
Catalog
Turn data into insight and action
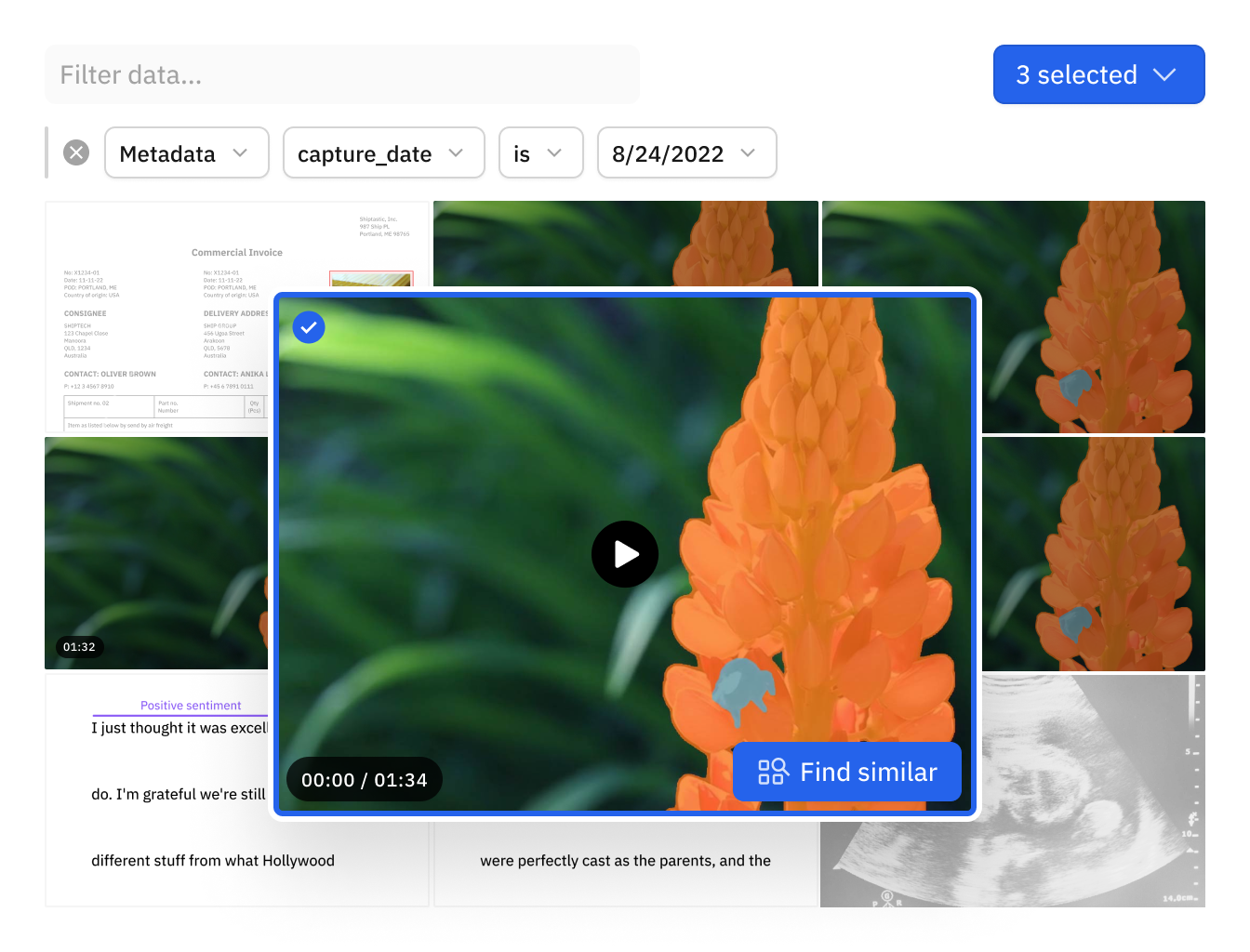
A new way to search unstructured data
Catalog eliminates the need to build your own traditional and vector database infrastructure. Build better AI applications by leveraging out-of-the-box search for images, text, videos, conversations, and documents across metadata, vector embeddings, and annotations.
Learn more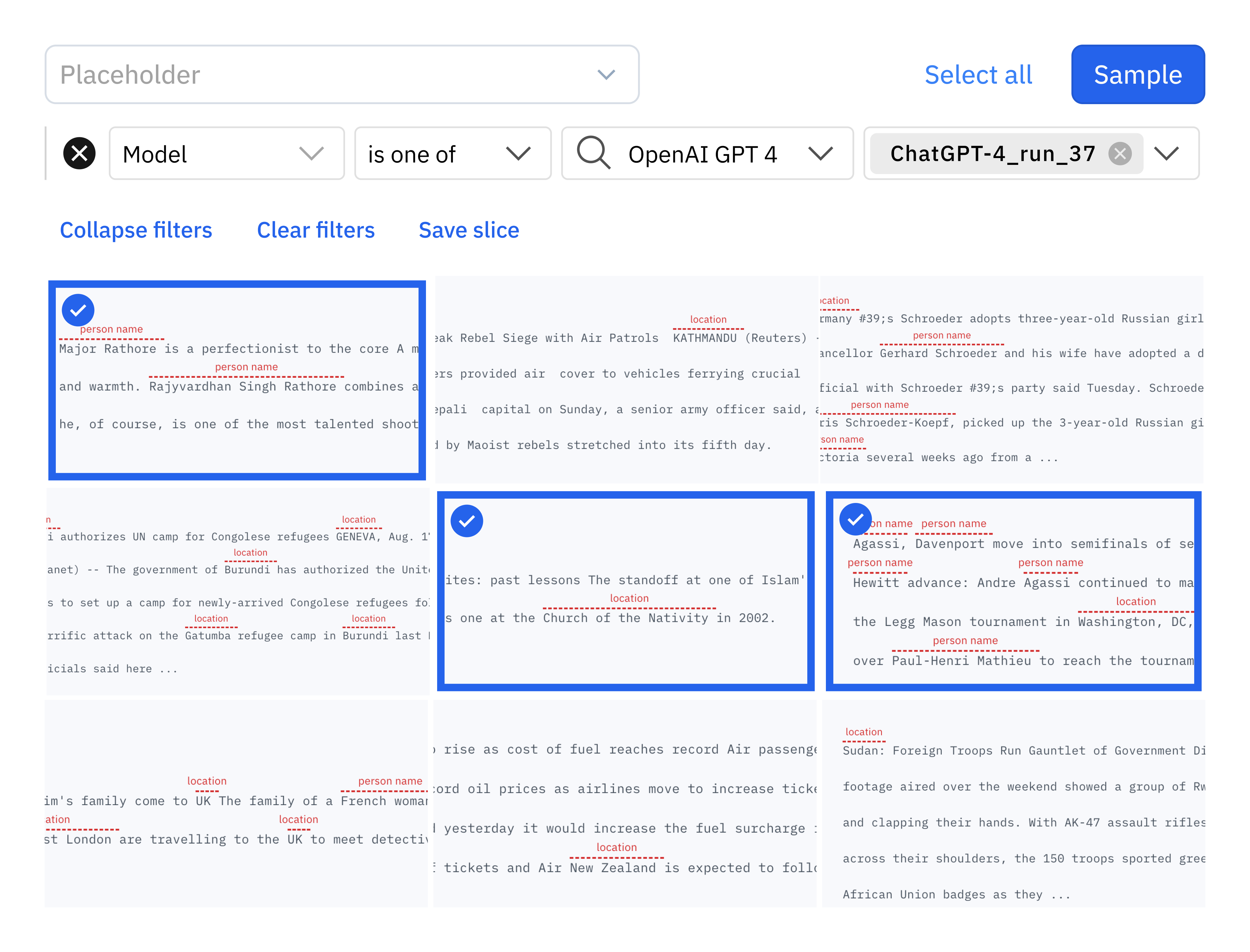
Explore datasets using AI insights
Curate and explore datasets faster than ever. Query your data using predictions generated from the latest and greatest foundation models. Supercharge your data enrichment process and accelerate curation efforts across image and text data modalities.
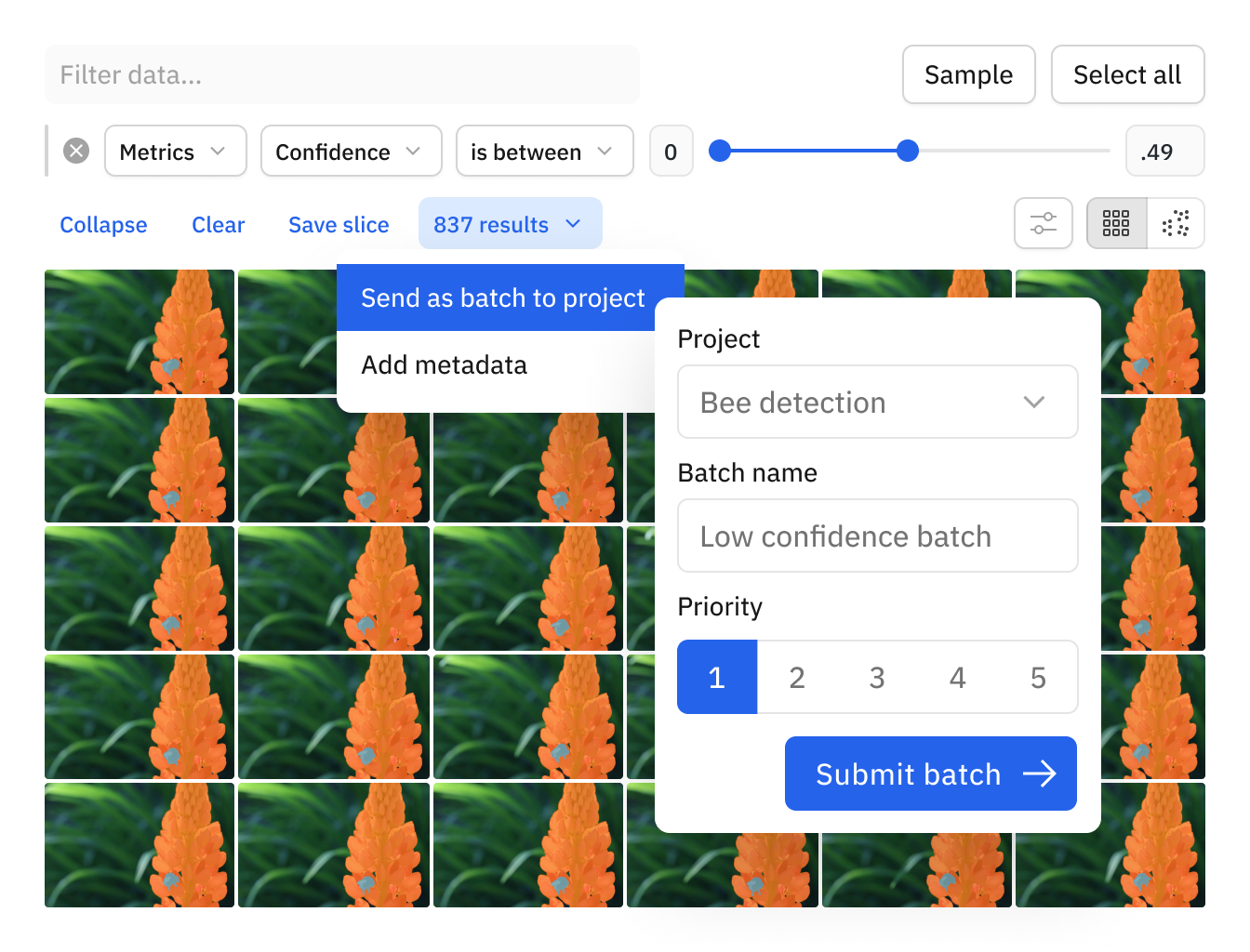
Improve models faster with active learning
Not all data impacts model performance equally. Through our active learning workflows and uncertainty sampling, you can filter for data with low-confidence predictions to curate and label the right data–not just more data.
Learn more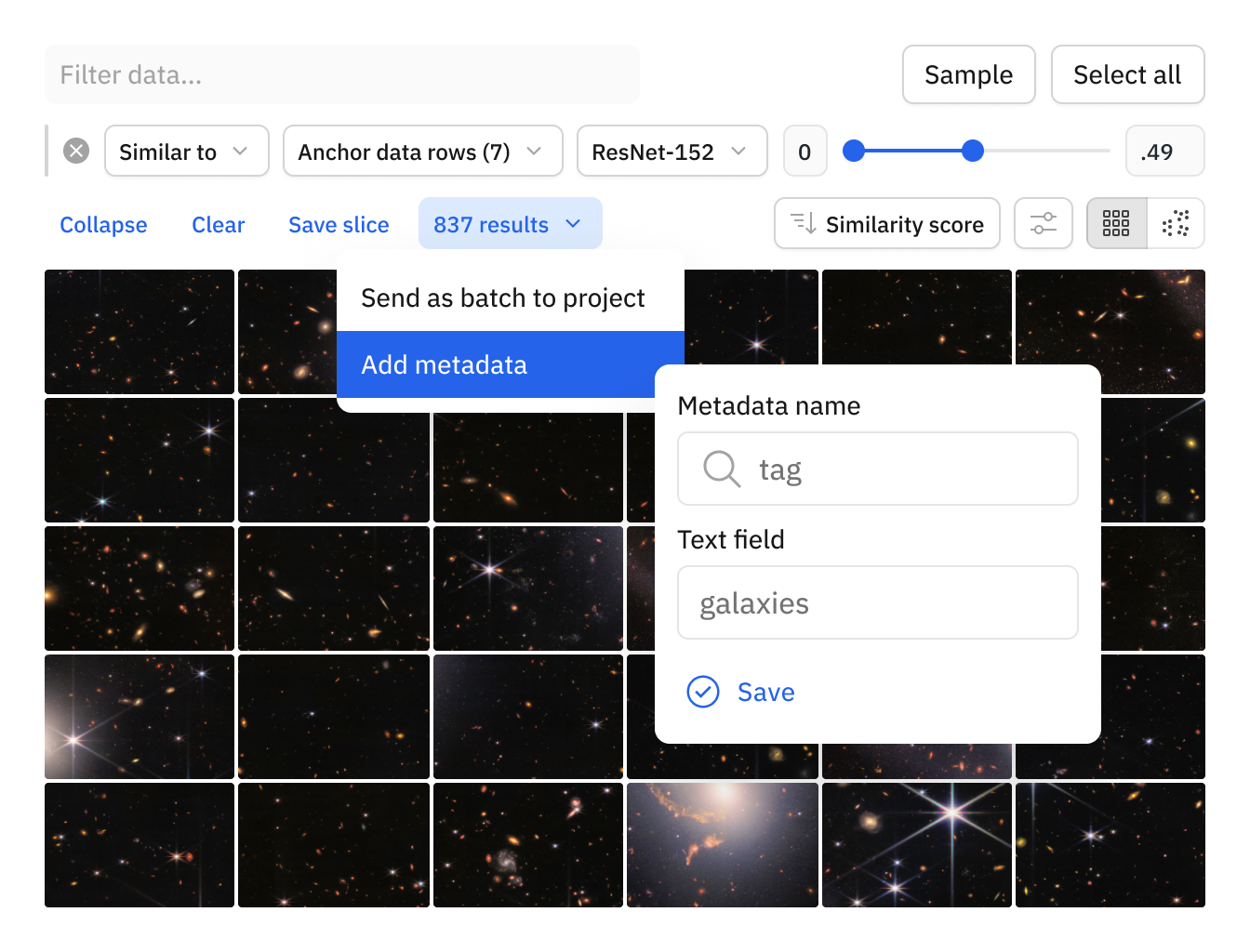
Perform zero shot classification with vector embeddings
Use inbuilt natural language search, pre-computed, or custom vector embeddings to find similar data clusters for automated classification. Optionally send to human review for maximal accuracy.
Learn more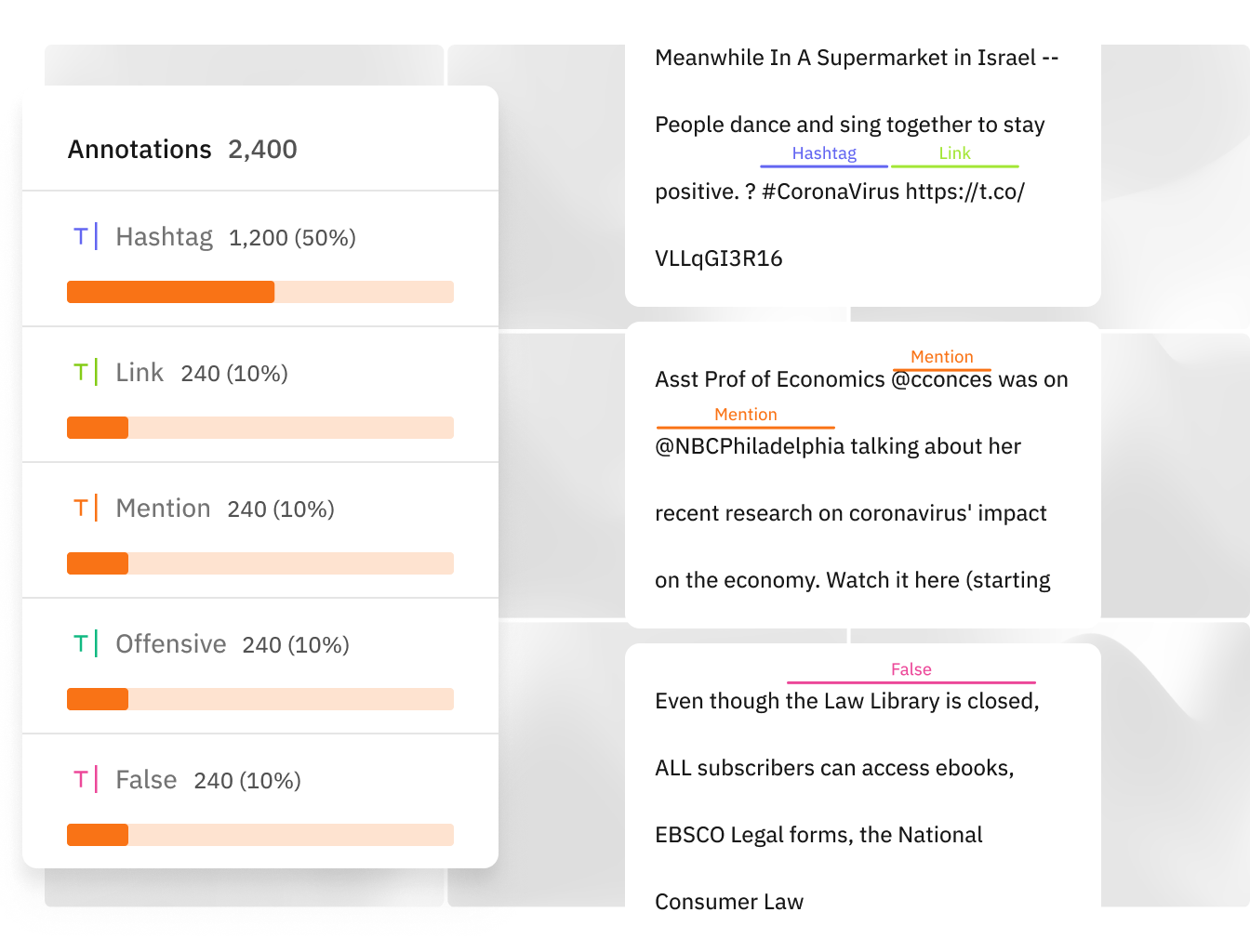
Analyze your data with metrics that matter
View a detailed class distribution of ground truth labels or model inferences to get a better understanding of your data. See how performance metrics like F1 score vary across your data so you can make the most informed decisions when curating data to label.
Optimize labeling budget
Not all data impacts model performance equally. Leverage your data distribution, model predictions, model confidence scores, and similarity search to curate high-impact unlabeled data that will boost your model performance.
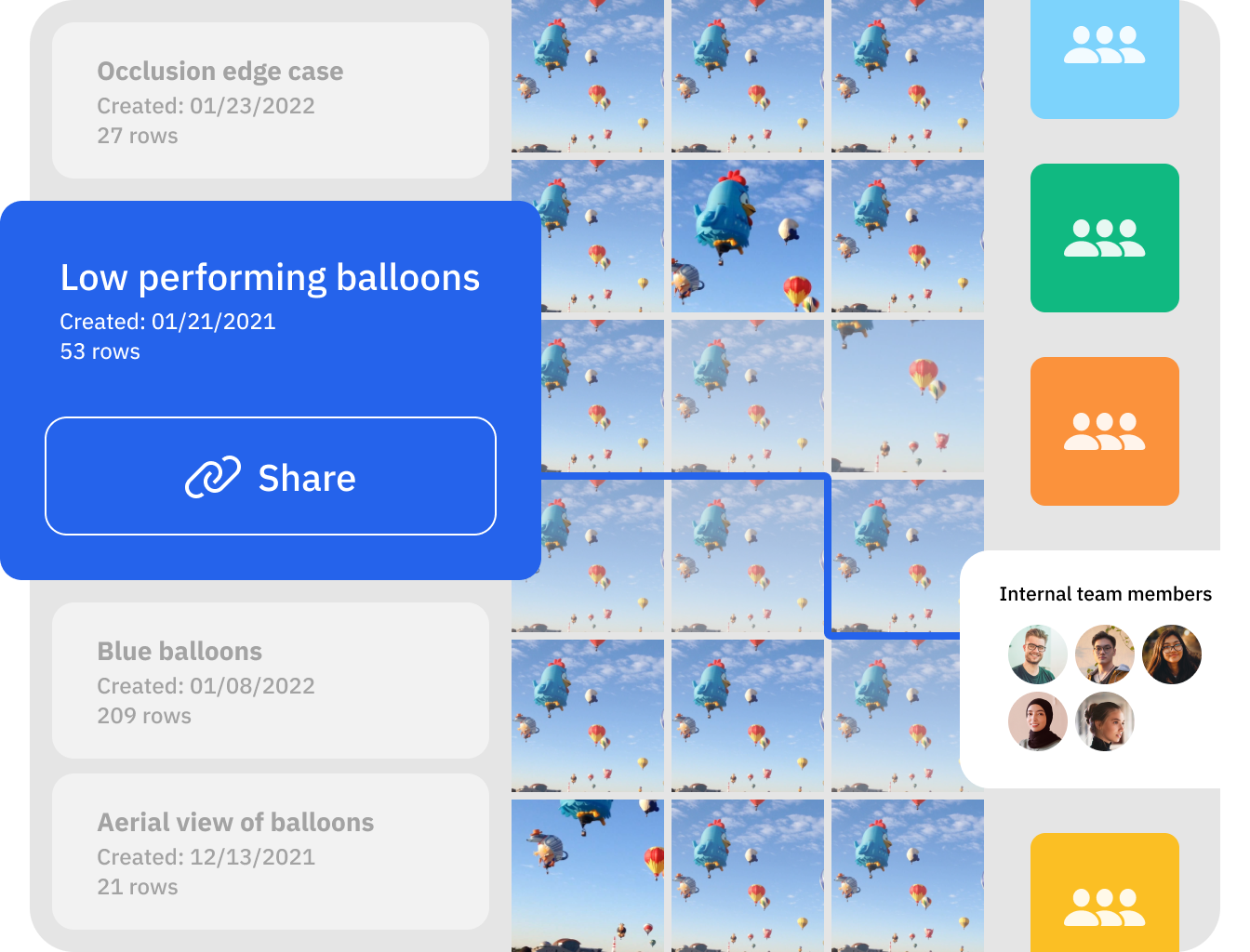
Share and act on insights faster
Don’t let searching for data and edge cases slow your team down or hold up conversations with stakeholders or customers. Instead of relying on one-off query scripts, search and discover data faster inside Catalog.



