×![]()

 All blog posts
All blog postsLabelbox•August 24, 2021
3 Key Takeaways from Labelbox & Databricks' session at AWS Dev Day

On July 21st 2021, Labelbox had the opportunity to present during AWS Dev Day alongside Databricks. The presentation covered how ML teams of any size can use Databricks, Labelbox, and Amazon S3 to build a robust ML pipeline. Below are three important topics we discussed during the event.
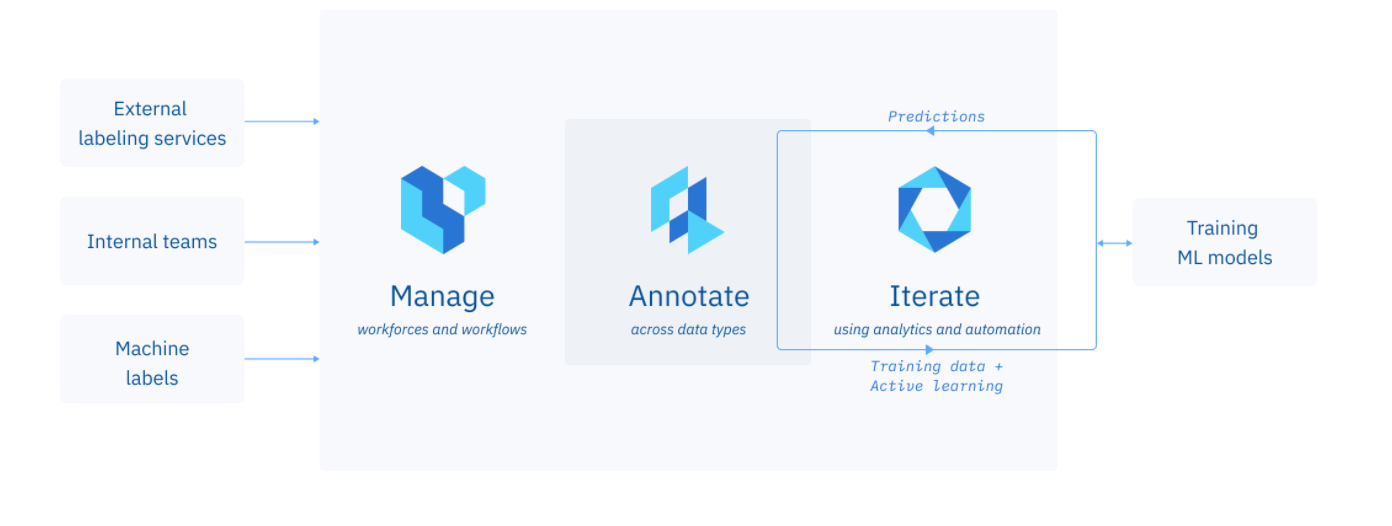
What is a training data platform?
A training data platform enables AI/ML teams to create high quality training data quickly, enabling them to get their algorithms to production faster. Labelbox was built with three specific requirements in mind:
- Annotate: The platform provides configurable tools to annotate several types of data in many different ways
- Manage: It gives ML teams full visibility and control over all the data, people, and processes throughout the labeling pipeline
- Iterate: It empowers teams with multiple workflows to iterate on their training data, so they can create data more likely to increase model performance
How to use the Labelbox connector for Databricks
The presentation included a live demo of how ML teams can use the Labelbox connector for Databricks (available for free on Github) to:
- Import data from Databricks to Labelbox
- Add structure to unstructured data
- Export labeled data back to Databricks for analysis, model training, and more
Watch the recording of the demo below.
How to train your model with your model
Many ML teams are using data warehouses (such as Databricks) and MLOPs platforms (such as MLFlow) to create a reliable pipeline as they develop and train their algorithms. Adding Labelbox to this mix can help teams create high quality training data fast, with multiple advanced workflows.
One of these is model-assisted labeling (MAL), which enables teams to import model outputs as pre-labeled data, which can then be reviewed, corrected, and improved by domain experts or labelers and used to make higher quality training data. Teams can use this workflow to:
- Improve upon the output of the model that they're currently training, or
- Use the output of a generic/off-the-shelf model as a foundation for developing training data for a use case that requires slightly different or more detailed data
In either case, MAL can significantly increase the speed and efficiency with which your ML team creates training data.
Watch the demo and visit our partner page to learn how your can use Labelbox with Databricks. You can also download our guide to discover how to choose a training data platform that significantly improves the quality and efficiency of your ML pipeline.


