
 All blog posts
All blog postsLabelbox•May 5, 2022
Catalog: The launchpad for unstructured data management
Unstructured data management is a major pain point and the main source of bottlenecks for teams trying to build advanced AI systems. This led the Labelbox team to build Catalog, an unstructured data management solution built into our training data platform that acts as a unifying layer across all your machine learning (ML) data and tackles three core challenges:
- Managing and searching massive unstructured datasets
- Visualizing and exploring data
- Curating efficient batches of high-value data
You can do all of this in Catalog without writing code or creating new ETL pipelines. By effortlessly centralizing and streamlining all your essential data workflows, Catalog allows you to increase your iteration velocity. Here’s a bit more on how Catalog helps you tackle each of the core challenges listed above:
Catalog is the central hub for structured and unstructured data management
While there are a number of world-class platforms for organizing and managing structured data, unstructured data requires a purpose-built tool that can combine different types of data and metadata from multiple sources into a simple, powerful UI. With Catalog, you now have a single, centralized location for managing all of your data, structured and unstructured.
Once you connect Labelbox to your AWS, GCP, or Azure accounts you can securely add all of your data to datasets in Labelbox. This allows you to view data from across multiple datasets and search for data using attributes like metadata, project, and annotation. Labelbox lets you manage and create custom metadata fields in the Schema page and you can now filter for data using metadata fields so that you can visualize your unstructured data in a single place. We’ve improved the filter syntax by introducing more powerful AND and OR filter logic operators, allowing you to gather more specific slices of data.
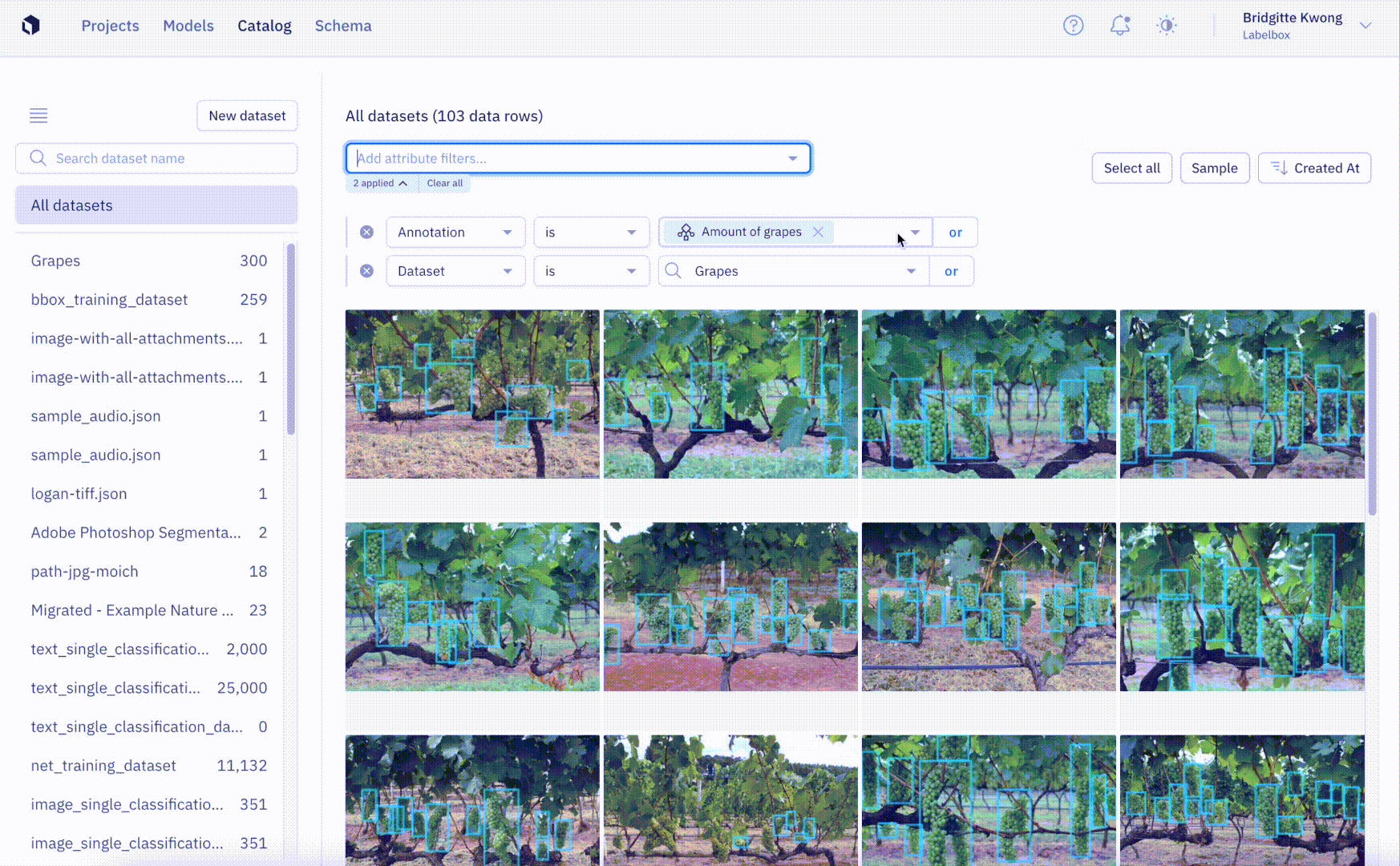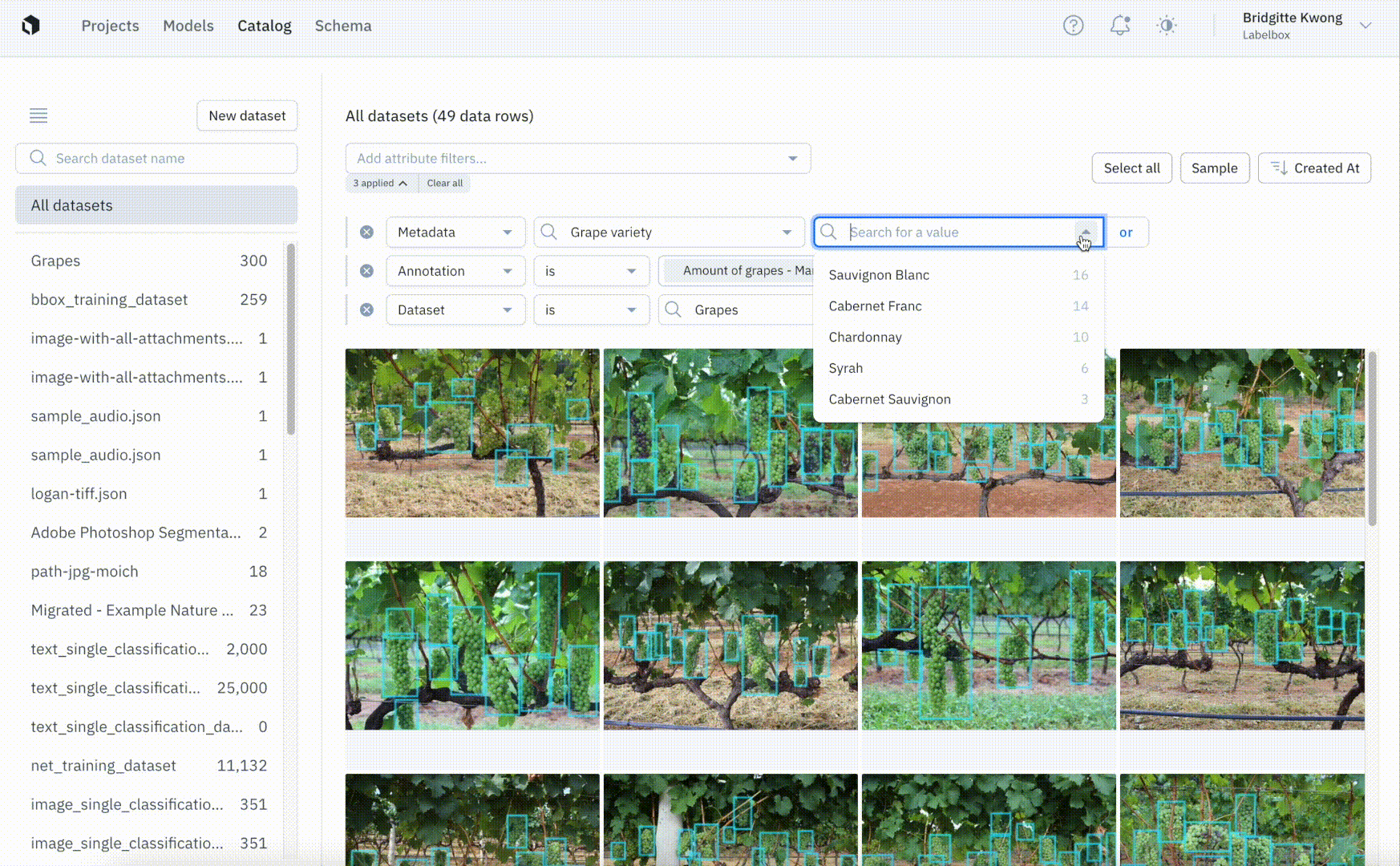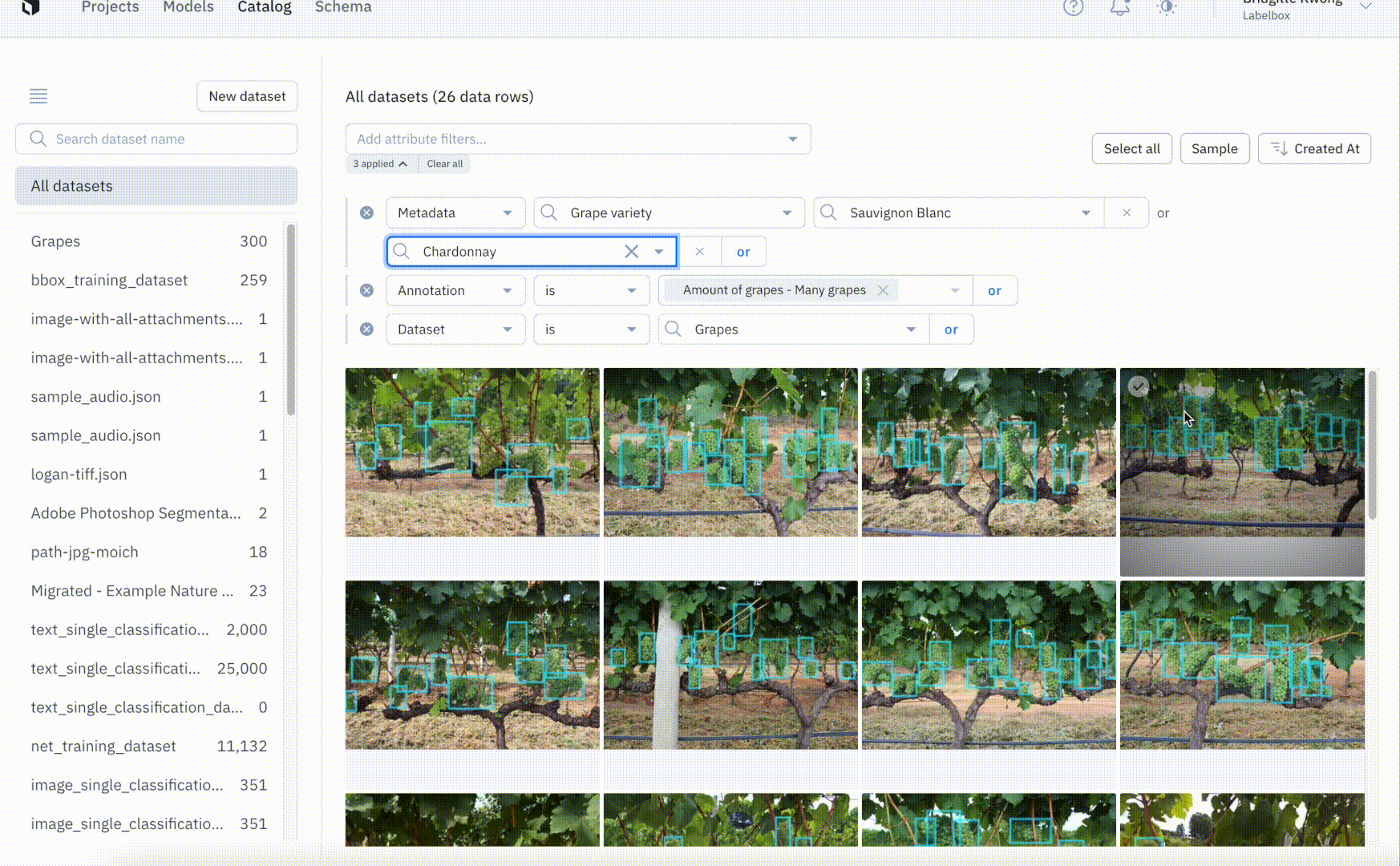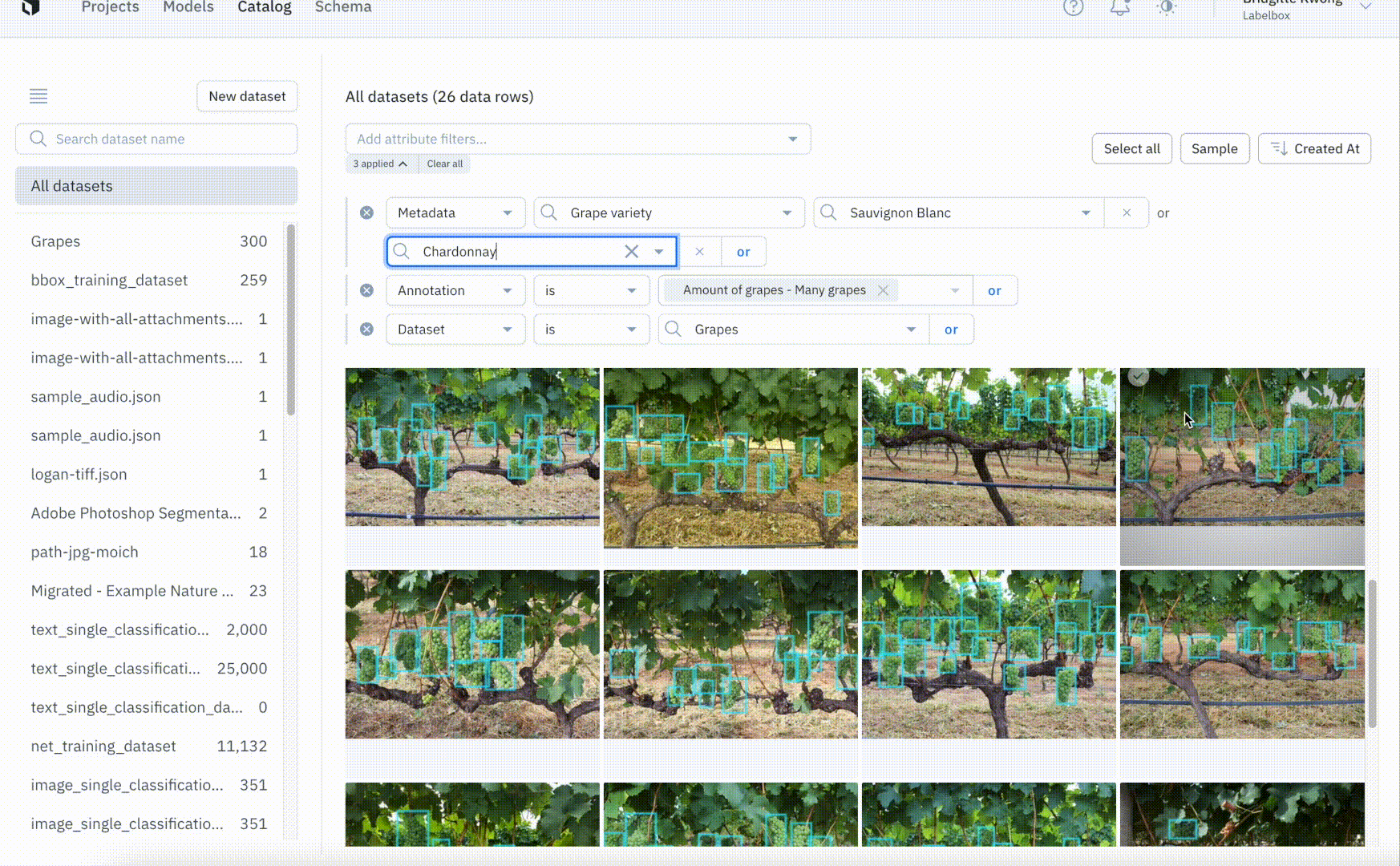
Visually explore unstructured and labeled data with ease
Understanding your data is critical for identifying possible edge cases that need to be addressed or for uncovering common patterns in data. Catalog makes exploring your data to uncover new insights and patterns simple and intuitive. By filtering through data based on annotation, project, or other attributes including metadata, you can more quickly identify trends that can guide the direction of your labeling projects. While model performance metrics can tell you which classes yield more errors, zooming in to better understand the data can help uncover the root of the problem. A few common problems include:
Poor data quality - Oftentimes a more thorough visual inspection of your data can help uncover low-quality data that could be introducing errors into your model. This could be as simple as using metadata filters to identify an out of focus camera or examples of objects that don’t accurately represent the class.
Redundant data - Highly similar pieces of data don’t actually provide new information to the model and can actually introduce bias. By easily visualizing your datasets, you can better evaluate whether you have too many low-value pieces of data. Save time and associated cost by excluding data that won’t lift model performance.
Difficult data - Some cases are more challenging for models because of environmental factors (e.g. night time, or distortions caused by occlusion). Labeling more data and improving label quality may help the model learn the patterns required to perform in these situations better. By visually exploring the data, you can uncover these difficult cases that would otherwise be hard to surface if only relying on performance metrics.
Finally, we’re excited to introduce annotation overlays in Catalog. You can now see annotations on images in Catalog gallery view and detail view. Seeing annotations on data can help quickly uncover trends in labeling accuracy and spot outliers in your dataset. We’re looking to support annotation overlays for all data modalities in the near future.
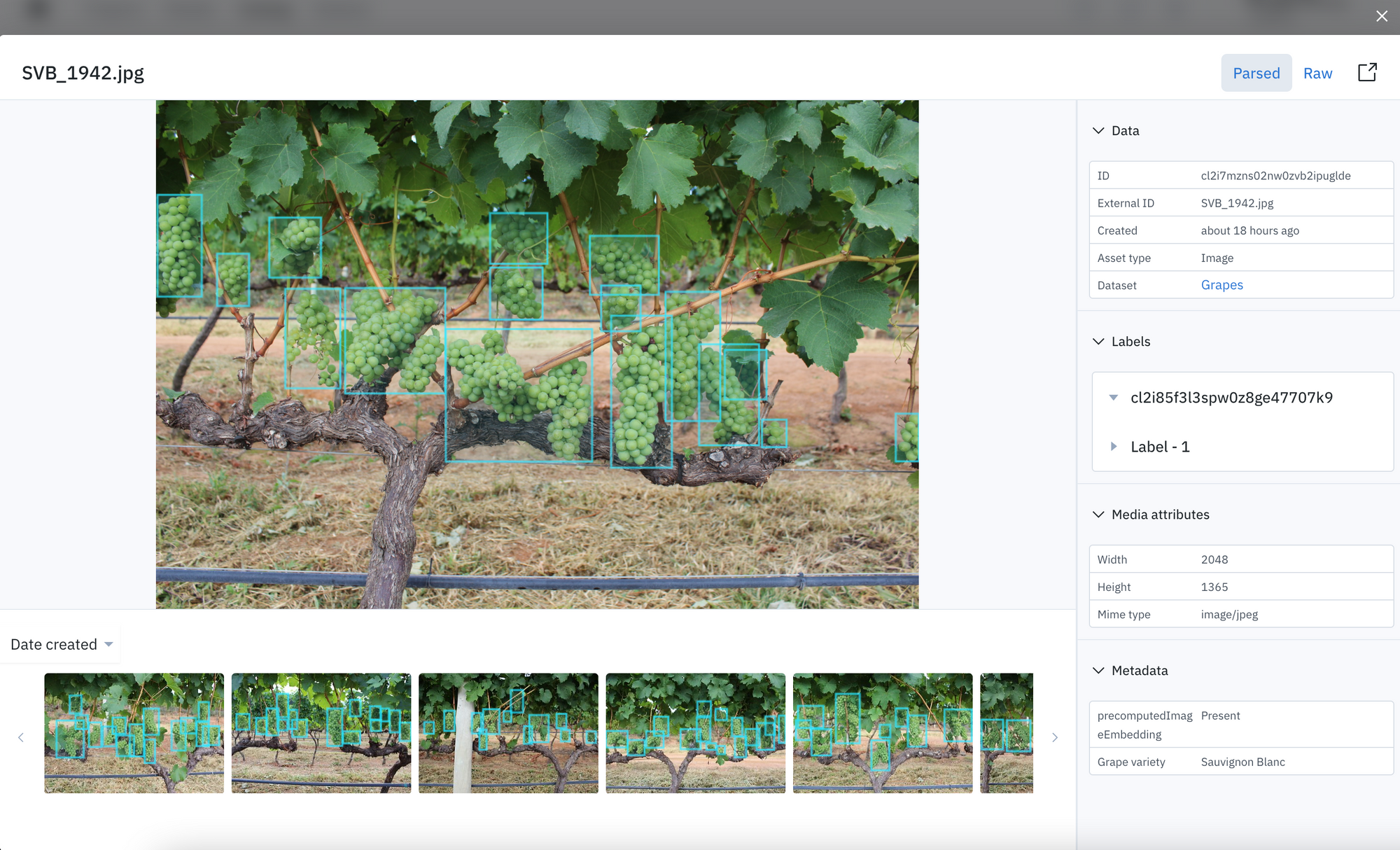
Curate high-value data for labeling projects
When it comes to training a model with labeled data, not all data will impact model performance equally. Data-centric AI development asserts that high-quality models rely on high-quality labeled data, and that ML teams should focus more of their efforts on data than on code. With this approach in mind, teams need to leverage active learning workflows and other ways to systematically identify which data will most dramatically improve their model’s performance and prioritize it over data that doesn’t.
To that end, we’ve developed three workflows that help teams curate high-value data. Keep reading or watch this short video walkthrough to learn how to put them to use.
Find data with Similarity Search and labeling functions
In a recent post we explored how model embeddings can be used to help find visually similar data for labeling projects. While that post offers a much deeper walkthrough, in short, Catalog can help you discover data that is visually similar to low performing classes so you can focus labeling efforts on data your model doesn’t know how to confidently identify.
Select batches of data to send directly to labeling projects
Labeling projects used to rely on attaching datasets that contained the right assets to label. This required teams to manage data searches and curation on their own using oftentimes cumbersome tools and workflows. With the batch workflow, teams can now use Catalog to search through all of their data and select the exact subset of data they want to send to a project for labeling. Recent improvements to the batch workflow introduced the ability to name, manage, and prioritize batches so teams have more visibility and control over their labeling projects.
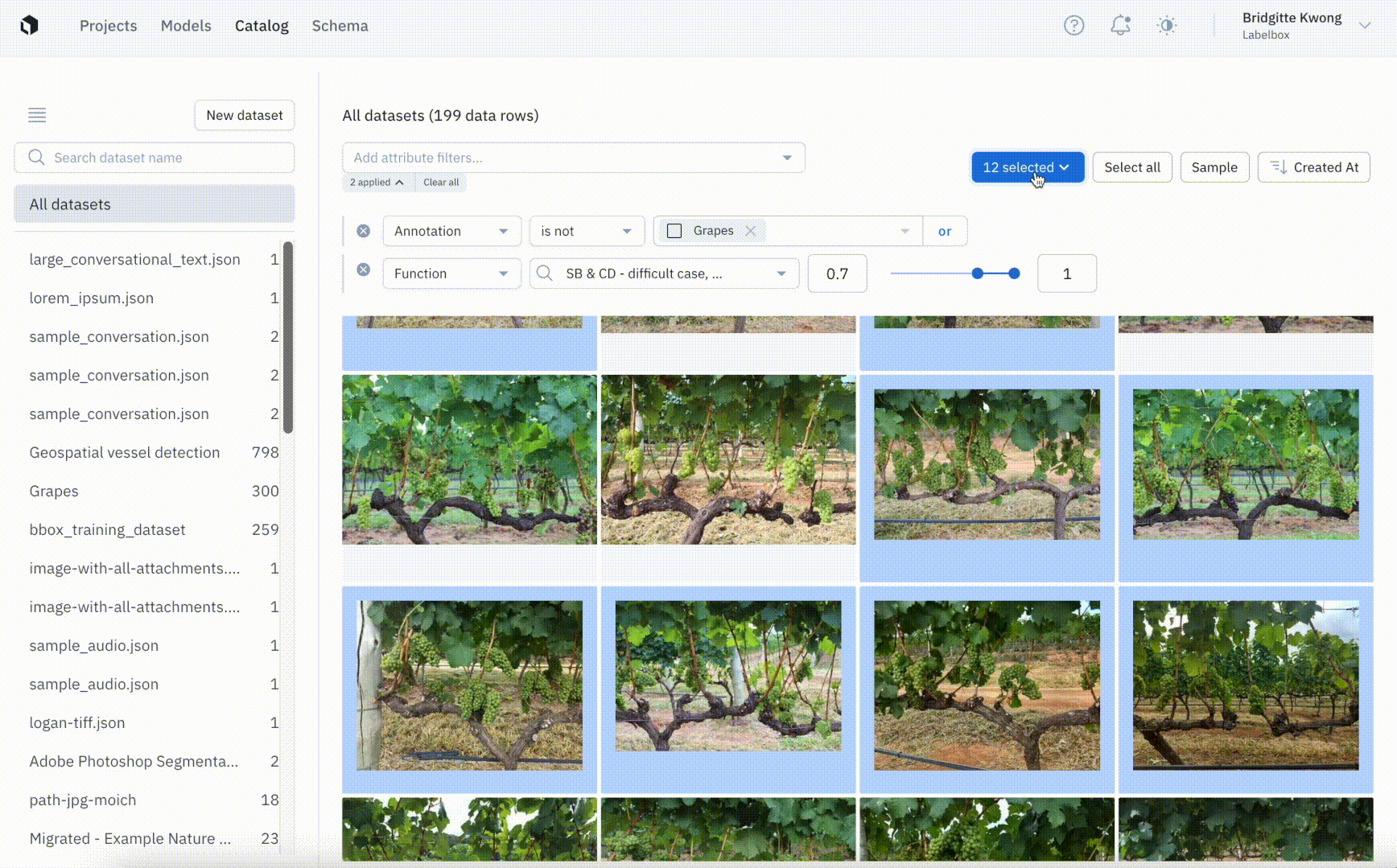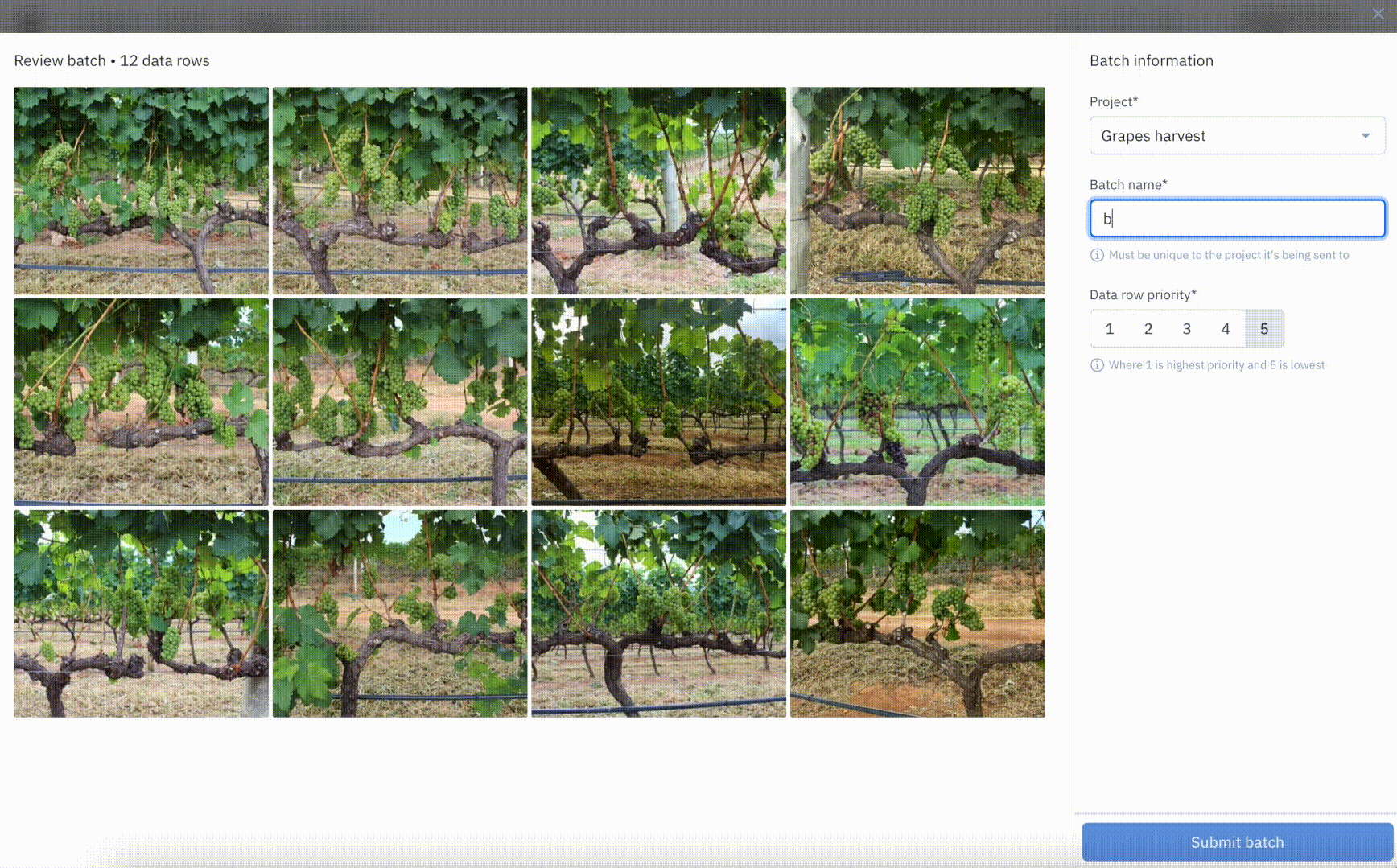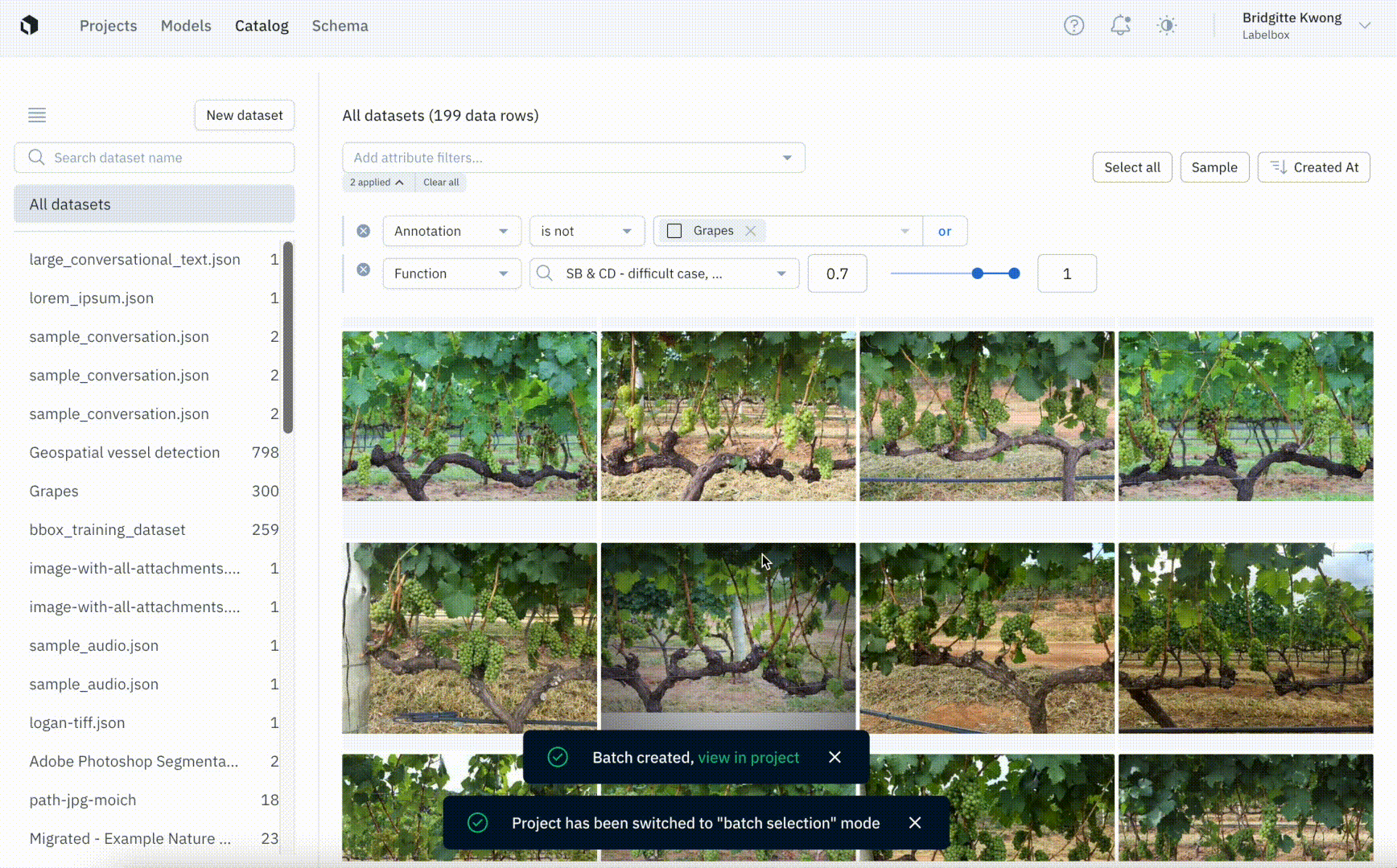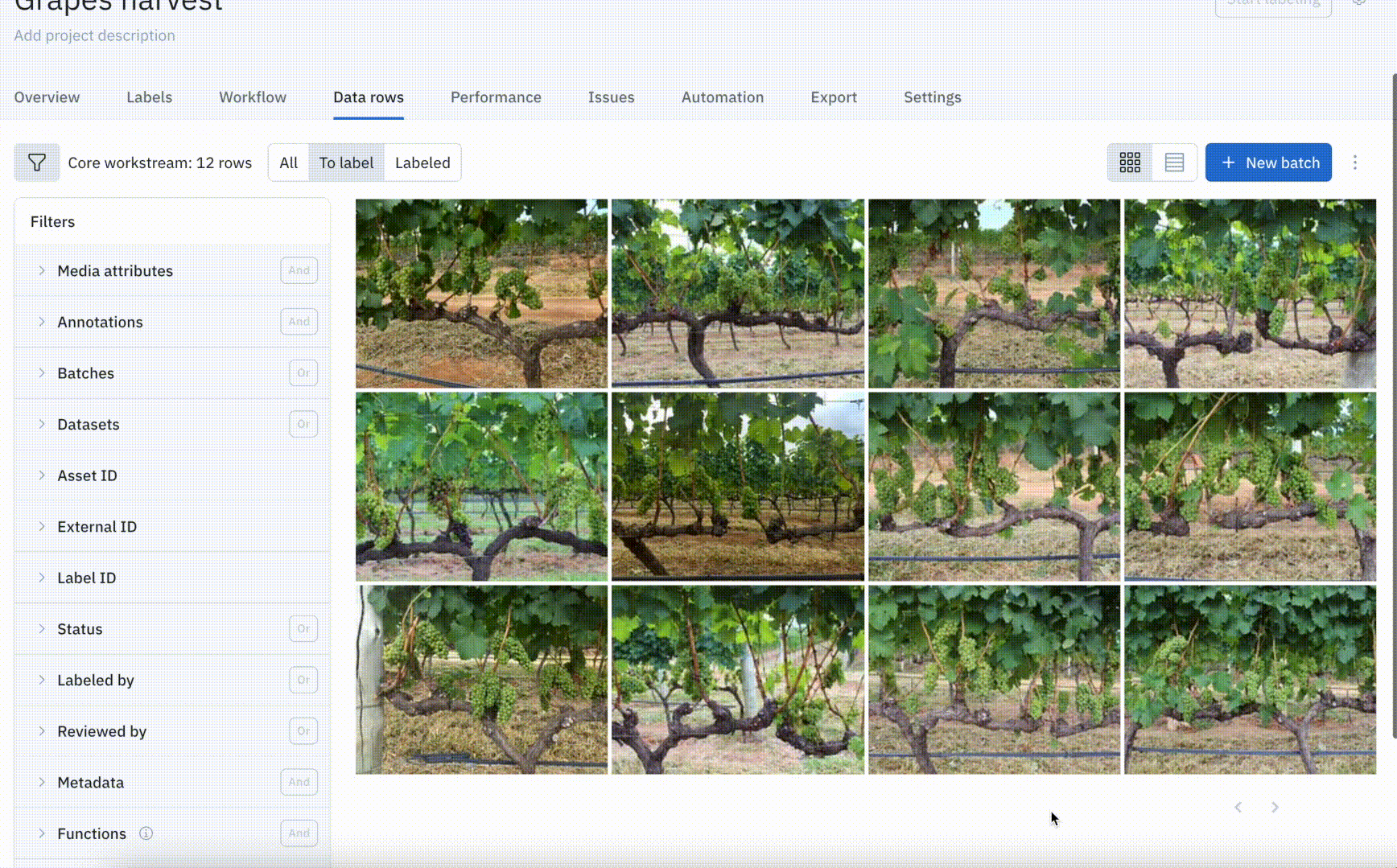
Use random sampling to iterate with smaller batches
Even when teams use Similarity Search and functions to identify a subset of data for labeling, they may still be faced with a large set of data that could take a long time to label without clear promise of improving model performance. To experiment and iterate faster, teams can curate a random sample of data and submit that smaller batch to a labeling project. Compared to manual sampling, random sampling can help remove bias while saving time so teams can move forward with smaller, more focused iterations.
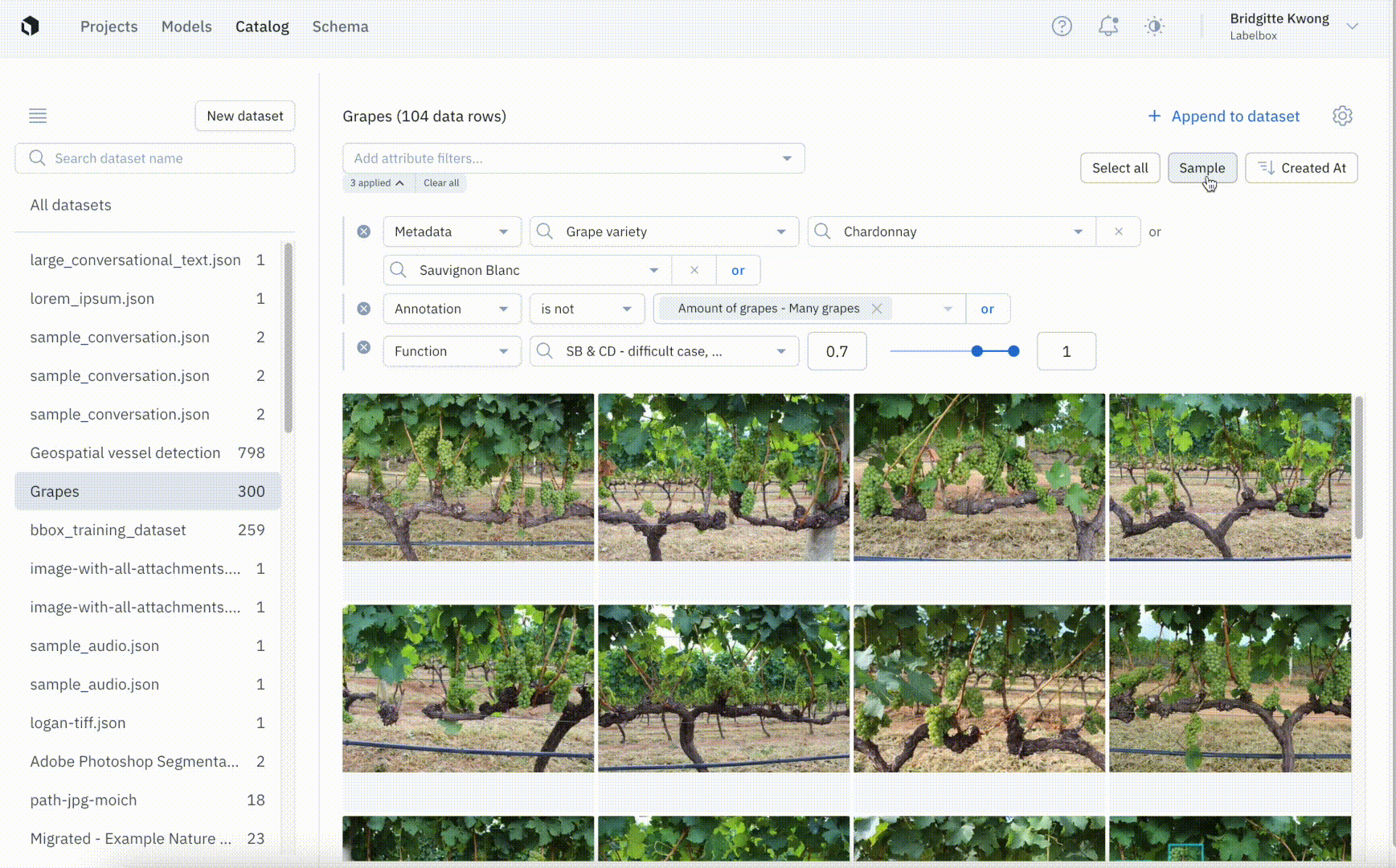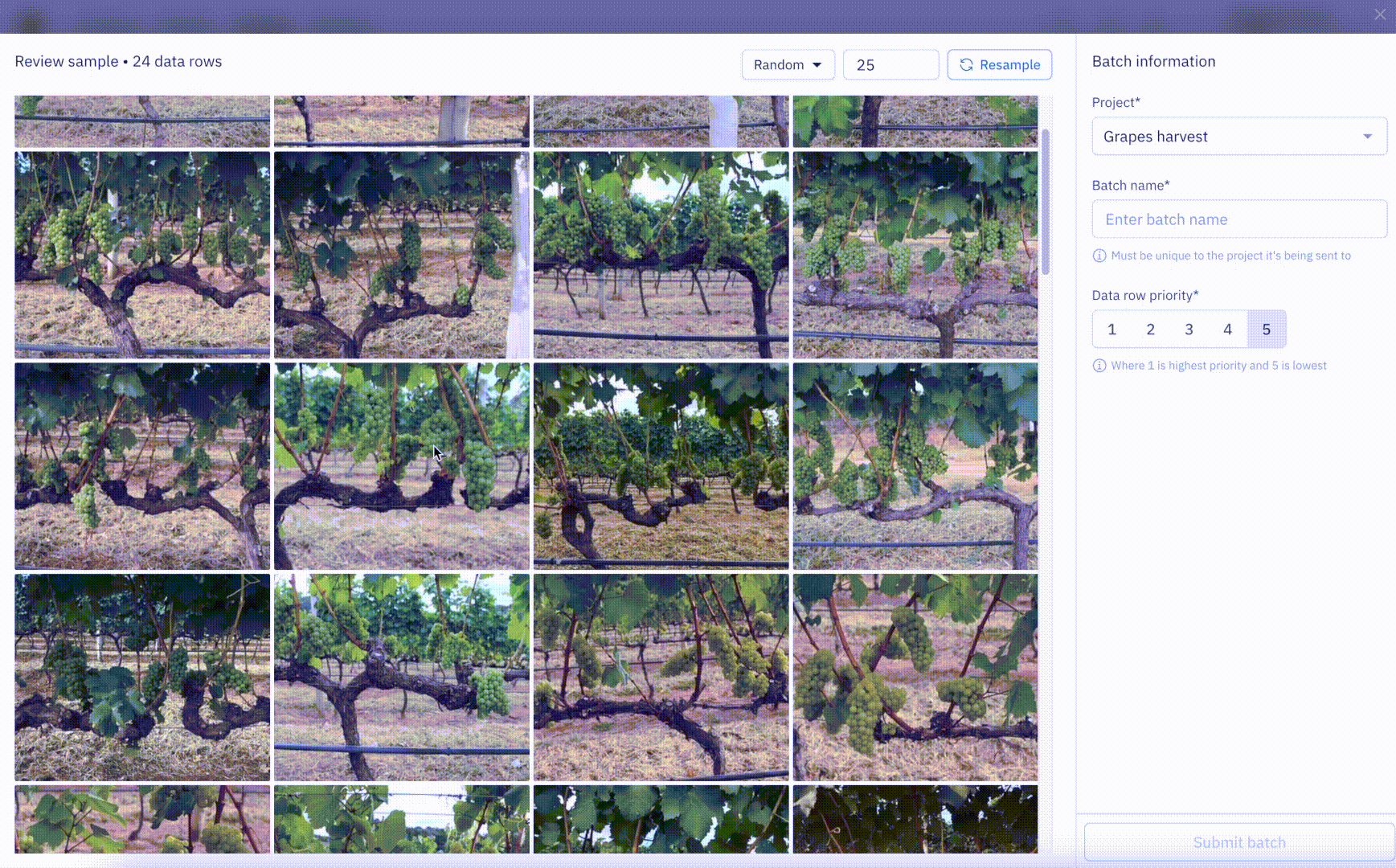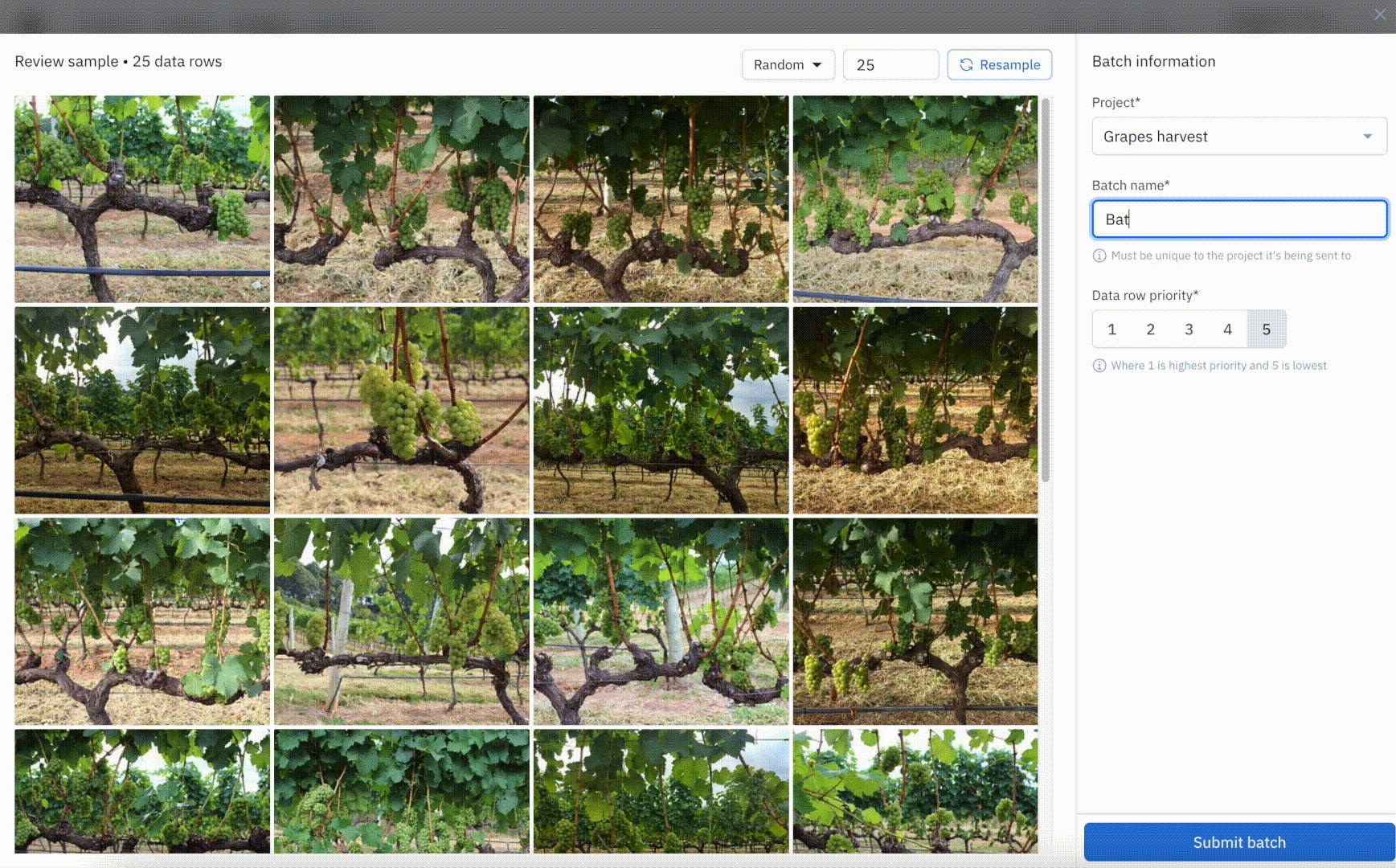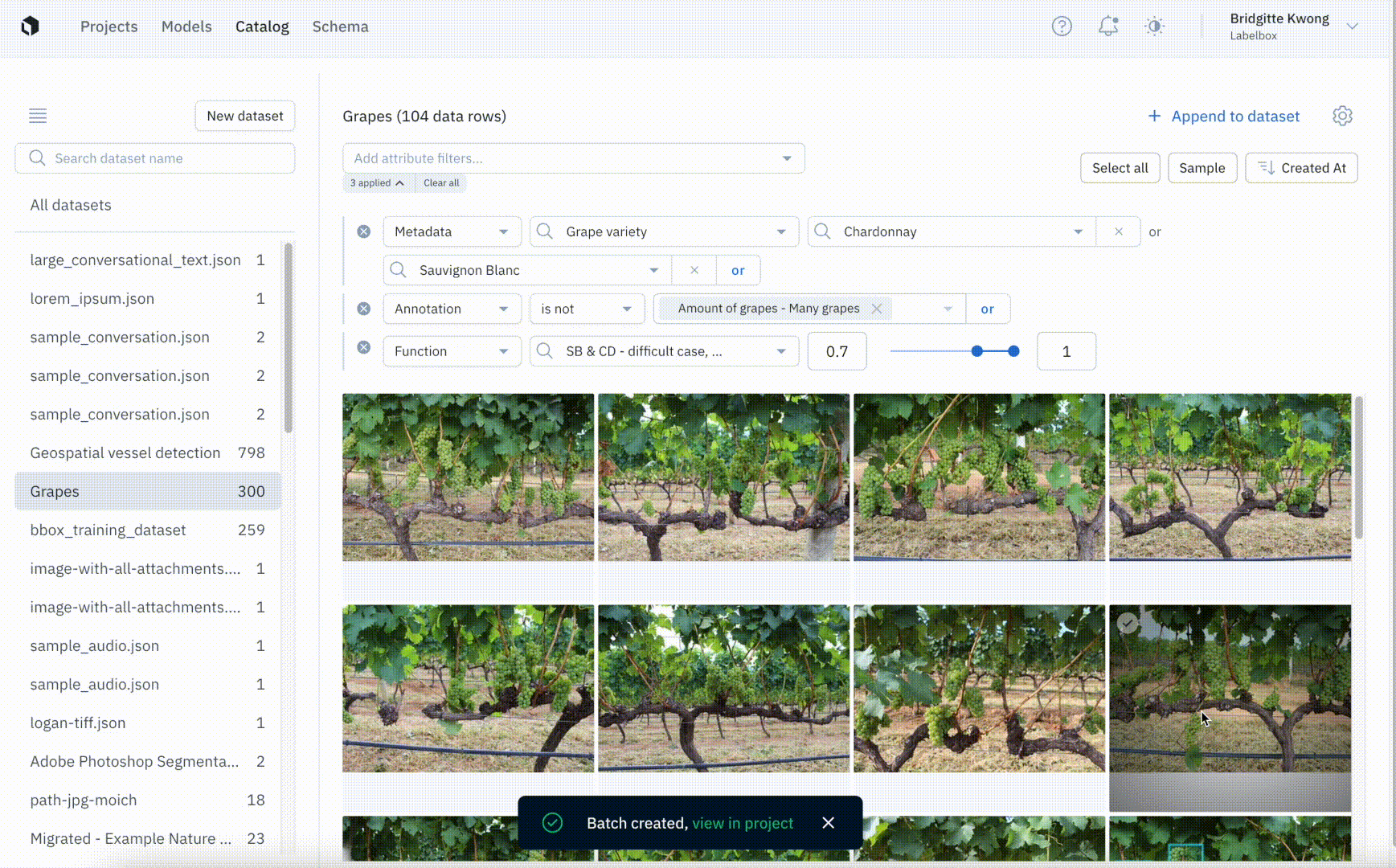
Launch data-centric workflows from Catalog
A key to a successful and efficient ML program is not only having a deep understanding of your data, but also systems and workflows in place to help you quickly and powerfully manage massive disparate datasets. Once a team can more confidently answer questions about their data and start uncovering new trends and outliers, they can focus their efforts toward identifying the type of data that will most meaningfully improve their model performance. Catalog makes that easy. We’re excited to see you get started.


