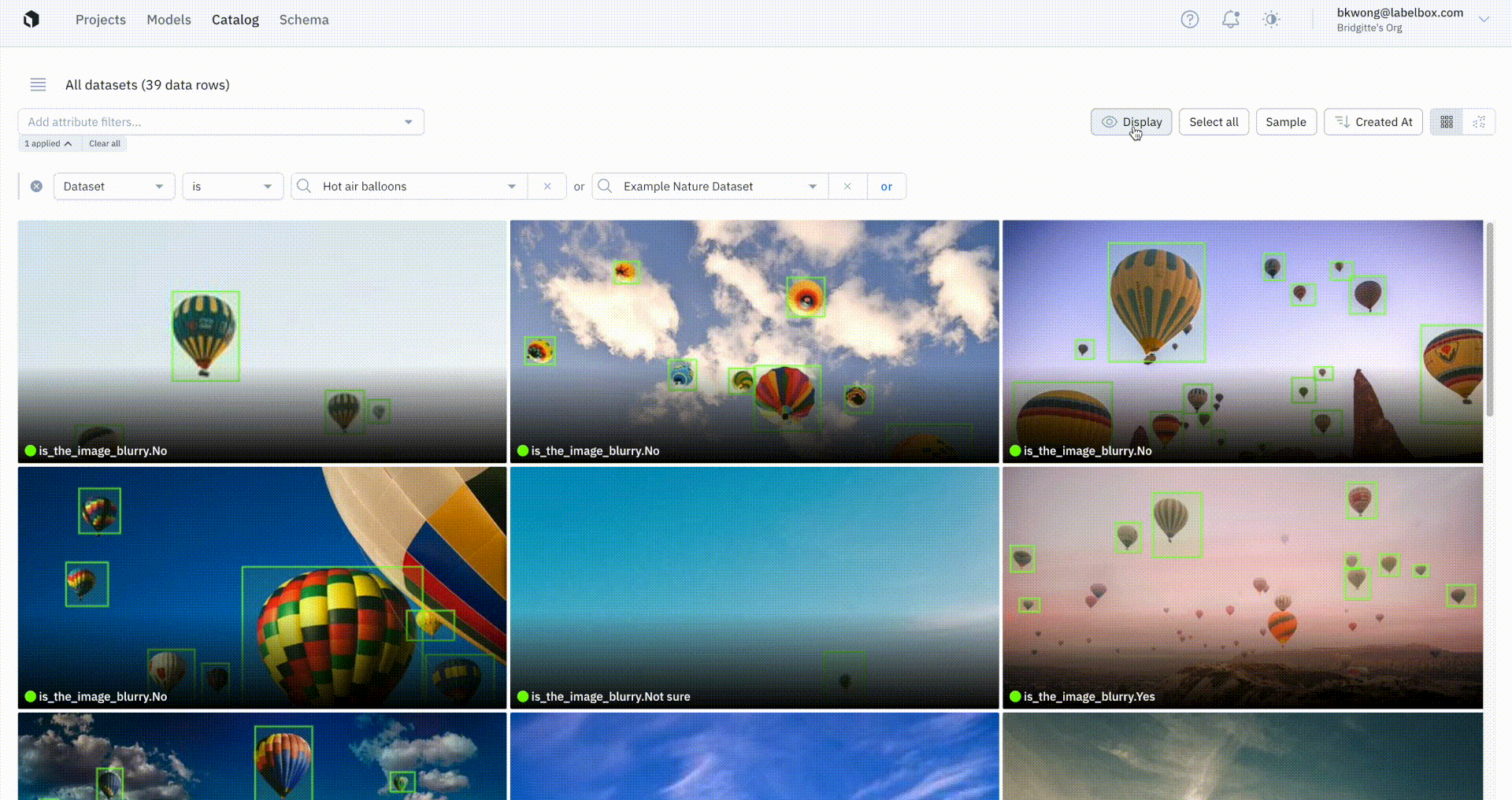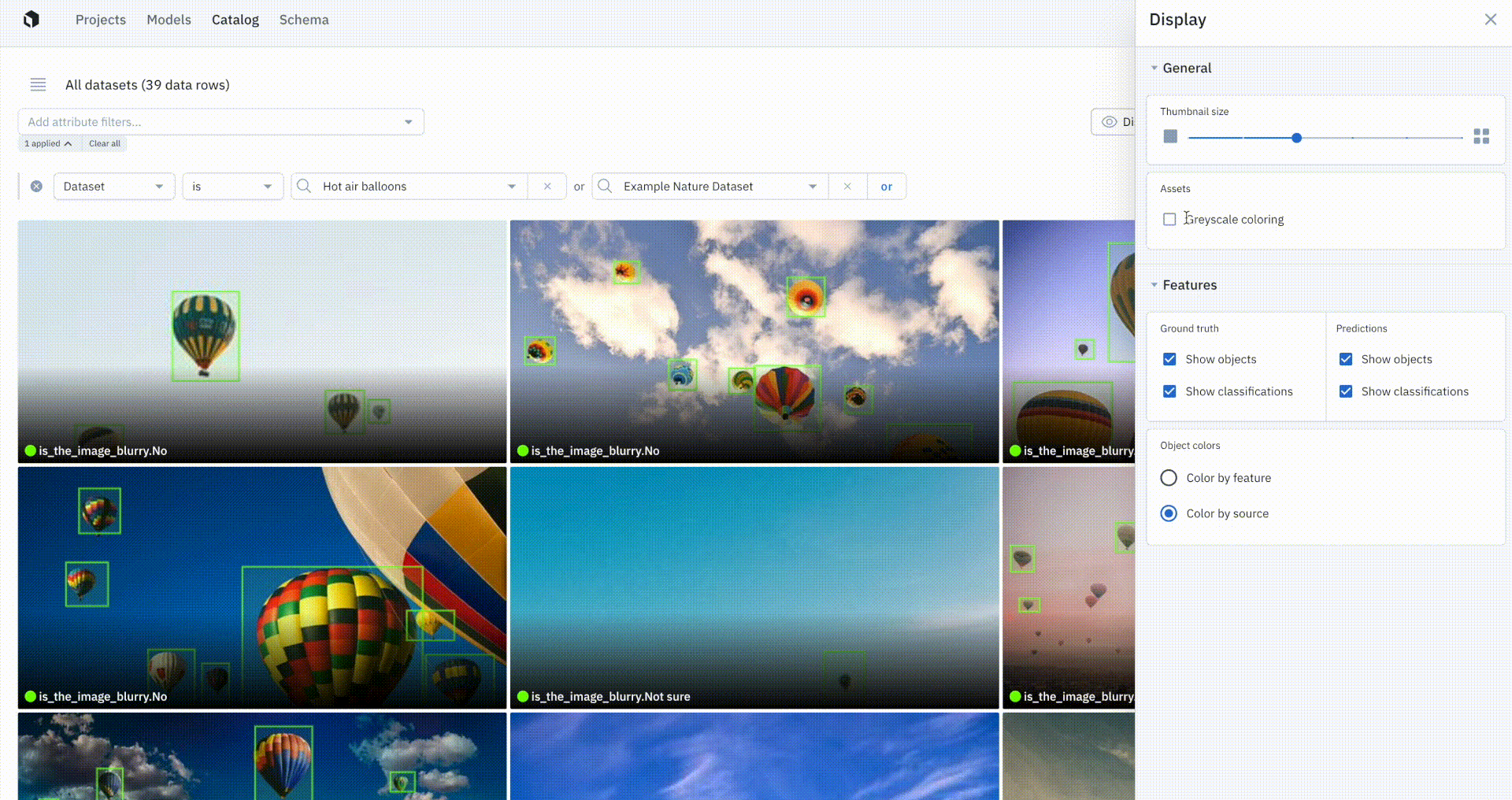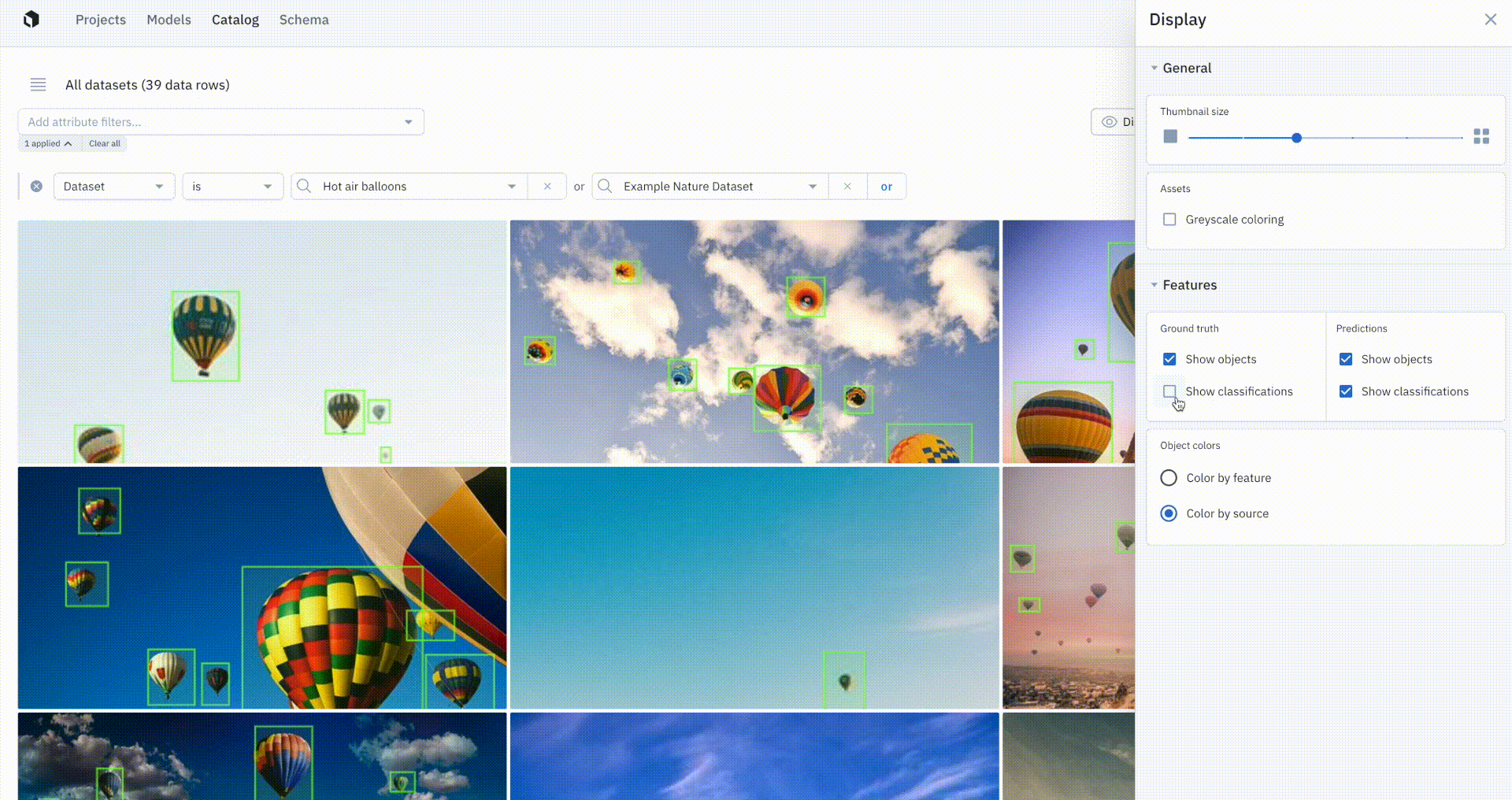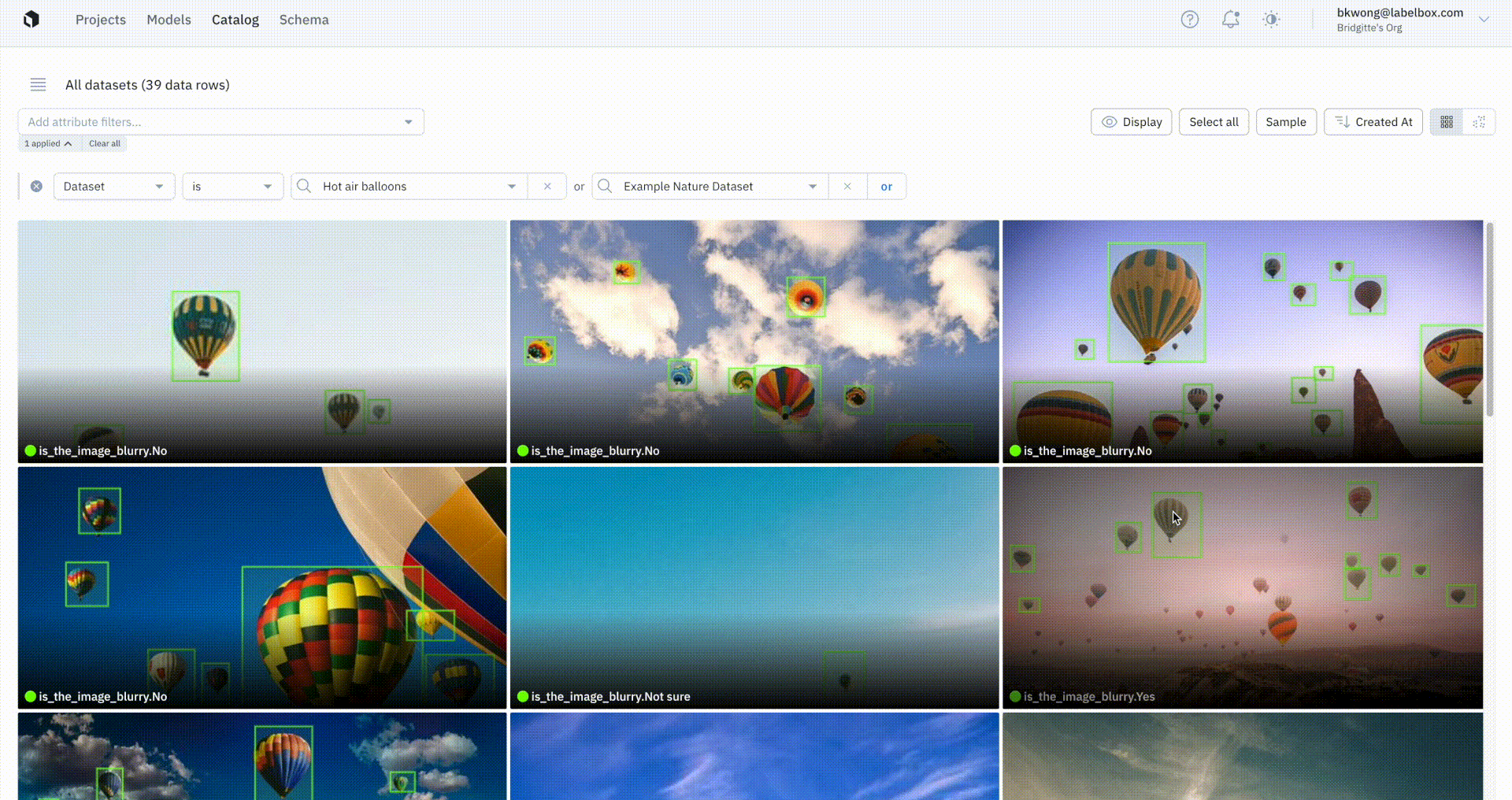
You’ll soon be able to visualize model prediction overlays on images in Catalog. Being able to easily view ground truth annotations and predictions lets teams immediately get a better understanding of how their model is performing and can help inform and validate hypotheses behind model behavior. While performance metrics and detailed diagnostics are necessary for uncovering trends in model performance and tracking improvements, visual inspection is an essential part of understanding performance and guiding iterations.
With our updates to Grid View and Detailed View in Catalog, you’ll soon be able to:
- View ground truth overlays for images and tiled imagery
- View prediction overlays for images
- Control the size of thumbnails shown in Grid View
- Adjust the grayscale coloring of images
- Choose and display labels from a project
- Choose and display predictions from a Model Run
Keep an eye out for these updates and learn more about Catalog in our documentation.
Better workforce orchestration with in-app updates & notifications
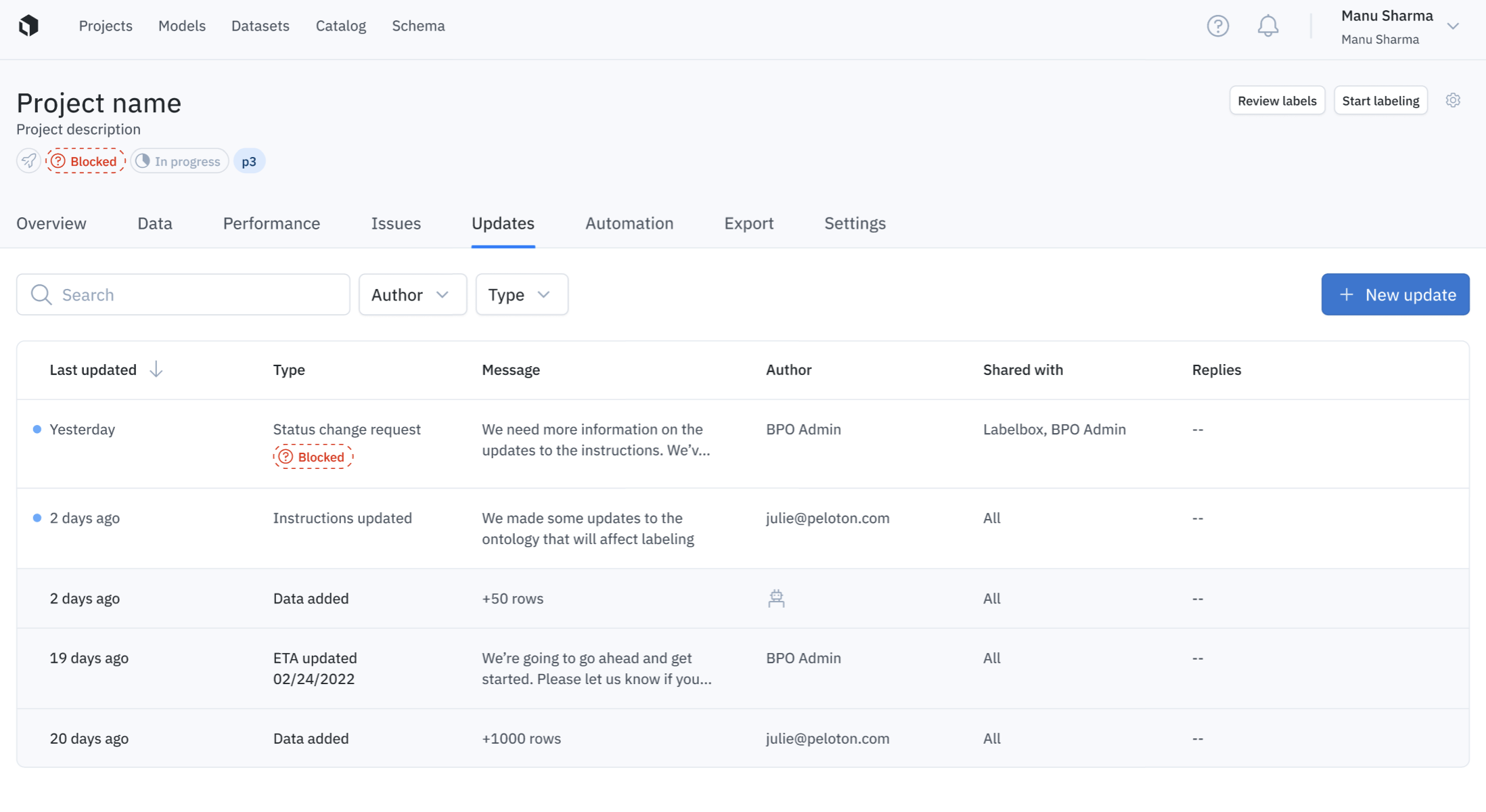
Teams who are working with our vetted labeling partners can now send and receive in-app updates and notifications to better orchestrate projects.
Rather than rely on numerous external collaboration tools, where the thread of a conversation can get lost, this new feature enables three-way communication between workforce customers, labeling partners (BPOs), and our Labeling Operations team.
This feature can be accessed via the new “Updates” tab within a project and gives a clear view of a project’s progress. Updates are organized according to function: Progress update, General update, Status update, Instructions update, Issues added & ETA changed. This allows for better organization and searchability.
Labelbox Boost provides on-demand expertise and labeling teams to deliver tailored training data solutions when and where you need them. Learn more about Boost.
Editor Updates
We’ve made several improvements to our editors.
Turn PDFs and documents into AI use cases
Documents are a common file type for many enterprise companies across industries such as financial services, insurance, and real estate. Companies may sit on a wealth of data, with no easy way to turn these documents into insights.
Our editor allows you to easily turn stores of PDF files and documents into performant ML models, unlocking the potential to help streamline and speed up existing business processes. Example use cases include automating tasks like extracting a billing address from invoices or contract dates for lease agreements.
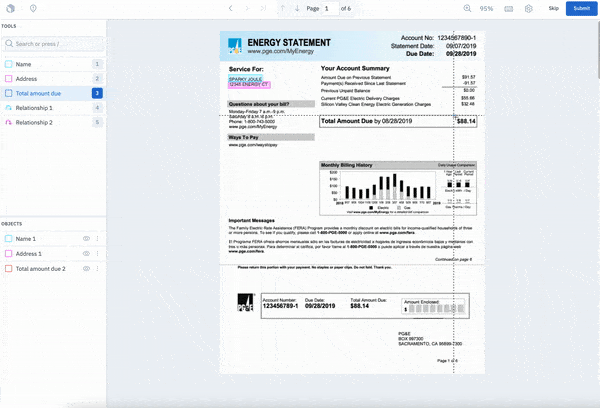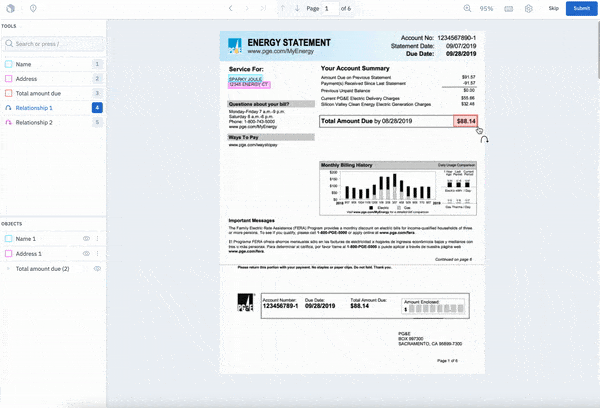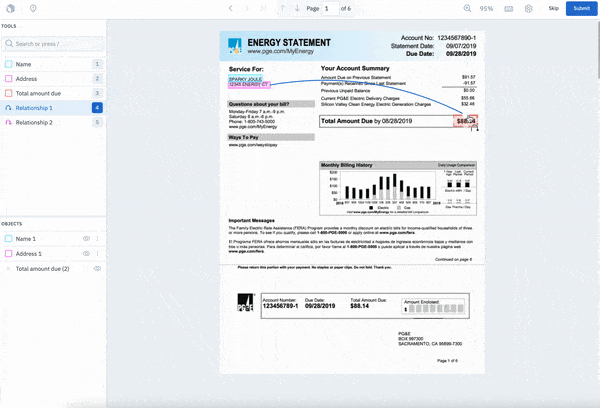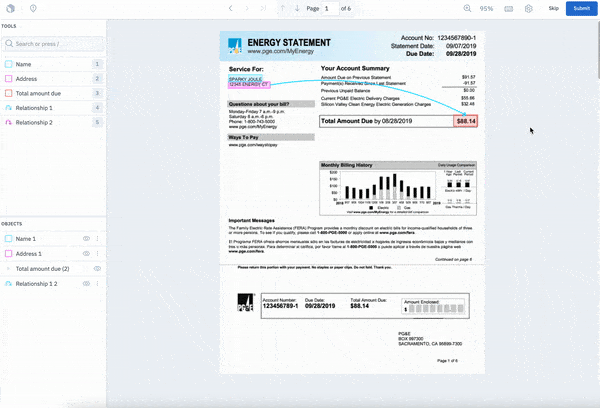
With our editor, you can now:
- Natively view and navigate multi-page PDF documents
- Create bounding box labels for optical character recognition (OCR) use cases
- Create classifications at the document and bounding box level
- Give and receive quick feedback on label quality through Issues & Comments
- Apply NER annotations directly to PDFs without converting them into text files (Currently in Closed Beta. Sign up for early access!)
While you can already create Annotation Relationships within images and between entities in our text editor, we’re excited to announce that you can now create Annotation Relationships between OCR bounding boxes or entities (in our NER Closed Beta) within documents. This tool allows you to specify a relationship between key characters to understand how they relate to each other.
Learn about how to upload a document dataset and more in our documentation.
Train a model on conversational text
We’re excited to announce that our new editor, designed to help customers better annotate text in the context of conversations, is currently available in beta for users in our EDU, Pro, and Enterprise tiers.
You can use this editor to label data for training conversational AI to power tailored experiences that foster positive customer sentiment and stronger brand loyalty. Example use cases include building new chat experiences to optimize business outcomes or building a model to identify inappropriate content for improved content moderation.
Watch the demo below to see our conversational text editor in action!
Label data to train conversational AI.
Learn more about our conversational text editor in our documentation.


