×![]()

 All blog posts
All blog postsManu Sharma•April 30, 2020
Active Learning: Speed up training data cycles with uncertainty sampling

Part 1 of a series highlighting Labelbox as a data engine powering your machine learning system.
View on GitHubMachine learning engineers often spend most of their time curating datasets for training models, wading through large (often unbounded) unlabeled datasets while adhering to a budget for annotations and training cycles.
In order to do this efficiently, ML engineers often rely on an active learning framework to surface the most informative data to learn from. If a model is given the most informative training examples, it will reach the desired performance with fewer human annotations and ultimately fewer training cycles.
In Part 1 of this series, we will use Labelbox to implement a simple active learning framework on a relatively easy problem and dataset, resulting in a 40% reduction in human annotation to achieve asymptotic performance.
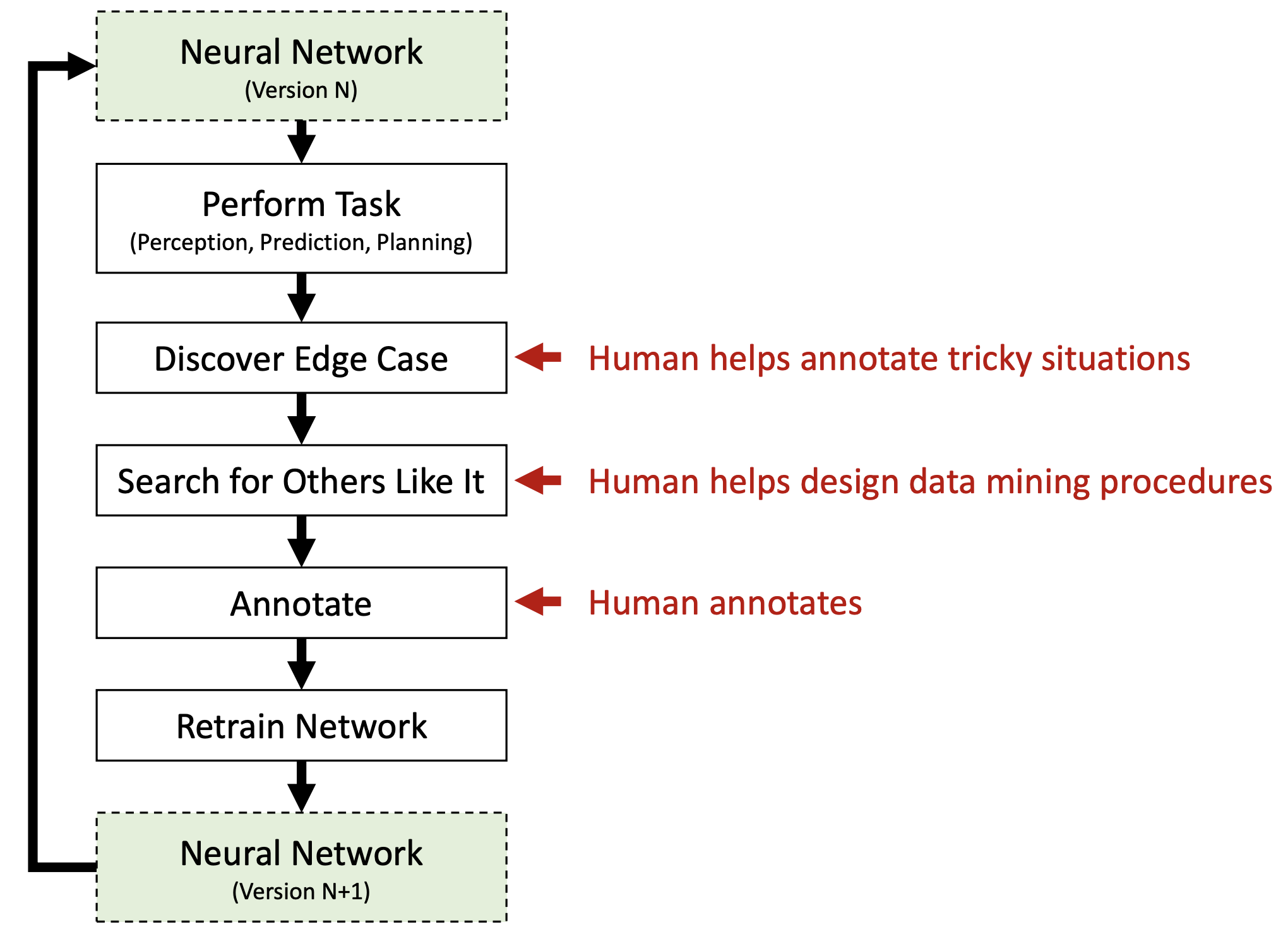
The simplest method for choosing which datarows to prioritize is uncertainty sampling. Under this paradigm, practitioners will define an uncertainty metric to capture datarows for which a model is least confident in its decision and prioritize those examples for annotation and training.
Software dependencies
This notebook can be run using the following Dockerfile and requirements.txt
Build the Docker image locally:
docker build -t active-learning-part-1 .Launch the image with access to this notebook from within the current directory:
docker run -it -p 8888:8888 -v \
${PWD}:/usr/src/app -w /usr/src/app active-learning-part-1 \
jupyter notebook --ip 0.0.0.0 --no-browser --allow-rootDataset
Sentiment analysis on tweets taken from Twitter is a well-explored and tractable Natural Language Processing (NLP) problem. For this example, we take 8,000 random tweets from the sentiment140 dataset that are already classified as positive (0) or negative (4) sentiment. The derived 8000 random tweets csv is included for reference and was created by sorting randomly and then taking the first 8000 rows:
sort -R training.1600000.processed.noemoticon.csv > training.1600000.processed.noemoticon.csv.shuffled
head -8000 training.1600000.processed.noemoticon.csv.shuffled > training_8000_shuffled.csvIngest into Labelbox
First, we need to label a subset of data with Labelbox. To do so, we need to:
- Create a project
- Create and upload our dataset
- Configure the Labelbox text classification editor
from collections import defaultdict
from enum import Enum
from itertools import chain, islice
import json
import os
from typing import Callable, Dict, List, Tuple
from labelbox import Client, Dataset, LabelingFrontend, Project, DataRow
from labelbox import schema
import matplotlib.pyplot as plt
from matplotlib.legend import Legend
import numpy as np
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_auc_score
from sklearn.metrics.pairwise import cosine_similarity
from sklearn.model_selection import train_test_split
import subprocess
from transformers import DistilBertModel, DistilBertTokenizer
import torchLABELBOX_API_KEY = <LABELBOX_API_KEY>We start by loading our 8000 tweets into a DataFrame, taking 800 for our validation set and 7200 for our training set.
RANDOM_SEED = 123
DATA_DIR = 'data'
def load_non_weather_data():
data = pd.read_csv(
filepath_or_buffer=os.path.join(DATA_DIR, 'training_8000_shuffled.csv'),
names=["target", "ids", "date", "flag", "user", "text"],
encoding='ISO-8859-1'
)
data.rename(columns=
{
'target': 'sentiment',
'ids': 'id'
}, inplace=True
)
# 0 is positive
# 4 is negative in the original dataset, use 1 for clarity
data.sentiment = data.sentiment.map({0: 0, 4: 1}).values
return data
def train_val_split(df, test_frac: float):
test_rows = df.sample(frac=test_frac, random_state=RANDOM_SEED)
df['split'] = df.id.apply(lambda row: 'test' if row in test_rows.id.values else 'train')
return dfSENTIMENT_DF = load_non_weather_data()
SENTIMENT_DF = train_val_split(SENTIMENT_DF, 0.1)# labelbox setup names
PROJECT_NAME = 'tweet_sentiment_demo'
DATASET_NAME = 'tweet_sentiment_demo'
LABELING_FRONTEND_NAME = "Binary sentiment editor"
def maybe_create_project(project_name: str) -> schema.project.Project:
'''Creates project if it does not already exist, otherwise fetches.
NOTE: we assume there is only one project with a given
project name. this is not guaranteed, but sufficient
for a tutorial.
'''
client = Client(LABELBOX_API_KEY)
projects = client.get_projects(where=Project.name == project_name)
try:
project = next(iter(projects))
except StopIteration:
project = client.create_project(name=project_name)
return project
def sentiment_df_to_json_rows(dataframe: pd.core.frame.DataFrame) -> Dict[str, str]:
'''Converts dataframe rows to json rows.'''
return json.loads(
dataframe.rename(
columns={'id': 'external_id', 'text': 'row_data'}
)[['external_id', 'row_data']].to_json(orient='records'))
def maybe_create_sentiment_dataset(
dataset_name: str,
project_name: str,
dataframe: pd.core.frame.DataFrame) -> schema.dataset.Dataset:
'''Creates our sentiment dataset with 80k datarows if it does not already exist, otherwise fetches.
'''
client = Client(LABELBOX_API_KEY)
project = maybe_create_project(project_name)
datasets = client.get_datasets(where=Dataset.name == DATASET_NAME)
try:
dataset = next(iter(datasets))
def attach_dataset(project_id: str, dataset_id: str) -> None:
response = client.execute(f'''
mutation AttachDataset{{
updateProject(
where:{{
id: "{project_id}"
}},
data:{{
datasets: {{
connect: {{
id: "{dataset_id}"
}}
}}
}}
){{
id
}}
}}
''')
attach_dataset(project.uid, dataset.uid)
except StopIteration:
dataset = client.create_dataset(name=DATASET_NAME, projects=project)
try:
next(iter(dataset.data_rows()))
except StopIteration:
task = dataset.create_data_rows(sentiment_df_to_json_rows(dataframe))
task.wait_till_done()
return dataset
def update_with_uid(
dataframe: pd.core.frame.DataFrame,
dataset: schema.dataset.Dataset) -> pd.core.frame.DataFrame:
"""Add uid column for tracking labelbox's id of the same datarow in our dataframe.
Args:
df: dataframe to augment
project_name: project name for dataset
dataset_name: name for dataset
"""
external_uid_map = {
int(data_row.external_id): data_row.uid
for data_row in dataset.data_rows()
}
dataframe['uid'] = dataframe.id.map(external_uid_map)
return dataframe
def create_labeling_frontend() -> str:
'''Creates a labeling frontend and returns its id.'''
client = Client(LABELBOX_API_KEY)
response = client.execute('''
mutation CreateLabelingFrontend ($name: String! ){
createLabelingFrontend(data: {
description: "Classify sentiment as positive or negative",
iframeUrlPath: "https://classification.labelbox.com",
name: $name
}){
id
}
}
''', {'name': LABELING_FRONTEND_NAME})
return json.loads(response)['data']['CreateLabelingFrontend']['id']
def maybe_create_ontology(project_name: str) -> None:
'''Creates/grabs ontology for sentiment annotation.
1. Sets up ontology for binary sentiment classification.
2. Sets labeling frontend using the classification iframe.
3. Links these with the given project.
'''
client = Client(LABELBOX_API_KEY)
project = maybe_create_project(project_name)
ontology = '''
{
"tools": [],
"classifications": [
{
"name": "Sentiment",
"instructions": "Is this tweet primarily positive or negative in sentiment?",
"type": "radio",
"options": [
{
"value": 0,
"label": "Negative"
},
{
"value": 1,
"label": "Positive"
}
]
}
]
}
'''
frontends = client.get_labeling_frontends(where=LabelingFrontend.name == LABELING_FRONTEND_NAME)
try:
frontend = next(iter(frontends))
except StopIteration:
frontend_id = create_labeling_frontend()
frontends = client.get_labeling_frontends(
where=LabelingFrontend.id == frontend_id)
frontend = next(iter(frontends))
project.setup(frontend, ontology)We create a project named PROJECT_NAME with a dataset named DATASET_NAME using our API key, LABELBOX_API_KEY. After uploading our 8000 tweets to Labelbox, we update our DataFrame with the DataRow.uid to keep track of uid's given by Labelbox. To finish project setup, we link it with a labeling frontend and ontology specifically for Text Classification.
dataset = maybe_create_sentiment_dataset(dataset_name=DATASET_NAME, project_name=PROJECT_NAME, dataframe=SENTIMENT_DF)
update_with_uid(SENTIMENT_DF, dataset)
maybe_create_ontology(PROJECT_NAME)
Since our dataset already includes sentiment classifications, we can proceed as if we already annotated 100 tweets and train a preliminary model on these 100 tweets.
Training a model
Thanks to advances in deep learning for NLP, we do not have to train a language model from scratch. We use a distilled version of BERT: DistilBERT (created by Hugging Face) to generate embeddings of our tweets. We then pool these embeddings together and treat them as features for a logistic regression to learn sentiment.
Note: Depending on the hardware this is run on, embedding 8,000 tweets may take 15-20 minutes.
model = DistilBertModel.from_pretrained("distilbert-base-uncased", cache_dir='model_dir')
tokenizer = DistilBertTokenizer.from_pretrained("distilbert-base-uncased", cache_dir='model_dir')
def encode_text(text):
'''Embed text with DistilBERT and return average pool.
Note: YMMV with average pool vs max pool. average pool was just chosen for simplicity.
'''
input_ids = torch.tensor([tokenizer.encode(text)])
return model(input_ids)[0].mean(1)[0].detach().numpy()
def add_encoded(df: pd.core.frame.DataFrame) -> pd.core.frame.DataFrame:
'''Add features encoded by DistilBERT and an average pool as a column.'''
df['encoded_text'] = df.text.apply(encode_text)
return df
def train_model(train: pd.core.frame.DataFrame) -> LogisticRegression:
'''Trains logistic regression model over given training data.'''
model = LogisticRegression(solver="liblinear")
model.fit(list(train.encoded_text.values), list(train.sentiment.values))
return model
def eval_model(model: LogisticRegression, test: pd.core.frame.DataFrame) -> float:
'''Calculates AUC of the ROC of the trained model on given test data.
https://en.wikipedia.org/wiki/Receiver_operating_characteristic#Area_under_the_curve
'''
# auc score entire over test split
roc = roc_auc_score(
list(test.sentiment.values),
model.predict_proba(list(test.encoded_text.values))[:,1])
return rocSENTIMENT_DF = add_encoded(SENTIMENT_DF)
train = SENTIMENT_DF[SENTIMENT_DF.split == 'train']
test = SENTIMENT_DF[SENTIMENT_DF.split == 'test']
We begin our first iteration by prioritizing any 100 datarows for human annotation via Queue customization in Labelbox.
- Set priority of 100 datarows to 1
- Set priority of the remainder datarows to 2
Note: Priority for all datarows should be set, otherwise the queue may default to lexicographical resolution of priority.
def fetch_labeling_parameter_overrides(project_name: str) -> List:
'''Fetches all datarows with labeling parameter overrides in a project.'''
project_id = maybe_create_project(project_name).uid
client = Client(LABELBOX_API_KEY)
overrides = []
override = True
while override:
response = client.execute(
f'''
query pullLabelingParameters{{
project(where: {{id: "{project_id}"}}) {{
labelingParameterOverrides{{
id
priority
}}
}}
}}
'''
)
override = json.loads(response)['data']['project']['labelingParameterOverrides']
overrides.extend(override)
return overrides
def prioritize(project_name: str, dataset_name: str, uids: List[str]) -> None:
'''Prioritizes given uids for labeling and deprioritizes all other.
NOTE: We have to deprioritize so that we don't rely on queue rebuilding to
avoid default lexicographical sorting.
> When setting queue prioritization on an active queue, and without the queue rebuilding,
the given data rows will have their priority updated, and if there’s a collision
(as in above, where two data rows have a priority of 1), they will be ordered lexicographically.
https://labelbox.com/docs/api/queue-customization#setting_queue_prioritization
'''
project_id = maybe_create_project(project_name).uid
dataset = maybe_create_sentiment_dataset(
dataset_name=dataset_name,
project_name=project_name,
dataframe=SENTIMENT_DF)
priority_data_rows = (
f'{{dataRow: {{id: "{uid}"}}, priority: 1, numLabels: 1}}'
for uid in uids
)
rest_data_rows = (
f'{{dataRow: {{id: "{data_row.uid}"}}, priority: 2, numLabels: 1}}'
for data_row in dataset.data_rows()
if data_row.uid not in uids
)
data_rows = chain(priority_data_rows, rest_data_rows)
client = Client(LABELBOX_API_KEY)
def batches(iterable, size):
iterator = iter(iterable)
for first in iterator:
yield chain([first], islice(iterator, size - 1))
for batch in batches(data_rows, size=999):
response = client.execute(
f'''
mutation setLabelingParameterOverrides {{
project(where: {{ id: "{project_id}" }}) {{
setLabelingParameterOverrides(data: [
{','.join(batch)}
]) {{
success
}}
}}
}}
'''
)
assert not response.get('errors')prioritize(PROJECT_NAME, DATASET_NAME, SENTIMENT_DF.head(100).uid.to_list())
When these datarows are labeled, we would export them via bulk export or webhooks. However, for this walkthrough, we can just take the first 100 from the already labeled data.
annotation_budget = 100
labeled_training_data = train[:annotation_budget]
model = train_model(labeled_training_data)
roc = eval_model(model, test)
print(f'ROC: {roc}')ROC: 0.728004201286644
Uncertainty sampling
We will employ a fairly straightforward definition of model uncertainty: one minus the largest posterior probability of our model. The intuition here is: given the highest posterior probability is the model's prediction, we take the remaining probability left until the model would have been 100% certain as the uncertainty.
def uncertainty_score(
rows: pd.core.frame.DataFrame,
model: LogisticRegression) -> float:
'''Returns uncertainty of the model on given data.'''
return 1 - model.predict_proba(list(rows.encoded_text)).max(1)For the subsequent batches of annotations, we will pick the top 100 datarows for which the model is the most uncertain. For demonstration's sake, we work with our already labeled dataset. In reality, one would continue employing the above outlined prioritization via Queue customization in Labelbox.
def naive_sampler(
sample: pd.core.frame.DataFrame,
train: pd.core.frame.DataFrame,
num: int, _) -> pd.core.frame.DataFrame:
'''Returns the next number of datarows that have not been trained on.'''
untrained = train[~train.index.isin(sample.index)]
return pd.concat([sample, untrained.head(num)])
def uncertainty_sampler(
sample: pd.core.frame.DataFrame,
train: pd.core.frame.DataFrame,
num: int,
model: LogisticRegression) -> pd.core.frame.DataFrame:
'''Returns the top number of most uncertain datarows.'''
untrained = train[~train.index.isin(sample.index)]
def uncertainty_sampling(
rows: pd.core.frame.DataFrame,
num: int,
model: LogisticRegression) -> pd.core.frame.DataFrame:
temp_df = rows.copy()
temp_df['uncertainty'] = uncertainty_score(rows, model)
temp_df = temp_df.sort_values('uncertainty', ascending=False)
return temp_df[:num]
return pd.concat([sample, uncertainty_sampling(untrained, num, model)])
def batch_roc(
train: pd.core.frame.DataFrame,
batches: List[int],
sampling_method: str) -> List[float]:
'''Returns ROC metric for every addition to the training data.
The sampling_method will dictate how new data is selected
for labeling and inclusion into training data.
'''
SAMPLING_METHODS = {
'naive': naive_sampler,
'uncertainty': uncertainty_sampler
}
rocs = []
batch_size = batches[1] - batches[0]
sample = train[:batch_size]
for _ in batches:
model = train_model(sample)
roc = eval_model(model, test)
#roc = eval_model(model, train)
rocs.append(roc)
sample = SAMPLING_METHODS[sampling_method](sample, train, batch_size, model)
return rocsWe compare uncertainty sampling against naive sampling where random data is selected at every iteration until all training data is labeled and trained over.
batch_size = 100
batches = np.arange(100, len(train), batch_size)
naive_rocs = batch_roc(train, batches, 'naive')
uncertainty_rocs = batch_roc(train, batches, 'uncertainty')
fig, ax = plt.subplots()
lines = [
ax.plot(batches, uncertainty_rocs, '-', color='blue', label='uncertainty sampling'),
ax.plot(batches, naive_rocs, '--', color='black', label='random sampling'),
]
ax.set_xlabel('# of labeled data in training set')
ax.set_ylabel('ROC on test set')
plt.legend()
plt.grid()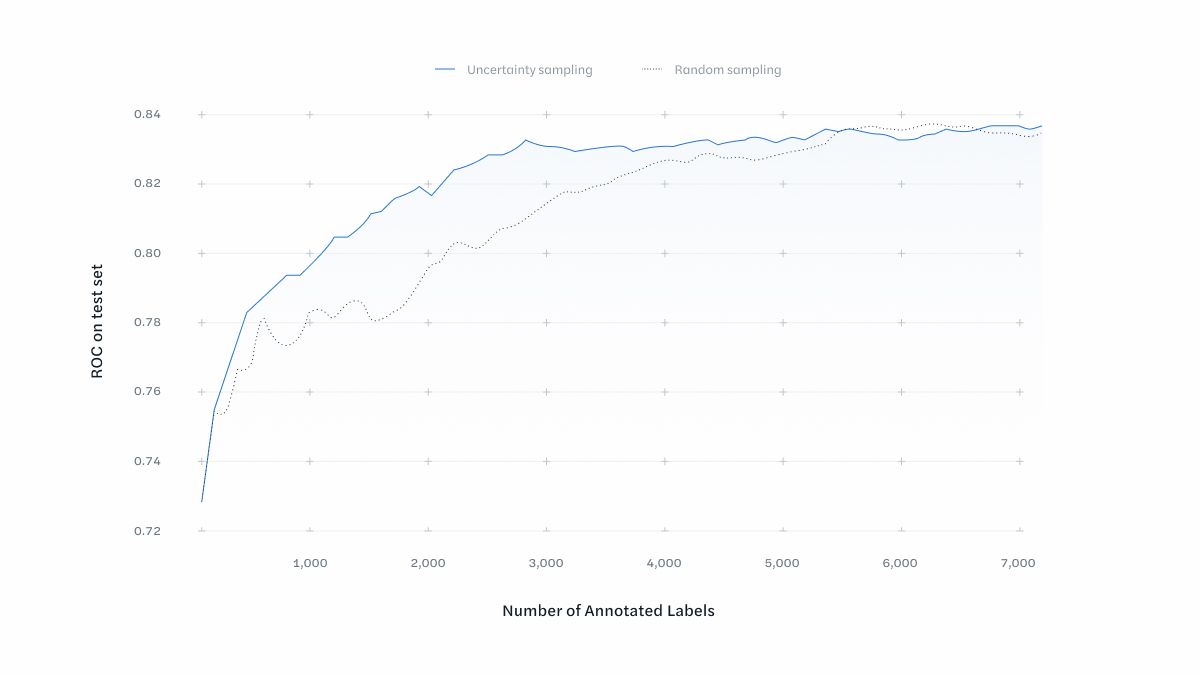
The model trained with training examples chosen by uncertainty sampling is able to reach asymptotic performance with around 3,000 annotations, 40% fewer than the model trained by naive random sampling. Not only does this minimize the number of assets that require human annotation, it minimizes the number of examples the model has to be trained with, the time required to train the model to satisfactory performance.
Conclusion
Queue customization in Labelbox is an incredibly simple way to start using active learning. By prioritizing certain datarows for annotation, machine learning systems can achieve their goals with less annotation cost and fewer training cycles. In many cases, the datarows that a model is uncertain of are also often more engaging to annotate and more important to review, allowing the human components of your machine learning system to spend their time on high impact decisions.
Next Steps
Practical considerations
Modern neural networks are deeper and datasets are larger; retraining may neither be ideal nor necessary. Active learning is also a useful tool for transfer learning or fine tuning frameworks. Tasks beyond classification can also benefit, such as image segmentation, named entity recognition, etc. We encourage you to seek domain specific literature for inspiration.
For example, there are other ways of measuring uncertainty, such as classification entropy or classification margin. Or you may wish to differentiate between epistemic and aleatoric uncertainty. In fact, uncertainty sampling is far from the only way of surfacing informative examples.
For ensemble-based approaches, disagreement sampling may be more useful, surfacing examples where the ensemble is highly disagreeable.
For datasets with a long tail of rare examples, diversity sampling proposes representative examples for prioritization, exposing the most diverse examples for model training.
How might queue customization speed up your training iteration cycles?
- Prioritizing rare examples?
- Prioritizing complicated examples?
- Tell us more; reach out to us!
How can Labelbox help?
- Surface informative datarows for your dataset for training or review?
- Aid exploration of your dataset based on metadata associated with each datarow?
- Tell us more; reach out to us!


