×![]()

 All blog posts
All blog postsLabelbox•June 24, 2022
6 key best practices for AI teams to save time when creating AI data
Introduction
One thing all ML teams share is the need to make their data useful for their models. Wading through a vast amount of unstructured data to accurately annotate assets requires a tremendous amount of patience, organization, and time. According to Algorithmia's State of ML Survey, nearly 96% of companies encounter delays getting to production and 78% of machine learning projects stall before deployment. Moving faster is the top pain point we hear from customers; it controls their ability to meet project goals and gain advantage over competitors. Speed is essential to not only get models to production but do so on timelines that meet these increasingly aggressive expectations.
Annotate faster with a dynamic queuing system
AI teams can benefit from speedier annotations by employing a dynamic queuing system that routes labeling tasks to the right team members so they are never sitting idle. With dynamic queuing, teams are able to create labeling workflows where low confidence predictions are visible and prioritized to their data scientists and labelers. This allows you to more quickly analyze and correct labels.

Dynamic queuing allows you to save time by automatically routing labeling tasks to the right team members.
- Only active labelers will be assigned assets to annotate to eliminate duplication and waiting
- Dynamic queuing reserves multiple assets at a time to make sure your labeling team isn’t waiting around in between assets
- The team shares a backlog that’s automatically distributed among labelers and reviewers
Improve collaboration and consensus between teams
To enable better collaboration during the labeling process, teams should look to implement processes and dedicated tooling to make repetitive tasks effortless, such as adding and clarifying feedback on a labeled asset. In order to elicit and clarify feedback, the ability to quickly raise issues and add comments on a labeled asset provides a simple and reliable channel for escalating questions to reviewers or subject matter experts.
A labeler can create an issue to ask a question, submit the label completed to the best of their ability, and receive feedback and clarification during the label review process. This streamlined way of collaborating on labels provides teams with an expedited way to handle inevitable issues that arise during labeling.
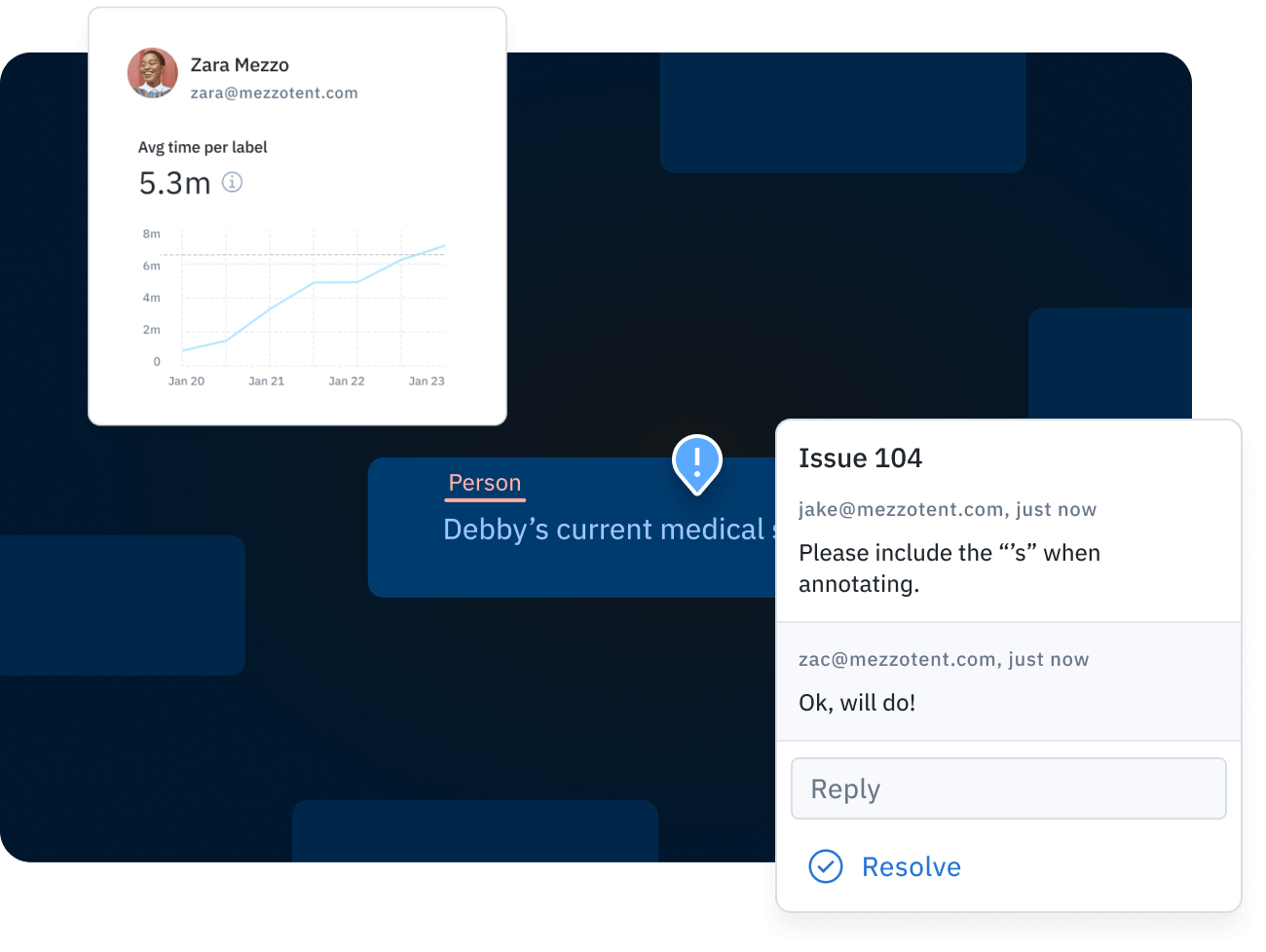
To improve consensus amongst team members, you can quickly drive toward an agreement as a team with a consensus tool that helps you arrive at a shared understanding of what good looks like. This tool allows you to automatically compare annotations on a given asset to all other annotations on that asset. Consistency is measured by the average of the label agreement between labelers. For example, when the consensus is set to 3, every label is grouped with two similar labels and the average of the three becomes the consensus score.
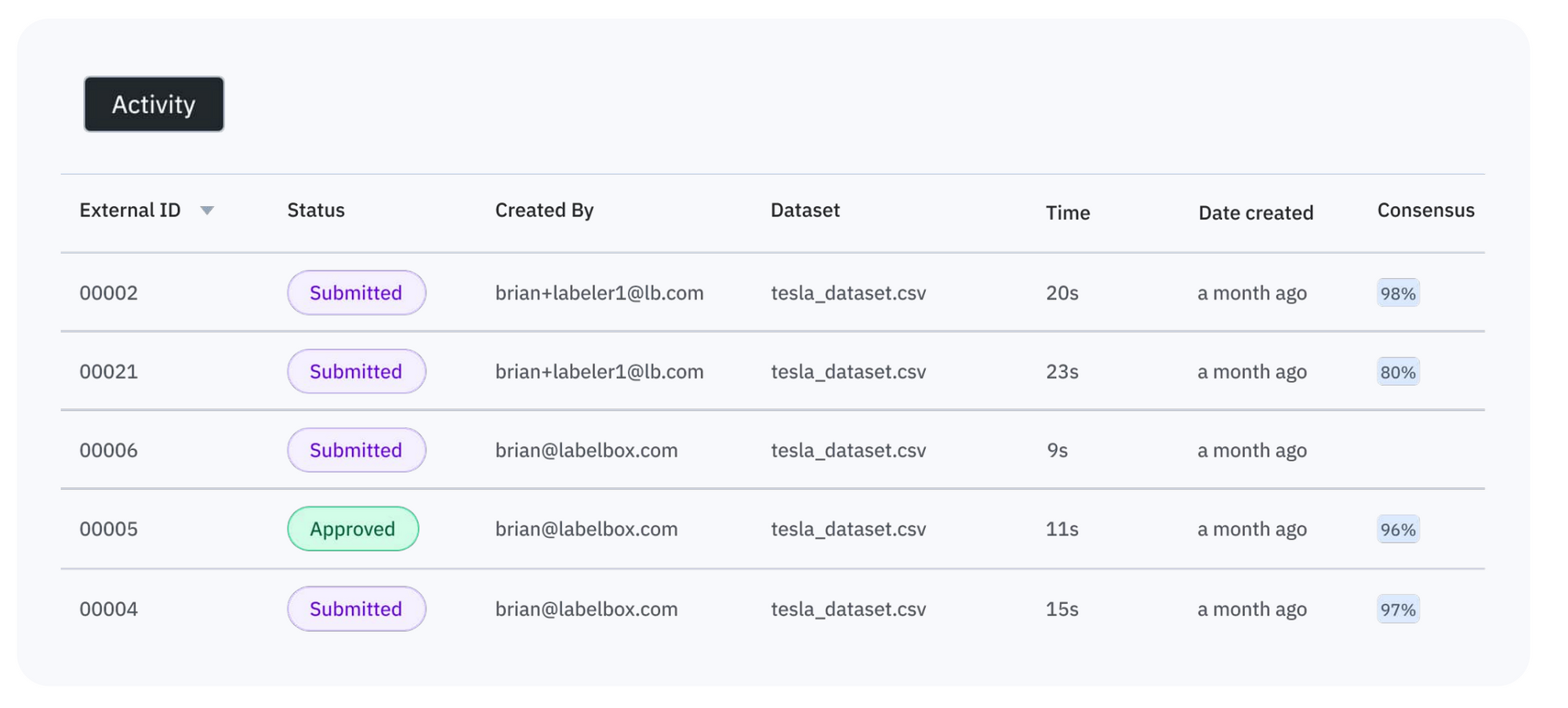
Utilize a programmatic approach for quicker access to data
Teams can now speed up the data import and labeled data export process through the use of a programmatic approach via SDKs and/or APIs rather than slowly handling data transfer methods manually. By connecting your team’s data and automating bulk operations, labeled data (including all the metadata, how the dataset was created, as well as labeler feedback) becomes much easier and quicker to manage and track as the complexity of your projects grows over time. This approach offers endpoint flexibility, so you can plug and play into your existing workflows without losing any valuable aspects of your training data.
One example of how this can be accomplished is through the use of a Python SDK, which offers more control over your data while simplifying and speeding up data import. For example, it simplifies the data import process so that you can use bulk DataRow creation. This process is asynchronous, so you don't have to wait for bulk creation to finish before continuing with other tasks (though you can wait if you want to). In some cases, you can also create projects and datasets programmatically, export labels, and add metadata to your assets all in an object-oriented way with a Python SDK — complete with all relationships between objects, speeding up your labeling workflow. By utilizing this approach, you can even export newly created training data automatically for an active learning workflow and adjust your labeling queue to focus on improving confidence in specific classes.
Leverage software optimized for speed
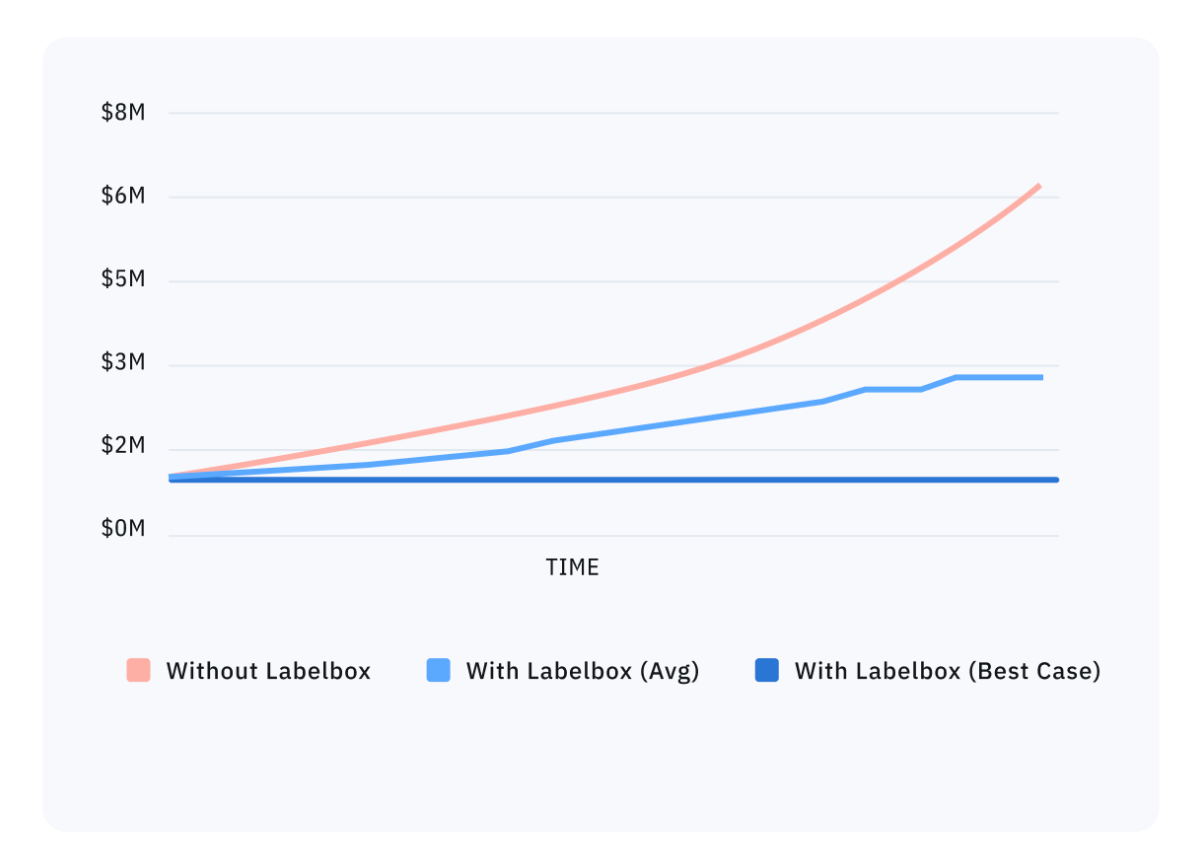
Many ML teams spend a considerable amount of time attempting to build out custom infrastructure for the training data that doesn’t scale and leads to disjointed development efforts. According to research firm Cognilytica, ML teams spend up to 80% of their time building and maintaining training data infrastructure.
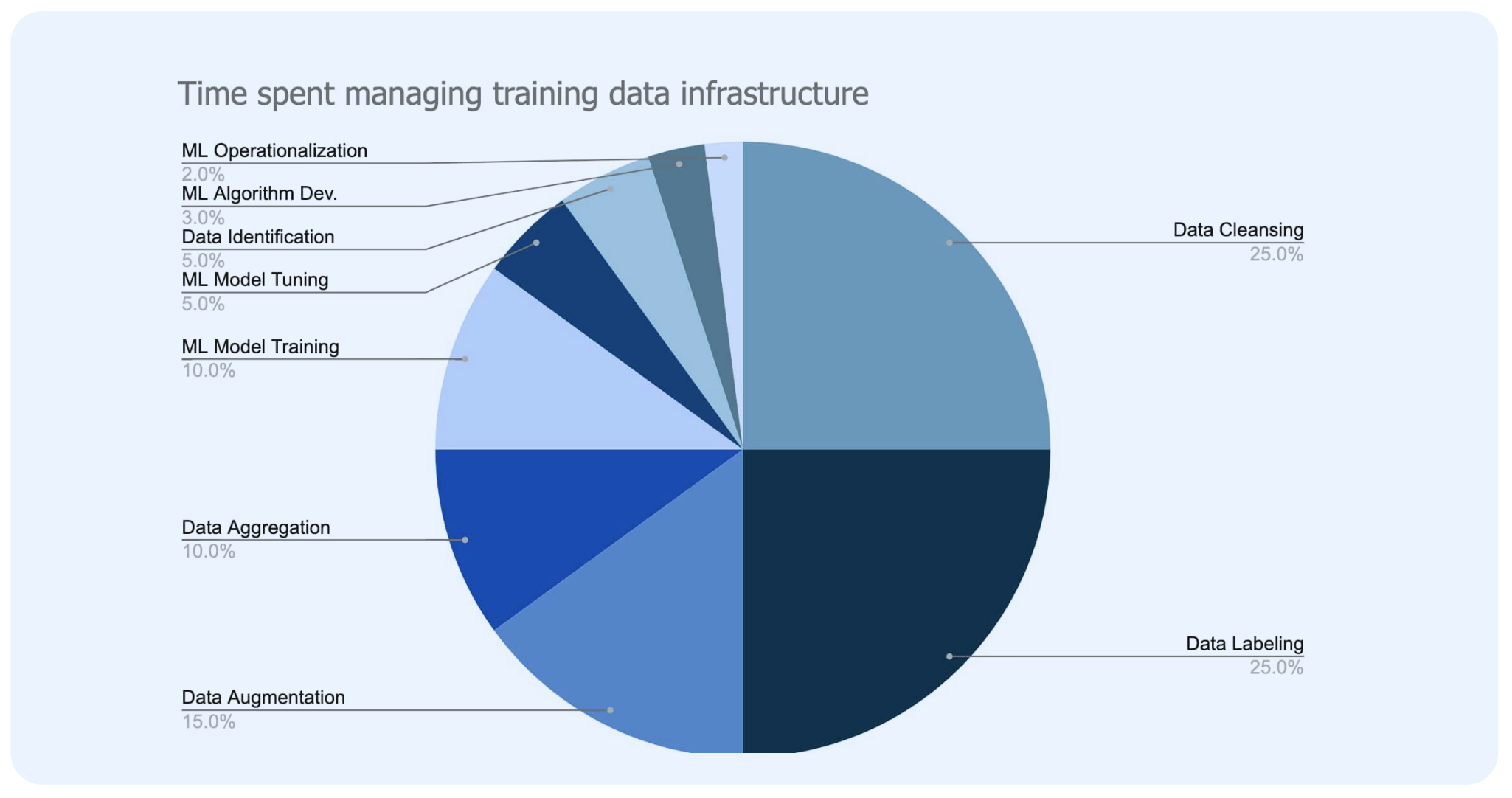
Building such custom infrastructure can be both difficult and expensive, potentially costing millions of dollars in engineering resources to build and maintain. As a time-saving alternative, many teams have found the answer in adopting a data engine. A data engine is purpose-built software engineered for speed and ease of use in handling AI data. It allows teams to move faster with best practices already built in place, rather than home-grown tools and recreating the wheel. By incorporating a data engine, teams save exponential time on data preparation and labeling, so ML teams can spend more time on their core
competency: building production models.
But not all TDPs are created equal. You can learn more about what data engines offer ML teams in The complete guide to data engines for AI, and how to choose the best one for your team by reading our buyer’s guide.
Incorporate automation through model-assisted labeling
Accurately annotating the tens of thousands if not millions of assets necessary to achieve a comprehensive data set has blocked many promising AI initiatives from ever reaching production-ready models. That’s why automation through model-assisted labeling is one of the simplest ways to reduce the waste of precious capital. Model-assisted labeling uses your own model to make labeling easier, more accurate, and faster. In some cases, we’ve seen ML teams save 50-70% on their entire labeling budget by utilizing this method.
Utilize active learning and prioritize the right data
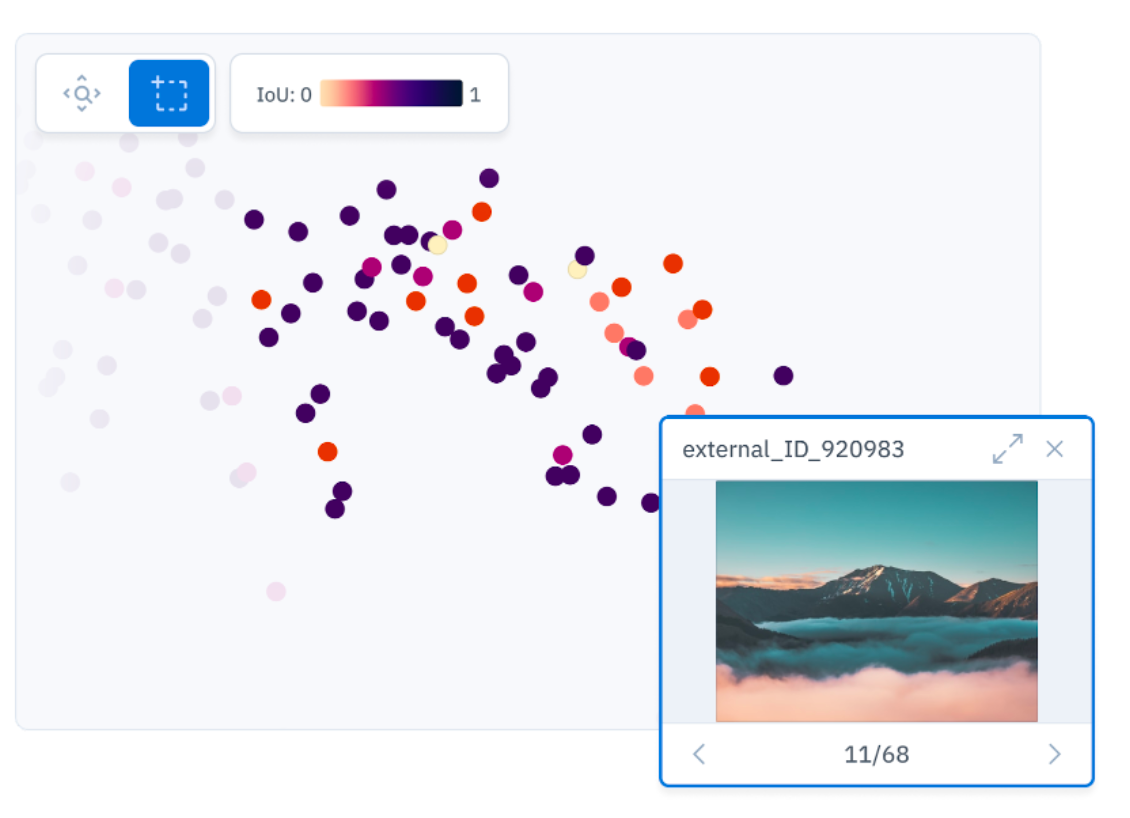
Your team can achieve considerable gains in productivity and efficiency by employing active learning and prioritizing the right data. We’ve seen customers reduce their iteration cycles by up to 8X and use less training data by curating their datasets. Data selection for active learning typically involves selecting rare data or difficult cases. In the case of rare data, models need a minimum number of examples in order to perform well on a chosen task. Without a sufficient number of examples to feed the model, it can be too inefficient to sample data randomly. Using tools like a similarity function with model embeddings can help you to discover more matching data examples. Teams can visually find patterns and identify edge cases in data through the use of model embeddings. By clustering visually similar data, teams can better understand trends in model performance as well as data distribution. While teams can calculate and plot clusters manually, some use cases in ML require more time-sensitive trend detection and a quicker approach. This is where a visual embeddings tool can be helpful to boost model performance and support an active learning workflow.
Additional resources
For a deeper dive into the best practices outlined in this post and see demos of how they work in Labelbox, watch our on-demand webinar, the six best practices to save time when creating AI data. You can also download our guide which goes deeper into the six time-saving practices above.


