×![]()

 All blog posts
All blog postsLabelbox•November 17, 2022
Measure and improve pre-labeling workflows with the automation efficiency score

The machine learning team at Blue River Technology was in the process of developing a computer vision system to identify and eradicate weeds using robots that would reduce herbicide use in fields by 90%. With a machine learning (ML) model that identified weeds and crops in images of fields — farmers could optimize spending and usage of herbicides and preserve valuable crops.
As the team built their solution, they realized that their labeling process, which involved external workforce vendors, trained botanists and agronomists creating meticulous annotations on image data, was enormously expensive. To develop their product on budget, they needed a more efficient labeling process.
To build this new process, the team began experimenting with different ways to accelerate their labeling and review workflows. By importing model predictions as pre-labels via model-assisted labeling with the Labelbox data engine, the team ensured that labelers only had to adjust or correct masks and label errors, rather than creating them from scratch. Some pre-labels also directed labelers' attention to specific areas of each image that required labeling, further reducing the time to label each piece of data.
With every iteration, their model became better at the task at hand, and the team could dedicate more time and SME time on edge cases and low confidence areas. By leveraging model-generated pre-labels, Blue River Technology cut labeling time by over 50%.
Creating large volumes of high-quality training data is a vital function of a data engine. Training data is necessary for both training performant models and maintaining models in production. However, when costs increase linearly with the number of annotations, labeling the required amount of data can quickly become expensive — in costs, time, and talent.
Automating your data labeling process is not only a key component of an effective data engine, but is key to producing high-quality data, fast. While automation can range from AI-assisted tools to automated labeling pipelines, there is one method that provides the most significant and long-term time and cost savings: pre-labeling.
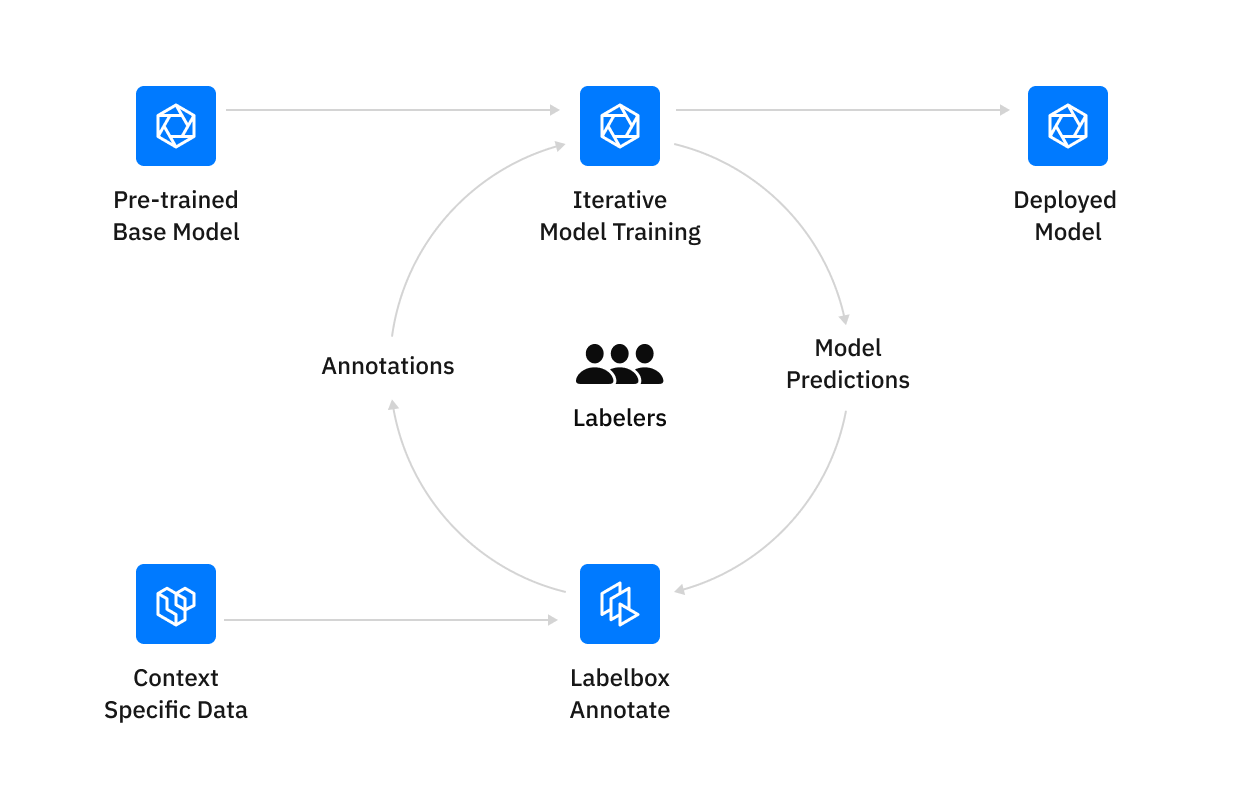
By using a model of your choice, you can import pre-labels to enable faster data-centric iterations that leads to a more accurate and performant model over time. Since Labelbox launched the model-assisted labeling workflow in 2020, AI teams of every maturity level have leveraged it to drive up labeling efficiency and reduce costs.
Even so, it's hard for most teams to measure the impact of their specific use of pre-labeling — a requirement for those experimenting with different tactics and/or models. Quantifying the savings and efficiencies from pre-labeling typically requires teams to meticulously track (usually via manual means such as spreadsheets) labeling time and costs, and then compare them to previous or control group results.
Today, Labelbox is launching a new feature to our model-assisted labeling workflow to help ML teams measure and understand how their pre-labeling process is impacting labeling time and efficiency.
Introducing the automation efficiency score
The automation efficiency score is a new metric that will appear on Labelbox users’ project dashboard, on the Automation tab. Instead of operating blindly or spending more time manually tracking efficiency gains from pre-labeling, teams now have a tangible way to quantify how their use of pre-labeling accelerates model development.
If you’re using model-assisted labeling on a project, you’ll be given a score from 0-100. This score is calculated on a per-project basis and leverages project data (the percentage of features created with model-assisted labeling and total time savings compared to the average time taken to label non-pre-labeled assets) to come up with a single measure of how well your project uses automation to improve labeling efficiency.
The automation efficiency score will automatically start appearing in the Automation tab of your projects once the following conditions have been met:
- You have labeled at least 10 data rows without using model-assisted labeling
- You have imported at least 1 batch of labels as pre-labels using model-assisted labeling
- You have labeled at least 10 data rows with the model-assisted labeling pre-labels
Along with a dedicated single score to convey how efficiently you’re utilizing pre-labels, Labelbox now provides additional metrics to help identify potential areas of inefficiency:
- Percentile automation efficiency score
- Percentile of features made with automation
- Estimated percent time saved per label using automation
- Total time saved across the project (hours)
The time savings from using pre-labels doubles as you climb the automation efficiency score ladder. Projects with an automation efficiency score of over 75 experience 65% in time savings by leveraging pre-labeling — all without sacrificing training data quality. In other words, world-class projects can save two-thirds in labeling time and costs. Projects with an automation efficiency score of 50-75 see an average of 40% in time savings. Even teams with an automation score of 25-50 – those who are not fully optimizing their pre-labeling workflow – see an average of 10% in time savings.
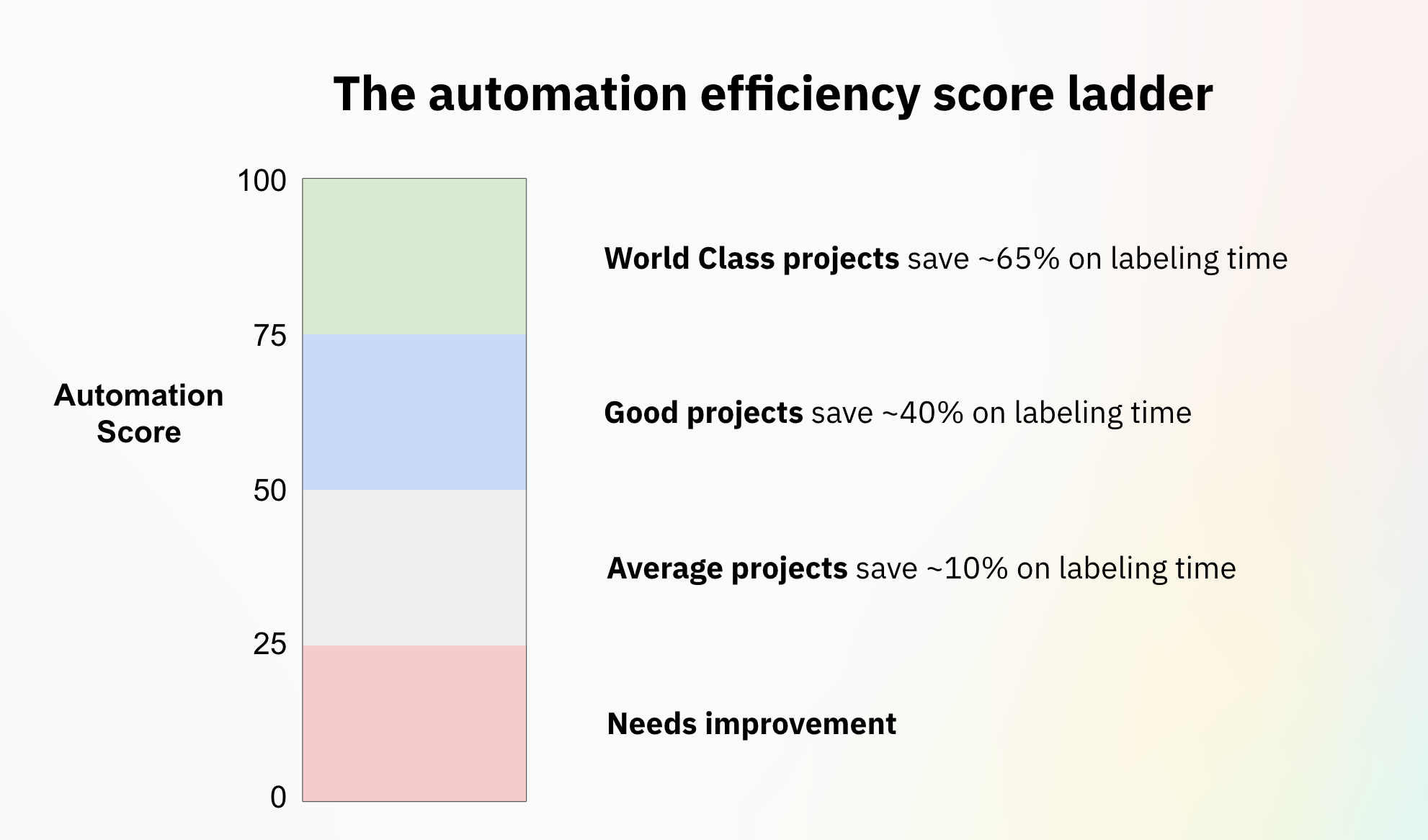
While teams might have a lower automation efficiency score to start, they can quickly leverage the available insights and additional metrics to identify gaps in their current workflow and work towards increasing their score. Teams experimenting with various pre-labeling setups can now easily compare results with their automation efficiency score — and teams who were previously operating blind now have more visibility into their pre-labeling success.
You can learn more about the automation efficiency score in our documentation.
The updated Automation tab and automation efficiency score are now available on all projects for Labelbox users. If you’re not currently a Labelbox user, you can try it for free and start leveraging pre-labels to reduce labeling time and costs today.


