
 All guides
All guidesHow to pre-label images in your annotation project
With the recent integration of model-assisted labeling (MAL) directly into Labelbox projects, labeling teams can now quickly generate pre-labels using the most powerful foundation models available today. This is particularly valuable for computer vision projects where pre-labeling images with bounding boxes and segmentation masks can significantly reduce the time required for human labelers to annotate data.
Use model-assisted labeling in your project
Check out how model-assisted labeling works within Labelbox projects:
Pre-label images with model-assisted labeling in Labelbox
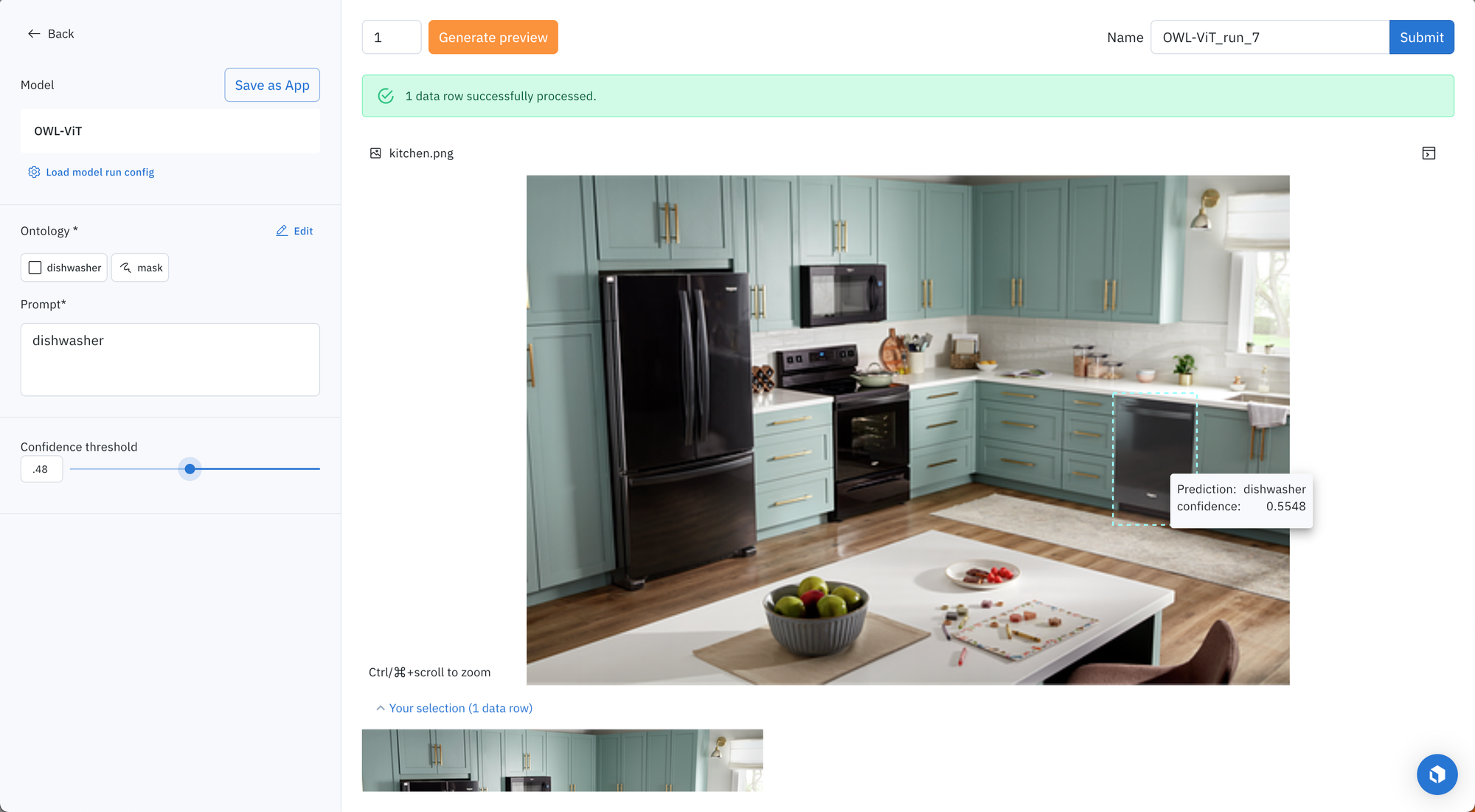
Within a Labelbox project, you now have the option to invoke powerful computer vision models to run through your project’s data and generate pre-labels in a matter of minutes. This enables your human labelers to simply correct and submit labels instead of starting from scratch.
Pre-labeling with bounding boxes
There are many state of the art foundation models available for adding bounding boxes to images. Each of these models come with different advantages and configuration options depending on your use case. For example, Grounding DINO and OWL-ViT are prompt-based models that take in general phrases, like “trees” or “black mug”, and can intelligently detect objects that fit the description. These models are great for custom use cases since they can generalize well to new objects based on the description you provide. On the other hand, Ultralytics YOLOv8 does not require a prompt. It has been trained on an extensive list of common objects in our day to day life, so it can identify those objects in your image without any prompt. It works well for most common use cases right out of the box.

Pre-labeling with segmentation masks
For many computer vision use cases, applying segmentation masks to images is critical especially in complex scenarios where precise delineation of objects is necessary. Drawing segmentation masks used to be a manual, tedious process of using a pen or brush tool, but using foundation models in Labelbox can save valuable human labeling time and accelerate your labeling process.
We recommend considering Meta’s Segment Anything Model (SAM), the best-in-class segmentation foundation model that can draw masks around any discrete object in the image. You can also run GroundingDINO or OWL-ViT to draw bounding boxes around objects of interest first, and then feed those boxes into SAM to draw masks within each box. All of this is possible with a few clicks in Labelbox projects.
Summary
Labelbox has been a pioneer of model-assisted labeling for years, starting out by using our powerful SDK to upload model-generated annotations. After working closely with our customers, we’re excited to streamline the experience and integrate MAL directly into your labeling workflow with just a few clicks and no-code required.
Try it when you create your next image project in Labelbox. And don’t worry, we are continuing to invest in supercharging your labeling workflows with the power of foundation models. So stay tuned, there is more to come!
If you are not already using Labelbox, you can get started for free or contact us to learn more about pre-labeling images using model-assisted labeling.