
 All blog posts
All blog postsLabelbox•June 3, 2022
Training a model from your labeled data in just one click
The holy grail of Software 2.0 and ML development is having the ability to take high-quality training data and labels and then sitting back and seeing the model train itself to a superhuman level of accuracy.
However, many ML developers today still need to write a lot of custom data processing code and training/deployment configurations in numerous Python scripts or Jupyter notebooks in order to start a model training job. In fact, machine learning engineers and data scientists report spending 45% of their time getting data ready before they can use it to develop models. This represents one of the main bottlenecks slowing down domain experts from training ML models.
With this in mind, Labelbox recently launched the beta for our model training and experiment management tools to help ML developers do the following:
- Quickly launch experiments and evaluate whether state-of-the-art ML models can power your business use cases.
- Increase model and data experimentation velocity by integrating labeled data directly into the training pipeline.
- Track all data and model experiments in one place.
Featured workflow: 1-click model training with Vertex AutoML
Labelbox now provides a reference model training integration based on GCP’s Vertex AI. Once you set up the integration with your Vertex AI account, you can train a model from your labeled data in Labelbox with a single click.
Here is the step-by-step guide on how to create a model:
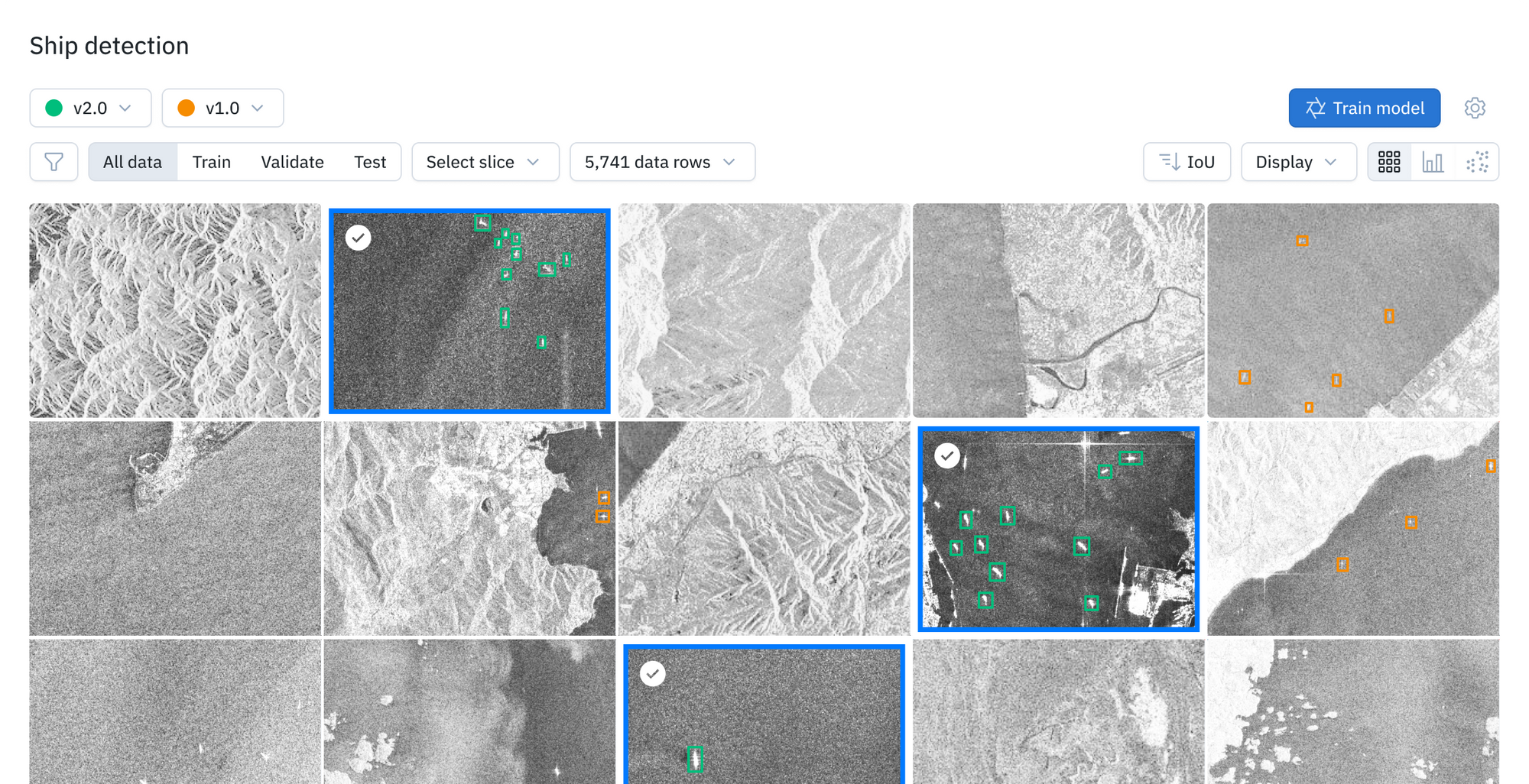
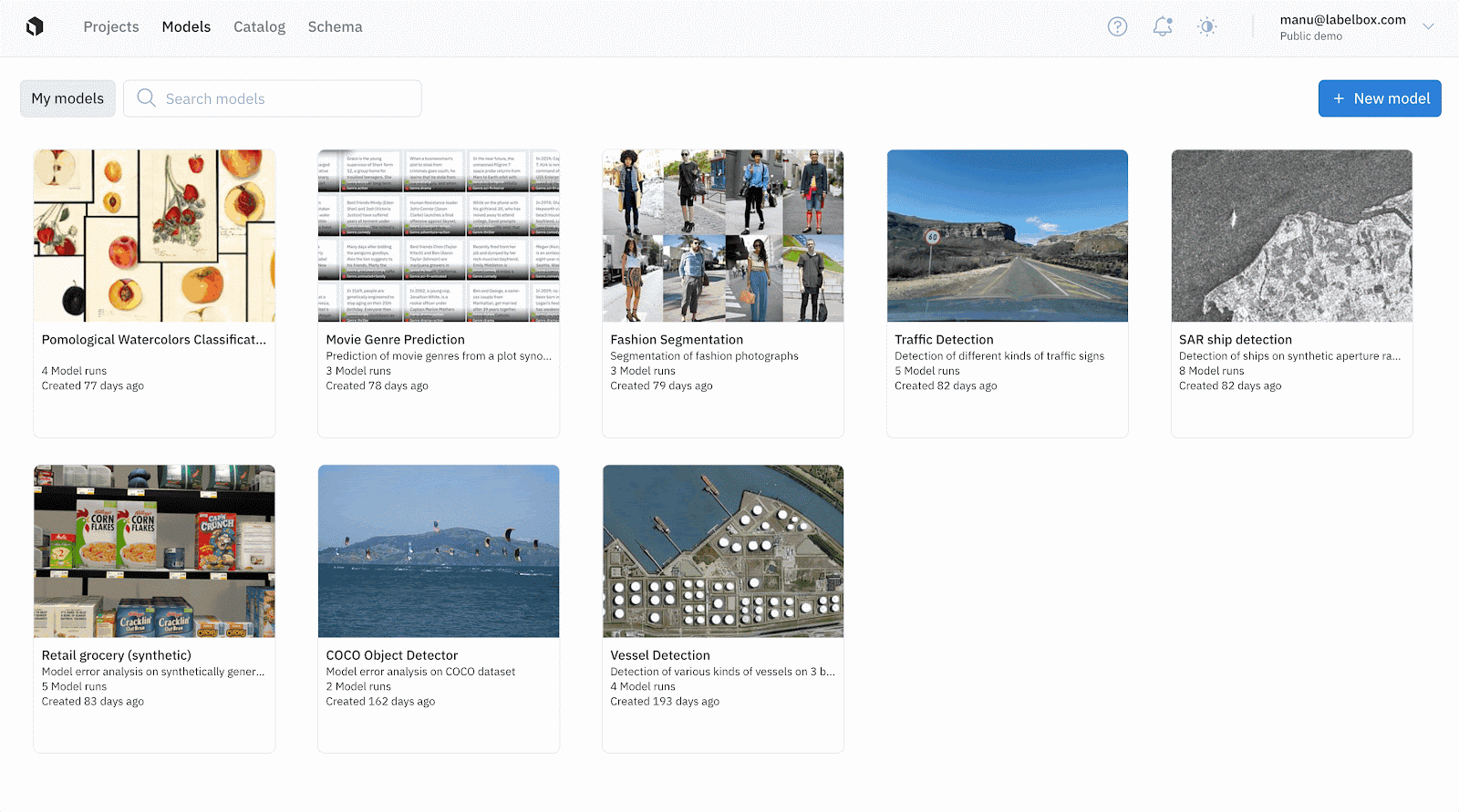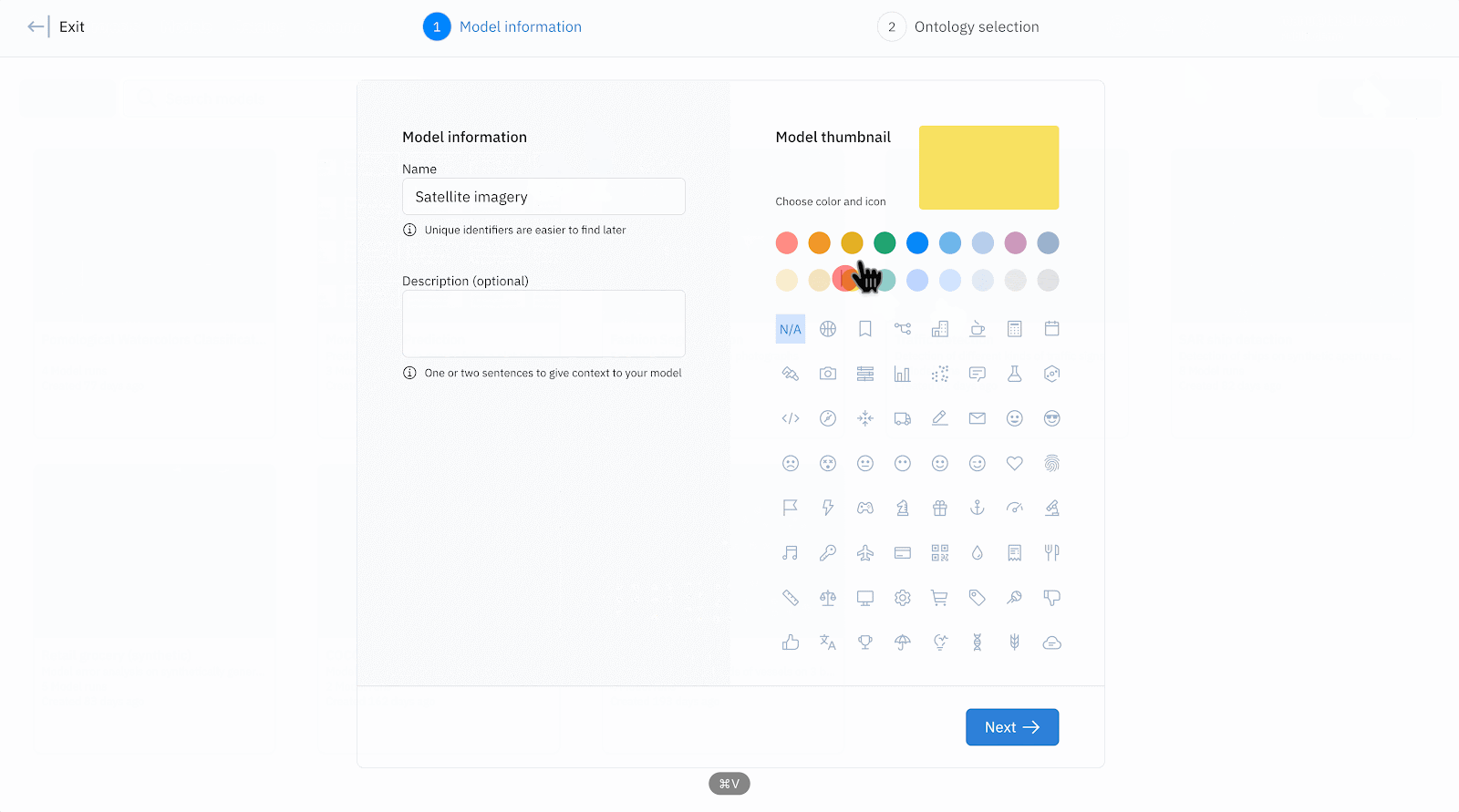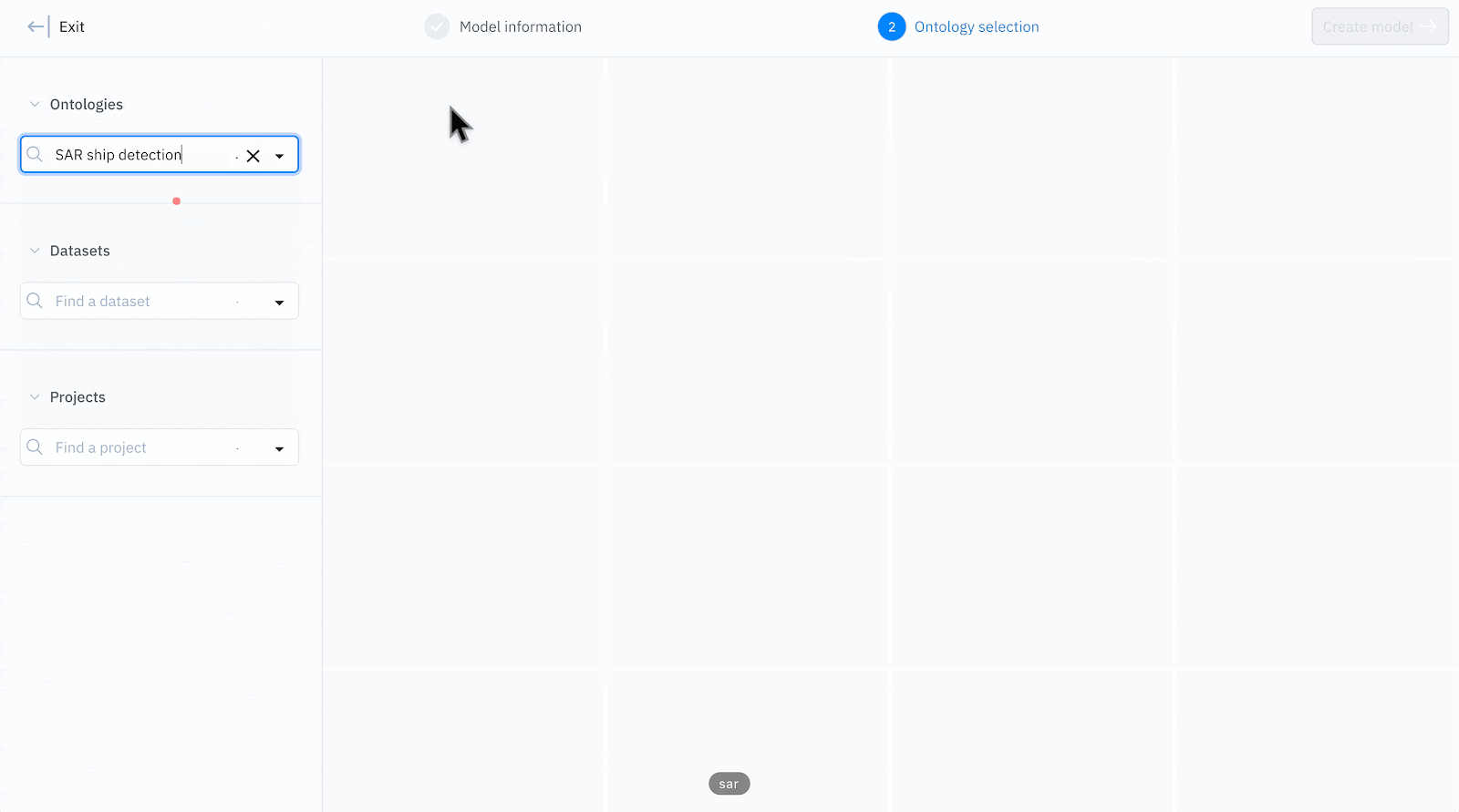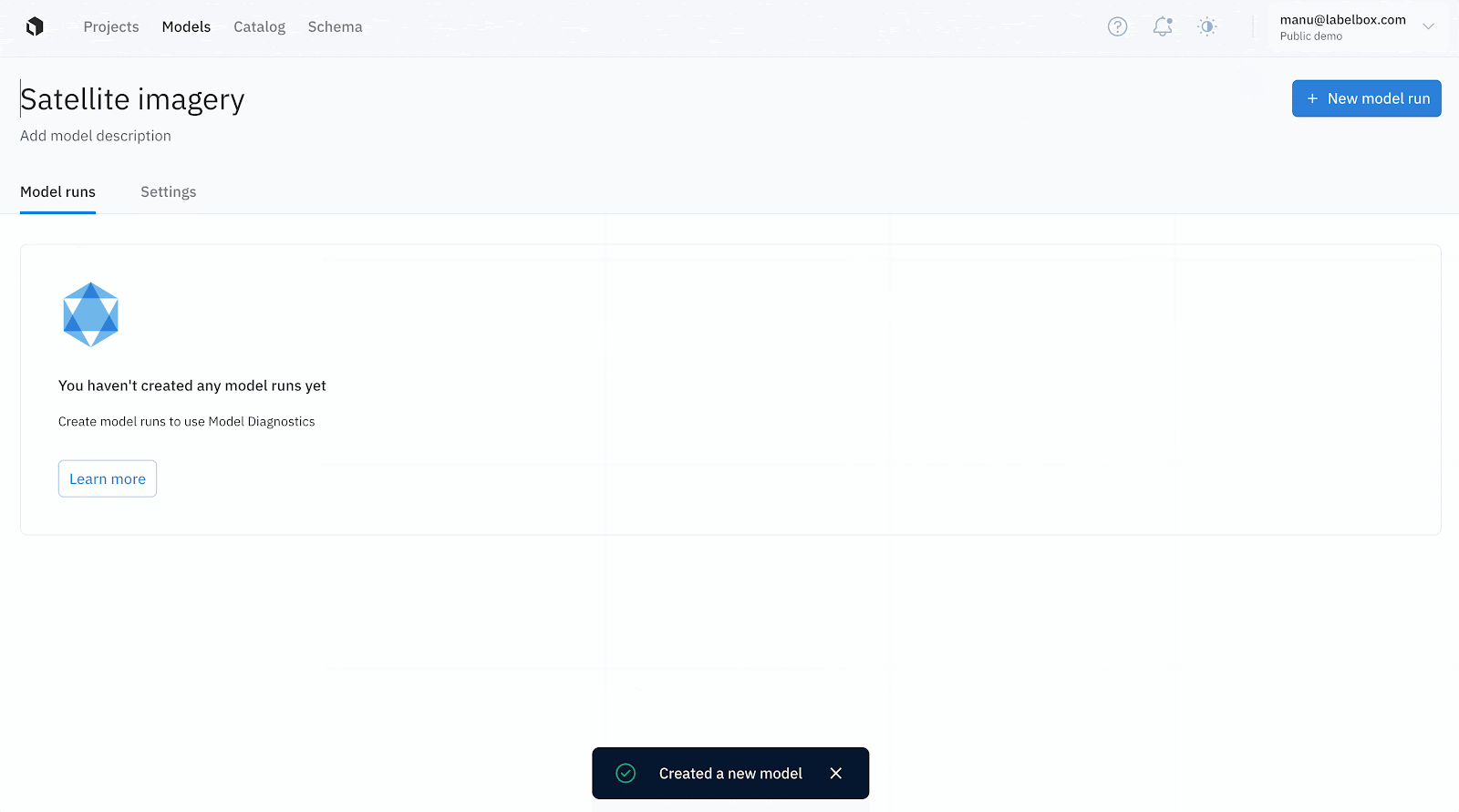
- Create a model and select training data by choosing your ontology, projects and datasets.
2. Create a model run and curate train, validate, and test data splits.

3. Configure your model training integration settings.
Before you can use the one-click model training integration, you only need to connect your Vertex cloud account to your Labelbox organization. Then, you can use the same integration for all model training requests.
4. Initiate model training by selecting one of the AutoML tasks from Vertex AI.

5. Examine model results and take actions to improve your data and models.
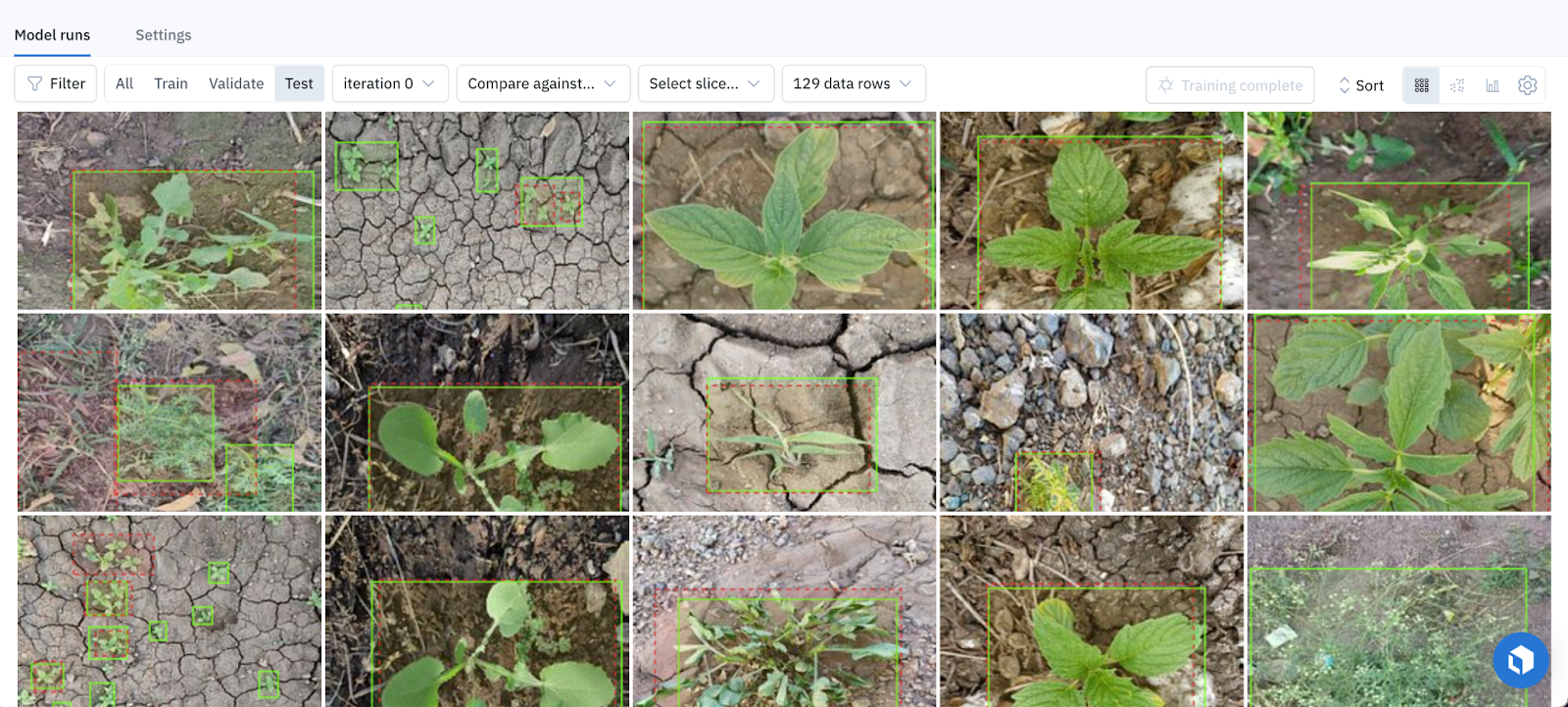
From here, you can evaluate your model , find model errors to improve your next model iteration, find label errors and reduce your labeling budget.
The beta is available for all current customers. If you're a user of our free Developer Tier or aren't a customer but would like to learn more, you can sign up for the beta, and we thank you in advance for your feedback as we continue to build new ways to simplify the model training process.


