×![]()

 All blog posts
All blog postsLabelbox•March 2, 2023
Explore new public datasets, surface and save data slices

One of the biggest challenges for AI teams is being able to select the right data to train models or for your use case. This month, we are releasing several updates to help you better visualize and explore your data so that you can make more informed decisions on how to organize and prioritize your growing data.
Explore assets from public datasets
Like many of you, we’ve encountered the challenges of dealing with public datasets — whether you just want to easily browse them to see the data or need to find data within specific parameters or a query. Leveraging Catalog as its foundation, you can now search, explore, and browse large-scale datasets.
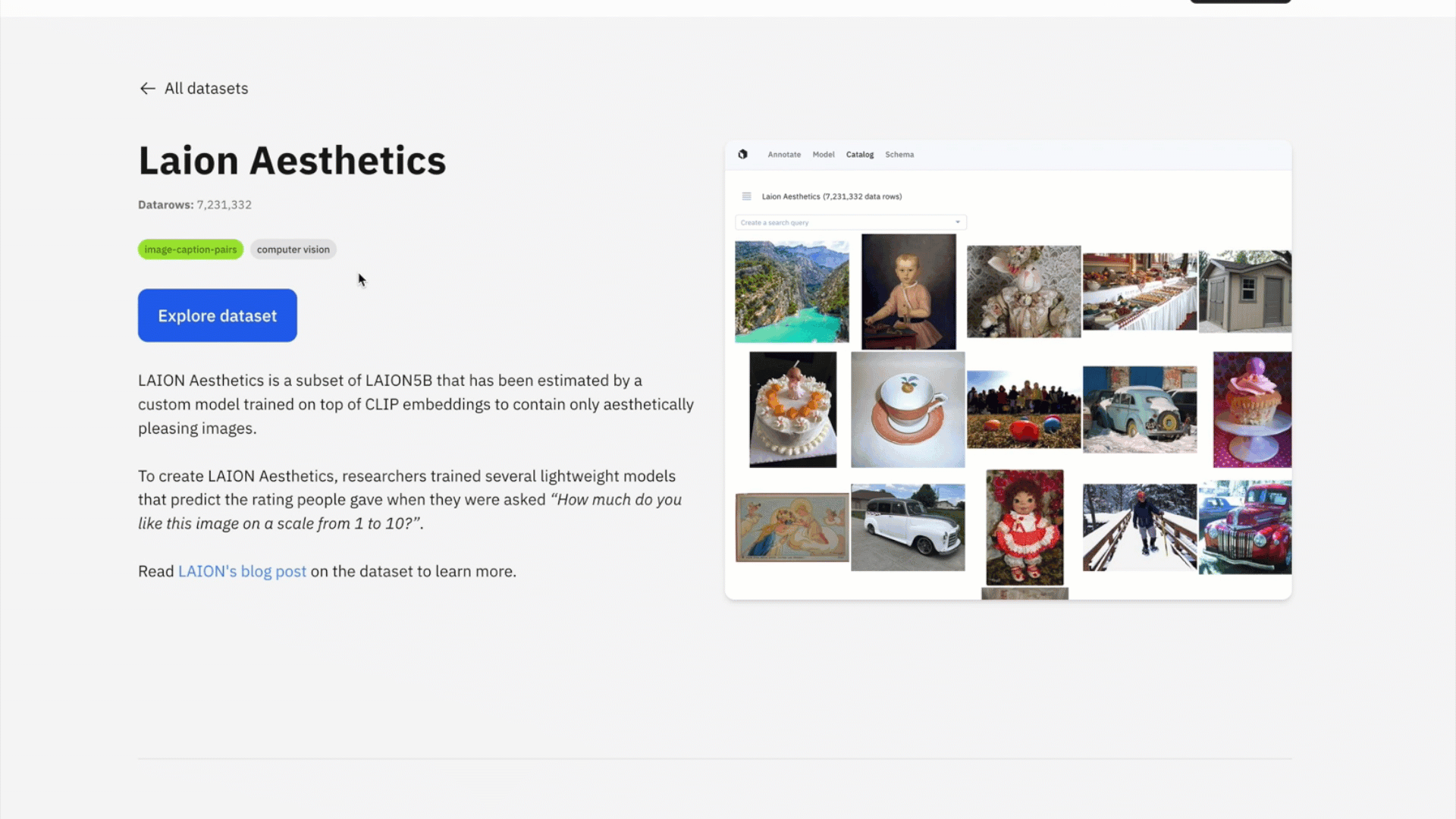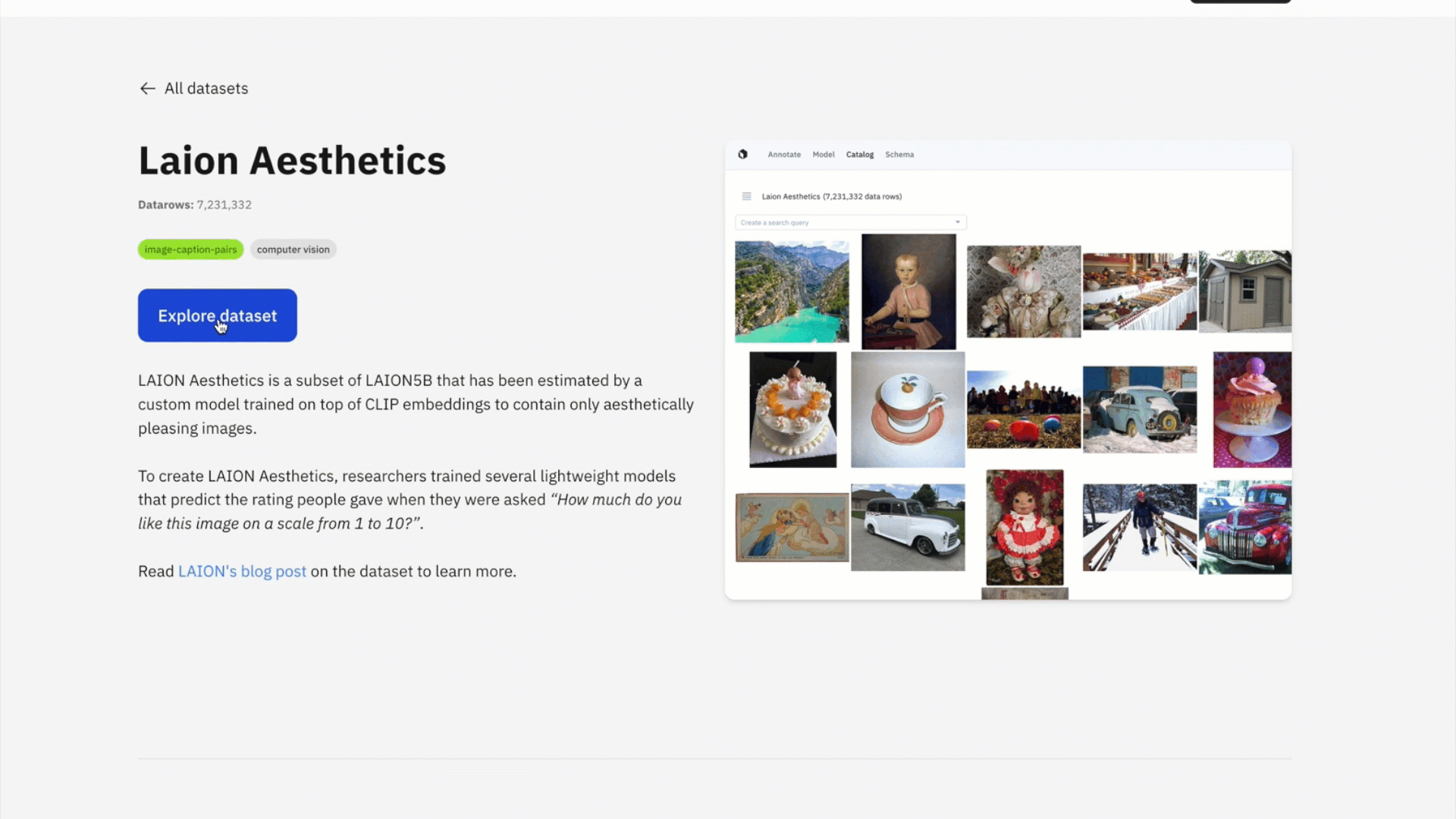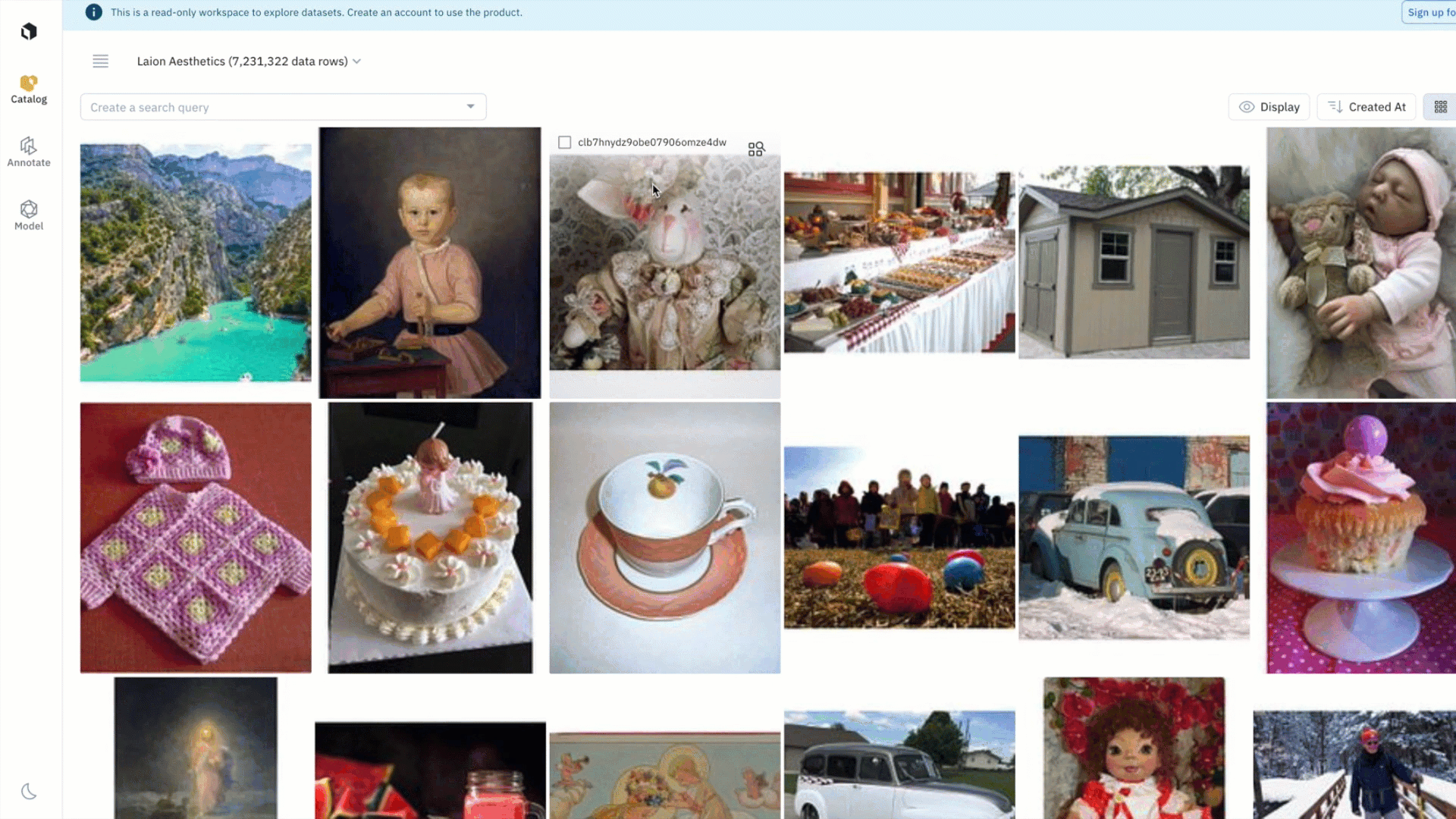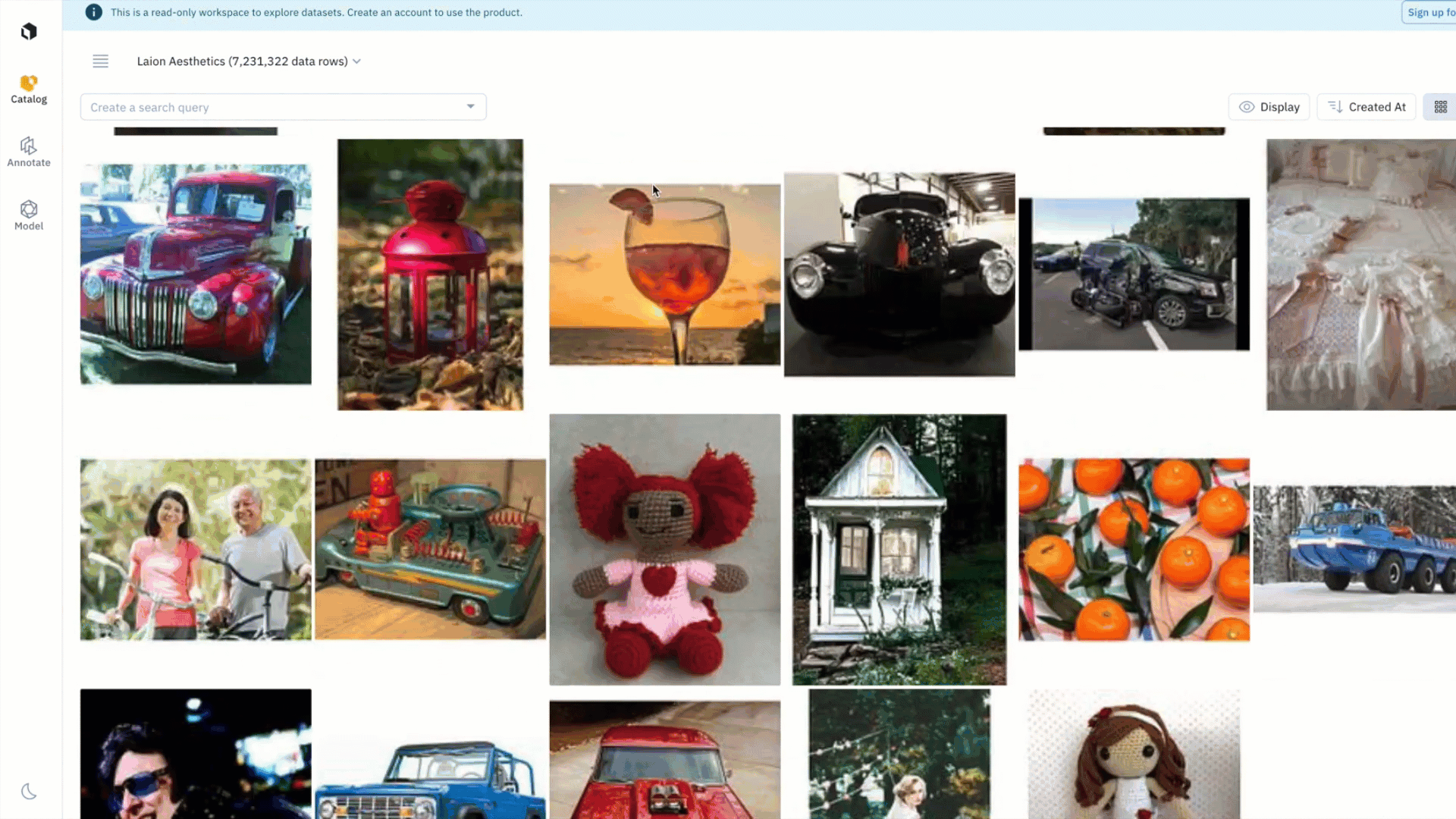
Discover, browse, and gain inspiration from innovative AI datasets that can inform your own pipeline. You can rapidly browse, visualize, organize and analyze petabytes of publicly-available datasets across diverse use cases and modalities.
- Discover and stay up to date on the latest innovative datasets without downloading large files
- Browse multiple public datasets without navigating GitHub repos, Command Lines, or Jupyter notebooks
- Explore datasets that you find interesting by layering filters in Catalog
To learn more about public datasets, you can read our latest blog post.
Surface data with natural language search
In addition to searching for data rows in Catalog by metadata, annotations, similarity, or dataset, you can now use natural language to find a specific subset of data rows. Rather than flying blind, this lets you easily:
- Evaluate the frequency of model failures
- Find more examples of rare or “difficult” data
- Assess your current data in the context of your business goals
By leveraging natural language search and other filters in Catalog, you can:
Capture the complexity of your use case: Layer natural language search with other structured search filters (such as metadata, annotations, media type, etc.) to better refine and organize your data.
Explore your ever-growing store of data: As your data grows, you can leverage natural language search and other filters in Catalog to query tens of millions of assets at scale.
Quickly gain insights from your data: Return search results on 10 million assets in as quick as 3 seconds.
Powered by CLIP embeddings, simply type an English text query to bring up all instances of images that match the description of the phrase:
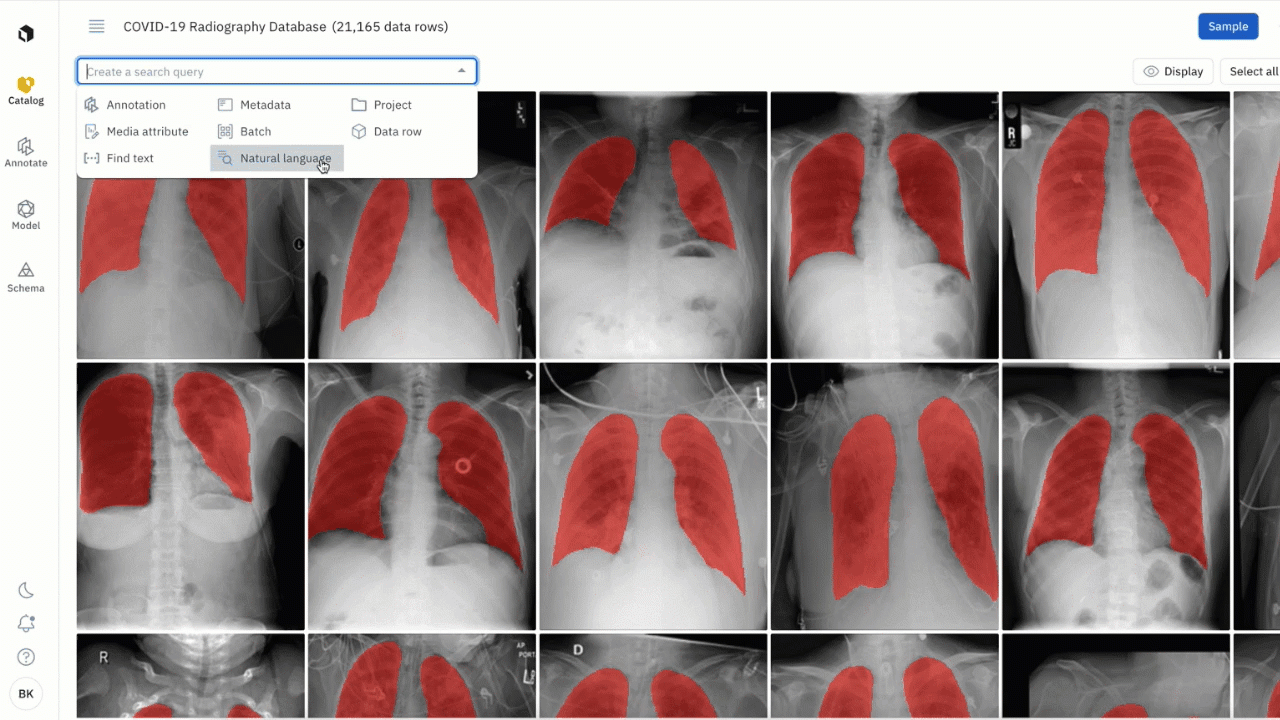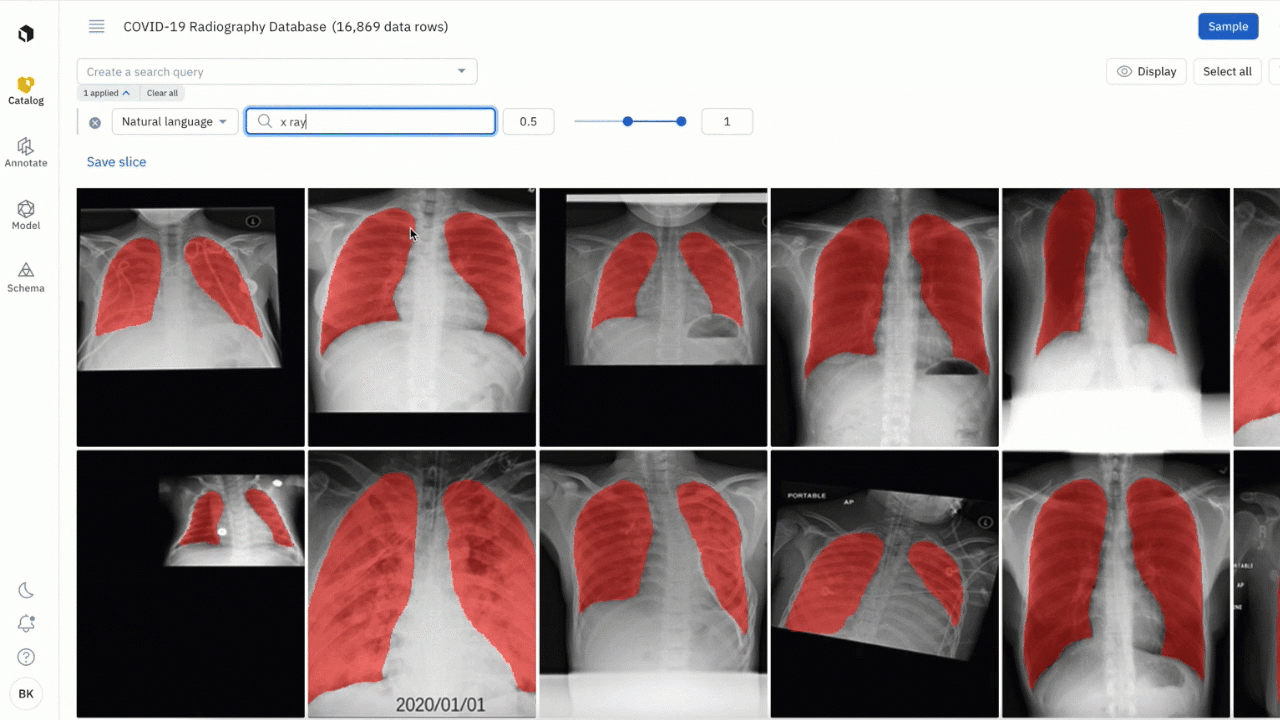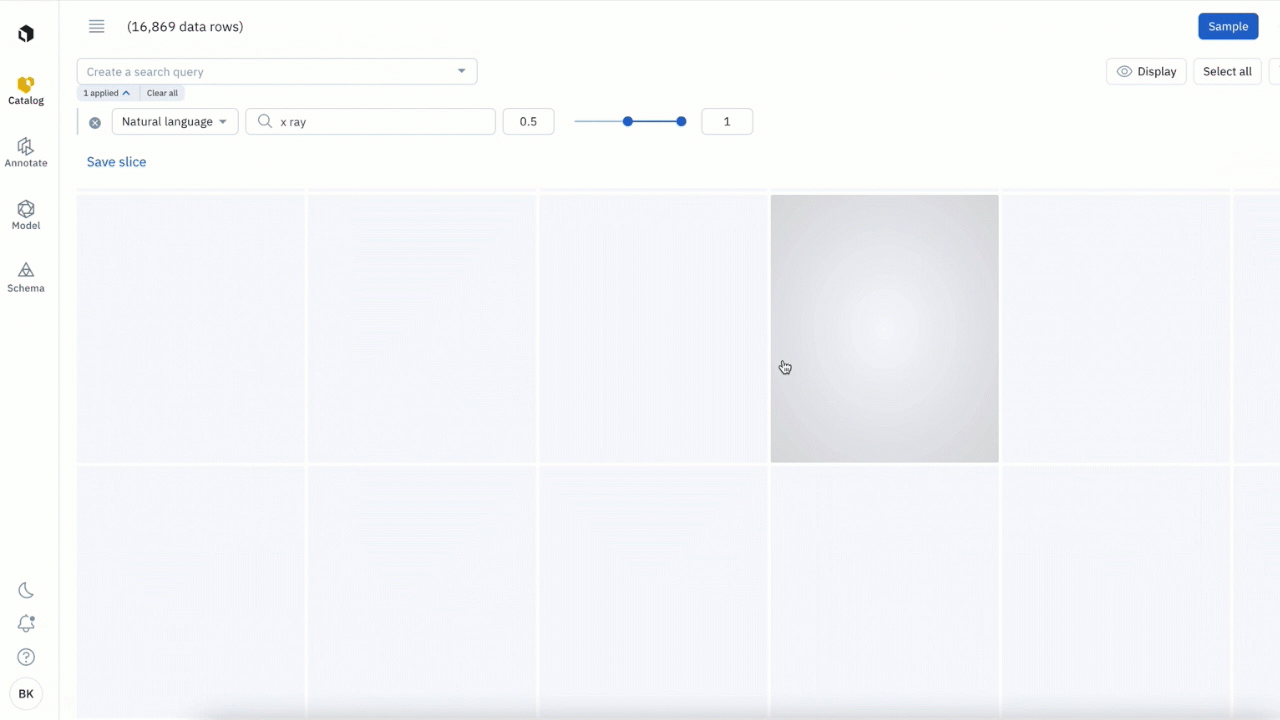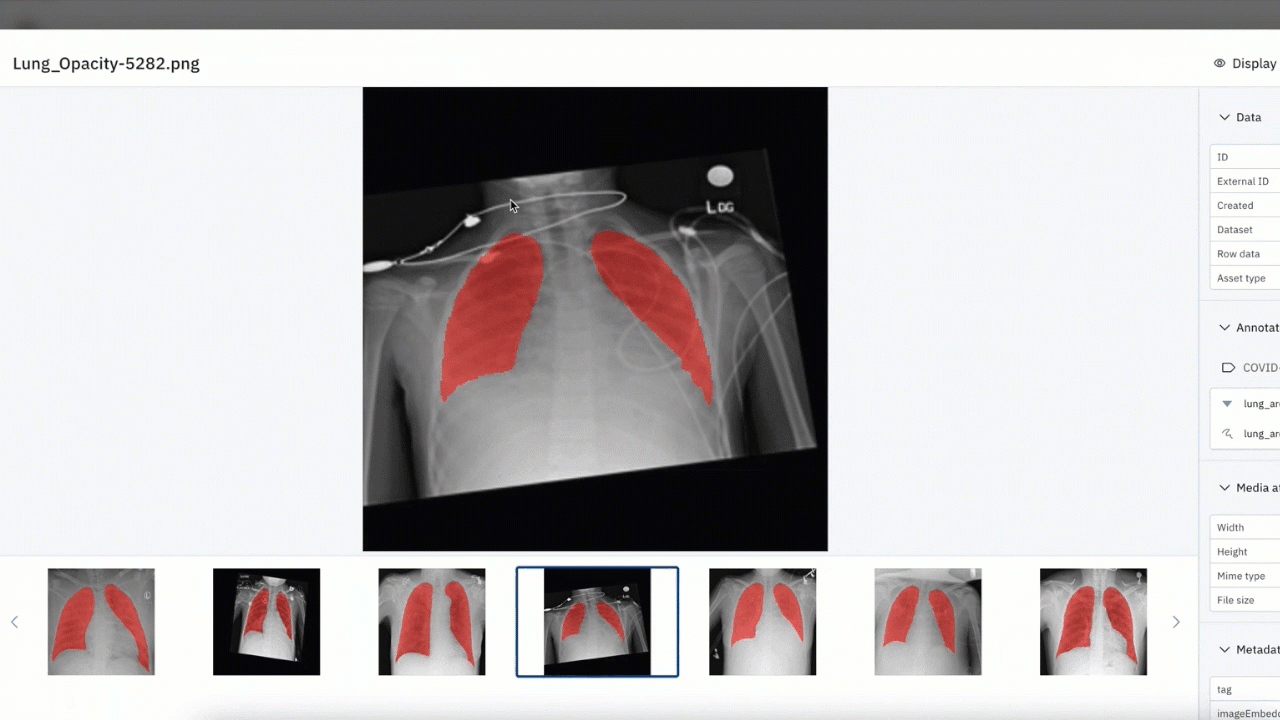
- Click on the “Natural Language” filter in the Catalog search bar and enter a word or phrase
- For example, searching “x-rays” will bring up all images of x-rays. You can further refine that search with natural language to only view x-rays that have a medical device present in the image by searching “medical device”
- This is available on images, tiled imagery, and on the first page of PDF documents
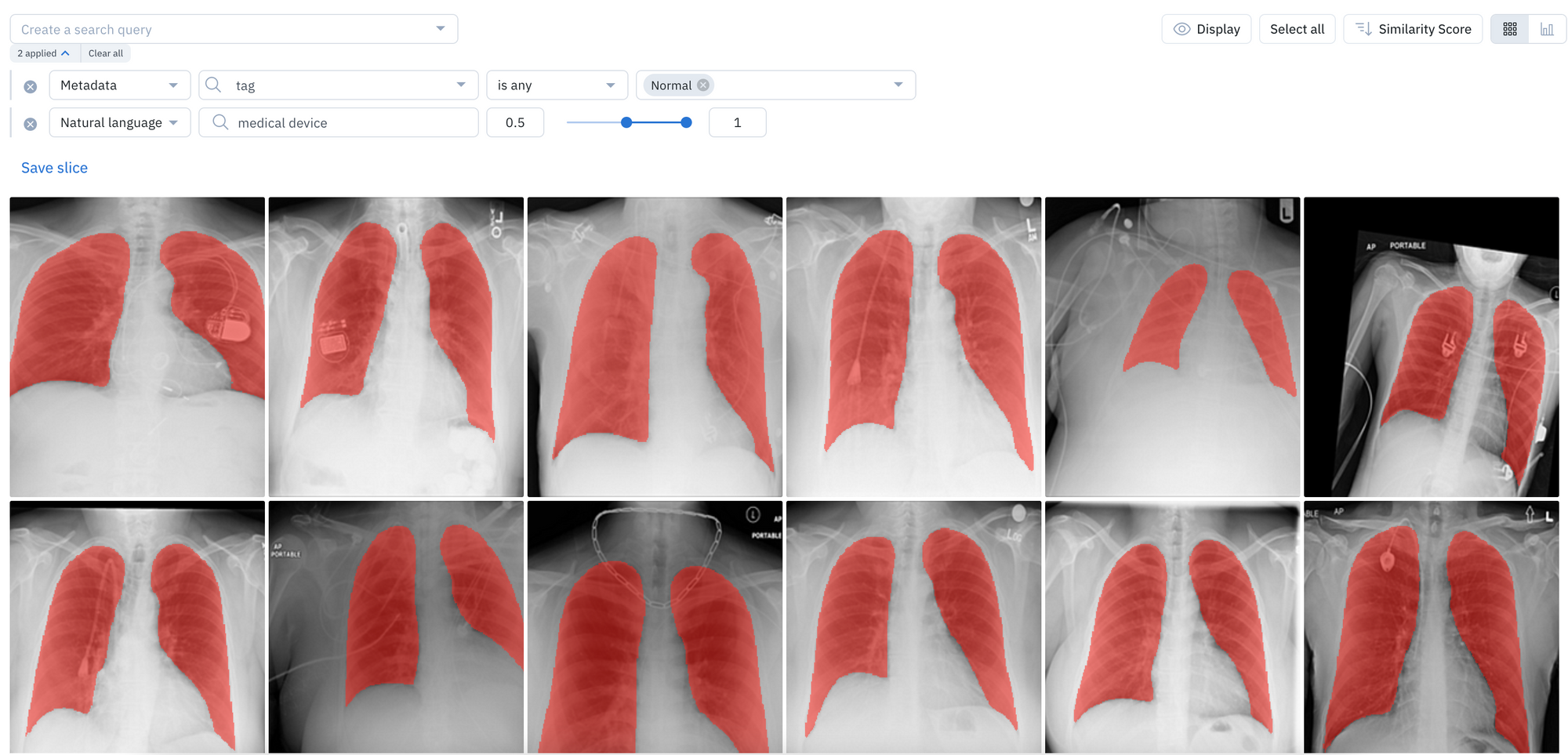
You can try natural language search on your own data in Catalog or on one of the available public datasets today.
Search for specific phrases or words in your text data
Making sense of your data across media types and datasets can be a challenging task. You can now use the “Find text” filter in Catalog to surface all instances of exact and partial matches to a word or phrase.
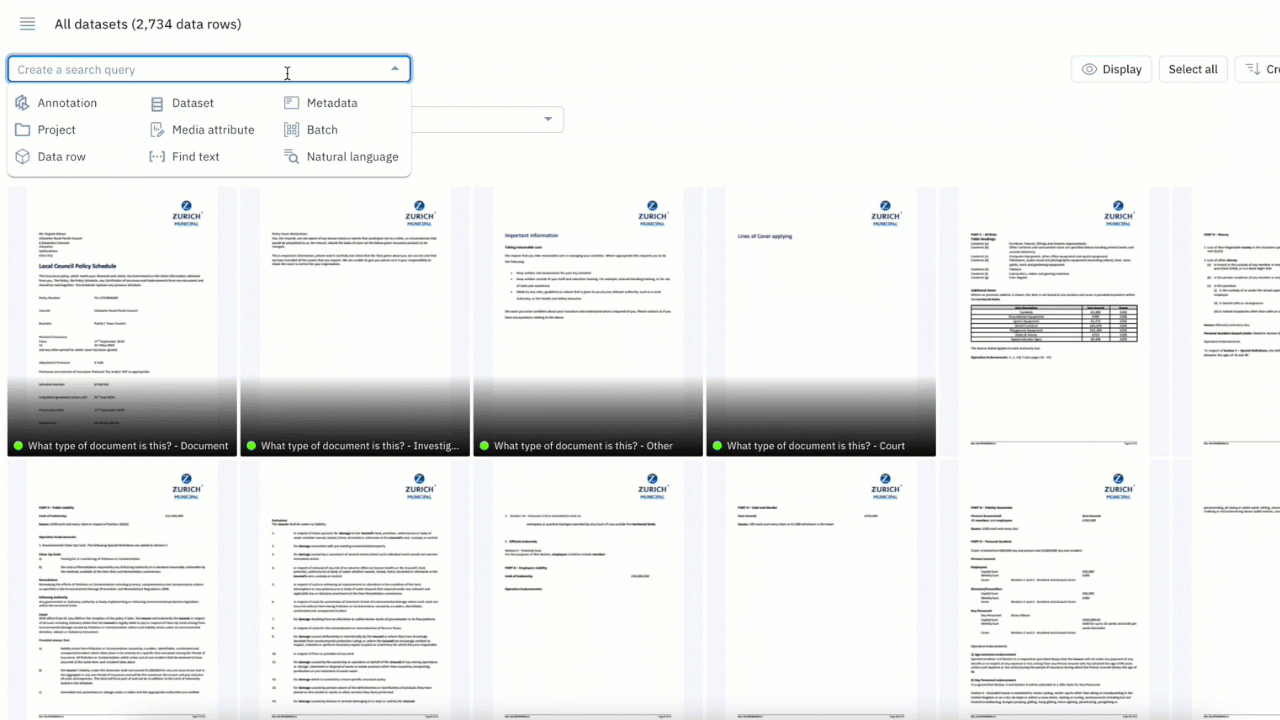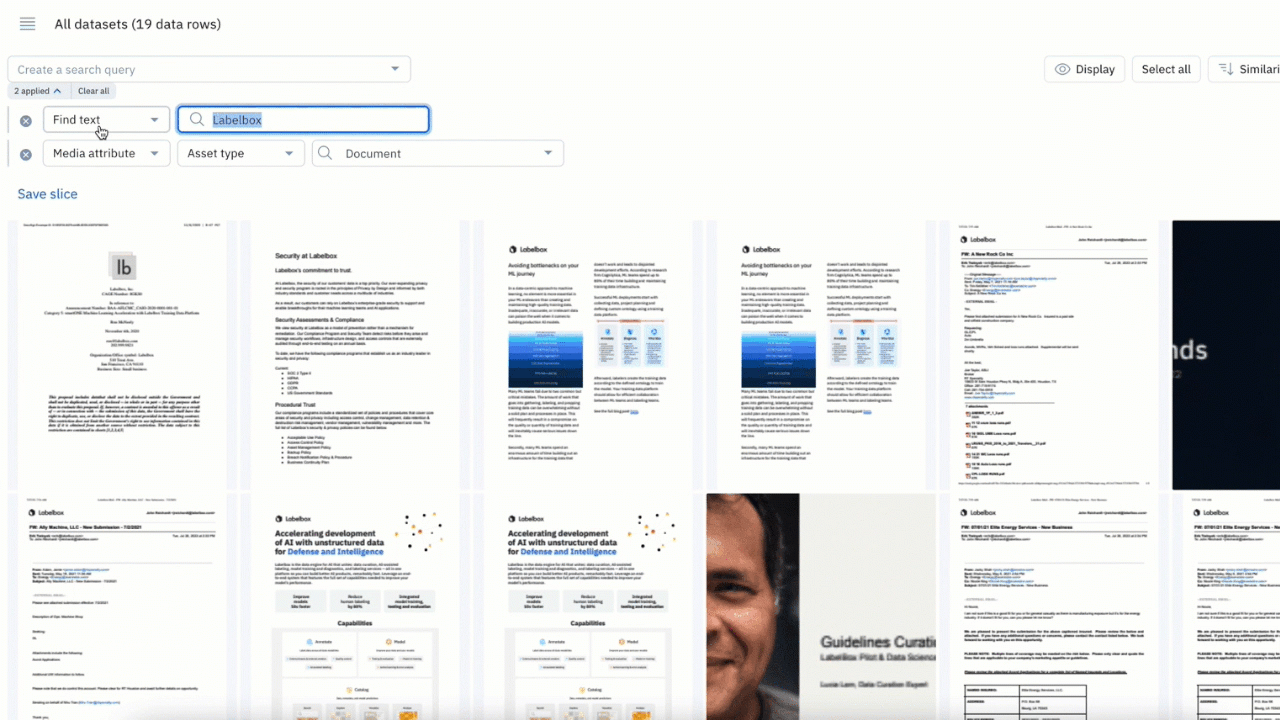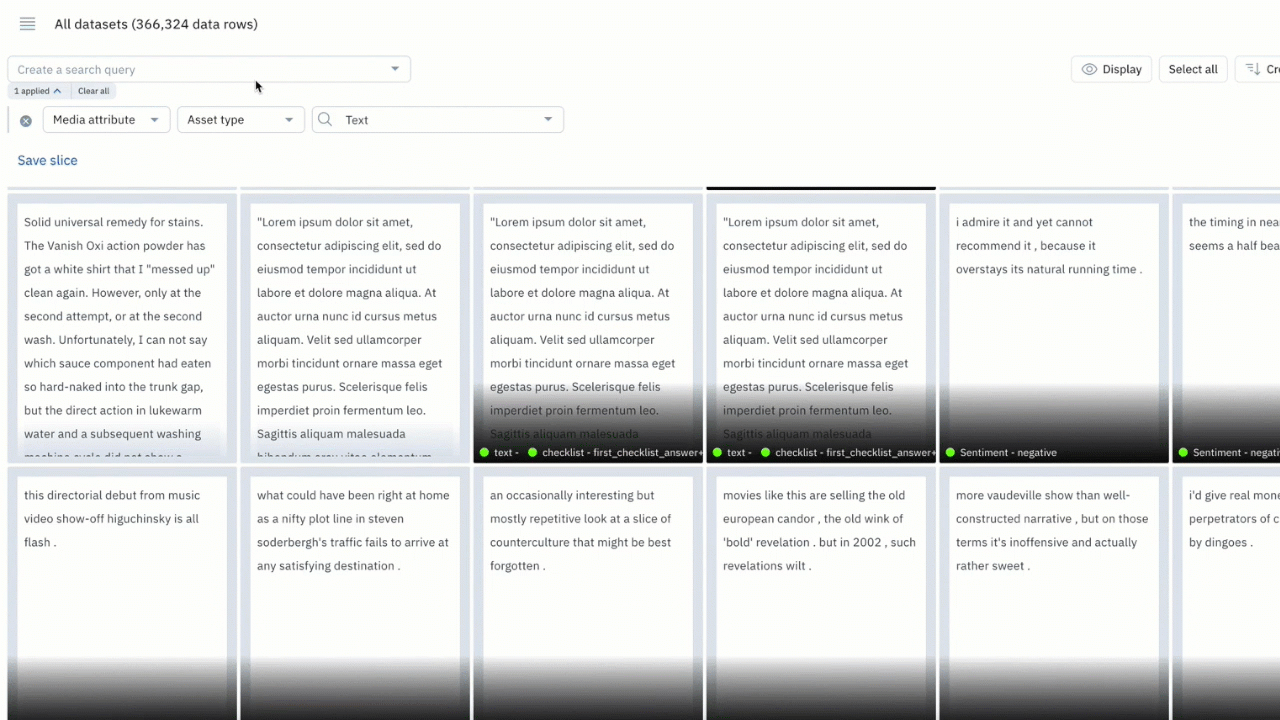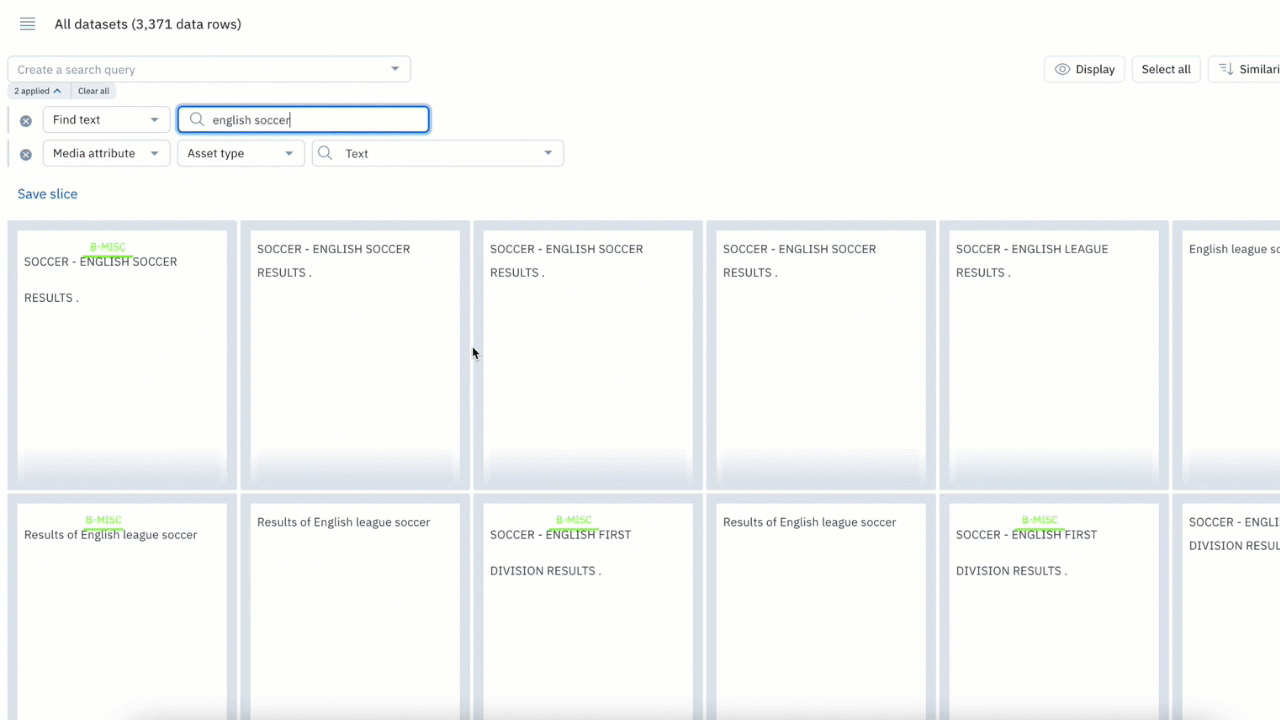
- Search for words across text files, HTML, and PDF documents to quickly find all data rows that match your search phrase
- You can use up to 100 characters or 10 words in your text search
- Combine the “Find text” search with other filters to narrow your search for your desired use case
You can try to find specific instances of text on your own data in Catalog or on one of the available public datasets today.


