
 All blog posts
All blog postsBrian Rieger•October 30, 2020
Automating Computer Vision Annotation: Let Your Model Do The Work.
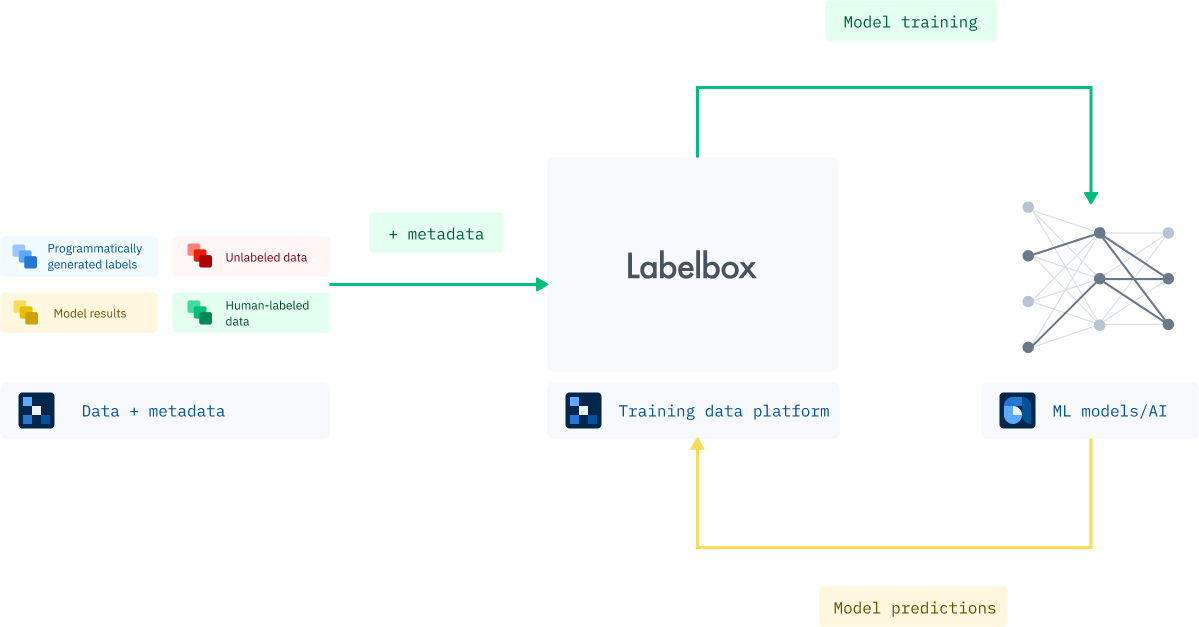
Almost anyone working on computer vision applications these days struggles with the same problem: how to speed up data labeling, the most expensive and time-consuming part of developing a supervised machine learning system. It doesn’t stop when a machine learning system goes into production. In fact, it can grow.
The answer, of course, is automation - letting the computer do most of the work so that humans only need to complete it.
But not all automated solutions are the same. The best, by far, are those that use the model you are building to help do the labeling for you.
Sound like a circular argument?
Consider this: there are three basic ways to automate labeling depending on how aware the method is of the data to be labeled.
DATA UNAWARE
The simplest is to use an algorithm such as a graph cut – let’s call this a data-unaware method. The algorithm knows nothing about the data or what the labeler is looking for to label. It is concerned only with the numeric values of contiguous pixels. It’s fine for segmentation, but for complex segmentation, even with strongly contrasted boundaries, the human work of correcting the automated segmentation can be more than simply tracing the boundary by hand.
DATA SEMI-AWARE
Make the method more aware of the data, however, and the results improve. For example, an off-the-shelf, convolutional neural network trained on a public dataset can recognize standard objects – people and animals, cars and bicycles. That may get you part way to labeling what you want, reducing the time – and work – required. Call this a data semi-aware system.
DATA FULLY AWARE
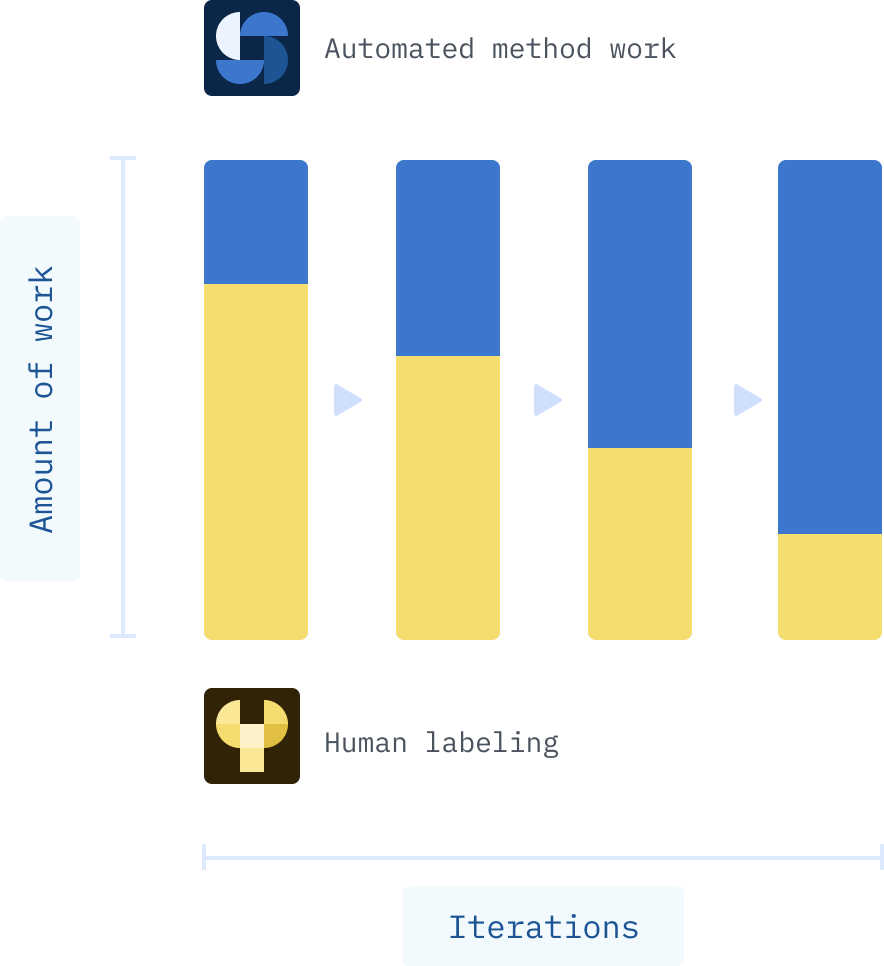
But for more complex labeling tasks – and labeling tasks are increasingly complex today – you’re better off with a method that is fully aware of your data. A standard convolutional neural network might be all you need, but to make it fully data aware, it must be trained on your data set.
Take a company like SmartVid, for example. Their computer vision systems monitor construction sites for safety compliance, among other things. A convolutional neural network trained on a public data set can recognize humans, and this might be enough to train a system to monitor social distancing. But if SmartVid wants to monitor mask-wearing, they’ll have to employ people to check each human in the data and label whether they are wearing a mask or not. As the volume of mask-wearing labels grows, however, that data can be used to train the model to pre-label mask-wearing humans, further reducing the hand-labeling work required.
REDUCING HUMAN WORK OVER TIME
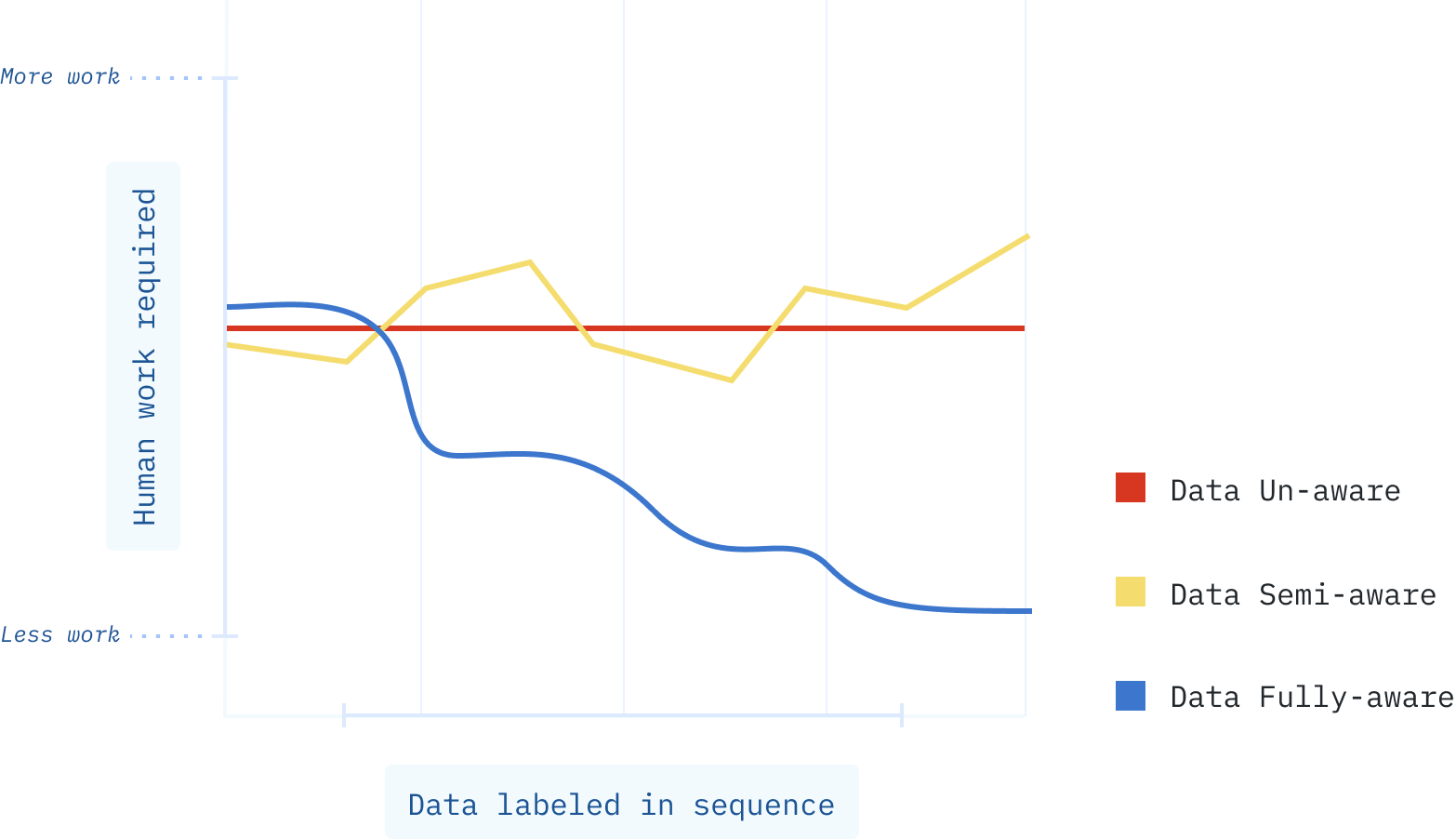
The performance of data unaware systems is consistent over time and data semi-aware system performance is either consistent or degrades as the labeling requirements become more complex over time. But data fully aware systems get better with time, as labeled data is fed back into the model.
This is particularly useful when labeling requires expensive expertise. A computer vision model built to diagnose lung cancer, for example, needs to be trained on lung scans labeled by experienced radiologists. Over time, the model learns to pre-label the scans and once the pre-labeling is accurate enough, the task can be turned over to less skilled – and less expensive – workers to verify the automated labels.
Another data fully aware method would involve a two-step process. A pathologist, for example, might mark a contiguous group of cancer cells as a first step, and then a less-skilled group of workers might outline the malignant cells. In this case, a predictive model trained on the pathologist-labeled data can learn to pre-label groups of cells as cancerous, speeding up the work of the pathologist. A second predictive model trained on the data in which groups of cells have been outlined, can pre-draw segmentation boundaries around those cells, speeding up the second step as well.
SMART TRAINING DATA PLATFORM VS AUTOMATED LABELLING SERVICE
Some companies are beginning to offer these solutions as a service: you start labeling on their platform, and their semi-aware model quickly becomes fully aware as it learns exactly what you're labeling.
But beware. Labeled data is your most important IP and if a vendor is training their model on your data set, they are, in effect, creating their own instance of your model. You don’t have access to the vendor’s model. The vendor’s model is running opaquely, inside of the platform that you're using on the web. Their model might be even better than your own.
A better way is to use a training data platform, or TDP, that can integrate your model into the labeling workflow so that you control the creation of the pre-labeled data that human labelers check.
You start with your proprietary data set, your model and a team of labelers and quickly the model learns what you want to label and feeds pre-labeled data to the human labelers who feed the labeled data back to the training data set in a positive feedback loop. Soon, your model is pre-labeling the data for you, steadily reducing the human work involved and speeding up iterations of your model. Neither the TDP nor the labeling team ever get a copy of the model.
This method also offers greater flexibility. You may want to run multiple models on the data, or you may want to change your model midstream. A smart TDP gives you full control.
CONCLUSION
The world is facing a tsunami of data that needs to be labeled as supervised learning spreads through the global economy. No industry can escape it. Algorithms and computing power are now commodities. Quality labeled data has become the most important differentiator in any supervised learning system. A flexible TDP that allows model integration with a positive feedback loop that pre-labels data will speed the labeling process. Those companies that label fast and label accurately will ride the wave to success. Those who fall behind, will drown.


