
 All blog posts
All blog postsLabelbox•March 2, 2023
Use Labelbox to explore public datasets

A big challenge for AI teams is being able to select the right data to train models for ML applications. Public datasets can be a great starting point for teams of varying ML maturity levels – whether you’re looking for a broad dataset that will fit your general use case or for specific assets that will boost your model’s performance.
However, like many of you, we’ve encountered the challenges of dealing with public datasets — it can be incredibly hard to browse the data and even harder to find specific examples of data within the larger dataset.
You can now browse over 30+ large scale public datasets directly through Labelbox. Leveraging Catalog as its foundation, you can freely browse, visualize, organize and analyze petabytes of publicly-available datasets across diverse use cases and modalities. With the advancement of generative AI models that thrive on open internet data, you can discover and extract value from innovative public datasets to enrich your own pipeline.
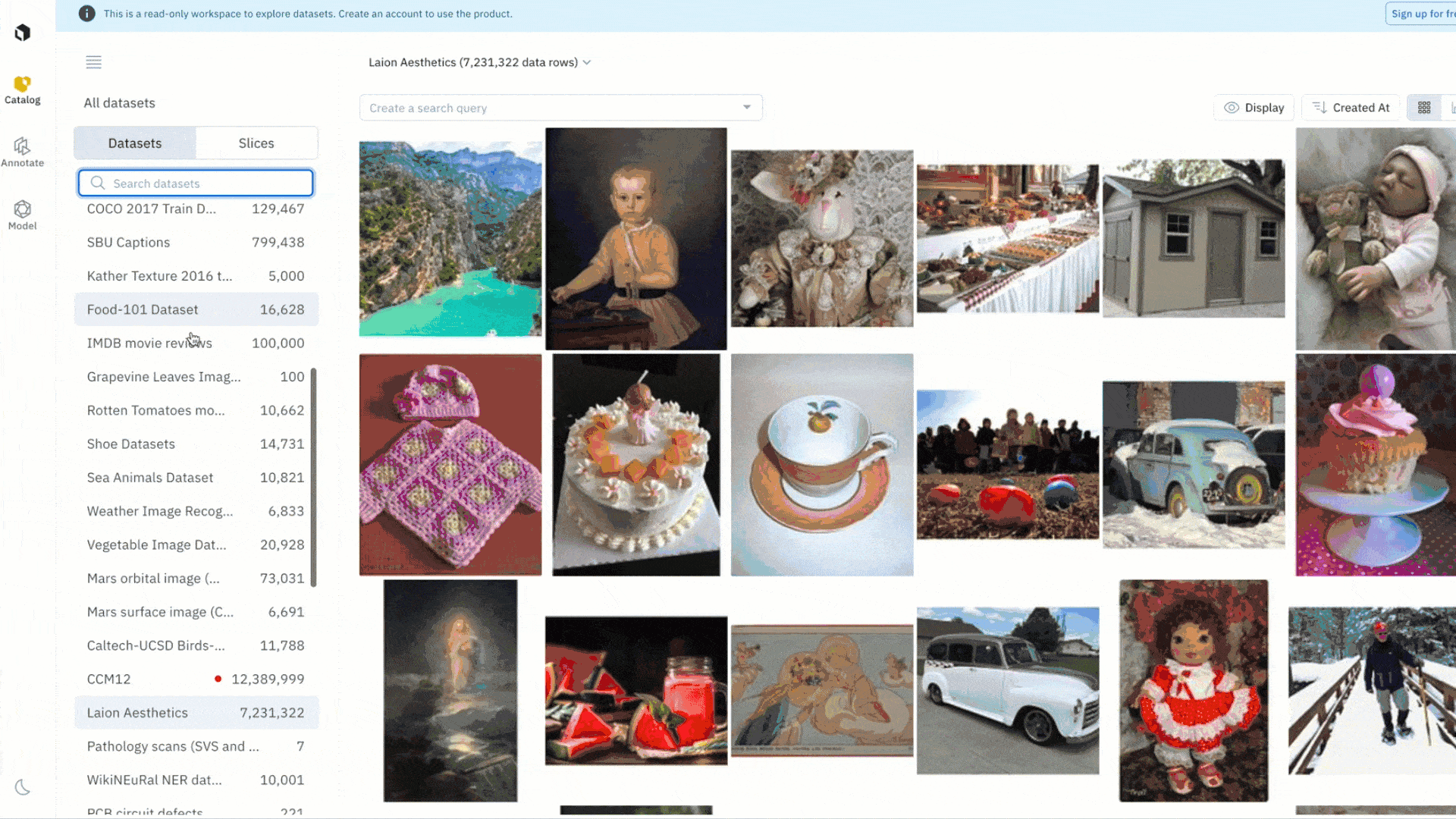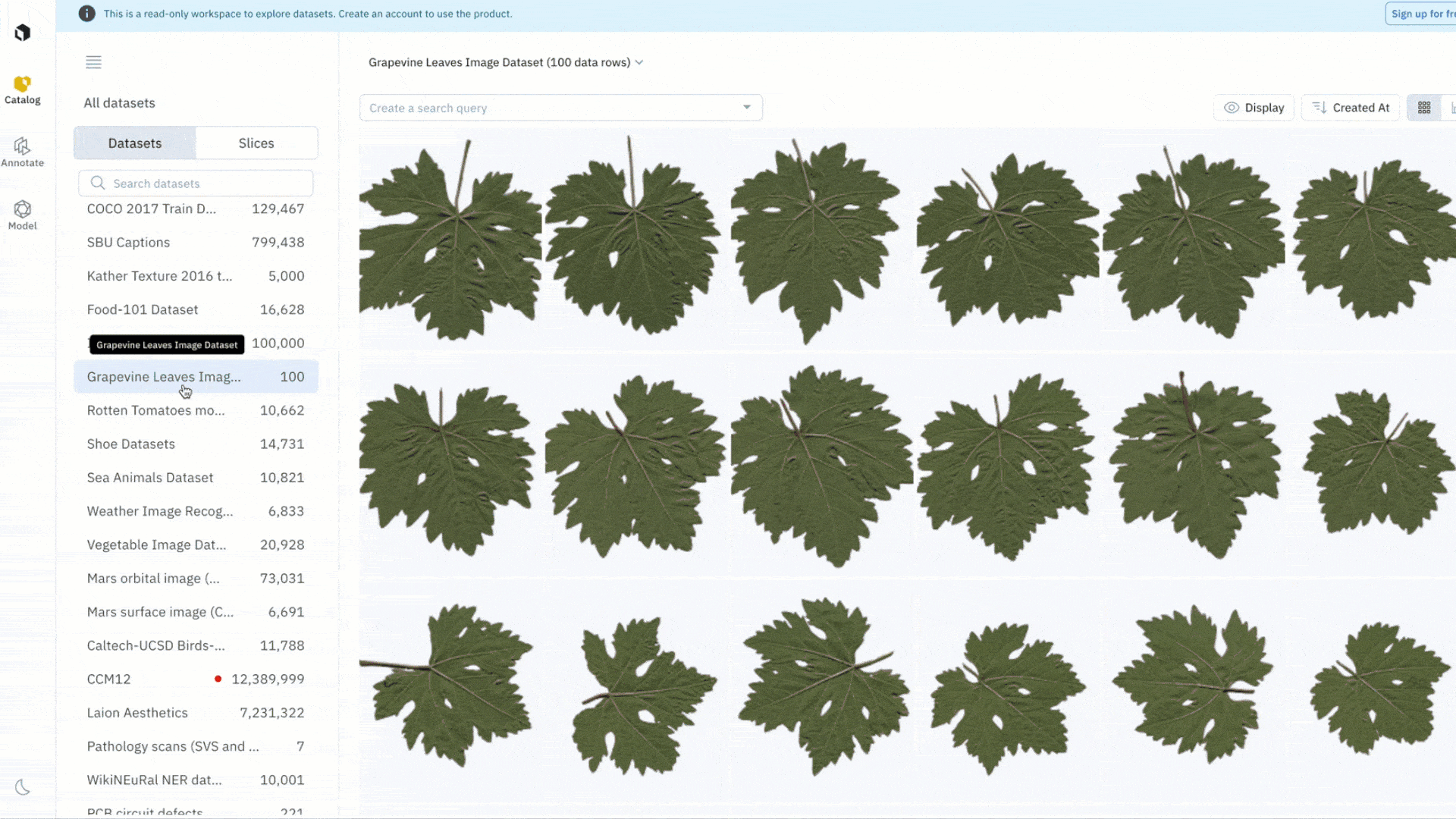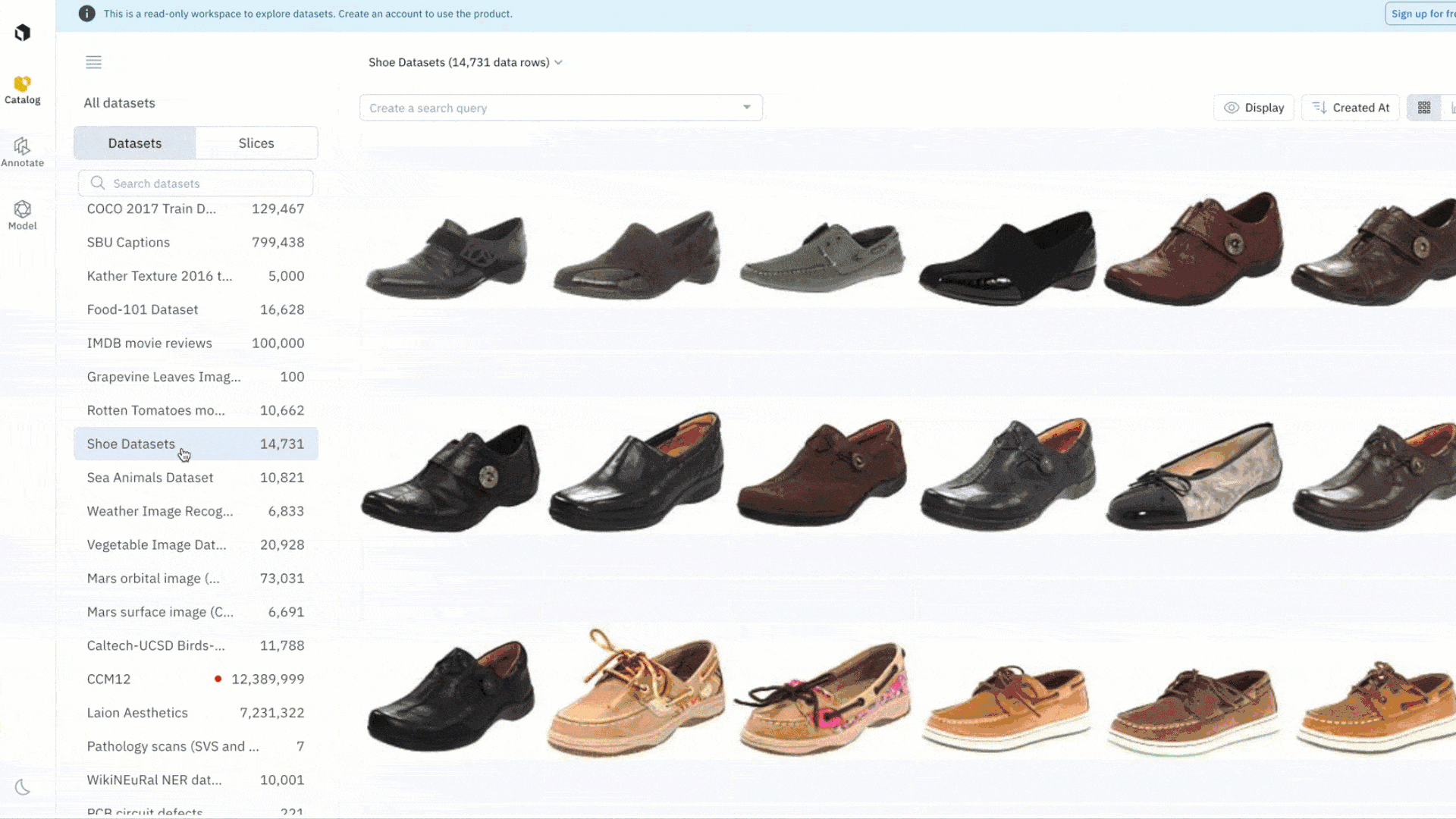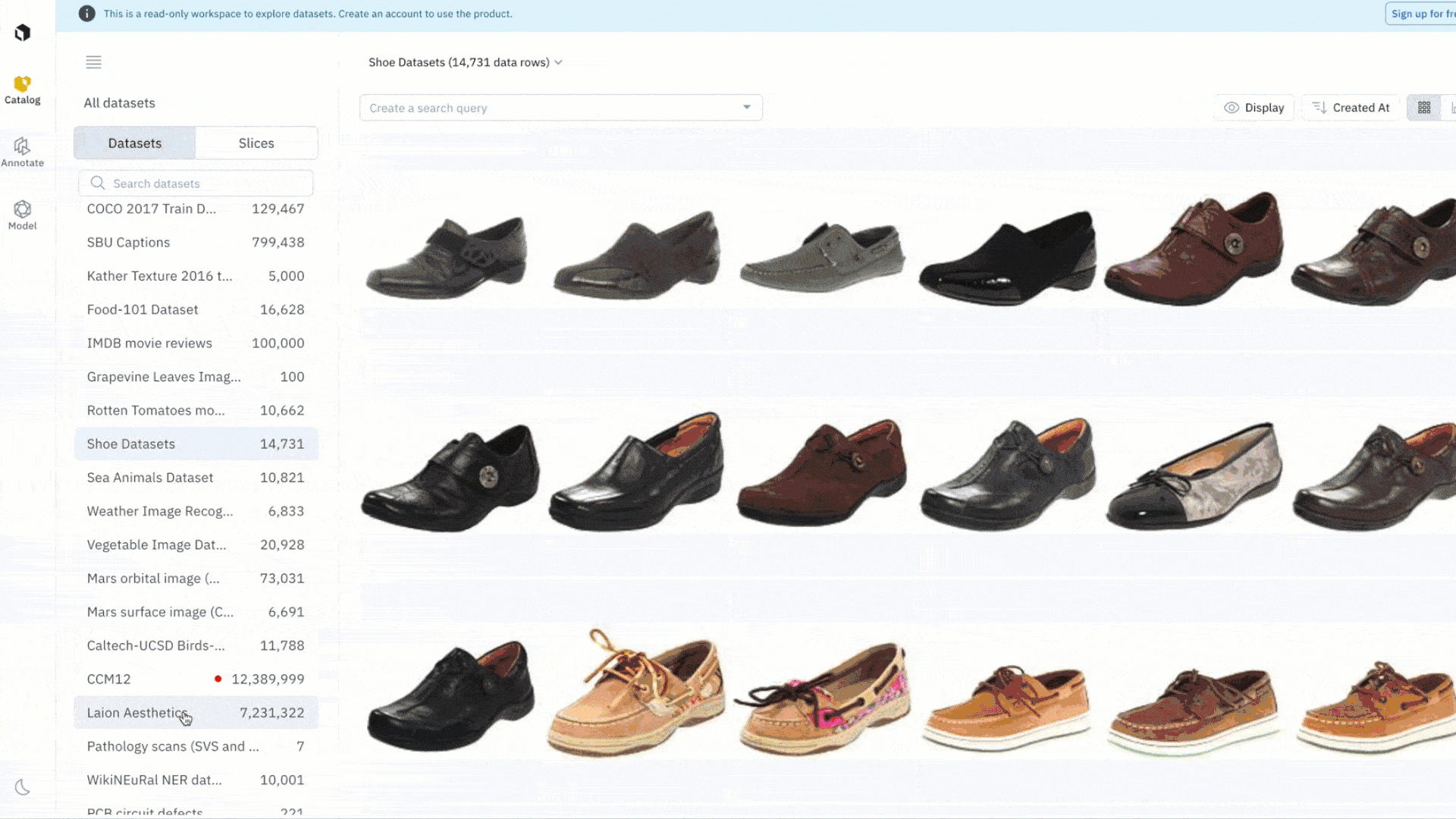
Explore a public dataset: LAION Aesthetics
Known as a large scale ‘dataset of datasets,’ viewing the LAION dataset would normally require technical proficiency, including using the command line and downloading subsections of the 10TB image and text caption dataset manually and over time. Historically, there has been no way to see samples of this dataset prior to downloading it and no way to visually inspect if it would actually benefit your use case.
With the ability to view public datasets in Labelbox Catalog, you can explore subsections of the LAION dataset by visualizing all data rows and filtering the dataset to narrow in on a subset of data that might be of interest.
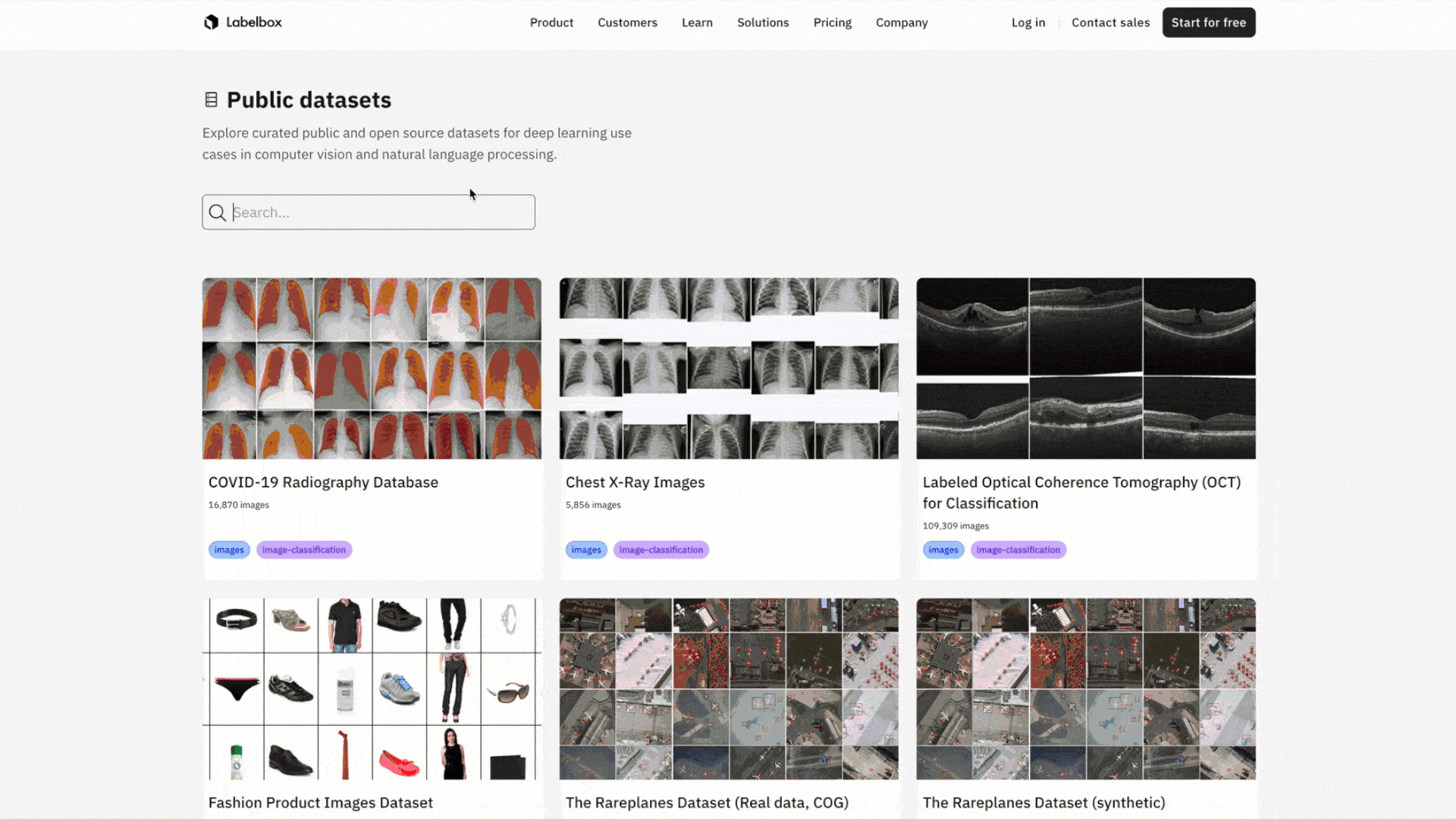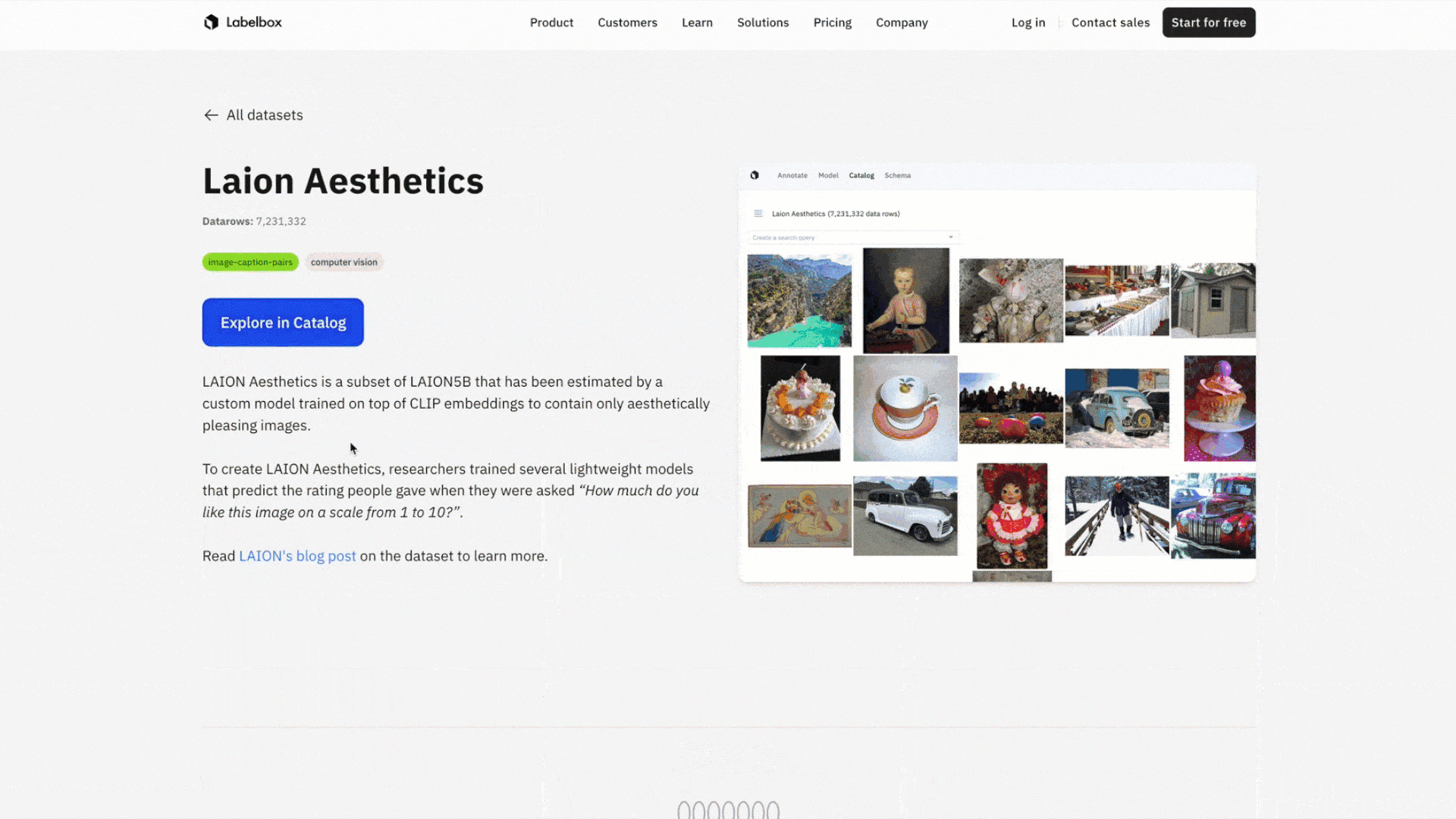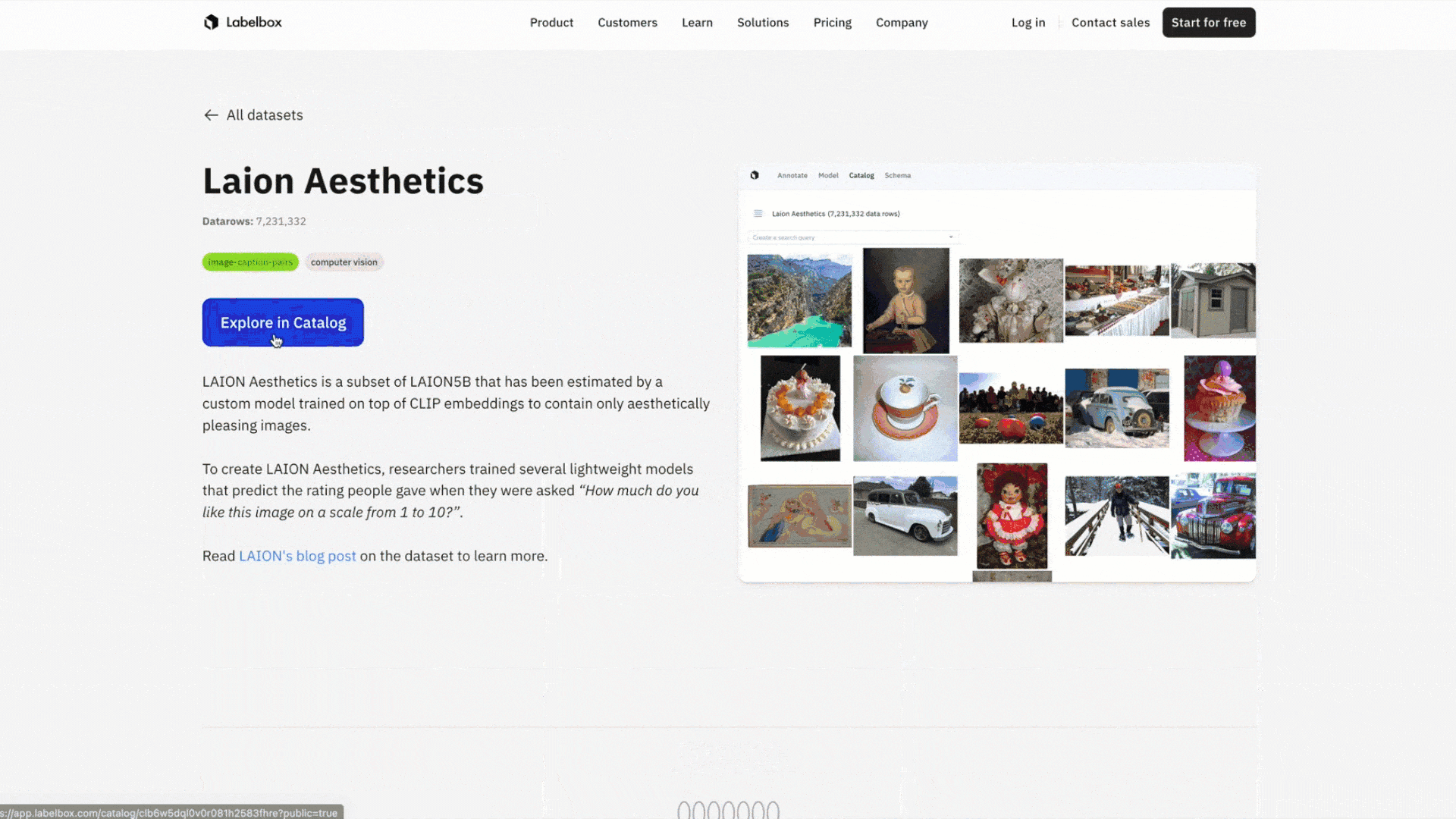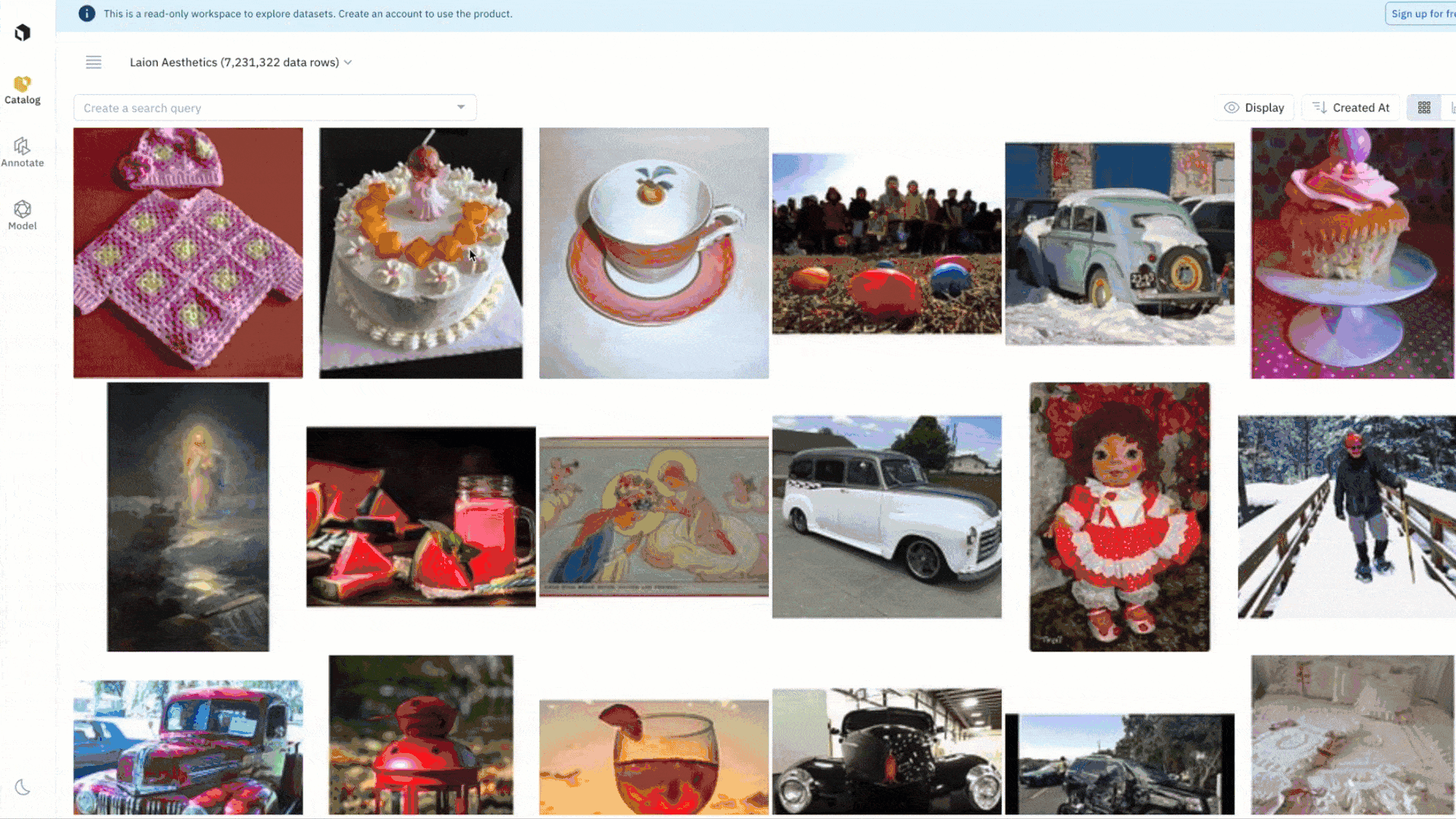
Visualize and browse assets across datasets
Easily discover and stay up to date on datasets across a variety of modalities and that demonstrate AI/ML innovation without having to download large datasets.
You can easily browse a subsection of 7M assets from the LAION dataset – a voluminous 10 TB collection of datasets — without having to find an accessible home for it on your computer or within your own repo. Sort, organize and curate data across a wide variety of public datasets spanning text, image, geospatial data, and more.
Easily investigate and assess datasets
Data curation and selection is a critical part of any ML workflow. You can curate interesting subsets of data to appropriately assess whether or not the public dataset might be of interest for your use case. This can be used to look for bias, surface duplicate data, or assess the general quality of the dataset in relation to your use case.
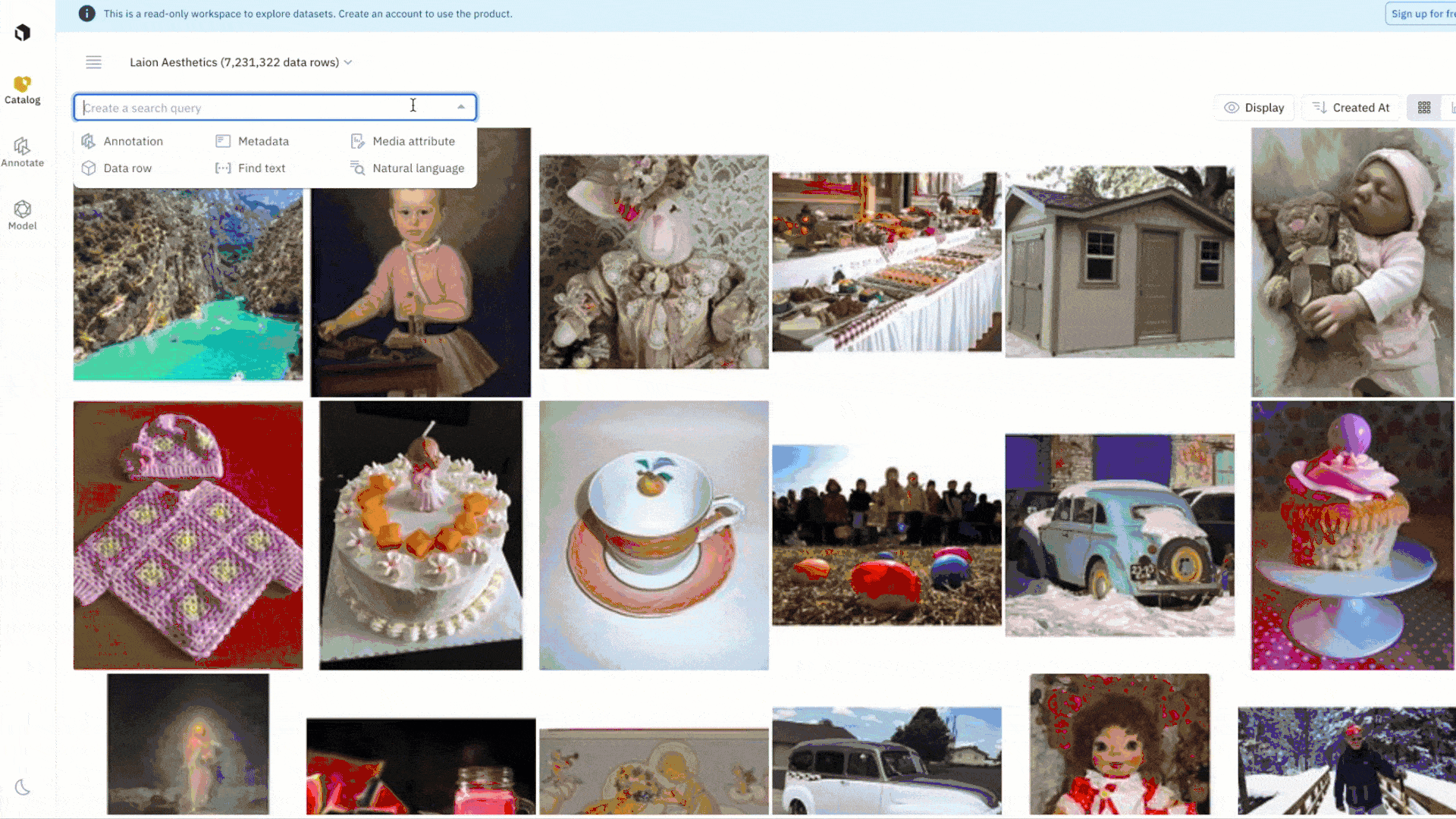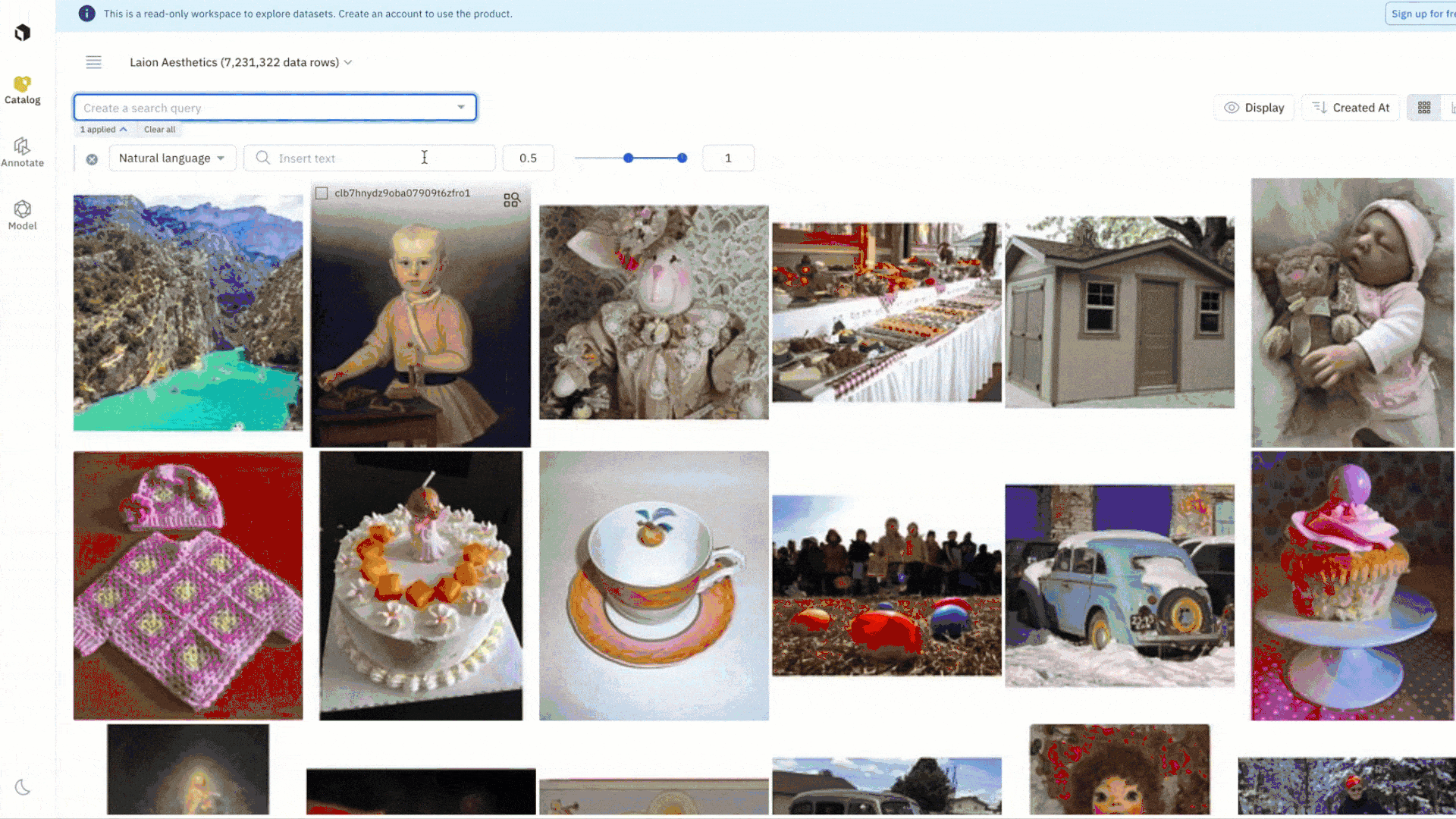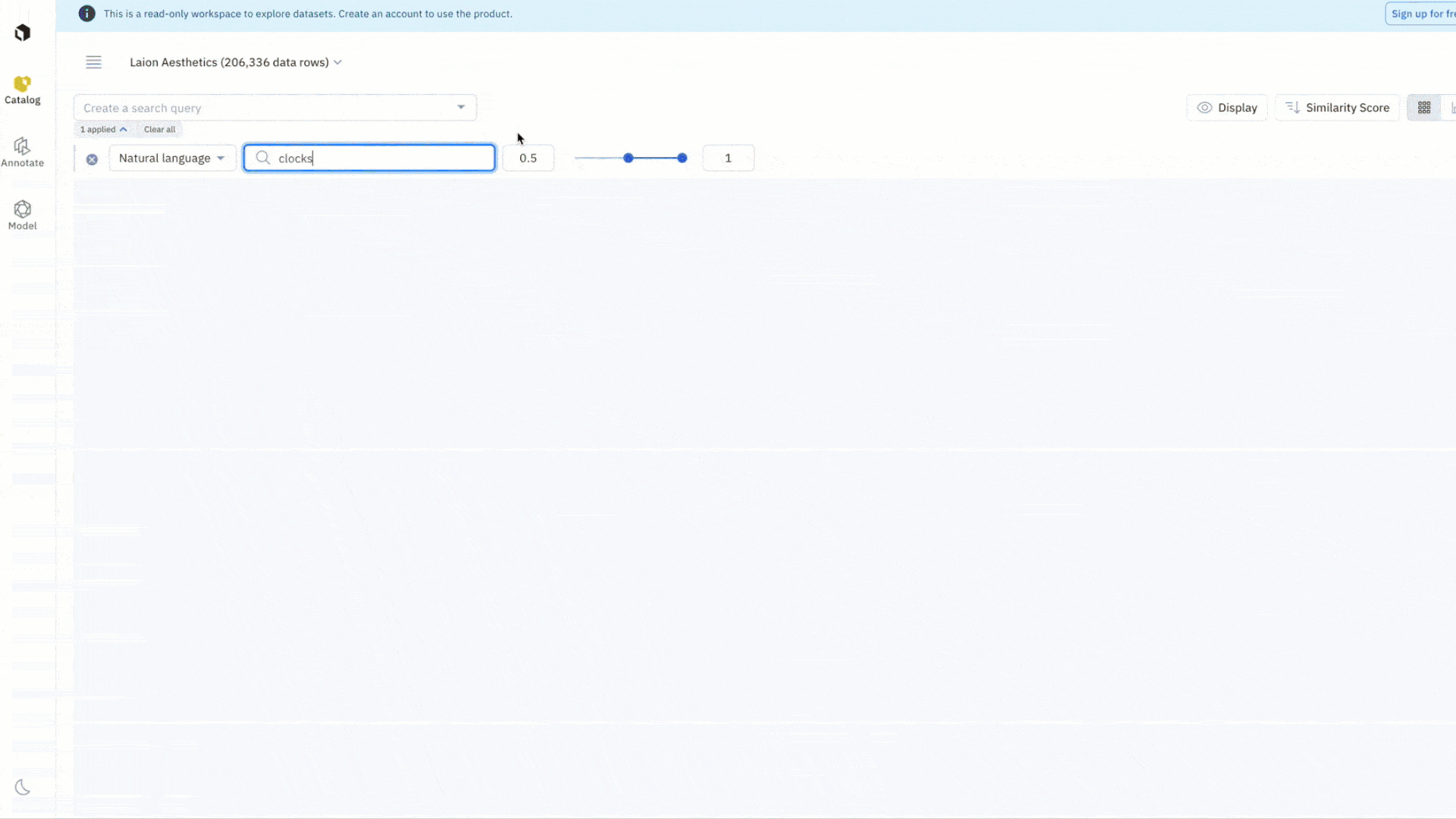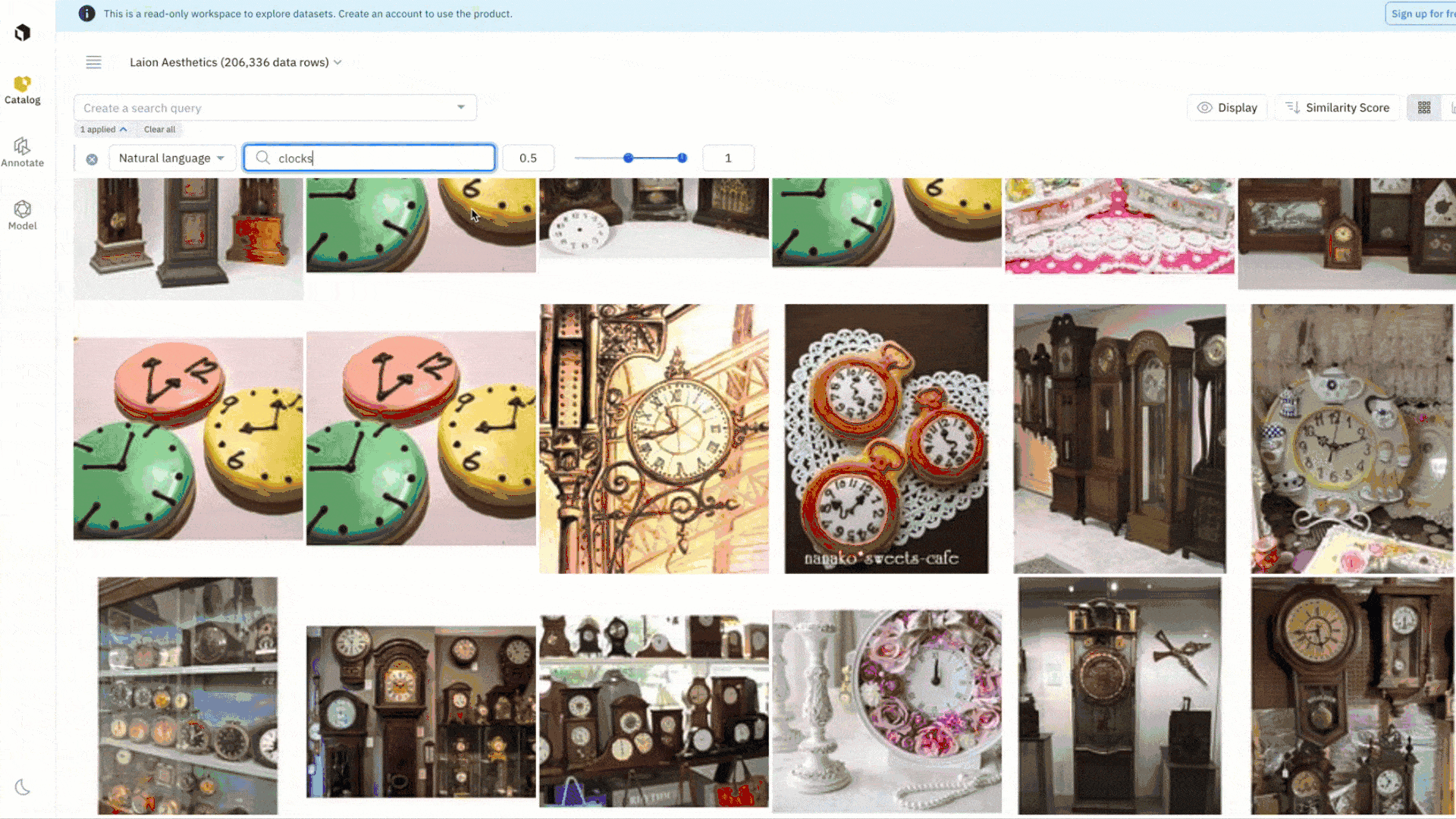
Leverage the provided filters in Catalog to quickly explore and narrow in on a subset of data. For example, you can conduct a natural language search on “clocks” to surface all instances of LAION Aesthetic images that match the word “clocks”. You can also combine filters, like metadata, media attribute, and similarity search, to create more granular searches that capture the complexity of your use case. Once you’ve found a data row of interest, you can automatically surface all instances of similar data in one click with a similarity search that leverages embeddings.
Try it yourself:
- View and browse the LAION Aesthetic dataset in Catalog
2. Create a search query by clicking on the provided filters:
- Click on “Natural language search” and type the word “clocks”
- Browse data rows until you find an image of wall clocks or another image of interest
3. Find all instances of similar data
- Hover on the data row and click on the top right icon to “Find similar data”
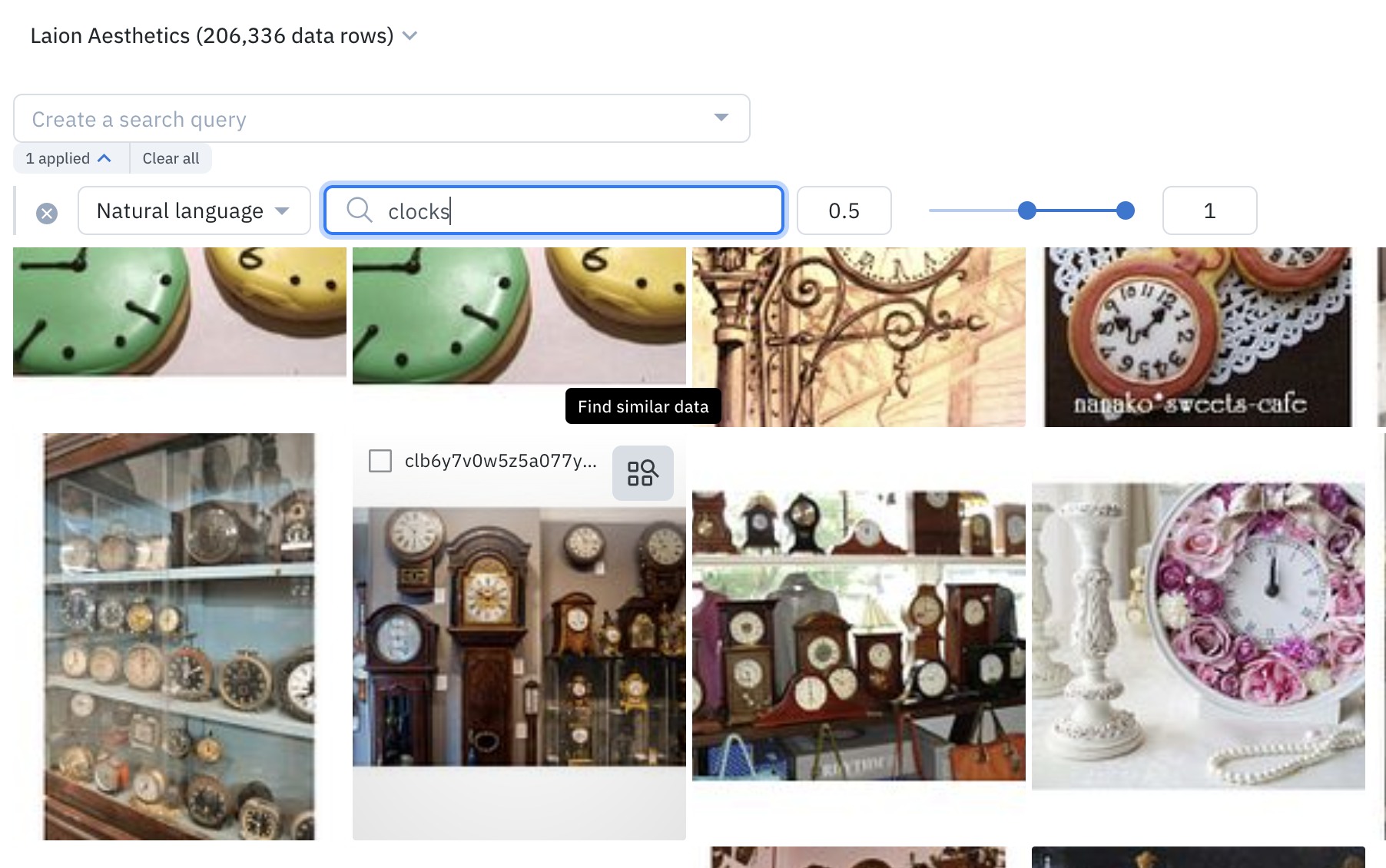
4. Combine filters to create a more complex search
- You can add filters to your search criteria to include specific metadata, media attribute, and more
5. Explore other interesting slices of data available across public datasets by clicking on “Slices” on the left-side panel
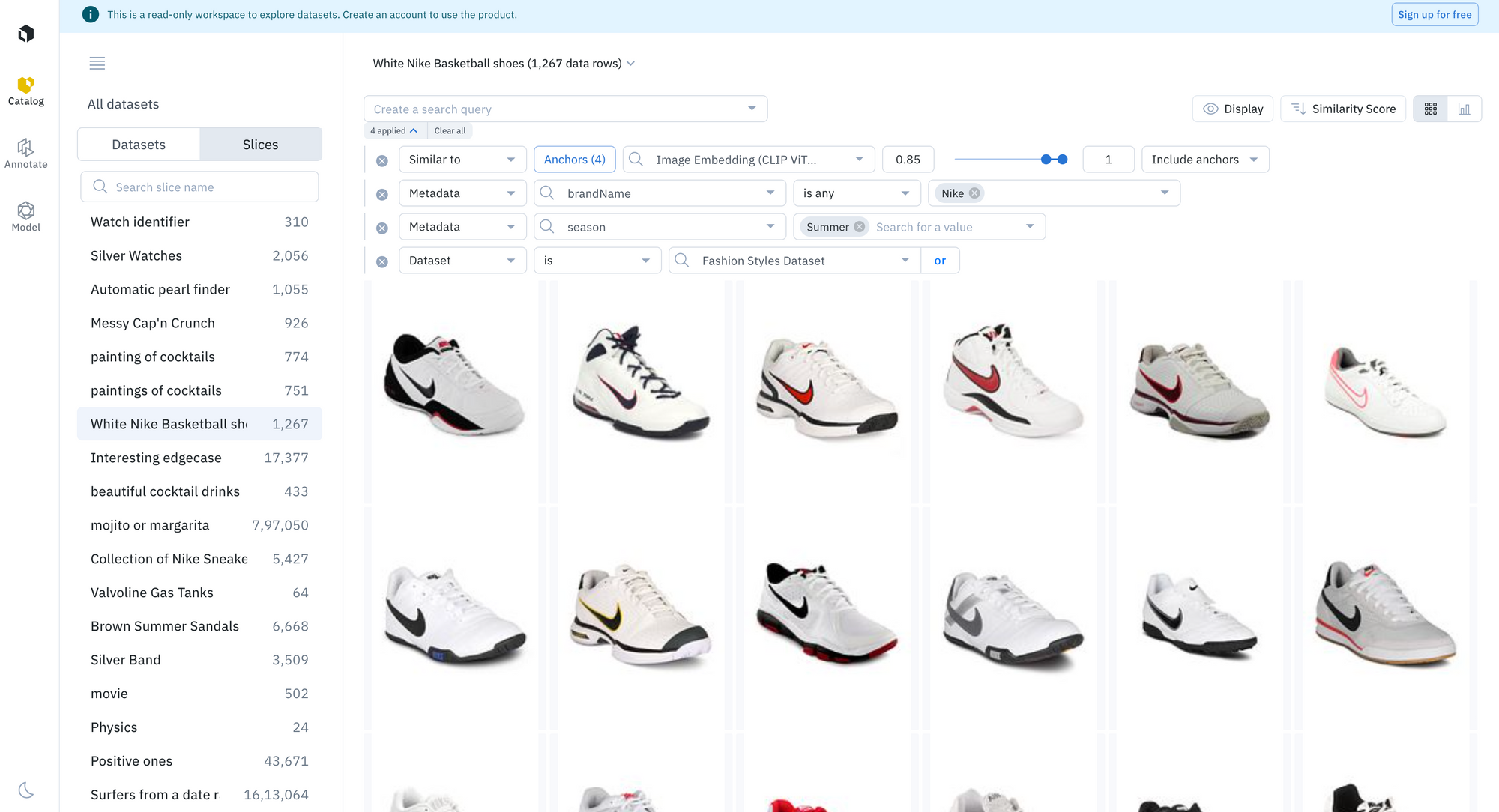
What’s next?
Whether you’re interested in browsing public datasets to kickstart your team’s AI initiatives or are looking for specific assets to incorporate into your model training pipeline, you can start by browsing over 30+ public datasets on our webpage today.
As we continue to work on making public datasets more beneficial for the AI community, we always welcome your feedback and are open to hearing which public datasets you would find the most valuable.
If you’re interested in visualizing, exploring, and organizing your own data, we encourage you to create a free Labelbox account to upload and view your own data.


